大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。今天给大家带来的文章是LoRA微调的技巧和方法,希望能对同学们有所帮助。
文章目录
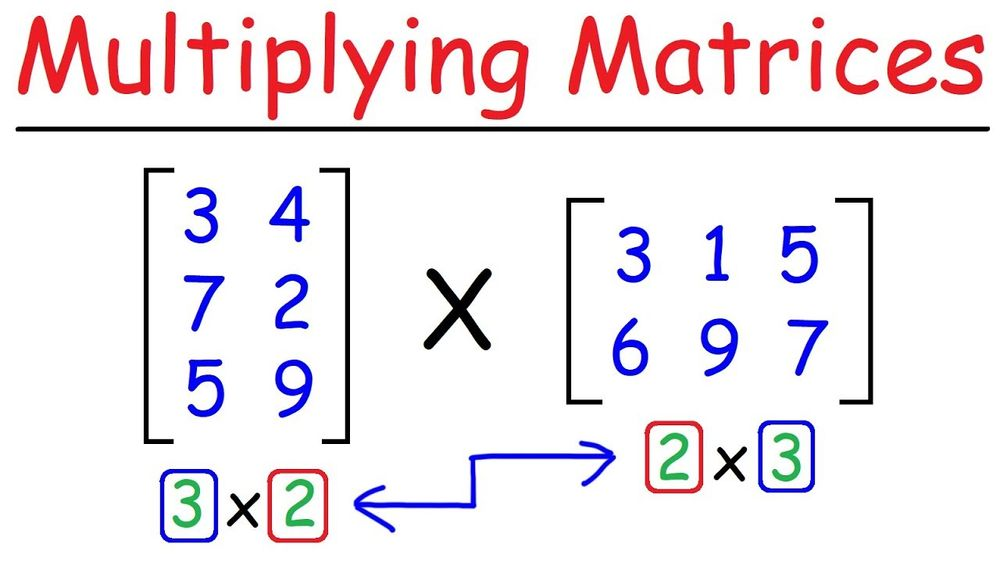
1. 定义
对于大语言模型而言,全量微调的代价是比较高的,需要数百GB的显存来训练具有几B参数的模型。为了解决资源不足的问题,大佬们提出了一种新的方法:低秩适应(Low-Rank Adaptation)。与微调OPT-175B相比,LoRA可以将可训练参数数量减少一万倍,并且GPU显存降低3倍以上。详细内容可参考论文《LoRA: Low-Rank Adaptation of Large Language Models》和HuggingFace PEFT博客文章《Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware》。

LoRA是一种常用的高效微调的训练方法(PEFT),旨在加快大型语言模型的训练过程,同时减少显存的使用。通过引入更新矩阵对现有权重进行操作,LoRA专注于训练新添加的权重。LoRA方法具有以下的几大优点:
- 保留预训练权重:LoRA保持先前训练权重的冻结状态,最小化了灾难性遗忘的风险。这确保了模型在适应新数据时保留其现有知识。
- 已训练权重的可移植性:与原始模型相比,LoRA中使用的秩分解矩阵参数明显较少。这个特点使得经过训练的LoRA权重可以轻松地转移到其他环境中,使它们非常易于移植。
- 与注意力层集成:通常将LoRA矩阵合并到原始模型的注意力层中。此外,自适应缩放参数允许控制模型对新培训数据调整程度。
- 显存效率:LoRA改进后具有更高效利用显存资源能力,在不到本机微调所需计算量3倍情况下运行微调任务成为可能。
对于普通用户来说,依然很难满足1/3的显存需求。幸运的是,大佬们又发明了一种新的LoRA训练方法:量化低秩适应(QLoRA)。它利用bitsandbytes库对语言模型进行即时和近无损量化,并将其应用于LoRA训练过程中。这导致显存需求急剧下降,可以在2个3090卡上微调70B的模型。相比之下,要微调同等规模的模型通常需要超过16个A100-80GB GPU,对应的成本将非常巨大。详细内容可参考论文QLoRA: Efficient Finetuning of Quantized LLMs。

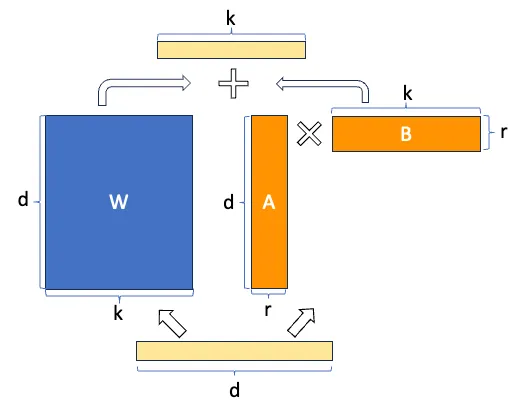
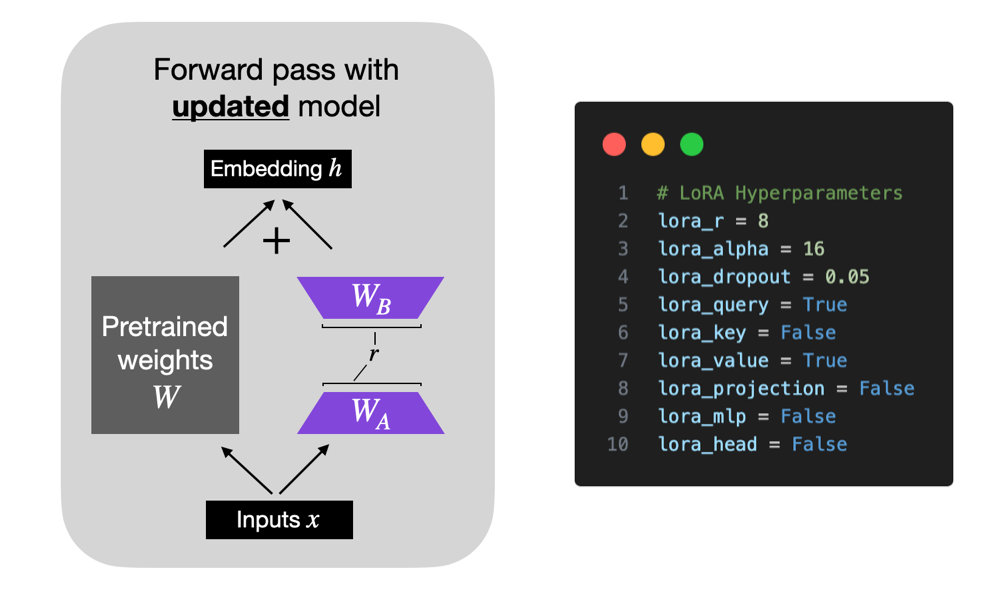
2. LoRA微调参数
首先最关键的参数为:低秩矩阵对应的秩(rank)。为了减少显存,对权重矩阵应用了低秩分解。在LoRA论文中,建议rank设置不小于8(r = 8)。请记住,较高的rank会导致更好的结果,但需要更多的显存。数据集的数量和复杂度越高,所需的rank就越高。
除此之外,另外需要设置的参数即为LoRA微调对应的网络层。最基本的训练对象是查询向量(例如q_proj)和值向量(例如v_proj)投影矩阵。不同模型对应的网络层如下所示:
| Model | Model size | Default module |
|---|---|---|
| Baichuan | 7B/13B | W_packbaichuan |
| Baichuan2 | 27B/13B | W_packbaichuan2 |
| BLOOM | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value |
| ChatGLM | 36B | query_key_value |
| Falcon | 7B/40B/180B | query_key_value |
| InternLM | 7B/20B | q_proj,v_proj |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj |
| LLaMA-2 | 7B/13B/70B | q_proj,v_proj |
| Mistral | 7B | q_proj,v_proj |
| Mixtral | 8x7B | q_proj,v_proj |
| Phi | 1.5/21.3B/2.7B | Wqkv-Q |
| Qwen | 1.8B/7B/14B/72B | c_attn |
| XVERSE | 7B/13B/65B | q_proj,v_proj |
| Yi | 6B/34B | q_proj,v_proj |
3. 书籍推荐
大模型是深度学习自然语言处理皇冠上的一颗明珠,也是当前AI和NLP研究与产业中最重要的方向之一。本书使用PyTorch 2.0作为学习大模型的基本框架,以ChatGLM为例详细讲解大模型的基本理论、算法、程序实现、应用实战以及微调技术,为读者揭示大模型开发技术。
3.1 《从零开始大模型开发与微调:基于PyTorch与ChatGLM》

3.2 内容介绍
大模型是深度学习自然语言处理皇冠上的一颗明珠,也是当前AI和NLP研究与产业中最重要的方向之一。本书使用PyTorch 2.0作为学习大模型的基本框架,以ChatGLM为例详细讲解大模型的基本理论、算法、程序实现、应用实战以及微调技术,为读者揭示大模型开发技术。本书配套示例源代码、PPT课件。
《从零开始大模型开发与微调:基于PyTorch与ChatGLM》共18章,内容包括人工智能与大模型、PyTorch 2.0深度学习环境搭建、从零开始学习PyTorch 2.0、深度学习基础算法详解、基于PyTorch卷积层的MNIST分类实战、PyTorch数据处理与模型展示、ResNet实战、有趣的词嵌入、基于PyTorch循环神经网络的中文情感分类实战、自然语言处理的编码器、预训练模型BERT、自然语言处理的解码器、强化学习实战、只具有解码器的GPT-2模型、实战训练自己的ChatGPT、开源大模型ChatGLM使用详解、ChatGLM高级定制化应用实战、对ChatGLM进行高级微调。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
3.3 适合人群
《从零开始大模型开发与微调:基于PyTorch与ChatGLM》适合PyTorch深度学习初学者、大模型开发初学者、大模型开发人员学习,也适合高等院校人工智能、智能科学与技术、数据科学与大数据技术、计算机科学与技术等专业的师生作为教学参考书。
3.4 粉丝福利
- 本次送书两本
- 活动时间:截止到2023-12-27 9:00
- 参与方式:关注博主、并在此文章下面点赞、收藏并任意评论。
- 一本送给所有粉丝抽奖,另外一本送给购买专栏的同学们,购买专栏并且没有送过书的同学们可私信联系,先到先得,仅限一本
3.5 自主购买
小伙伴也可以访问链接进行自主购买哦~
直达京东购买链接🔗:《从零开始大模型开发与微调:基于PyTorch与ChatGLM》