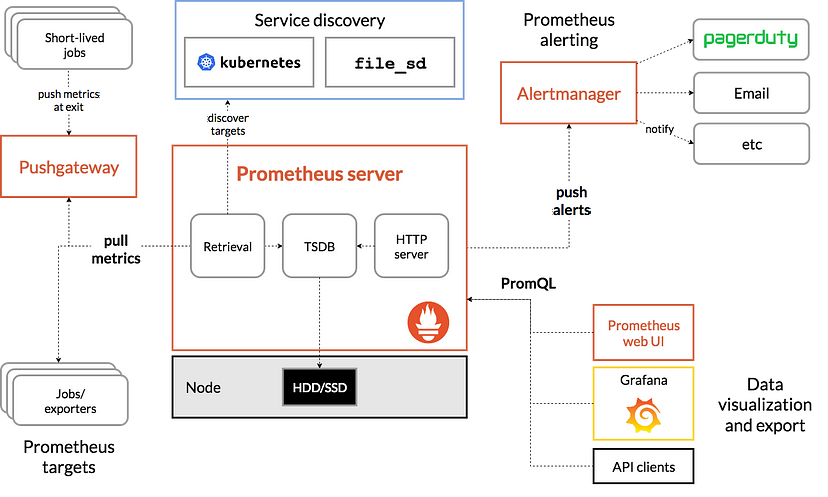
本文旨在帮助Pytorch使用者快速上手使用寒武纪MLU。以代码块为主,文字尽可能简洁,许多部分对标NVIDIA CUDA。不正确的地方请留言更正。本文不定期更新。
文章目录
前言
大背景:信创改造、信创国产化、GPU国产化。
为使PyTorch支持寒武纪MLU,寒武纪对机器学习框架PyTorch进行了部分定制。若要在寒武纪MLU上运行PyTorch,需要安装并使用寒武纪定制的 Cambricon PyTorch。
Cambricon PyTorch的Python包torch_mlu导入
Cambricon CATCH是寒武纪发布的一款Python包(包名torch_mlu),提供了在MLU设备上进行张量计算的能力。安装好Cambricon CATCH后,便可使用torch_mlu模块:
import torch # 需安装Cambricon PyTorch
import torch_mlu # 动态扩展MLU后端
导入 torch 和 torch_mlu 后可以测试在MLU上完成加法运算:
t0 = torch.randn(2, 2, device='mlu') # 在MLU设备上生成Tensor
t1 = torch.randn(2, 2, device='mlu')
result = t0 + t1 # 在MLU设备上完成加法运算
将模型加载到MLU上model.to(‘mlu’)
以ResNet18为例,将模型加载到MLU上用 model.to('mlu'),对标cuda的 model.to(device) :
# 定义模型
model = models.__dict__["resnet50"]()
# 将模型加载到MLU上。
mlu_model = model.to('mlu')
定义损失函数,然后将其拷贝至MLU
# 构造损失函数
criterion = nn.CrossEntropyLoss()
# 将损失函数拷贝到MLU上
criterion.to('mlu')
将数据从CPU拷贝到MLU设备
x = torch.randn(1000000, dtype=torch.float)
x_mlu = x.to(torch.device('mlu'), non_blocking=True)
以mnist.py为例的训练代码demo
import torch # 导入原生 PyTorch
import torch_mlu # 导入 Cambricon PyTorch
from torch.utils.data import DataLoader
from torchvision.datasets import mnist
from torch import nn
from torch import optim
from torchvision import transforms
from torch.optim.lr_scheduler import StepLR
import torch.nn.functional as F
# 定义模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
# 定义前向计算
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# 模型训练
def train(model, train_data, optimizer, epoch):
model = model.train()
for batch_idx, (img, label) in enumerate(train_data):
img = img.mlu()
label = label.mlu()
optimizer.zero_grad()
out = model(img)
loss = F.nll_loss(out, label)
# 反向计算
loss.backward()
# 梯度更新
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(img), len(train_data.dataset),
100. * batch_idx / len(train_data), loss.item()))
# 模型推理
def validate(val_loader, model):
test_loss = 0
correct = 0
model.eval()
with torch.no_grad():
for images, target in val_loader:
images = images.mlu()
target = target.mlu()
output = model(images)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(val_loader.dataset)
# 打印精度结果
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(val_loader.dataset),
100. * correct / len(val_loader.dataset)))
# 主函数
def main():
# 定义预处理函数
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.1307],[0.3081])])
# 获取 MNIST 数据集
train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True)
test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True)
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=1000, shuffle=False)
net_orig = Net()
# 模型拷贝到MLU设备
net = net_orig.mlu()
optimizer = optim.Adadelta(net.parameters(), 1)
# 训练10个epoch
nums_epoch = 10
# 训练完成后保存模型
save_model = True
# 学习率调整策略
scheduler = StepLR(optimizer, step_size=1, gamma=0.7)
for epoch in range(nums_epoch):
train(net, train_data, optimizer, epoch)
validate(test_data, net)
scheduler.step()
if save_model: # 将训练好的模型保存为model.pth
if epoch == nums_epoch-1:
checkpoint = {
"state_dict":net.state_dict(), "optimizer":optimizer.state_dict(), "epoch": epoch}
torch.save(checkpoint, 'model.pth')
if __name__ == '__main__':
main()