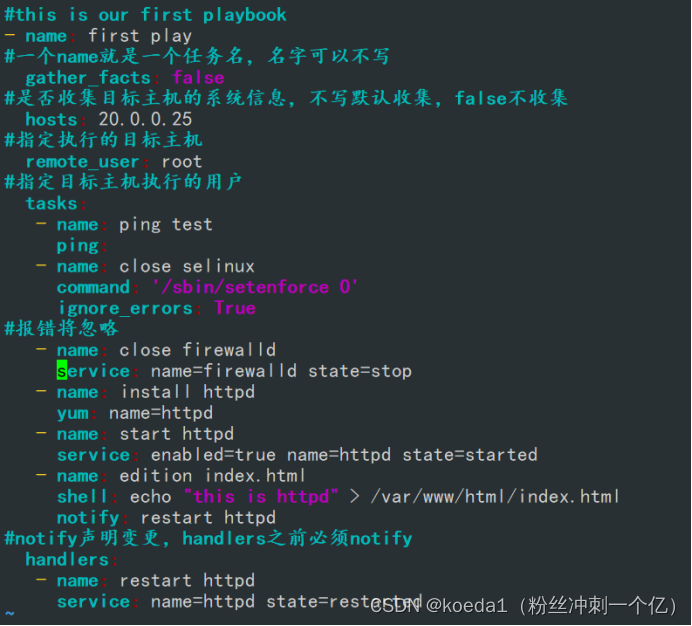
索引可以说是Elasticsearch中非常重要的模块,一个索引可以视作关系数据库中的一张表,本帖将详细介绍与Elasticsearch索引相关的各种功能等。主要内容如下:
- 索引映射(mapping)结构的定义方法,常用的各种字段类型和动态映射的使用。
- 使用Elasticsearch的REST端点完成对索引数据的增删改查。
- 索引数据的路由规则,根据索引数据默认的路由策略实现手动使用路由规则控制数据写入分片。
- 索引别名(aliases)的使用方法,包括如何将别名与数据过滤和数据路由配合使用来获得索引数据。
- 使用滚动索引(rollover index)将属于一个索引的数据分发到新的索引中,避免数据在一个索引中写入得太多。
- 索引数据的状态管理,包括对索引清空缓存、刷新、冲洗、强制合并、关闭、冻结等操作。
- 使用索引的块配置来改变索引数据的读写状态。
- 索引模板的概念,使用索引模板自动化创建同一类型的索引映射。
- 索引监控的方法,使用监控端点查看索引的各项统计指标。
- 使用过滤条件控制索引分片的分配。
1、使用映射定义索引结构
本节介绍使用索引映射建立索引结构,并介绍索引常用的字段类型和元数据字段信息,掌握了这些你可以根据实际需要创建映射结构来存储索引数据。
1.1、映射的概念和使用
Elasticsearch的映射相当于数据库的数据字典,它定义了每个字段的名称和能够保存的数据类型。例如,你可以定义一个简单的索引映射,如下所示:
PUT mysougoulog
{
"settings": {
"number_of_shards": "5",
"number_of_replicas": "1"
},
"mappings": {
"properties": {
"userid": {
"type": "text"
}
}
}
}
在Kibana中运行上述代码后,就在Elasticsearch中创建了一个名为mysougoulog的索引,其中包含一个userid字段,类型为text。映射的settings里面包含创建索引时设定的配置信息。索引的配置也分为静态配置和动态配置,静态配置必须在创建映射时写入settings,动态配置既可以在settings中设置,也可以在创建映射后调用REST服务进行修改。上述代码在索引mysougoulog的映射settings中配置了该索引拥有5个主分片,每个主分片拥有一个副本分片。如果不配置它,那么索引会默认拥有一个主分片和一个副本分片。主分片的数量是静态配置的,在索引创建后不得修改;副本分片的数量是动态配置的,可以使用如下的REST服务进行修改。
PUT mysougoulog/_settings
{
"settings": {
"number_of_replicas": "2"
}
}
注意:在Elasticsearch 7.x中定义索引的映射时,不再需要指定_type的类型,这个元数据已经被删除,但是索引依然会自带一个名为_doc的类型。索引的映射建立以后,可以继续给映射添加新的字段,但是旧的字段无法删除和修改,这点在使用时需要引起重视。
要查看刚才创建的映射结构,可以使用如下代码:
GET mysougoulog/_mapping
如果你想添加新的字段来改变映射,可以使用如下代码,添加一个名为key的text类型的字段:
PUT mysougoulog/_mapping
{
"properties": {
"key": {
"type": "text"
}
}
}
最新的映射结构如下所示:
{
"mysougoulog": {
"mappings": {
"properties": {
"key": {
"type": "text"
},
"userid": {
"type": "text"
}
}
}
}
}
1.2、映射支持的常规字段类型
Elasticsearch内置了20多种字段类型用于支持多种多样的结构化数据,由于篇幅所限,本小节仅介绍几种常用的字段类型,如需要了解全部的类型,请参考官方文档的有关介绍。
1.文本类型
文本类型(text)是索引中常用的字段类型,索引mysougoulog的两个字段都是文本类型。文本类型是一种默认会被分词的字段类型,如果不指定,Elasticsearch会使用标准分词器切分文本,并会把切分后的文本保存到索引中。搜索时,只有搜索文本和索引中的文本相匹配的文档才会出现在搜索结果中。
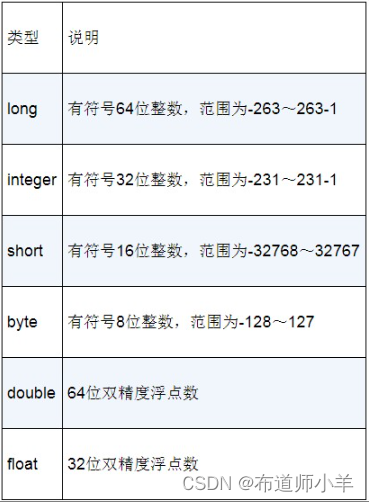
2.数值类型
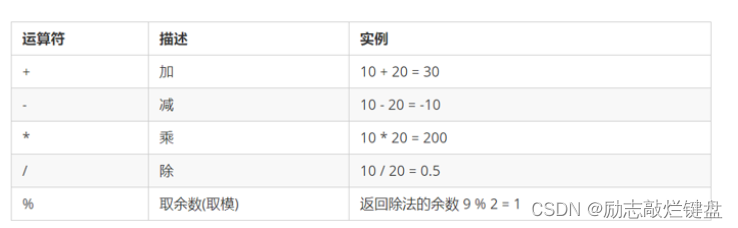
正如常规的数据库那样,Elasticsearch也支持不同精度的数值型数据,用于存放整数和浮点数,其支持的常用数值类型如下表所示:
3.日期类型
你可以使用下面的请求继续给mysougoulog索引添加一个日期类型(date)的字段visittime。
PUT mysougoulog/_mapping
{
"properties": {
"visittime": {
"type": "date"
}
}
}
默认情况下,索引中的日期为UTC时间格式,其比北京时间晚8h,使用时每次查询都需要进行格式转换,很不方便。所以在实际项目中,你可以使用format参数自定义时间格式,例如:
PUT sougoulog-date
{
"mappings": {
"properties": {
"visittime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss ||epoch_millis"
}
}
}
}
这里新建的索引sougoulog-date,使用format格式化日期,这个字段允许接收两种日期格式,其中epoch_millis代表时间戳的毫秒数。
注意:当你在使用date字段时,有必要搞清楚写入索引的格式化数据到底是UTC时间还是北京时间,这会影响搜索和统计时的时区设置。使用时间戳格式表示时间是个不错的办法,可以避免引起时区问题。由于yyyy-MM-dd HH:mm:ss不带有时区信息,写入数据时默认时区为0,Elasticsearch会把传入的日期看作UTC时间,存储时会把这个UTC时间转换为长整型的时间戳来保存,当你基于这个字段进行条件查询或统计分析时,实际上使用的是这个时间戳。在本书中,如果没有特别指明,索引中不带时区的日期都是指UTC时间。
4.关键字类型
关键字类型(keyword)的字段与文本类型的字段不同,它用于保存不经过分析、处理的原始文本,实际上keyword类型字段在实际开发中很常用,当需要对文本字段进行精准匹配查询时就必须使用keyword类型字段。你可以创建一个名称为name的关键字类型的索引,代码如下:
PUT keyword-test
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
}
}
}
}
在日常文本类型字段的使用过程中,假如检索时你既希望对文本数据做分词处理,又想用不分词的keyword类型字段来进行统计分析和精准搜索,该如何达到两全其美的效果呢?通常比较好的做法是,给text类型字段添加一个fields参数,在fields中放一个不分词的keyword类型字段。
PUT test-1
{
"mappings": {
"properties": {
"key": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
上面的索引test-1中,创建了一个名称为key的文本类型字段,它还包含一个不分词的keyword字段。ignore_above参数表示256个字符后面的内容会被忽略,不写入keyword字段,以节约存储空间。该索引的字段key可以用于全文检索,字段key.keyword则可用于精准搜索和聚集统计。
5.布尔类型
跟编程语言一样,布尔类型(boolean)用于保存真或假这种形式的数据。你可以创建一个布尔类型的索引,代码如下:
PUT test-2
{
"mappings": {
"properties": {
"sex": {
"type": "boolean"
}
}
}
}
6.经纬度类型
有时开发过程中涉及GIS地图相关的功能,例如与经纬度相关的搜索,这时候就需要用到经纬度类型(geo_point)。你可以创建一个经纬度类型的索引,代码如下:
PUT geo-1
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
这样就能创建索引geo-1,其包含一个location字段,是经纬度类型的,该类型的数据会包含坐标点的经纬度。
7.对象类型
你可以直接把一个JSON对象作为一个字段写入索引,对象里还可以继续嵌套对象:
PUT obj-test
{
"mappings": {
"properties": {
"region": {
"type": "keyword"
},
"manager": {
"properties": {
"age": {
"type": "integer" },
"name": {
"properties": {
"first": {
"type": "text" },
"last": {
"type": "text" }
}
}
}
}
}
}
}
该索引的manager字段是一个对象,它包含age和name两个字段,而name字段也是一个对象,它拥有first和last两个字段。索引在存储对象数据时,会像下面这样把整个对象进行“展平存储”:
{
"region": "USA",
"manager.age": 20,
"manager.name.first": "kite",
"manager.name.last": "lili"
}
这种方式导致一个对象不可以作为一个独立的单元来进行检索,这可能会影响搜索结果的准确性,实际中需要使用嵌套对象(nested object)来作为存储对象的容器。
8.数组类型
数组类型比较简单,你可以把多个同类型的数据放在同一个字段中,其既可以是数字、字符,也可以是对象类型的数据。使用数组类型时,映射中无须用额外的关键字进行定义,例如:
PUT shopping/_doc/1
{
"tags": [ "elastic", "search" ],
"lists": [
{
"name": "mylist",
"description": "language list"
},
{
"name": "testlist",
"description": "testlist"
}
]
}
上面的请求直接向索引shopping中添加了两个数组,一个是字符串数组tags,另一个是对象数组lists。Elasticsearch会根据数据内容自动生成对应的映射,这种机制就是后面要介绍的动态映射。
9.二进制文件类型
有时候你需要将图片的Base64编码的字符串保存到索引中,这时候你不应该使用关键字类型,因为keyword类型的字段拥有最大长度上限,很可能无法容纳二进制文件,所以应该使用专门的二进制文件类型(binary)。例如:
PUT binary-test
{
"mappings": {
"properties": {
"pic": {
"type": "binary"
}
}
}
}
这个映射只有一个二进制文件类型的字段pic,用于保存图片的Base64编码的字符串,由于该字段没有业务上的含义,因此它不能作为检索和统计分析的条件。
1.3、忽略映射中不合法的数据
有时你无法预知写入映射的数据是否都合法,如果某个字段写入的数据跟映射定义的字段类型不匹配就会导致数据写入失败。如果你希望即使某个字段的数据不合法,也不影响其他字段的写入,就可以在映射中使用ignore_malformed参数来实现这一目的。例如:
PUT ignore-test
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"born": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"ignore_malformed": true
}
}
}
}
在索引ignore-test的映射中,为born字段设置ignore_malformed为true,它表示即使born字段的数据非法,也不影响其他字段的写入。可以添加几条数据测试一下,代码如下:
PUT ignore-test/_doc/1
{
"age":22,
"born":"www"
}
PUT ignore-test/_doc/2
{
"age": "test",
"born":"2020-01-01 00:00:05"
}
PUT ignore-test/_doc/3
{
"age": 44,
"born":"2020-01-01 00:00:05"
}
上面添加的3条数据中,只有文档2无法添加成功,原因是age字段添加的数据不合法。由于对born字段设置了ignore_malformed为true,所以文档1能够添加成功,文档3的两个字段均合法,所以也能添加成功。通过下述代码查询添加到索引的数据。
GET ignore-test/_search
{
"query": {
"match_all": {
}
}
}
可以得到下面的结果:
{
"took": 93,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "ignore-test",
"_id": "1",
"_score": 1,
"_ignored": [
"born"
],
"_source": {
"age": 22,
"born": "www"
}
},
{
"_index": "ignore-test",
"_id": "3",
"_score": 1,
"_source": {
"age": 44,
"born": "2020-01-01 00:00:05"
}
}
]
}
}
可以看到文档1被成功添加到索引中,born字段出现在_ignored元数据中,表示该字段在写入时出现了非法数据。虽然可以在_source中找到非法的原始数据,但是这些非法的数据并未被写入索引也不能被搜索和统计。如果你想为索引的所有字段都开启忽略非法数据的功能,则可以在索引映射中添加相应的配置,代码如下:
PUT ignore-all-fields
{
"settings": {
"index.mapping.ignore_malformed": true
},
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"born": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
1.4、字段复制和字段存储
Elasticsearch允许在映射中为某个字段定义copy_to参数,以实现复制多个其他字段的内容,这样在搜索一个字段时能够达到同时搜索多个字段的效果,使用字段复制比使用多字段匹配Multi_match性能更好。
新建一个索引copy-field,其中,full_text字段的内容是从其余3个字段中复制而来的:
PUT copy-field
{
"mappings": {
"properties": {
"title": {
"type": "text",
"copy_to": "full_text"
},
"author": {
"type": "text",
"copy_to": "full_text"
},
"abstract": {
"type": "text",
"copy_to": "full_text"
},
"full_text": {
"type": "text"
}
}
}
}
然后向其中添加一条数据。
PUT copy-field/_doc/1
{
"title": "how to use es",
"author": "Smith",
"abstract":"this is the abstract"
}
此时直接搜索full_text字段能够达到同时搜索其他3个字段的效果:
POST copy-field/_search
{
"query": {
"match": {
"full_text": "smith"
}
}
}
该请求能搜到刚才添加的文档,不过可以注意到_source元数据中并不包含full_text字段的内容,因为_source保存的是构建索引时的原始JSON文本。
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "copy-field",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "how to use es",
"author": "Smith",
"abstract": "this is the abstract"
}
}
]
}
}
如果你想查看复制字段full_text的内容,可以在映射中设置将字段的值保存到磁盘上:
PUT copy-store-field
{
"mappings": {
"properties": {
"title": {
"type": "text",
"copy_to": "full_text"
},
"author": {
"type": "text",
"copy_to": "full_text"
},
"abstract": {
"type": "text",
"copy_to": "full_text"
},
"full_text": {
"type": "text",
"store": true
}
}
}
}
在字段full_text对应的代码中,将字段store设置成了true。下面添加一条数据来看一下效果,代码如下:
PUT copy-store-field/_doc/1
{
"title": "how to use es",
"author": "Smith",
"abstract":"this is the abstract"
}
然后使用stored_fields获取full_text字段的内容:
POST copy-store-field/_search
{
"stored_fields": ["full_text"]
}
从以下返回结果可以看到full_text字段的内容确实是由title、author、abstract这3个字段的内容拼接而成:
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "copy-store-field",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"fields" : {
"full_text" : [
"how to use es",
"Smith",
"this is the abstract"
]
}
}
]
}
注意:默认情况下,除了_source字段外,所有的字段均不会被保存到磁盘上,一般来说这也没什么问题,因为你可以使用_source得到字段的内容。由于字段的值可能有多个,所以在fields中返回的每个字段值是一个数组。
1.5、动态映射
若向Elasticsearch的索引中添加数据的字段是原先未定义的,数据也依然可以被成功添加。Elasticsearch拥有动态映射机制,会根据添加的数据内容自动识别对应的字段类型,这也正是索引的映射可以根据写入的数据自动“扩张”的原因。
当一个不存在的字段数据写入索引时,下表中的几种数据类型会被动态映射机制自动识别,其余类型必须手动指定,无法被自动识别出来,默认的字段动态映射规则如下表所示:
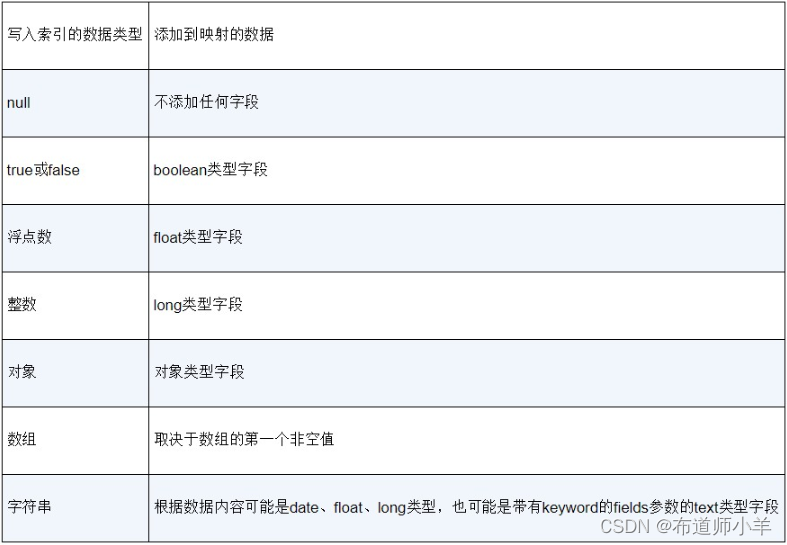
你可以用下面的请求测试日期类型字段的自动识别效果,它要求数据满足日期的格式规范:
PUT date-test/_doc/1
{
"create_date": "2015/09/02 00:00:00"
}
GET date-test/_mapping
从以下返回的结果中可以发现索引中自动添加了一个date类型字段:
{
"date-test" : {
"mappings" : {
"properties" : {
"create_date" : {
"type" : "date",
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis"
}
}
}
}
}
如果你不喜欢这种日期格式,可以手动修改,代码如下:
PUT date-test2
{
"mappings": {
"dynamic_date_formats": ["yyyy-MM-dd HH:mm:ss","yyyy-MM-dd"]
}
}
然后向索引date-test2中添加日期格式数据,代码如下:
PUT date-test2/_doc/1
{
"create_date": "2015-09-02 00:00:00",
"born":"2020-01-01"
}
GET date-test2/_mapping
从以下返回结果可以看到,索引date-test2中已经自动添加了两个新的date类型字段:
{
"date-test2": {
"mappings": {
"dynamic_date_formats": [
"yyyy-MM-dd HH:mm:ss",
"yyyy-MM-dd"
],
"properties": {
"born": {
"type": "date",
"format": "yyyy-MM-dd"
},
"create_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
}
动态映射机制还可以将数字字符串自动映射为float和long类型,不过需要设置索引的numeric_detection为true,代码如下:
PUT number-test
{
"mappings": {
"numeric_detection": true
}
}
PUT number-test/_doc/1
{
"price": "2.5",
"amount":"2"
}
GET number-test/_mapping
这时候,两个字符串字段自动被识别成了数值类型,返回结果如下:
{
"number-test": {
"mappings": {
"numeric_detection": true,
"properties": {
"amount": {
"type": "long"
},
"price": {
"type": "float"
}
}
}
}
}
以上便是索引默认的动态映射规则的相关说明,如果你不喜欢这套规则,还可以使用动态模板来自定义映射规则。假如你希望当整数字段添加到索引中时,映射中新增的是integer类型字段而不是long类型字段;当文本字段添加到索引中时,fields的keyword类型字段的长度为512而不是256,你可以为索引定义以下动态模板:
PUT dynamic-type
{
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 512
}
}
}
}
}
]
}
}
其中match_mapping_type代表映射自动识别的字段类型,可以在mapping中配置你想添加到映射中的字段类型。下面添加一条数据到索引dynamic-type中来查看效果,代码如下:
PUT dynamic-type/_doc/1
{
"age": 5,
"name": "li yan hong"
}
GET dynamic-type/_mapping
返回的索引映射结构如下:
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "text",
"fields" : {
"raw" : {
"type" : "keyword",
"ignore_above" : 512
}
}
}
}
除了使用字段类型进行映射,还可以按照字段名称来设置映射。例如,你想把所有字段名以long_开头的字段(字段名以_text结尾的除外)都映射为long类型,可以将动态模板配置成如下形式:
PUT dynamic-name
{
"mappings": {
"dynamic_templates": [
{
"longs_as_strings": {
"match_mapping_type": "string",
"match": "long_*",
"unmatch": "*_text",
"mapping": {
"type": "long"
}
}
}
]
}
}
上述配置使用了match参数,把以long_开头的字段(但排除以_text结尾的字段)配置成了long类型。下面添加一条数据到索引dynamic_name中来查看效果,代码如下:
PUT dynamic-name/_doc/1
{
"long_num": "5",
"long_text": "22"
}
GET dynamic-name
从以下返回结果可以看到,long_num被映射成了long类型,而long_text字段被映射 成了text类型:
"properties" : {
"long_num" : {
"type" : "long"
},
"long_text" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
对于存在对象类型的索引,可以使用path_match将指定路径的字段映射成需要的类型,代码如下:
PUT dynamic-obj
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
上述动态模板中配置了将路径匹配name.的字段(但排除路径匹配.middle的字段)全部映射成关键字类型。可以添加数据来查看映射的效果,代码如下:
PUT dynamic-obj/_doc/1
{
"name": {
"first": "Lily",
"middle": "Ted",
"last": "betty"
}
}
GET dynamic-obj
从下面的返回结果可以看到,在映射中,name.first和name.last都被映射成了关键字类型,而name.middle被映射成了默认的文本类型:
"properties" : {
"name" : {
"properties" : {
"first" : {
"type" : "keyword"
},
"last" : {
"type" : "keyword"
},
"middle" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
以上就是动态模板的使用方法,使用动态映射机制可以方便地向索引中动态添加新的字段并且可以自定义映射规则,比使用关系数据库方便,因为它能提高开发人员创建映射的效率,在实际项目中也比较常用。
2、 索引中数据的增删改查
在上节中已经介绍了如何建立具有各种数据类型的映射,但是它们只是空的数据字典,不包含任何文档数据,本节就来探讨如何对索引映射中的数据进行增删改查。
2.1、使用REST端点对索引映射中的数据进行增删改查
先新建一个索引结构,代码如下:
PUT test-3-2-1
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"sex": {
"type": "boolean"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"born": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"location": {
"type": "geo_point"
}
}
}
}
上述索引具有前面讲过的各种常用数据类型,下面就来向该索引添加一条数据,代码如下:
POST test-3-2-1/_doc/1
{
"id": "1",
"sex": true,
"name": "张三",
"born": "2020-09-18 00:02:20",
"location": {
"lat": 41.12,
"lon": -71.34
}
}
这样就向索引test-3-2-1中添加了一条数据,url请求参数中的1是该数据的主键,_doc表示索引的type。如果在参数中没有指定主键,Elasticsearch会为该文档生成一个不重复的字符串作为主键。文档的主键信息会保存在索引的元数据_id字段中,上述请求在主键为1的文档不存在时会添加一条记录到索引中,如果索引中已经存在一个主键为1的文档,就会把原有的文档完全覆盖。由于在映射中已经对日期字段born定义好了格式,这里的数据直接把格式化好的日期数据字符串添加到索引中即可。
注意:在实际项目中通常需要按照业务需求手动指定主键,它可以用于数据去重。修改文档数据时需要通过主键定位唯一的文档。_doc是索引的默认的type元数据,在Elasticsearch 6.x以后的版本中每个索引只能有一个type,7.x版本给每个索引指定了一个默认的type即_doc,元数据_type会在将来的版本中彻底被删除。
为了查看刚才添加的文档数据,可以发起一个查询请求,代码如下:
GET test-3-2-1/_doc/1
你将会查询到如下结果:
{
"_index": "test-3-2-1",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"id": "1",
"sex": true,
"name": "张三",
"born": "2020-09-18 00:02:20",
"location": {
"lat": 41.12,
"lon": -71.34
}
}
}
在上面的结果中,出现了好几个索引的元数据。所谓的索引的元数据,指的是记录索引数据的数据,它在Elasticsearch内部自动生成,可用于对索引数据进行识别和管理。其中,_index字段记录了该数据所属的索引,当请求参数的搜索范围是多个索引时这个字段会非常有用,它直接表明了每个文档所属的索引的名称。_type字段的值是默认值_doc,这个元数据在未来的版本中会被删除。_id字段指明了该文档的主键值是1。_version表示的是该文档的版本号,在旧版本的Elasticsearch中可以使用这个字段来完成并发控制,以防止出现并发问题,在7.9.1版本中已经改为使用_seq_no和_primary_term来完成并发控制。最后一个元数据_source字段保存了文档数据的完整JSON结构,用于查看文档的内容。
添加完数据以后,可以对该数据进行修改,使用如下请求:
POST test-3-2-1/_update/1
{
"doc": {
"sex": false,
"born": "2020-02-24 00:02:20"
}
}
上面的请求使用了_update端点进行数据修改,这时候只需要传递主键和需要修改的字段内容,对于无须修改的字段可以不用提供。再次查询结果如下:
{
"_index": "test-3-2-1",
"_id": "1",
"_version": 2,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"id": "1",
"sex": false,
"name": "张三",
"born": "2020-02-24 00:02:20",
"location": {
"lat": 41.12,
"lon": -71.34
}
}
}
最后试一试删除这条主键为1的数据,你只需要发送一个DELETE请求,代码如下:
DELETE test-3-2-1/_doc/1
以上就是对索引数据进行增删改查的基本介绍,通过使用这些REST端点,可以非常方便地完成对索引数据的操作管理。
2.2、使用乐观锁进行并发控制
由于Elasticsearch不支持事务管理,它自然也就没有事务的隔离级别。由于无法保证修改请求是按顺序到达Elasticsearch的,需要防止低版本的修改请求把高版本的数据覆盖掉,这时就需要采用乐观锁进行并发控制。如果你在关系数据库或者Java的多线程编程中使用过乐观锁,你应该会知道乐观锁的实现是基于版本号或者时间戳进行的。例如,初始化时,一条数据的版本号为1,每次这条数据被修改,其版本号就会加1。当修改这条数据的时候,修改请求需要携带当前已知的版本号作为修改条件,如果版本号发生改变,则修改失败。这样做是为了确保高版本的数据不会被低版本的数据覆盖,当多个修改请求携带版本号同时到达服务器时,只有一个请求可以成功。
低版本的Elasticsearch使用了_version字段来实现乐观锁,在Elasticsearch 7.9.1中使用_version进行并发控制会报错。它提供了两个新的字段_seq_no和_primary_term一起来实现乐观锁。假如你查出主键为1的文档的当前_seq_no为26、_primary_term为3,可以按如下方式来实现乐观锁修改数据:
PUT test-3-2-1/_doc/1?if_seq_no=26&if_primary_term=3
{
"id": "1",
"sex": false,
"name": "张三",
"born": "2020-09-11 00:02:20",
"location": {
"lat": 41.12,
"lon": -71.34
}
}
得到以下结果表示修改成功,此时_seq_no已经变为27。
{
"_index": "test-3-2-1",
"_type": "_doc",
"_id": "1",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 27,
"_primary_term": 3
}
如果在修改请求到达之前,这条数据被别的请求修改过了,就会因为_seq_no不匹配而修改失败,失败的返回结果如下:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [26], primary term [3]. Current document has seqNo [27] and primary term [3]",
"index_uuid": "pOjr40KuSWep3dxrhmAitg",
"shard": "0",
"index": "test-3-2-1"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [26], primary term [3]. Current document has seqNo [27] and primary term [3]",
"index_uuid": "pOjr40KuSWep3dxrhmAitg",
"shard": "0",
"index": "test-3-2-1"
},
"status": 409
}
2.3、索引数据的批量写入
如果你在建索引的时候把数据一条一条地发给Elasticsearch,这会导致发送太多的请求,使得建索引的速度变得很慢。在实际项目中经常需要使用可实现批量写入的API来把数据一组一组地提交给Elasticsearch,这样做能大大加快索引的构建速度。下面介绍两种批量建索引的方法以提高数据写入索引的效率。
1.批量提交(bulk)
批量提交的操作一共有4种类型:index、create、update、delete。index操作和create操作都能往索引中添加数据,区别是使用create操作时,文档主键如果在索引中已存在则会报错,使用index操作则会直接覆盖原有的文档。
例如,下面的请求可以一次性向索引test-3-2-1中提交3条类型为index的数据:
POST test-3-2-1/_bulk
{
"index":{
"_id":"3"}}
{
"id":"3","name":"王五","sex":true,"born":"2020-09-14 00:02:20","location":{
"lat":11.12,"lon":-71.34}}
{
"index":{
"_id":"4"}}
{
"id":"4","name":"李四","sex":false,"born":"2020-10-14 00:02:20", "location":{
"lat":11.12,"lon":-71.34}}
{
"index":{
"_id":"5"}}
{
"id":"5","name":"黄六","sex":false,"born":"2020-11-14 00:02:20", "location":{
"lat":11.12,"lon":-71.34}}
其中index是操作类型,_id是主键,后面的JSON数据表示添加的文档。你还可以在同一个请求中添加多种类型的操作,代码如下:
POST test-3-2-1/_bulk
{
"index":{
"_id":"2"}}
{
"id":"2","name":"赵二","sex":true,"born":"2020-09-14 00:02:20","location":{
"lat":11.12,"lon":-71.34}}
{
"create":{
"_id":"4"}}
{
"id":"4","name":"李四","sex":false,"born":"2020-10-14 00:02:20", "location":{
"lat":11.12,"lon":-71.34}}
{
"update":{
"_id":"5"}}
{
"doc" : {
"sex" : "false","born" : "2020-01-01 00:02:20"} }
{
"delete":{
"_id":"5"}}
各个操作返回的结果如下:
{
"took" : 74,
"errors" : true,
"items" : [
{
"index" : {
"_index" : "test-3-2-1",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 31,
"_primary_term" : 5,
"status" : 201
}
},
{
"create" : {
"_index" : "test-3-2-1",
"_type" : "_doc",
"_id" : "4",
"status" : 409,
"error" : {
"type" : "version_conflict_engine_exception",
"reason" : "[4]: version conflict, document already exists (current version [1])",
"index_uuid" : "pOjr40KuSWep3dxrhmAitg",
"shard" : "0",
"index" : "test-3-2-1"
}
}
},
{
"update" : {
"_index" : "test-3-2-1",
"_type" : "_doc",
"_id" : "5",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 32,
"_primary_term" : 5,
"status" : 200
}
},
{
"delete" : {
"_index" : "test-3-2-1",
"_type" : "_doc",
"_id" : "5",
"_version" : 3,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 33,
"_primary_term" : 5,
"status" : 200
}
}
]
}
可以看到,只有第二个请求(create)失败了,因为create操作的文档id在索引中已经存在,所以创建失败。另外,update和delete请求在提交的主键不存在时也会失败。
2.索引重建(reindex)
索引在使用一段时间以后,你可能会想修改索引的静态设置(settings)。但是这些设置(例如主分片的数目、分词器等)又无法直接修改,而重新导入一遍数据又太过麻烦,这个时候索引重建就特别有用。
假如现在已经有一个索引test-3-2-1,它的主分片和副本分片数都是1,你可以新建一个索引newindex-3-1-3把主分片数设置为5,然后把test-3-2-1中的数据转移到新的索引中:
PUT newindex-3-1-3
{
"settings": {
"number_of_shards": "5",
"number_of_replicas": "1"
}
}
POST _reindex
{
"source": {
"index": "test-3-2-1"
},
"dest": {
"index": "newindex-3-1-3"
}
}
出现以下结果表示索引重建完成,reindex批量添加了4条数据到新的索引中:
{
"took" : 256,
"timed_out" : false,
"total" : 4,
"updated" : 0,
"created" : 4,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
3、索引数据的路由规则
在定义索引映射时,你可以按照需要指定主分片的数量,当数据量较大时,通常主分片的数量也会设置得比较多。那么数据写入时是如何决定数据应该被保存到哪个分片上的呢?为了回答这个问题,本节就来谈谈索引数据的路由规则。
3.1、索引数据路由的原理
默认情况下,Elasticsearch会使用以下公式来决定数据被写入的分片的编号。
shard_num = hash(_routing) % num_primary_shards
默认情况下,_routing的值是文档的_id值,也就是根据主键的散列值对分片数进行取模运算,得到写入分片的编号。如果允许主分片数量发生改变,就意味着所有的数据需要重新路由,因此Elasticsearch禁止在索引建立以后修改主分片的数量。实际上,_routing的值可以定义为任意一个字段内容甚至是任意一个字符串。根据业务的需要合理地定义路由值,可以帮助开发人员快速地查找数据。例如,有一个索引存放着全校学生的各科成绩,如果把学生姓名作为_routing的值,你就能巧妙地把同一个学生的成绩数据分发到某一个固定的分片中,这样当你搜索的时候只要带上姓名这个路由值,就可以到指定的分片上查询到这个学生的数据,会直接跳过其他分片,从而提高查询性能。
注意:虽然手动指定路由值可以减少查询使用的分片数,但是这有可能引发大量的数据被路由到少数几个分片,而其余的很多分片数据量太少,使得分片的大小不均匀。Elasticsearch为了缓解这个问题,提供了索引分区的配置,允许使用同一路由的数据被分发到多个分片而不是一个分片,该配置需要在索引的index.routing_partition_size中进行设置。
当你给索引配置index.routing_partition_size以后,数据分片编号的计算公式就变成了以下形式:
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards
这时候,分片编号的计算结果改为由路由值和主键共同决定。对于同一个_routing,hash(_id)% routing_partition_size的可能结果有routing_partition_size种,routing_partition_size值越大,数据在分片上的分发就越均匀,代价是搜索时需要查找更多的分片。这样一来,同一种路由的数据会被分发到routing_partition_size种不同的分片上,从而缓解了同一路由的数据全部分发到某一个分片引起数据存储过于集中的问题。但是routing_partition_size值一旦大于1,由于join字段要求同一路由值的文档必须写入同一个分片,导致join字段在索引中不可使用。
3.2、使用自定义路由分发数据
为了能使用自定义路由完成数据的分发,应先建立一个映射,代码如下:
PUT test-3-3-2
{
"settings": {
"number_of_shards": "3",
"number_of_replicas": "1"
},
"mappings": {
"_routing": {
"required": true
}
}
}
这里创建了一个带有3个主分片的索引,使用到了元字段_routing,规定了对该索引数据进行增删改查时必须提供路由值。先添加一条数据,代码如下:
POST test-3-3-2/_doc/1?routing=张三&refresh=true
{
"id": "1",
"name": "张三",
"subject": "语文",
"score":100
}
由于该请求使用姓名字段作为路由值写入索引,查询时也需要带上这个路由值,否则会报错:
GET test-3-3-2/_doc/1?routing=张三
从下面的返回结果可以看到,查询结果中元字段_routing的值确实是“张三”:
{
"_index": "test-3-3-2",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"_routing": "张三",
"found": true,
"_source": {
"id": "1",
"name": "张三",
"subject": "语文",
"score": 100
}
}
当修改数据时,也需要带上这个路由值:
POST test-3-3-2/_update/1?routing=张三&refresh=true
{
"doc": {
"score": 120
}
}
删除索引则代码变为如下形式:
DELETE test-3-3-2/_doc/1?routing=张三
当检索数据时,如果带上这个路由值,可以跳过无关的分片,能减少资源的占用和加快查询速度:
GET test-3-3-2/_search?routing=张三
{
"query": {
"match_all": {
}
}
}
以上是一个简单的match_all查询,它会查询索引的全部文档。带上routing值“张三”表示只到该路由值对应的分片上去搜索数据。如果你想确定某个路由值会检索到哪个分片,可以使用REST端点,代码如下:
GET test-3-3-2/_search_shards?routing=张三
部分返回值如下:
…
"shards": [
[
{
"state": "STARTED",
"primary": true,
"node": "EijMhNrDSoy-Bbmo3W8JGA",
"relocating_node": null,
"shard": 1,
"index": "test-3-3-2",
"allocation_id": {
"id": "mTANUJ1eR4ys22iF-sFduw"
}
}
]
]
这说明提供“张三”这个路由值只需要到1号主分片上去搜索数据。如果不提供路由值,也就是默认的情况,则会得到以下结果:
…
"shards": [
[
{
"state": "STARTED",
"primary": true,
"node": "EijMhNrDSoy-Bbmo3W8JGA",
"relocating_node": null,
"shard": 0,
"index": "test-3-3-2",
"allocation_id": {
"id": "_utF3Kz9TnuR7tSDQOIXfw"
}
}
],
[
{
"state": "STARTED",
"primary": true,
"node": "EijMhNrDSoy-Bbmo3W8JGA",
"relocating_node": null,
"shard": 1,
"index": "test-3-3-2",
"allocation_id": {
"id": "mTANUJ1eR4ys22iF-sFduw"
}
}
],
[
{
"state": "STARTED",
"primary": true,
"node": "EijMhNrDSoy-Bbmo3W8JGA",
"relocating_node": null,
"shard": 2,
"index": "test-3-3-2",
"allocation_id": {
"id": "9UskrsM0Sv-YaM4ZNduAIA"
}
}
]
]
这说明不提供路由值时,查询会检索全部主分片(3个)。可见自定义路由能够减少查询的分片数量,从而加快查询速度。在实际项目中巧妙地使用这个功能,对提升查询性能是大有好处的。
4、索引的别名
想象这样一种场景,假如有一个索引只有一个主分片,但是时间久了以后数据量越来越大,你决定为索引扩容,可是又不愿意重建索引。一个解决问题的办法就是,你可以创建一个新的索引保存新的数据,然后取一个别名同时指向这两个索引,这样在检索时使用别名就可以同时检索到两个索引的数据。本节就来谈谈索引别名的使用。
4.1、别名的创建和删除
先来新建两个索引logs-1和logs-2并添加数据:
POST logs-1/_doc/10001
{
"visittime": "10:00:00",
"keywords": "[世界杯]",
"rank": 18,
"clicknum": 13,
"id": 10001,
"userid": "2982199073774412",
"key": "10001"
}
POST logs-2/_doc/10002
{
"visittime": "11:00:00",
"keywords": "[奥运会]",
"rank": 11,
"clicknum": 2,
"id": 10002,
"userid": "2982199023774412",
"key": "10002"
}
添加一个索引别名logs指向这两个索引:
POST /_aliases
{
"actions": [
{
"add": {
"index": "logs-1",
"alias": "logs"
}
},
{
"add": {
"index": "logs-2",
"alias": "logs"
}
}
]
}
查看刚才创建的别名logs包含哪些索引,可以用下面的代码:
GET _alias/logs
如果要删除索引logs-1的别名,可以使用以下代码:
POST /_aliases
{
"actions" : [
{
"remove": {
"index" : "logs-1", "alias" : "logs" } }
]
}
你也可以使用通配符匹配一组索引,给所有以logs为前缀的索引添加别名logs,可以用下面的代码:
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "logs*", "alias" : "logs" } }
]
}
4.2、别名配合数据过滤
配合使用别名和数据过滤可以达到类似于数据库视图的效果,可以把查询条件放入别名,这样在搜索别名时会自动带有查询条件,能起到数据自动过滤的作用。例如:
POST /_aliases
{
"actions": [
{
"add": {
"index": "logs*",
"alias": "logs",
"filter": {
"range": {
"clicknum": {
"gte": 10
}
}
}
}
}
]
}
上面的请求在别名logs中配置了一个range过滤器,它表示只查询clicknum大于等于10的数据。下面来进行简单的别名查询以查看效果。
POST logs/_search
{
"query": {
"match_all": {
}
}
}
以下查询结果中只有一条数据,这说明别名配置的过滤器起作用了:
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "logs-1",
"_type" : "_doc",
"_id" : "10001",
"_score" : 1.0,
"_source" : {
"visittime" : "10:00:00",
"keywords" : "[世界杯]",
"rank" : 18,
"clicknum" : 13,
"id" : 10001,
"userid" : "2982199073774412",
"key" : "10001"
}
}
]
}
4.3、别名配合数据路由
你可以给索引别名指定路由值,使用别名读写数据时就会自动携带配置的路由参数,代码如下:
POST /_aliases
{
"actions": [
{
"add": {
"index": "logs-1",
"alias": "logs",
"routing": "1"
}
}
]
}
你可以在搜索时和索引时配置不同的路由值,需注意的是,搜索时使用的路由值可以是多个,索引时使用的路由值只能有一个,因为一条数据只能被写入一个分片,代码如下:
POST /_aliases
{
"actions": [
{
"add": {
"index": "logs-1",
"alias": "logs",
"search_routing": "1,2",
"index_routing": "2"
}
}
]
}
当一个索引别名指向多个索引时,如果直接使用别名写入数据会出错,原因是Elasticsearch并不知道你到底想写入哪一个索引。如果想使用别名写入数据,需要指定当前写入的具体索引的名称,代码如下:
POST /_aliases
{
"actions": [
{
"add": {
"index": "logs-1",
"alias": "logs",
"is_write_index": true
}
},
{
"add": {
"index": "logs-2",
"alias": "logs"
}
}
]
}
上述代码中的配置is_write_index为true表示当前向索引别名logs写入的索引是logs-1,如果需要写入logs-2,则需要指定它的is_write_index属性为true,并将logs-1的is_write_index属性设置为false。
5、滚动索引
当有一个索引数据量太大时,如果继续写入数据可能会导致分片容量过大,查询时会因内存不足引起集群崩溃。为了避免所有的数据都写入同一个索引,可以考虑使用滚动索引。滚动索引需要配合索引别名一起使用,可实现把原先写入一个索引的数据自动分发到多个索引中。
先创建一个索引log1,它有一个别名logs-all:
PUT /log1
{
"aliases": {
"logs-all": {
}
}
}
然后使用别名往log1中写入数据:
PUT logs-all/_doc/1?refresh
{
"visittime": "10:00:00",
"keywords": "[世界杯]",
"rank": 18,
"clicknum": 13,
"id": 10001,
"userid": "2982199073774412",
"key": "10001"
}
PUT logs-all/_doc/2?refresh
{
"visittime": "11:00:00",
"keywords": "[杯]",
"rank": 20,
"clicknum": 12,
"id": 1121,
"userid": "298219d9073774412",
"key": "2"
}
现在来为别名logs-all指定一个滚动索引,如果条件成立,就把新数据写入log2:
POST /logs-all/_rollover/log2
{
"conditions": {
"max_age": "7d",
"max_docs": 1,
"max_size": "5gb"
}
}
上面的滚动索引配置的条件是,如果往别名logs-all中写入的索引数据量大于等于1,或者主分片总大小超过5GB,或者创建索引的时间长度超过7天,就把新的数据写入新索引log2。该请求会返回滚动索引的执行结果,结果如下:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"old_index" : "log1",
"new_index" : "log2",
"rolled_over" : true,
"dry_run" : false,
"conditions" : {
"[max_size: 5gb]" : false,
"[max_docs: 1]" : true,
"[max_age: 7d]" : false
}
}
从请求返回的结果可以看出,此时max_docs条件已成立,一个新的索引log2已经创建出来了,此时别名logs-all已经指向了log2,log1的别名已经被删除。因此,如果继续往别名logs-all中写数据,数据会被写入log2。
以此类推,如果log2的数据太多,你又可以使用滚动索引把新数据写入索引log3。如果你觉得每次为新索引指定名称太麻烦,你可以为第一个索引指定一个有规律的名称,例如log-000001,那么使用滚动索引时,新的索引会自动生成名称,在前一个的尾数上直接加1,代码如下:
PUT /log-000001
{
"aliases": {
"logseries": {
}
}
}
POST /logseries/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 1,
"max_size": "5gb"
}
}
该请求返回的新索引名称为log-000002,但由于此时3个滚动条件都没有被触发,新的索引log-000002实际上未被创建,返回结果如下:
{
"acknowledged" : false,
"shards_acknowledged" : false,
"old_index" : "log-000001",
"new_index" : "log-000002",
"rolled_over" : false,
"dry_run" : false,
"conditions" : {
"[max_size: 5gb]" : false,
"[max_docs: 1]" : false,
"[max_age: 7d]" : false
}
}
注意:当滚动索引的3个条件均未被触发时,新的索引不会被创建,向别名写入数据时还是会写入旧的索引。滚动索引的触发条件到底何时能成立,对于这一点只能够使用轮询的机制定时调用_rollover端点来做尝试。如果轮询的间隔设置得太大,会导致许多数据没有被及时滚动到新索引中。
6、索引的状态管理
Elasticsearch为开发人员提供了一组API用于对索引的状态进行管理,这些管理操作包括:清空缓存(clear cache)、刷新索引(refresh index)、冲洗索引(flush index)、强制合并(force merge)、关闭索引(close index)、冻结索引(freeze index)。本节就来探讨它们的使用方法。
6.1、清空缓存
Elasticsearch之所以能够成为高性能的搜索引擎是因为它拥有强大的缓存机制,可将很多数据直接放在内存中,可以大大提升查询速度。Elasticsearch使用的缓存分为3种类型:节点的查询缓存、分片的请求缓存和字段数据(fielddata)缓存。fielddata是一种缓存于内存中的数据结构,它是一个文档主键指向每个字段数据的映射,类似于关系数据库的表结构。每个字段的数据缓存在fielddata中用于高性能的排序和聚集统计。
清空索引test-3-2-1的某一类缓存,可使用以下代码:
//清空字段数据缓存
POST /test-3-2-1/_cache/clear?fielddata=true
//清空节点的查询缓存
POST /test-3-2-1/_cache/clear?query=true
//清空分片的请求缓存
POST /test-3-2-1/_cache/clear?request=true
如果想清空索引test-3-2-1的全部缓存可直接把参数去掉,代码如下:
POST /test-3-2-1/_cache/clear
如果要清空所有的索引缓存可以使用以下代码:
POST /_cache/clear
6.2、刷新索引
当外部数据写入索引时,数据并不会直接提交到磁盘上,因为提交数据的过程成本高昂,会按照一定的流程将数据周期性地提交到磁盘上进行持久化,如下图所示:

整个过程的实现可以分为3个步骤:
- 将索引请求的文档数据写入内存中的缓冲区和事务日志,此时这些数据还不能被搜索到。
- 刷新索引数据,把缓冲区的数据写入文件系统缓存,此时数据已能够被搜索到。
- 冲洗索引数据,把文件系统缓存中的数据写入磁盘并清空事务日志,完成数据提交。
可见,索引经过刷新操作后,之前的所有写入操作就能够在内存中生效,最新的数据就可以被检索到。默认情况下,Elasticsearch会对过去30s内被搜索的索引提供自动化刷新机制,刷新间隔默认是1s,其可以在index.refresh_interval的索引配置中进行修改。通过调用REST端点,可以完成对索引的手动刷新,例如:
POST /test-3-2-1/_refresh
如果想刷新全部索引,则可直接使用以下代码:
POST /_refresh
注意:刷新索引是比较耗费性能的操作,在实际项目中应尽量避免手动刷新索引,直接使用默认的刷新机制即可。
6.3、冲洗索引
如果说刷新索引就是把数据写入内存的话,那么冲洗索引就是把数据存储到外存。由于把数据逐条存储到外存比较耗费性能,Elasticsearch使用了事务日志(translog)来记录每个写入的请求信息。冲洗索引时,Elasticsearch会一次性把文件系统缓存的数据写入磁盘,然后把事务日志清空,这个过程默认是每隔一段时间自动完成的。如果Elasticsearch突然宕机,它会在下次启动时自动将事务日志中的数据恢复到磁盘上,从而最大限度地减少数据丢失。通常开发人员并不需要手动完成冲洗索引,使用默认的配置即可。
冲洗索引test-3-2-1的操作如下:
POST /test-3-2-1/_flush
冲洗全部索引的操作如下:
POST /_flush
6.4、强制合并
一个Elasticsearch的索引可以有一到多个主分片,每个主分片是一个Lucene索引,一个Lucene索引又包含一到多个段(segment)。当删除索引文档时,数据不会彻底从磁盘上删除,计算机只会对删除的文档做一个删除标记。而强制合并索引的段时,会把分片内部很多零碎的小段合并成大段并去除被删除的文档,这样做的好处是每个分片中的段会减少并会腾出被删除文档所占据的外存空间。段的强制合并通常比较耗时,它会自动在后台进行,必要时手动触发段强制合并也是有意义的。
触发一次索引test-3-2-1的强制合并,操作代码如下:
POST /test-3-2-1/_forcemerge
你也可以触发所有索引进行强制合并,操作代码如下:
POST /_forcemerge
6.5、关闭索引
部分索引在业务中不需要使用但是又不能够将其直接删除,这时可以使用关闭索引的操作使索引不再接收读写请求。索引被关闭后,该索引在集群中相关的内部数据也会被销毁,这有利于减少集群的负担。
关闭索引test-3-2-1的操作如下:
POST /test-3-2-1/_close
如果你想把它重新打开,则可以使用以下代码:
POST /test-3-2-1/_open
6.6、冻结索引
如果集群中存在一些旧索引,不再有新的数据写入它们,查询频率很低但是又不能直接关闭它们,因为偶尔存在查询的需要,这时候可以考虑使用冻结索引。索引一旦被冻结,就会变成只读的状态,不可写入新的数据,查询时Elasticsearch会实时构建冻结索引的每个分片的瞬态数据结构,并在搜索完成后立即丢弃这些数据结构。这样做可以避免大量的旧索引占用集群的缓存,拖累整体的查询性能。由于被冻结索引查询的频率很低,即使响应速度稍慢也是可以接受的。
冻结索引test-3-2-1的操作如下:
POST /test-3-2-1/_freeze
解除冻结的操作如下:
POST /test-3-2-1/_unfreeze
7、索引的块
索引的块(blocks)能够阻塞某个索引上的读请求或者写请求,使得索引成为只读或者只写的状态。你可以通过改变一些索引的动态设置来配置索引的块,具体的配置信息如下表所示:
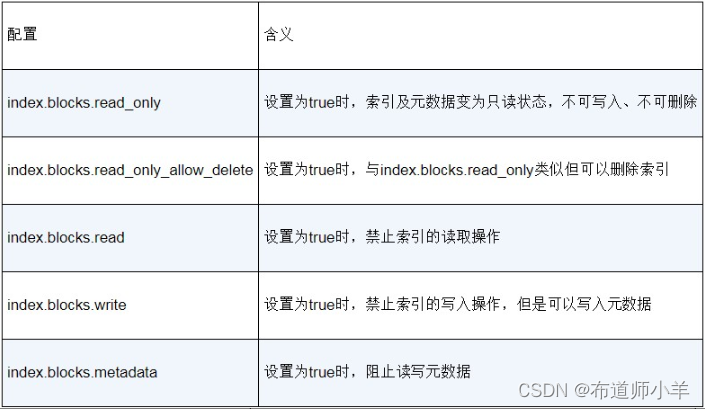
下面来演示其中几种配置的效果,先把索引test-3-2-1设置为只读状态:
PUT test-3-2-1/_settings
{
"index.blocks.read_only":"true"
}
此时如果写入数据就会报错:
{
"error" : {
"root_cause" : [
{
"type" : "cluster_block_exception",
"reason" : "index [test-3-2-1] blocked by: [FORBIDDEN/5/index read-only (api)];"
}
],
"type" : "cluster_block_exception",
"reason" : "index [test-3-2-1] blocked by: [FORBIDDEN/5/index read-only (api)];"
},
"status" : 403
}
要取消只读状态只需要把配置改为false:
PUT test-3-2-1/_settings
{
"index.blocks.read_only":"false"
}
再把索引设置为禁止写入:
PUT test-3-2-1/_settings
{
"index.blocks.write":"true"
}
此时,索引已无法写入,但是可以写入元数据,例如关闭索引:
POST /test-3-2-1/_close
8、索引模板
当需要为同一类索引应用相同的配置、映射、别名时,如果每次创建索引都逐一配置会有些麻烦。索引模板的出现正是为了简化这种操作,使用索引模板你可以方便地为某一类索引自动配置某些共同的参数。本节就来探讨索引模板的使用方法。
8.1、使用索引模板定制索引结构
假如你想在Elasticsearch中创建两个索引service-log1和service-log2,这两个索引分别记录了不同年份的服务日志数据,它们的映射结构是相同的,也具有相同的分片数和别名。为了实现这一效果,你可以先创建一个索引模板service-template。
PUT _index_template/service-template
{
"index_patterns": [
"service-log*"
],
"template": {
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"serviceid": {
"type": "keyword"
},
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
},
"aliases": {
"service-logs": {
}
}
},
"priority": 200,
"version": 3,
"_meta": {
"description": "my custom"
}
}
在上述的配置中,index_patterns用于设置索引模板可以匹配的索引名,这里配置了所有以service-log开头的索引都会“命中”此模板。该模板还配置了索引的分片数、副本分片数、字段映射和别名。priority用来设置模板的优先级,其值越大优先级越高。version表示版本号,_meta可以保存一些元数据。当模板service-template已经存在时,再次编辑模板配置并发送上述请求可以修改模板的内容。
如果想查询索引模板的信息,可以使用以下代码:
GET /_index_template/service-template
有了索引模板,创建索引时,一旦索引名被索引模板匹配就会自动加载模板的配置到索引映射中。例如,创建一个索引service-log1:
PUT service-log1
创建成功后,查看该索引的配置信息:
GET service-log1
可以从上述代码运行结果中看到模板中的配置已经自动在service-log1中得到应用。如果你想在索引service-log2中自定义某些配置,可以在创建索引映射的时候指明,这样就能把模板的配置覆盖掉:
PUT service-log2
{
"settings": {
"number_of_shards": "3",
"number_of_replicas": "2"
},
"mappings": {
"properties": {
"level": {
"type": "text"
},
"serviceid": {
"type": "long"
}
}
}
}
上述代码在索引service-log2中设置了分片数和每个主分片的副本分片数分别为3和2,添加了一个字段level,又把serviceid字段设置为long类型,运行上述代码后可以发现索引映射中的配置确实成功覆盖掉了索引模板中的配置。查看service-log2的映射结果如下:
{
"service-log2" : {
"aliases" : {
"service-logs" : {
}
},
"mappings" : {
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"created_at" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss"
},
"level" : {
"type" : "text"
},
"serviceid" : {
"type" : "long"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1601965153703",
"number_of_shards" : "3",
"number_of_replicas" : "2",
"uuid" : "0tEAWaSkS3Cqh3LioDJfbA",
"version" : {
"created" : "7090199"
},
"provided_name" : "service-log2"
}
}
}
}
如果需要删除索引模板,可以使用以下代码:
DELETE /_index_template/service-template
注意:Elasticsearch内置了两个索引模板分别匹配名称符合logs-*-和metrics--*的索引。在创建索引和索引模板时要特别注意不要匹配错索引模板,以避免最后索引配置的效果达不到预期。
8.2、使用模板组件简化模板配置
按照上节介绍的方法你已经可以快速地创建索引模板,并可以把配置自动应用到匹配的索引中了,但是这样做会使得索引模板的配置内容较多。为了简化索引模板中的配置内容,你可以把常规的索引设置、映射等内容写成可复用的模板组件,然后在索引模板中引用这些组件,这样模板中的配置内容就会非常简洁,便于移植和管理。
先创建一个组件模板comp1,它拥有字段content:
PUT _component_template/comp1
{
"template": {
"mappings": {
"properties": {
"content": {
"type": "text"
}
}
}
}
}
查看组件模板的端点:
GET _component_template/comp1
再创建一个组件模板comp2,它配置了别名loginfo,主分片数为3,每个主分片的副本分片数为2:
PUT _component_template/comp2
{
"template": {
"settings": {
"number_of_shards": "3",
"number_of_replicas": "2"
},
"aliases": {
"loginfo": {
}
}
}
}
然后创建一个索引模板infotmp,把上述两个组件模板加载到索引模板中,索引模板会匹配所有名称以loginfo开头的索引:
PUT _index_template/infotmp
{
"index_patterns": ["loginfo*"],
"priority": 200,
"composed_of": ["comp1", "comp2"]
}
可以创建一个索引loginfo1然后查看结果:
PUT loginfo1
GET loginfo1
从以下返回结果可以看出索引loginfo1已经获得了两个组件模板中配置的映射、别名和分片数:
{
"loginfo1" : {
"aliases" : {
"loginfo" : {
}
},
"mappings" : {
"properties" : {
"content" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1601967493187",
"number_of_shards" : "3",
"number_of_replicas" : "2",
"uuid" : "zbvp-P-SSAq7hXUGFLl1Aw",
"version" : {
"created" : "7090199"
},
"provided_name" : "loginfo1"
}
}
}
}
如果要删除索引模板infotmp以及组件模板comp1和comp2,可以使用以下代码:
DELETE /_index_template/infotmp
DELETE _component_template/comp1
DELETE _component_template/comp2
注意:当多个组件模板中存在重复的配置内容时,后面的组件模板配置会覆盖前面的组件模板配置。如果一个组件模板正在被某个索引模板所引用,则这个组件模板不可以被删除。
9、索引的监控
如果你想知道索引运行的状态和统计指标,就需要用到本节介绍的Elasticsearch监控端点。本节将介绍索引的各种监控端点,内容包括监控索引的健康状态,监控索引分片的段数据、分配和恢复,监控索引的统计指标。
9.1、监控索引的健康状态
如果你想知道索引test-3-2-1的健康状态可以使用索引的cat端点,代码如下:
GET /_cat/indices/test-3-2-1?v&format=json
得到的返回信息如下:
[
{
"health" : "yellow",
"status" : "open",
"index" : "test-3-2-1",
"uuid" : "mTB_AcxlRTGfQE4ec_TtiQ",
"pri" : "1",
"rep" : "1",
"docs.count" : "4",
"docs.deleted" : "1",
"store.size" : "24.3kb",
"pri.store.size" : "24.3kb"
}
]
从上述返回结果可以看出索引的健康状态、运行状态、主分片和每个主分片的副本分片的数量、现有文档总数、删除文档总数、索引占用的空间大小、主分片占用的空间大小。由于该索引运行在单节点上,副本分片无法分配,所以主分片占用的空间和索引占用的总空间大小是一样的。索引的健康状态分为3种,如果存在主分片没有得到分配,则健康状态为red;如果存在副本分片没有得到分配,则健康状态为yellow;如果主分片和副本分片都得到了分配,则健康状态为green。为了让副本分片得到分配,在本地再启动一个节点node-2,代码如下:
.\elasticsearch.bat -Epath.data=data2 -Epath.logs=log2 -Enode.name=node-2
再次查看索引test-3-2-1的健康状态,从下述返回结果可以发现,副本分片成功分配后,索引的健康状态变为green,索引占用的空间大小增大一倍:
[
{
"health" : "green",
"status" : "open",
"index" : "test-3-2-1",
"uuid" : "mTB_AcxlRTGfQE4ec_TtiQ",
"pri" : "1",
"rep" : "1",
"docs.count" : "4",
"docs.deleted" : "1",
"store.size" : "48.6kb",
"pri.store.size" : "24.3kb"
}
]
9.2、监控索引分片的段数据
前面讲过,一个索引的分片实际上是一个Lucene索引,一个Lucene索引是由很多个段(segment)构成的,你可以使用以下请求查看索引test-3-2-1分片内部的段信息:
GET /_cat/segments/test-3-2-1?v&format=json
得到的每个分片中的段信息如下:
[
{
"index" : "test-3-2-1",
"shard" : "0",
"prirep" : "r",
"ip" : "127.0.0.1",
"segment" : "_0",
"generation" : "0",
"docs.count" : "0",
"docs.deleted" : "1",
"size" : "6kb",
"size.memory" : "0",
"committed" : "true",
"searchable" : "false",
"version" : "8.6.2",
"compound" : "true"
},
……
也可以使用_segments端点按照分片进行查看,这种方法更加直观:
GET /test-3-2-1/_segments
得到的每个分片包含的段信息如下:
"indices" : {
"test-3-2-1" : {
"shards" : {
"0" : [
{
"routing" : {
"state" : "STARTED",
"primary" : true,
"node" : "pbBVcOsqST6V01O1uXYNRw"
},
"num_committed_segments" : 4,
"num_search_segments" : 2,
"segments" : {
"_0" : {
"generation" : 0,
"num_docs" : 0,
"deleted_docs" : 1,
"size_in_bytes" : 6220,
"memory_in_bytes" : 0,
"committed" : true,
"search" : false,
"version" : "8.6.2",
"compound" : true,
"attributes" : {
"Lucene50StoredFieldsFormat.mode" : "BEST_SPEED"
}
},
……
随着数据的不断写入、修改和删除,分片中的段信息会越来越多,这也是索引需要定期进行段合并的原因。
9.3、监控索引分片的分配
你可以像上节节中介绍的那样,使用_cat/shards查看索引的每个分片的分配结果,也可以使用_shard_stores端点查看索引中已经分配过的分片所在的位置,不显示未分配的分片所在的位置:
GET /test-3-2-1/_shard_stores
使用这个端点得到的分片存储的信息更加详细,还包括分配id、分片所在节点的详细信息,具体如下:
{
"indices" : {
"test-3-2-1" : {
"shards" : {
"0" : {
"stores" : [
{
"pbBVcOsqST6V01O1uXYNRw" : {
"name" : "node-1",
"ephemeral_id" : "zbKz3VxERVOyTvq3pdI_nw",
"transport_address" : "127.0.0.1:9300",
"attributes" : {
"ml.machine_memory" : "16964157440",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "20"
}
},
"allocation_id" : "SrHQqwYKTJmxtSYK-Mi6hQ",
"allocation" : "primary"
}
]
}
}
}
}
}
9.4、监控索引分片的恢复
你可以使用_cat/recovery端点查看分片的恢复情况,本小节介绍使用_recovery端点查看分片恢复的更多细节信息。例如:
GET /test-3-2-1/_recovery
在以下的这个端点的返回结果中,除了有分片号(id)、恢复类型(type)、起始时间(start time in millis)、结束时间(stop time in millis)、数据来源(source)和目标节点(target)这些常规的字段之外,还包含分片恢复过程中的统计信息,例如恢复了多少个文件(files.total)、占用多大空间(total in bytes)、恢复的事务日志的个数(translog)等。
{
"test-3-2-1" : {
"shards" : [
{
"id" : 0,
"type" : "EXISTING_STORE",
"stage" : "DONE",
"primary" : true,
"start_time_in_millis" : 1608079382641,
"stop_time_in_millis" : 1608079383111,
"total_time_in_millis" : 469,
"source" : {
"bootstrap_new_history_uuid" : false
},
"target" : {
"id" : "pbBVcOsqST6V01O1uXYNRw",
"host" : "127.0.0.1",
"transport_address" : "127.0.0.1:9300",
"ip" : "127.0.0.1",
"name" : "node-1"
},
"index" : {
"size" : {
"total_in_bytes" : 11631,
"reused_in_bytes" : 11631,
"recovered_in_bytes" : 0,
"percent" : "100.0%"
},
"files" : {
"total" : 10,
"reused" : 10,
"recovered" : 0,
"percent" : "100.0%"
},
"total_time_in_millis" : 2,
"source_throttle_time_in_millis" : 0,
"target_throttle_time_in_millis" : 0
},
"translog" : {
"recovered" : 0,
"total" : 0,
"percent" : "100.0%",
"total_on_start" : 0,
"total_time_in_millis" : 405
},
"verify_index" : {
"check_index_time_in_millis" : 0,
"total_time_in_millis" : 0
}
}
]
}
}
9.5、监控索引的统计指标
Elasticsearch提供了一个统计指标的查看端点,通过该端点可以查看每个索引的统计数据,其调用方法如下:
GET /test-3-2-1,mysougoulog/_stats
以上这个请求查询了索引test-3-2-1和mysougoulog的统计指标,返回的结果如下:
{
"_shards" : {
"total" : 12,
"successful" : 6,
"failed" : 0
},
"_all" : {
"primaries" : {
……
},
"total" : {
……
}
},
"indices" : {
"mysougoulog" : {
"uuid" : "4uU50jAeS_G_s3fzmLgRAw",
"primaries" : {
"docs" : {
"count" : 2,
"deleted" : 0
},
……
},
"total" : {
"docs" : {
"count" : 2,
"deleted" : 0
},
……
}
}
}
}
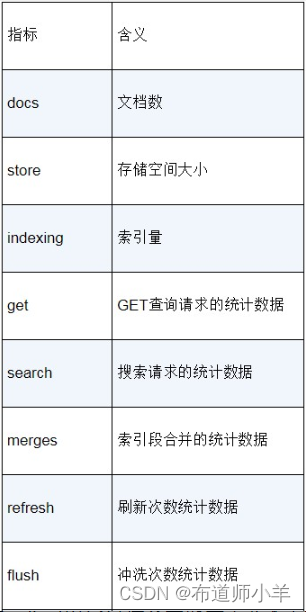
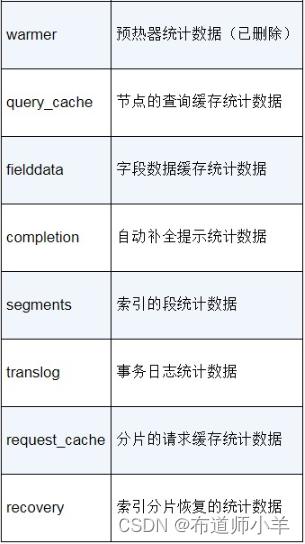
其中,_all中的内容是两个索引的统计数据,indices里面包含每个索引单独的统计数据。在每个索引的统计数据中,又包含主分片(primaries)的统计数据和全部分片(total)的统计数据。stats端点的索引的统计数据的指标如下表所示:
如果觉得返回的指标太多,你可以通过传参来指定需要查看的统计指标,以下请求只查看索引段合并与刷新次数的统计数据:
GET /test-3-2-1,mysougoulog/_stats/merge,refresh
10、控制索引分片的分配
在3.4节中讲述了如何控制索引分片的分配,但通过cluster.routing.allocation.*设置后,该配置会对整个集群的所有索引有效,本节来探讨如何单独控制某个索引分片的分配。
与之前一样,启动3个节点并在启动时携带自定义属性,让它们成为控制分片分配时的过滤条件。
.\elasticsearch.bat -Epath.data=data -Epath.logs=logs -Enode.name=node-1 -Enode.attr.zone=left
.\elasticsearch.bat -Epath.data=data2 -Epath.logs=log2 -Enode.name=node-2 -Enode.attr.zone=right
.\elasticsearch.bat -Epath.data=data3 -Epath.logs=log3 -Enode.name=node-3 -Enode.attr.zone=top
这样就为每个节点携带了一个zone属性,值分别为left、right和top。现在新建一个索引index-allocation。
PUT index-allocation
{
"settings": {
"number_of_shards": "3",
"number_of_replicas": "1"
}
}
配置该索引的分片只分配到zone值为left和right的节点上,需注意该配置只对索引index-allocation有效:
PUT index-allocation/_settings
{
"index.routing.allocation.include.zone": "left,right"
}
查看分片的分配结果,从以下结果可以看出分片果然只分配到了node-1和node-2上:
GET _cat/shards/index-allocation?v
index shard prirep state docs store ip node
index-allocation 1 p STARTED 0 208b 127.0.0.1 node-2
index-allocation 1 r STARTED 0 208b 127.0.0.1 node-1
index-allocation 2 r STARTED 0 208b 127.0.0.1 node-2
index-allocation 2 p STARTED 0 208b 127.0.0.1 node-1
index-allocation 0 r STARTED 0 208b 127.0.0.1 node-2
index-allocation 0 p STARTED 0 208b 127.0.0.1 node-1
注意:如果索引的分配过滤条件与集群的分配过滤条件发生冲突,则索引在分配分片时会应用先配置的那个条件,读者可以自行测试其效果。
11、小结
介绍了Elasticsearch中很关键的知识点——索引的使用方法,主要内容总结如下:
- 既可以使用各种字段类型手动定义字段映射来设置索引结构,也可以使用动态映射自动生成索引结构。动态映射提供了索引中未定义字段的自动化识别功能,让索引的映射结构可以自动扩展,并且这种识别方式是可自定义的。
- Elasticsearch提供了对索引进行增删改查的REST端点,修改时可以使用乐观锁进行并发控制,批量写入数据可以大大提高索引的构建效率。
- 索引对写入的数据会自动进行默认的数据路由,通过手动调整数据的路由值可以把数据分发到指定的分片中,这样做可以加快查询速度,但也可能导致各分片中的数据分布不均匀。
- 使用索引别名可以同时检索多个索引的数据,别名中可以配置过滤条件和路由规则,使得用别名查询数据时能够得到一种类似视图的效果。
- 使用滚动索引可以把一个索引的数据在达到一定条件时分发到多个索引中。为了能及时触发滚动索引,需要使用合适的定时任务检测使用滚动索引的时机。
- 索引的状态管理包括对索引的状态、缓存进行调整,有一些操作会在后台自动进行,要根据每个操作的影响和特点决定执行相关操作的时机。
- 配置索引的块可以限制索引的部分功能,可以让索引变为只读、只写、禁止读写元数据等状态。
- 使用索引模板可以为同一类索引自动配置好映射字段、别名、设置信息等,这样做可以大大提高创建索引映射的效率,以及减少很多重复的工作。使用模板组件可以简化索引模板的配置内容。
- Elasticsearch提供了各种不同的端点来监控索引的健康状态、统计指标等,在需要的时候调用它们能及时地知道索引的运行情况。
- 可以使用index.routing.allocation配置来设置某个索引分片分配的位置,这些配置能够帮助开发人员主动选择分片所在的节点。