目录
链表理论基础
鏈表型態
- 單向Link-List
- 每個節點不知道上一個節點只知道下一個節點在哪
- 雙向Link-List
- 每個節點都知道自己的上一個節點也知道下一個節點在哪
- 循環Link-List
- 最後一個節點不是指向Null 而是指向head形成循環
鏈表的存儲
- 因為每個節點都是靠指標指向下一個節點,所以可以不連續排列,由指標來串接各個節點,分配機制取決於操作系統的內存管理
鏈表的定義
鏈表可以想像是一串粽子,粽子(資料),綁粽子的繩子(指標),這兩個形成一個節點,假設有連接兩個粽子之間的繩子則可以當作節點的連結。
鏈表程式定義
struct ListNode{ int val; //數據,這個粽子的內餡是甚麼 ListNode *next; //指標,指向下一個值,是否讓我可以連結下一個粽子的重要關鍵 ListNode(int x): val(x), next(NULL){} //節點的構造函數,就有點像是一開始要不要定義這個粽子是甚麼餡料 }可不可以有多個數據,就是粽子的內餡可不可以多一點,可以!
但內餡一多,粽子就會變重,道理一樣,如果數據一多,節點就會佔更多空間
struct ListNode{ int val; //數據,這個粽子的內餡是甚麼 char val2; long val3; ListNode *next; //指標,指向下一個值,是否讓我可以連結下一個粽子的重要關鍵 ListNode(int x,char y, long z): val(x), val2(y), val3(z), next(NULL){} //節點的構造函數,就有點像是一開始要不要定義這個粽子是甚麼餡料 };那可不可以不要有構造函數,可以,但在後續操作時,就不能直接賦值給節點了
//有構造函數的: ListNode* head = new ListNode(1,'2',3); //無構造函數的 ListNode* head = new ListNode(); head->val = 1; head->val2 = '2'; head->val3 = 3;
鏈表的操作
刪除節點
刪除C節點,只要將B節點的指標指向D,並釋放節點C即可
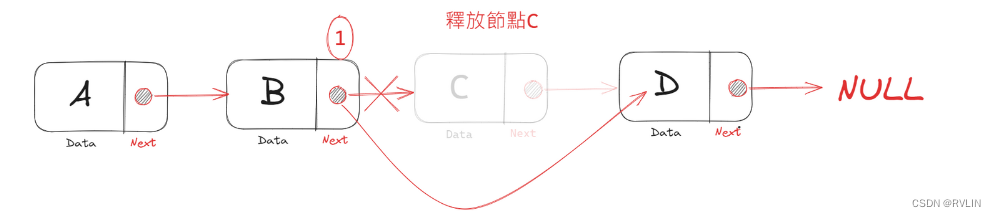
插入節點
插入E節點,將B節點的指向改向E,並將E節點指向C即可

性能分析
鏈表跟數組適合不同的情況
| 資料型態 | 插入/刪除 (時間複雜度) | 查詢(時間複雜度) | 適用場景 |
|---|---|---|---|
| 數組 | $O(n)$ | $O(1)$ | 數據固定 頻繁查詢 較少增刪 |
| 鏈表 | $O(1)$ | $O(n)$ | 數據不固定 較少查詢 頻繁增刪 |
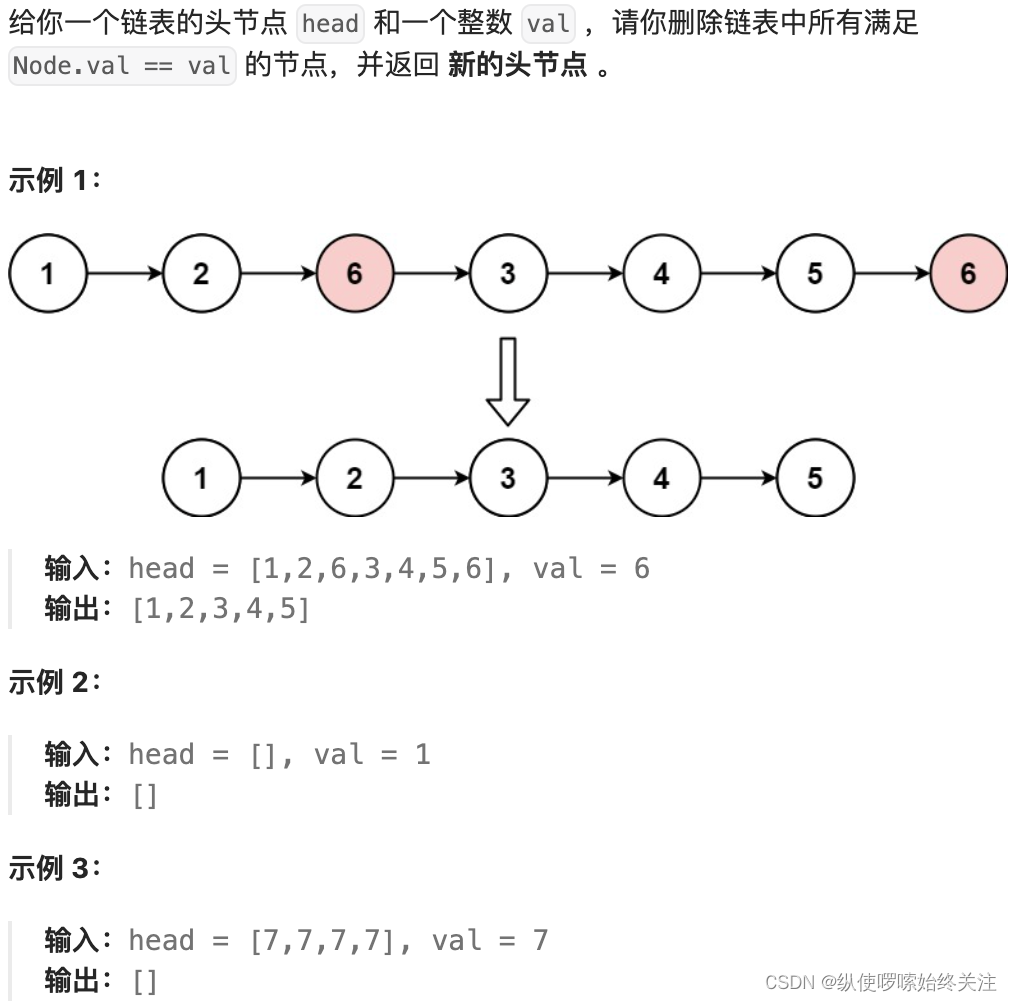
讀題
203.移除链表元素
看完代码随想录之后的想法
卡哥主要是講兩種做法
- 一般的刪除,需要考慮head為target的狀況,簡單來說就是有例外狀況,處理規則會不統一
- 使用虛擬head,建立一個dummyhead,將這個例外狀況給排除,讓所有節點都是使用統一一套規則。
707.设计链表
自己看到题目的第一想法
自己看完後,其實就有想法大致上知道怎麼做了,只是對於C++,我目前只是剛學,對於很多語法並不熟悉(看起來要去看黑馬的教程了),所以就去看代碼隨想錄的講義以及影片講解。
看完代码随想录之后的想法
自己還是太高估自己了,看完之後就有幾處地方沒有想清楚
並沒有去考慮到非法index的產生
AddAtTail //寫成size-- 實際上應該是cur->next != NULL 這樣寫size會被我改變
tmp=nullptr; //看完代碼隨想錄才知道要再加上這個指針,代碼隨想錄解是如下 //delete命令指示释放了tmp指针原本所指的那部分内存, //被delete后的指针tmp的值(地址)并非就是NULL,而是随机值。也就是被delete后, //如果不再加上一句tmp=nullptr,tmp会成为乱指的野指针 //如果之后的程序不小心使用了tmp,会指向难以预想的内存空间
不熟悉語法一開始沒有定義變數
private: int _size; LinkedNode* _dummyHead;
看到這細節沒有注意到,的確一步步做出來了,但感覺自己還是會有很大的進步空間,也算釋然吧
206.反转链表
看完代码随想录之后的想法
一開始看到反轉鏈表的時候,其實有點矇,但聽到卡哥說使用雙指針的方式,並且講解之後,就感覺豁然開朗,在之後說遞迴的寫法就更容易去理解了,對於這個反轉鏈表的實現也比較清晰了
203.移除链表元素 - 實作
思路
使用兩種做法,一個是沒有使用dummyhead另一個有使用dummyhead
- 沒有使用dummyhead
- 判斷head是否為target,如果是的話,將head刪除→ 因為直到head不是target才可以繼續往下,所以使用while回圈進行判斷
- 設置一個cur的node = head,用來遍歷所有節點
- 設置while迴圈判斷cur以及cur→next不為空,遍歷所有節點
- 如果cur→next→val 為target,則將cur→next = cur→next→next;
- 所有節點遍歷完後,return head;
- 有使用dummyhead
- 設置一個dummyhead→next = head,用來遍歷所有節點
- cur = dummyhead
- 設置while迴圈判斷cur以及cur→next不為空,遍歷所有節點
- 如果cur→next→val 為target,則將cur→next = cur→next→next;
- 所有節點遍歷完後,return dummyhead→next (因為dummyhead只是我們用來替代head的節點,所以return時要回傳它所指向的真正的head)
Code
沒有使用dummyhead
錯誤代碼1
class Solution { public: ListNode* removeElements(ListNode* head, int val) { while(head != NULL && head->val == val){ ListNode *tmp = head; head = head->next; delete tmp; } ListNode *cur = head; while(cur != NULL && cur->next != NULL){ if(cur->next->val == val){ ListNode *tmp = cur; -> 應該要是cur-next才是我要儲存的 cur->next = cur->next->next; delete tmp; } else{ cur = cur->next; } } return head; } };正確代碼
class Solution { public: ListNode* removeElements(ListNode* head, int val) { while(head != NULL && head->val == val){ ListNode *tmp = head; head = head->next; delete tmp; } ListNode *cur = head; while(cur != NULL && cur->next != NULL){ if(cur->next->val == val){ ListNode *tmp = cur->next; cur->next = cur->next->next; delete tmp; } else{ cur = cur->next; } } return head; } };使用dummyhead
class Solution { public: ListNode* removeElements(ListNode* head, int val) { ListNode *dummyhead = new ListNode(0,head); ListNode *cur = dummyhead; while(cur != NULL && cur->next != NULL){ if(cur->next->val == val){ ListNode *tmp = cur->next; cur->next = cur->next->next; delete tmp; } else{ cur = cur->next; } } return dummyhead->next; } };
707.设计链表 - 實作
Code
錯誤代碼
class MyLinkedList {
public:
struct ListNode {
int val;
ListNode* next;
ListNode(int x) : val(x), next(nullptr) {}
};
MyLinkedList() {
dummyhead = new ListNode(0);
size = 0;
}
int get(int index) {
if (index > (size - 1) || index < 0) {
return -1;
} //一開始並沒有去考慮到非法index的產生
ListNode *cur = dummyhead->next;
while(index -- ){
cur = cur->next;
}
return cur->val;
}
void addAtHead(int val) {
ListNode *newnode = new ListNode(val);
newnode->next = dummyhead->next;
dummyhead->next = newnode;
size++;
}
void addAtTail(int val) {
ListNode *cur = dummyhead;
ListNode *newnode = new ListNode(val);
while(size--){ //寫成size-- 實際上應該是cur->next != NULL 這樣寫size會被我改變
cur = cur->next;
}
size++;
cur->next = newnode;
}
void addAtIndex(int index, int val) {
if(index > size) return;
if(index < 0) index = 0; //一開始並沒有去考慮到非法index的產生
ListNode *cur = dummyhead;
ListNode *newnode = new ListNode(val);
while(index--){
cur = cur->next;
}
newnode->next = cur->next;
cur->next = newnode;
size++;
}
void deleteAtIndex(int index) {
if (index >= size || index < 0) {
return;
}//一開始並沒有去考慮到非法index的產生
ListNode *cur = dummyhead;
while(index--){
cur = cur->next;
}
ListNode *tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
tmp=nullptr; //看完代碼隨想錄才知道要再加上這個指針,代碼隨想錄解是如下
//delete命令指示释放了tmp指针原本所指的那部分内存,
//被delete后的指针tmp的值(地址)并非就是NULL,而是随机值。也就是被delete后,
//如果不再加上一句tmp=nullptr,tmp会成为乱指的野指针
//如果之后的程序不小心使用了tmp,会指向难以预想的内存空间
size--;
}
private:
int size;
ListNode* dummyhead;
};
正確代碼
class MyLinkedList {
public:
struct ListNode {
int val;
ListNode* next;
ListNode(int x) : val(x), next(nullptr) {}
};
MyLinkedList() {
dummyhead = new ListNode(0);
size = 0;
}
int get(int index) {
if (index > (size - 1) || index < 0) {
return -1;
}
ListNode *cur = dummyhead->next;
while(index -- ){
cur = cur->next;
}
return cur->val;
}
void addAtHead(int val) {
ListNode *newnode = new ListNode(val);
newnode->next = dummyhead->next;
dummyhead->next = newnode;
size++;
}
void addAtTail(int val) {
ListNode *cur = dummyhead;
ListNode *newnode = new ListNode(val);
while(cur->next != NULL){
cur = cur->next;
}
cur->next = newnode;
size++;
}
void addAtIndex(int index, int val) {
if(index > size) return;
if(index < 0) index = 0;
ListNode *cur = dummyhead;
ListNode *newnode = new ListNode(val);
while(index--){
cur = cur->next;
}
newnode->next = cur->next;
cur->next = newnode;
size++;
}
void deleteAtIndex(int index) {
if (index >= size || index < 0) {
return;
}
ListNode *cur = dummyhead;
while(index--){
cur = cur->next;
}
ListNode *tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
tmp=nullptr;
size--;
}
private:
int size;
ListNode* dummyhead;
};
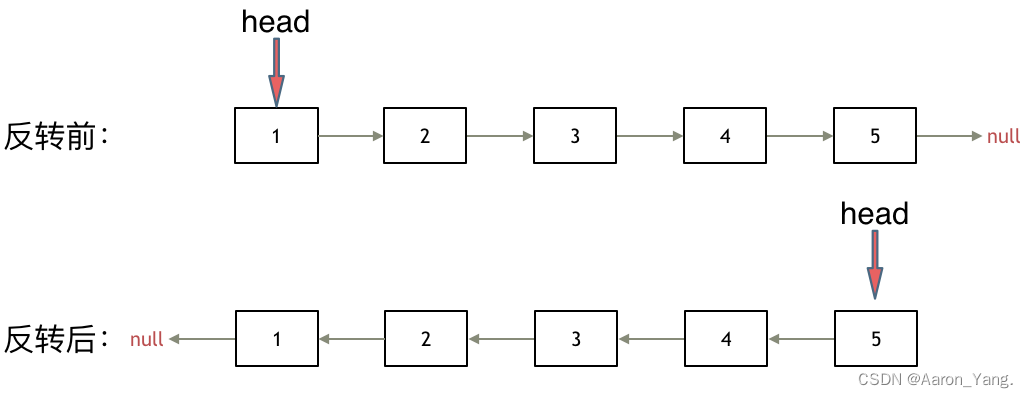
206.反转链表 - 實作
思路
雙指針
- 利用一個cur 以及 pre指針來進行
- pre的初始值設為NULL → 因為頭節點會變成尾節點所以pre的初始值設為NULL
- cur的初始值設為head
- 迴圈終止條件為cur走到NULL的位置
- 迴圈執行時須注意
- 需要一個暫時節點儲存cur→next的節點,避免cur指向反轉後,後面的節點遺失
- cur→ next = pre
- pre = cur
- cur = temp
- c、d非常重要,如果順序顛倒,則pre實際上是抓到原本cur→next的位置而不是cur,這點需要非常注意
- 最後返回pre的點,因為這時cur 走到NULL,而pre則是原本的tail現在的head
遞迴
- 建立一個reverse函數帶入值為cur,pre
- 在主函式中直接return reverse函數
- 主函示帶入reverse函數的值為(head, NULL) → 這裡可以發現可以跟雙指針的2、3進行對應
- 遞迴結束時是cur == NULL的時候 ,return pre節點,這點可跟雙指針的4、6做對應
- reverse函數下面繼續執行的則跟雙指針的5其實一樣
- 需要一個暫時節點儲存cur→next的節點,避免cur指向反轉後,後面的節點遺失
- cur → next = pre;
- 呼叫reverse函數cur = temp, pre = cur,這點可以跟雙指針的5-c, 5-d作對應
Code
雙指針
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* cur = head;
ListNode* pre = NULL;
while(cur){
ListNode* temp = cur->next;
cur->next = pre;
pre = cur;
cur = temp;
}
return pre;
}
};
遞迴
class Solution {
public:
ListNode* reverse(ListNode* cur, ListNode* pre){
if(cur == NULL) return pre;
ListNode* temp = cur->next;
cur->next = pre;
//對應雙指針法的
//pre = cur;
//cur = temp;
return reverse(temp, cur); //一開始忘記加return
}
ListNode* reverseList(ListNode* head) {
return reverse(head, NULL);
//對應雙指針法的
//ListNode* cur = head;
//ListNode* pre = NULL;
}
};
總結
自己实现过程中遇到哪些困难
實現過程中,其實在這三題當中,我很多小細節沒有去考慮到,主要有兩方面
- 一方面是對語法的不熟悉
- 另一方面也是對於鏈表的操作不熟悉
至於困難以及錯誤點都在上面有寫了
今日收获,记录一下自己的学习时长
自己今天大概學了3hr 左右,整理其實收穫很大,之前有了解過虛擬Head但沒有實際操作過,這一次直接來實行,真的很過癮
另外雙指針法以及遞歸彼此之間的對應,也讓我很欣喜,我很喜歡這樣不斷踏出自己舒適圈一點點的感受,所以認真作筆記以及把自己的錯誤點很誠實地記錄並分享,直面自己的錯誤,對於題目的思考也會更加的清晰。
相關資料
链表理论基础
文章链接:https://programmercarl.com/链表理论基础.html
203.移除链表元素
题目链接/文章讲解/视频讲解::https://programmercarl.com/0203.移除链表元素.html
707.设计链表
题目链接/文章讲解/视频讲解:https://programmercarl.com/0707.设计链表.html
206.反转链表
题目链接/文章讲解/视频讲解:https://programmercarl.com/0206.翻转链表.html