一、预处理器
1、用预处理指令#define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题)
#define SECONDS_PER_YEAR (365*24*60*60)UL
在这个例子中,SECONDS_PER_YEAR是一个宏常量,它的值被计算为365乘以24乘以60乘以60,即表示一年中的秒数。
这个表达式将使一个16位机的整型数溢出-因此要用到长整型符号L,告诉编译器这个常数是的长整型数
2、写一个"标准"宏MIN ,这个宏输入两个参数并返回较小的一个。
#define MIN(a, b) ((a) <= (b) ? (a) : (b))
这个宏使用了条件运算符(?:)来进行比较,并返回较小的参数。其中(a) <= (b)是比较表达式,如果为真,则返回(a),否则返回(b)。宏在预处理阶段进行文本替换,因此应确保将参数用括号括起来,以避免可能的优先级问题。
3、预处理器标识#error的目的是什么?
预处理器指令#error的目的是在预处理阶段生成一个错误消息。当条件满足时,它会停止编译过程,并将指定的错误消息输出到编译器的错误日志中。
#error指令通常用于在预处理阶段检查代码的某些条件或要求,如果不满足条件或不符合要求,则会触发错误消息。这可以帮助开发人员及早发现问题并进行修复。
使用#error指令的一些常见情况包括:
- 检查特定的编译器或操作系统版本要求。
- 确保必需的宏定义或头文件已经包含。
- 防止使用不推荐或废弃的功能或方法。
- 检查代码的一些约束条件是否满足,如数组大小、常量值等。
下面是一个示例,使用#error指令检查宏定义是否满足要求:
#ifndef MY_MACRO
#error "MY_MACRO is not defined. Please define it before compiling."
#endif
在上述示例中,如果预处理阶段检测到MY_MACRO宏未定义,编译将停止,并输出错误消息"MY_MACRO is not defined. Please define it before compiling." 到编译器的错误日志中。
总之,#error指令可以帮助开发人员在编译前捕获一些错误或不符合要求的情况,并提供有用的错误信息以便及早修复问题。
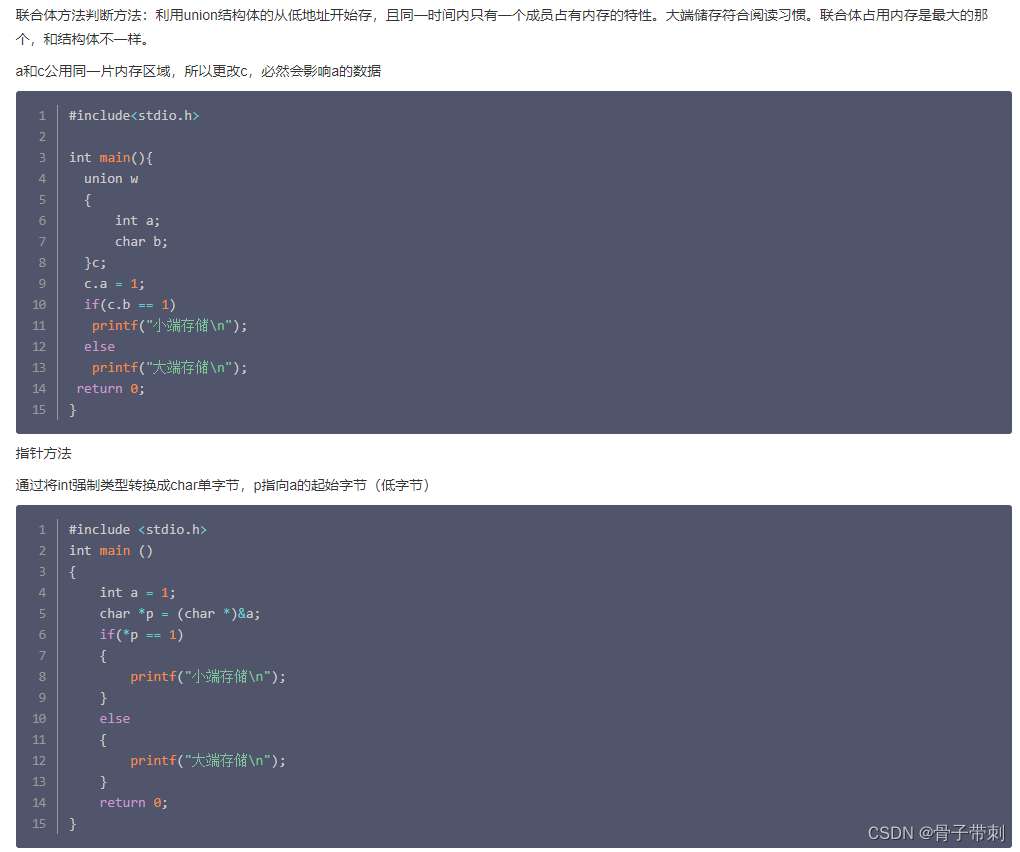
4.union {int a;char b} c;c.a = 0x12345678,写出小端机器上c.b的值.
在小端机器上,低位字节存储在低地址,高位字节存储在高地址。给定一个联合体union {int a; char b} c;,并假设c.a = 0x12345678,我们可以通过以下过程来确定在小端机器上c.b的值:
- 将
c.a的内存表示拆分为四个字节(byte):0x12、0x34、0x56和0x78。 - 在小端机器上,低位字节存储在低地址,因此最低有效字节为0x78,对应于
c.b的值。 - 因此,在小端机器上,
c.b的值为0x78。
换句话说,在小端机器上,联合体中的整数类型按照低字节优先的方式存储,因此取决于具体的机器架构和字节顺序。在这种情况下,c.b的值就是c.a的最低有效字节。
需要注意的是,字节顺序是与机器架构相关的,不同的机器可能有不同的字节顺序。因此,对于跨平台或与字节顺序有关的操作,需要特别小心处理和进行适当的转换。
5.下面程序,执行上面程序后,a[3][2]的值是?
int a[5][5], i;
int *p = (int *)(a + 1);
for (i = 0;i < 20; i++) (
*p++=i
在给定的程序中,由于指针 p 初始化为 (int *)(a + 1),它指向了数组 a 中的第2行(索引为1)。因此,在循环中逐个给 *p 赋值时,实际上是修改了 a[1][0]、a[1][1]、a[1][2] 等元素。
根据循环的迭代次数,我们可以得出以下结果:
a[1][0]的值为 0a[1][1]的值为 1a[1][2]的值为 2- …
a[3][2]的值为 12
因此,执行完上述程序后,a[3][2] 的值为 12。
6.如果要实现高级语言(C++ /JAVA) 中的map容器,哪些数据结构合适?
要实现高级语言(如C++或Java)中的map容器,以下数据结构是常用且适合的选择:
二叉搜索树(Binary Search Tree, BST):BST是一种常见的数据结构,它具有快速的查找和插入操作。在BST中,每个节点都包含一个键值对,并根据键进行排序。通过比较键值,可以在O(log n)的时间复杂度内执行查找、插入和删除操作。
平衡二叉搜索树(Balanced Binary Search Tree):平衡二叉搜索树是在BST的基础上进行了优化,以确保树的高度保持平衡,从而提供更稳定的性能。常见的平衡二叉搜索树包括红黑树、AVL树等。
散列表(Hash Table):散列表是一种通过哈希函数将键映射到存储位置的数据结构。它可以在O(1)的平均时间复杂度下执行插入、查找和删除操作。使用散列表实现
map时,需要处理哈希冲突和动态调整散列表大小的问题。跳跃表(Skip List):跳跃表是一种支持快速查找、插入和删除操作的数据结构。它通过多层链表来实现,其中每个层级都是原始链表的子集。跳跃表可以在O(log n)的时间复杂度内执行查找操作,且插入和删除操作的平均时间复杂度也是O(log n)。
以上数据结构中,二叉搜索树和平衡二叉搜索树提供了较为简单和直观的实现方式,适用于小规模数据集。散列表具有快速的查找和插入性能,适用于大规模数据集。而跳跃表则提供了一种平衡性能和实现复杂度之间折中的选择。
选择合适的数据结构取决于具体的需求、数据规模和性能要求。在实际应用中,需要综合考虑数据结构的特点、操作复杂度和空间开销等因素,选择最适合的数据结构来实现map容器的功能。
7.在32位机器上执行 char a[] =“hello”. char *p = a; sizeof(a) = ____字节,sizeof( p ) = ____字节。
在32位机器上执行以下代码:
char a[] = "hello";
char *p = a;
sizeof(a)返回的是数组 a 的大小,即整个字符数组的字节数。由于字符串 “hello” 包含 6 个字符(包括结尾的空字符 ‘\0’),因此 sizeof(a) 的值为 6 字节。
sizeof(p)返回的是指针 p 的大小,而不是指向的内容的大小。指针的大小在32位机器上通常是 4 字节。
所以,在32位机器上执行该代码后,sizeof(a) 的值为 6 字节,sizeof(p) 的值为 4 字节。
8.如果i的初始值为0,三个线程并发执行C语言 i++ 语句,执行完后的值可能是______
对于并发执行的情况下,三个线程同时执行 i++ 语句可能导致最终的值为1、2或3,原因如下:
竞态条件(Race Condition):在多线程环境下,由于线程之间的交错执行和并发访问共享资源,可能会导致竞态条件的发生。对于
i++这样的语句,涉及到读取变量 i 的当前值、增加该值以及写回新值,而这些操作可能会被不同的线程交错执行,导致最终结果的不确定性。执行顺序不确定:由于线程的调度是由操作系统控制的,具体的线程执行顺序是不确定的。即使代码看似按照顺序编写,但在实际执行过程中,不同线程的执行顺序可能会不同,从而导致最终结果的差异。
原子性问题:
i++操作并非原子操作,它包含了读取、增加和写回三个步骤。在多线程环境下,如果没有采取特殊的同步机制来保证原子性,多个线程可能同时读取同一个初始值,然后各自增加并写回,从而导致最终结果的不确定性。
因此,由于竞态条件、执行顺序不确定性和原子性问题,最终执行完后的值可能是1、2或3,具体取决于线程间的交错执行和调度顺序。
9.假设将内存由若干个等长页组成,页大小为2的n次方,地址a所在页的起始地址是_______,页内偏移是___________.
假设将内存由若干个等长页组成,页大小为2的n次方。给定一个地址a,可以计算出该地址所在页的起始地址和页内偏移。
页起始地址计算:
页起始地址 = a & (~(2^n - 1))
这里的 &(按位与) 操作用于将地址 a 的低 n 位清零,即将页内偏移部分置零,得到页的起始地址。页内偏移计算:
页内偏移 = a & (2^n - 1)
这里的 &(按位与) 操作用于获取地址 a 的低 n 位,即页内偏移部分。
综上所述,给定一个地址 a,它所在页的起始地址是 a & (~(2^n - 1)),页内偏移是 a & (2^n - 1)。
10.UART的配置寄存器(32位) 地址为0x10000000,其格式如下: 写出将B域置为Ox1F的代码片断__________。
| 31 ~11 | 10~2 | 1 |
|---|---|---|
| A | B | C |
//想用指针指向地址0x100000000。
int *p = (int *)0x100000000:
//进行置1操作
(*p)|=(0x1F<<1);
//进行清零操作
(*p)&=~(0x1F<<1);
11.int a=50;a > > =2:写出a的值____.
给定 int a = 50; 和 a >>= 2; 这两行代码,a 的值将变为 12。
这是因为 >>= 是右移赋值操作符,将变量 a 的值按位右移指定的位数,并将结果赋值给变量 a。在这种情况下,a 初始值为 50,二进制表示为 00110010。右移 2 位后,得到 00001100,即十进制的 12。因此,执行完 a >>= 2 后,变量 a 的值变为 12。
12.已知一段内存起始地址a,长度b,和另一段内存起始地址c,长度d。写出可以判断出两段内存重叠的布尔表达式______.
要判断两段内存是否重叠,可以使用以下布尔表达式:
(a < (c + d)) && ((a + b) > c)
这个布尔表达式的含义是,如果地址段1(起始地址为a,长度为b)的结束地址大于地址段2(起始地址为C,长度为d)的起始地址,并且地址段1的起始地址小于地址段2的结束地址,则说明两个地址段有重叠。
解释一下上述表达式:
(a < (c + d)):判断地址段1的起始地址是否小于地址段2的结束地址。((a + b) > c):判断地址段1的结束地址是否大于地址段2的起始地址。
如果上述布尔表达式返回 true,则表示两个地址段存在重叠;如果返回 false,则表示两个地址段不重叠。
13.简述设备驱动中,自旋锁、开关中断、互斥量这三种同步机制的特点。
在设备驱动中,自旋锁、开关中断和互斥量是常用的同步机制,它们具有不同的特点:
自旋锁(Spin Lock):
- 特点:自旋锁是一种忙等待的同步机制,当一个线程尝试获取自旋锁时,如果锁已经被其他线程占用,则该线程会一直循环忙等待,直到锁变为可用。
- 适用场景:适用于对临界区的访问时间非常短暂的情况,不涉及长时间的睡眠或阻塞操作。适合用于多核系统,避免线程切换带来的性能损耗。
开关中断(Disable Interrupts):
- 特点:开关中断是通过禁用中断来实现同步的机制。当一个线程执行代码段时,可以通过关闭中断的方式来防止其他线程或中断处理程序的干扰。
- 适用场景:适用于需要保护临界区免受中断干扰的情况。适用于单核和多核系统。
互斥量(Mutex):
- 特点:互斥量是一种基于信号量的同步机制,用于保护共享资源的互斥访问。当一个线程获取到互斥量时,其他线程需要等待直到互斥量被释放。
- 适用场景:适用于对临界区的访问时间较长,涉及睡眠或阻塞操作的情况。适用于单核和多核系统。
这些同步机制在设备驱动中的选择取决于具体的需求和场景。自旋锁适用于对临界区的访问非常短暂的情况;开关中断适用于需要保护临界区免受中断干扰的情况;互斥量适用于对临界区的访问时间较长的情况。同时,应根据系统的特性、硬件支持和性能要求来选择合适的同步机制。
14.如果一个程序退出时产生异常,异常发生在main函数结束后,请分析可能导致异常原因。
如果一个程序在main函数结束后产生异常,可能的原因有以下几种:
静态对象的析构顺序问题:C++中,静态对象会在main函数结束后自动调用析构函数进行清理。如果程序中存在多个静态对象,而它们之间存在依赖关系,那么在main函数结束后进行析构时可能会导致异常。
动态内存管理问题:如果程序在运行期间使用了动态内存分配(如new/delete、malloc/free等),但没有正确释放相关的资源,可能导致内存泄漏或者访问已释放内存的错误,从而在程序退出时产生异常。
线程未正确终止:如果程序中使用了多线程,而某个线程未正确地终止或释放相关资源,可能会导致程序退出时发生异常。
异常处理不完整:如果程序中存在异常抛出但未被捕获和处理的情况,当这些未处理的异常传播到main函数之外时,可能导致程序在退出时发生异常。
越界访问或空指针引用:如果程序中存在越界访问数组、使用空指针进行操作等错误,这些错误在main函数执行结束后仍然可能导致异常的发生。
以上是一些常见的可能导致程序在main函数结束后产生异常的原因。根据具体的异常信息和程序代码,可以进一步定位问题并进行修复。使用合适的调试工具和技术,如断点调试、异常捕获和日志记录等,有助于分析和解决这些异常问题。
15.假如以下程序(伪代码)在某两款操作系统下运行性能差异很大,请描述分析问题的方法,并深入分析可能产生差异的原因。
void main()
{
// 以下函数相互之间存在强依赖性,不可单独使用
get data from network(); //从网络获取数据
handle data(); //处理数据,涉及大量浮点运算
save data to file(); //保存数据到文件
}
分析问题的方法:
性能测试和测量:在两款操作系统下运行该程序,并进行性能测试和测量。可以使用性能分析工具、计时器或者其他性能评估方法来获取程序在不同操作系统下的执行时间、资源利用率等数据。
对比差异:对比两款操作系统下的性能数据,查看是否存在明显的差异。比较各个阶段(从网络获取数据、处理数据、保存数据到文件)的执行时间、CPU利用率等指标,找出差异所在。
调试和分析:如果发现性能差异,可以通过调试和分析来进一步深入研究原因。可能需要观察程序的执行轨迹、检查相关系统资源使用情况、分析调用栈、查看系统日志等。
系统特性和配置:比较两款操作系统的特性和配置,例如任务调度算法、内核设计、I/O子系统、调度优先级等。这些因素可能会影响程序的性能表现。
优化策略:根据分析结果,确定可能导致差异的原因,并尝试采取相应的优化策略。例如,针对涉及大量浮点运算的阶段,可以考虑使用优化的数学库或算法,或者通过并行化处理来提高性能。
可能产生差异的原因:
硬件差异:两款操作系统运行在不同的硬件平台上,硬件性能的差异可能导致程序执行的速度和效率有所不同。
调度策略:两款操作系统采用不同的任务调度算法,如抢占式调度和协作式调度。这些调度策略会影响任务之间的切换和优先级分配,从而可能导致性能差异。
优化实现:两款操作系统对于底层功能的实现方式可能不同,例如网络数据获取、浮点运算库的实现等。这些实现的差异可能会导致性能差异。
文件系统性能:保存数据到文件涉及到文件系统的读写操作,两款操作系统的文件系统性能可能有所差异,如磁盘访问速度、缓存机制等。
并发和并行性能:如果程序中存在多线程或多进程,并发和并行执行的性能也可能受到操作系统的影响,如线程调度、锁机制、内存管理等。
通过以上方法和分析,可以帮助我们深入了解两款操作系统下性能差异的原因,并针对性地进行优化和改进,以提高程序的性能。
16.设计一套线程池接口 (不用实现),要求该接口可以完成线程池创建、销毁、以及传入某个回调函数并在线程中执行的功能。
// 定义回调函数类型
typedef void (*ThreadTask)(void*);
class ThreadPool {
public:
// 创建线程池
static ThreadPool* create(int numThreads);
// 销毁线程池
virtual void destroy() = 0;
// 提交任务到线程池中执行
virtual void submit(ThreadTask task, void* arg) = 0;
};
使用该接口,可以通过以下步骤来使用线程池:
创建线程池:
ThreadPool* pool = ThreadPool::create(numThreads);提交任务到线程池:
ThreadTask task = // 设置回调函数 void* arg = // 设置回调函数的参数 pool->submit(task, arg);在回调函数中执行具体的操作。例如,执行某个函数或者一段代码块。
当不再需要线程池时,销毁线程池:
pool->destroy();
注意,这只是一个线程池接口的设计示例,并没有提供具体的实现。在实际使用时,需要根据具体的需求和平台环境,实现相应的线程池类并提供适当的方法来创建、销毁和执行任务。同时,还需要考虑线程安全性、任务队列管理等方面的实现细节。
17.请实现一个算法,判断数学表达式是否合法,例如: 合法:“123*((456 - 3) + 789)”,非法:“123(* 456 + 789)”
bool is math expression (char* exp)