Python 基础
部分信息参考 菜鸟教程
介绍背景
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。它起源于1980年代末,由Guido van Rossum 创建。Python的设计哲学是“明确优于隐晦”,注重代码的可读性,易于阅读和理解。
环境搭建
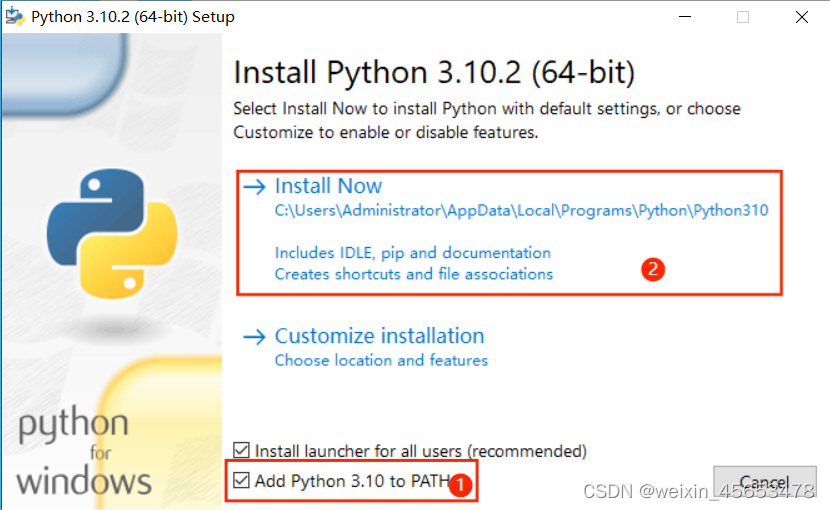
Python 可以在多个平台(如 Windows、macOS 和 Linux)上运行。为了开始学习 Python,你需要安装 Python 解释器。你可以从 Python 官方网站下载并安装最新版本的 Python。 一般使用最新版本前3个版本左右
下载
win下
下载安装包Python Release Python 3.12.1 | Python.org 下载python
win常见安装软件 略(注意添加环境变量)
Linux下
如 centos 直接使用yum安装
yum install python -y
macos
去官方下载安装Python Releases for macOS | Python.org
或者应用商店直接下载
其他
anconda安装
Anaconda 教程 | 菜鸟教程 (runoob.com)
开发工具
pycharm
官方下载地址Download PyCharm: Python IDE for Professional Developers by JetBrains
社区版本免费使用 功能被阉割
vscode
官方下载地址Visual Studio Code - 代码编辑
安装python插件就可以进行运行了
其他
idea
cmd 等
基础语法
Python 的基础语法包括以下几个方面:
print("Hello world!")
变量:
Python 中的变量不需要预先声明,可以直接赋值。Python 支持多种数据类型,包括数字、字符串、列表、字典等。
a = 1
b = "abcd"
c = []
d = {
}
print(a,b,c,d) # 打印输出
# ... 直接使用不用声明

变量命名:
- 第一个字符必须是字母表中字母或下划线 _ (一般被弃用)。
- 变量名的其他的部分由字母、数字和下划线组成。
- 变量名对大小写敏感。
- 不要使用
保留关键字 - 在 Python 3 中,可以用中文作为变量名,非 ASCII 变量名也是允许的了。
保留关键字
import keyword
keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释 ———[最喜欢的就是写代码不写注释,最不喜欢的就是别人的代码没有注释]
单行注释
多行注释
# 单行注释
"""
多行注释 不区分单双引号 但是必须配对 【不能前面双后面单】
"""
模块和包:使用第三方的库 或者自己封装
Python 中的模块和包可以帮助你组织和管理代码,使其更加模块化和可重用。
import pandas as pd # 导入 pandas 库 取别名 pd
from matplotlib import pyplot as plt #从matplotlib中 导入 pyplot库 取别名 plt
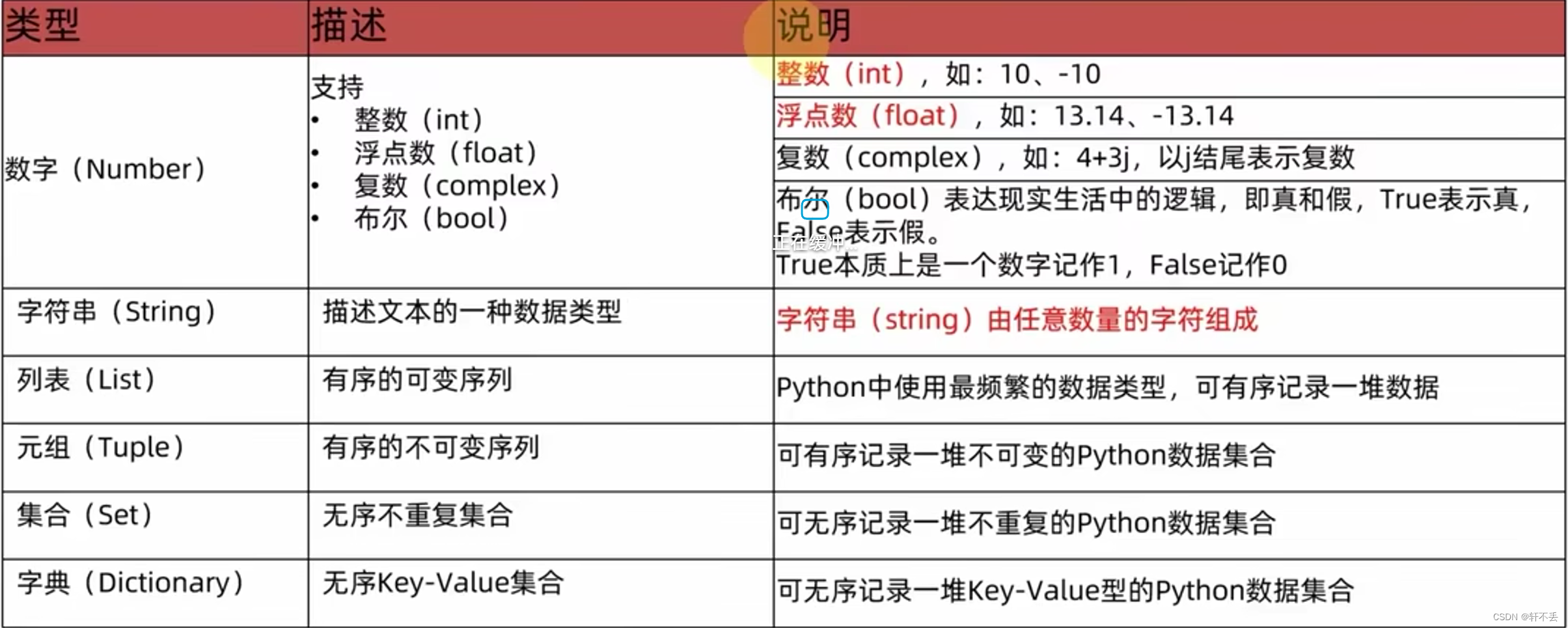
数据类型
Python 支持以下几种数据类型:
数字:包括整数和浮点数和复数。
var1 = 1
var2 = 10.123
数字类型转换
x = int(x) # 将x转换为一个整数。 (常用)
x = float(x) # 将x转换到一个浮点数。 (常用)
x = complex(x) # 将x转换到一个复数,实数部分为 x,虚数部分为 0。
x = complex(x, y) # 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
数字运算 基础的加减乘除 +, -, ***** ,/
a = 1 + 2
b = 1 - 2
c = 1 * 2
d = 5 / 2
e = 5 // 2 # 地板除 一般去尾 只保留整数部分 7.9//3 = 2.0
f = 10 % 3 # 取模 返回余数 也不计算小数点后面
print("1 + 2 = ",a)
print("1 - 2 = ",b)
print("1 * 2 = ",c)
print("5 / 2 = ",d)
print("5 // 2 = ",e)
print("10 % 3 = ",f)

数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 以浮点数形式返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,…) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,…) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| [round(x [,n])](https://www.runoob.com/python3/python3-func-number-round.html) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。其实准确的说是保留值将保留到离上一位更近的一端。 |
| sqrt(x) | 返回数字x的平方根。 |
随机函数
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| [randrange (start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| [seed(x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
三角函数
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(xx + yy)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 e,e即自然常数(自然常数)。 |
字符串:
由零个或多个字符组成。
字符串是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 " )来创建字符串。
var1 = "qwert"
var2 = "1234"
Python 访问字符串中的值
切片 变量[头下标:尾下标]
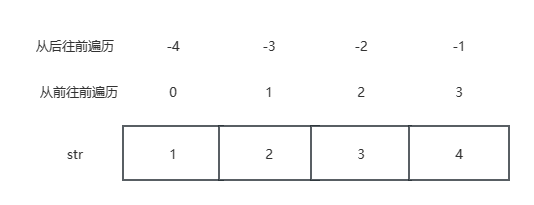
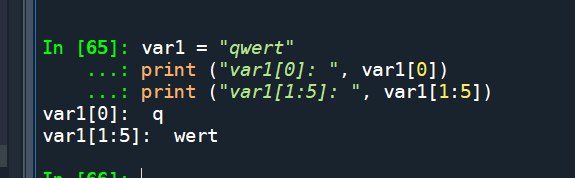
案例
var1 = "qwert"
print ("var1[0]: ", var1[0])
print ("var1[1:5]: ", var1[1:5])
字符串转义
| 转义字符 | 描述 | 实例 |
|---|---|---|
| (在行尾时) | 续行符 | >>> print("line1 \ ... line2 \ ... line3") line1 line2 line3 >>> |
| \ | 反斜杠符号 | >>> print("\\") \ |
| ’ | 单引号 | >>> print('\'') ' |
| " | 双引号 | >>> print("\"") " |
| \a | 响铃 | >>> print("\a")执行后电脑有响声。 |
| \b | 退格(Backspace) | >>> print("Hello \b World!") Hello World! |
| \000 | 空 | >>> print("\000") >>> |
| \n | 换行 | >>> print("\n") >>> |
| \v | 纵向制表符 | >>> print("Hello \v World!") Hello World! >>> |
| \t | 横向制表符 | >>> print("Hello \t World!") Hello World! >>> |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | >>> print("Hello\rWorld!") World! >>> print('google runoob taobao\r123456') 123456 runoob taobao |
| \f | 换页 | >>> print("Hello \f World!") Hello World! >>> |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | >>> print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | >>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World! |
| \other | 其它的字符以普通格式输出 |
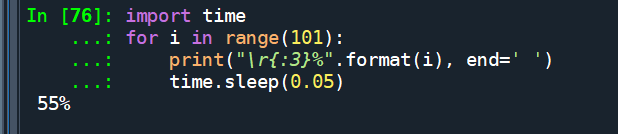
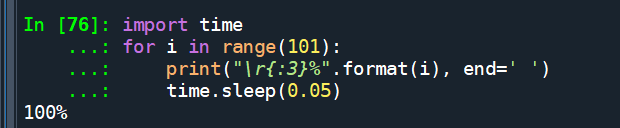
\r 的使用 只能替换开头
import time
for i in range(101):
print("\r{:3}%".format(i),end=' ')
time.sleep(0.05)
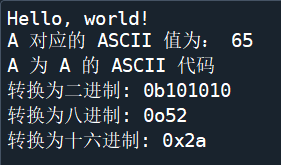
print('\'Hello, world!\'') # 输出:'Hello, world!'
print("Hello, world!\nHow are you?") # 输出:Hello, world!
# How are you?
print("Hello, world!\tHow are you?") # 输出:Hello, world! How are you?
print("Hello,\b world!") # 输出:Hello world!
print("Hello,\f world!") # 输出:
# Hello,
# world!
print("A 对应的 ASCII 值为:", ord('A')) # 输出:A 对应的 ASCII 值为: 65
print("\x41 为 A 的 ASCII 代码") # 输出:A 为 A 的 ASCII 代码
decimal_number = 42
binary_number = bin(decimal_number) # 十进制转换为二进制
print('转换为二进制:', binary_number) # 转换为二进制: 0b101010
octal_number = oct(decimal_number) # 十进制转换为八进制
print('转换为八进制:', octal_number) # 转换为八进制: 0o52
hexadecimal_number = hex(decimal_number) # 十进制转换为十六进制
print('转换为十六进制:', hexadecimal_number) # 转换为十六进制: 0x2a
字符串运算符
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | ‘H’ in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | ‘M’ not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
| % | 格式字符串 | 请看下一节内容。 |
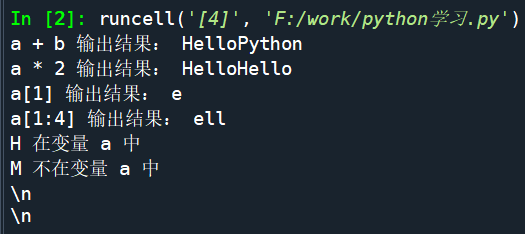
a = "Hello"
b = "Python"
print("a + b 输出结果:", a + b)
print("a * 2 输出结果:", a * 2)
print("a[1] 输出结果:", a[1])
print("a[1:4] 输出结果:", a[1:4])
if( "H" in a) :
print("H 在变量 a 中")
else :
print("H 不在变量 a 中")
if( "M" not in a) :
print("M 不在变量 a 中")
else :
print("M 在变量 a 中")
print (r'\n')
print (R'\n')
Python 字符串格式化
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 符 号 |
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%‘输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python 的字符串内建函数
| 序号 | 方法及描述 |
|---|---|
| 1 | capitalize() 将字符串的第一个字符转换为大写 |
| 2 | center(width, fillchar)返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding=“utf-8”, errors=“strict”) Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding=‘UTF-8’,errors=‘strict’) 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| 6 | endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 suffix 结束,如果 beg 或者 end 指定则检查指定的范围内是否以 suffix 结束,如果是,返回 True,否则返回 False。 |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False… |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | [ljust(width, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | [replace(old, new [, max])](https://www.runoob.com/python3/python3-string-replace.html) 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串末尾的空格或指定字符。 |
| 31 | split(str=“”, num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 | splitlines([keepends]) 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars]) 在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars=“”) 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
可使用 format 函数
列表:
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
创建列表
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
list4 = []
读取数据
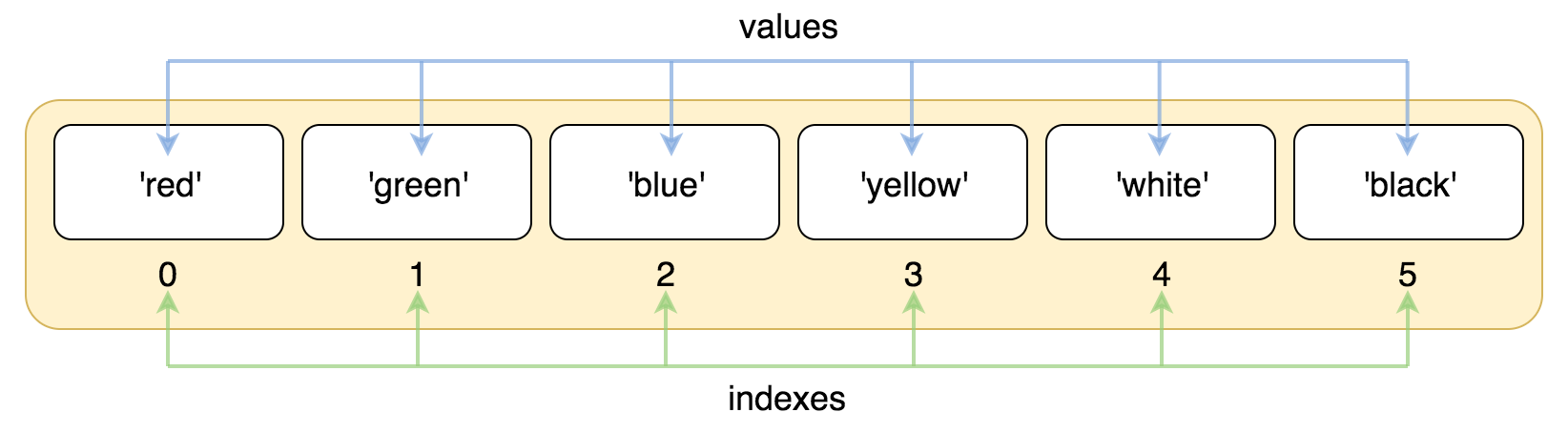
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print( list[0] )
print( list[1] )
print( list[2] )
切片
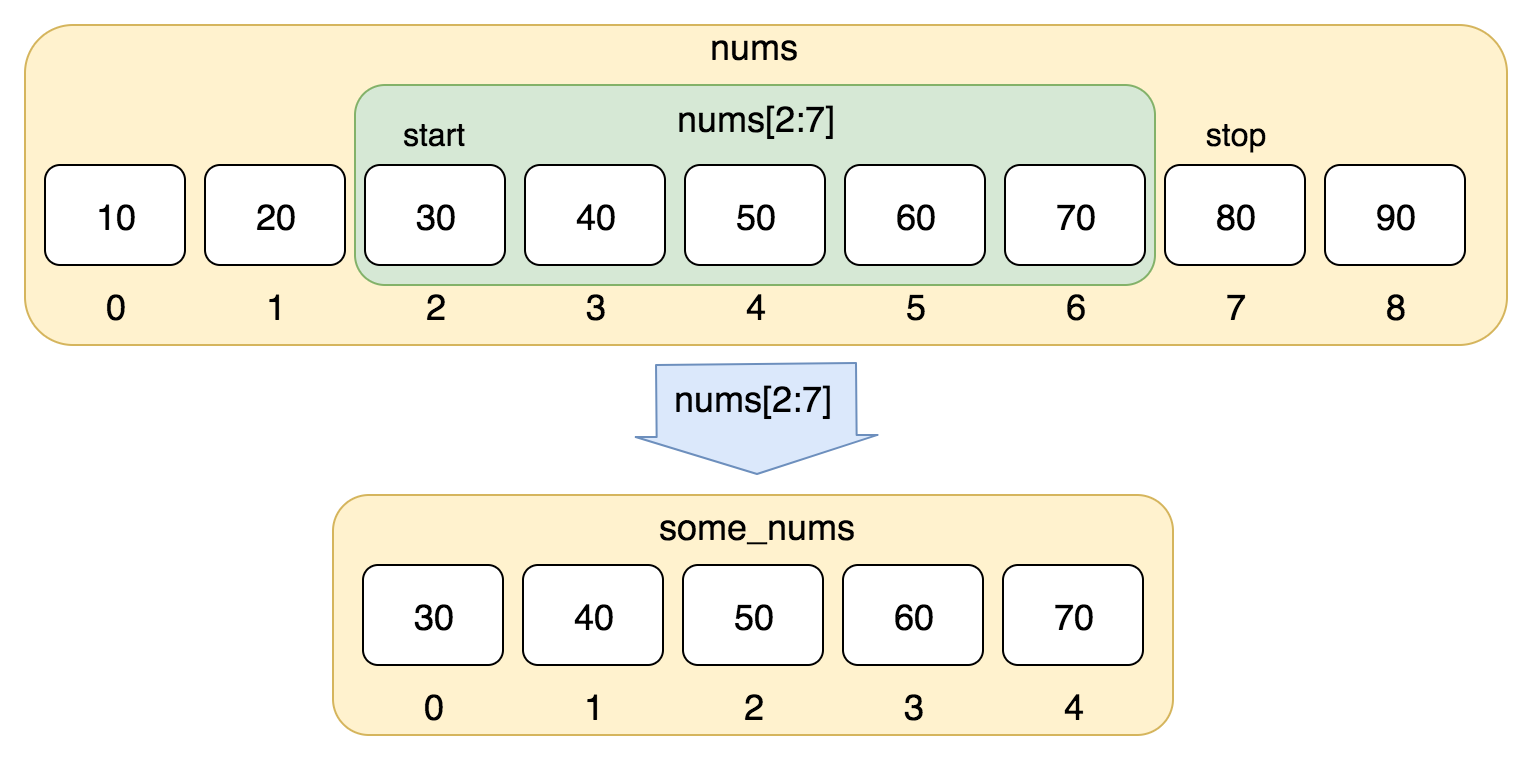
nums = [10, 20, 30, 40, 50, 60, 70, 80, 90]
print(nums[0:4])
增删
append
del list[n]
list.append("data")
del list[2] # 删除第三个 从开始
列表的基本操作
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
Python列表函数&方法
| 序号 | 函数 |
|---|---|
| 1 | len(list) 列表元素个数 |
| 2 | max(list) 返回列表元素最大值 |
| 3 | min(list) 返回列表元素最小值 |
| 4 | list(seq) 将元组转换为列表 |
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort( key=None, reverse=False) 对原列表进行排序 |
| 10 | list.clear() 清空列表 |
| 11 | list.copy() 复制列表 |
字典:
键值对的集合,键是唯一的。
创建字典
dict1 = {
}
dict2 = dict()
dict3= {
'name': '小明', 'likes': 123, 'url': 'www.baidu.com'}
访问字典里的值 通过key访问value
tinydict = {
'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print ("tinydict['Name']: ", tinydict['Name'])
print ("tinydict['Age']: ", tinydict['Age'])
修改字典
dict1 = {
'Name': '小明', 'Age': 7, 'Class': 'First'}
dict1['Age'] = 8 # 更新 Age
dict1['School'] = "大学" # 添加信息
print ("dict1['Age']: ", dict1['Age'])
print ("dict1['School']: ", dict1['School'])

删除字典元素
dict1 = {
'Name': '小明', 'Age': 7, 'Class': 'First'}
del dict1['Name'] # 删除键 'Name'
dict1.clear() # 清空字典
del dict1 # 删除字典
print ("dict1['Age']: ", dict1['Age'])
print ("dict1['School']: ", dict1['School'])

字典键的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
- 键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
字典内置函数&方法
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | len(dict) 计算字典元素个数,即键的总数。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> len(tinydict) 3 |
| 2 | str(dict) 输出字典,可以打印的字符串表示。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> str(tinydict) "{'Name': 'Runoob', 'Class': 'First', 'Age': 7}" |
| 3 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> type(tinydict) <class 'dict'> |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回一个视图对象 |
| 7 | dict.keys() 返回一个视图对象 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 返回一个视图对象 |
| 11 | pop(key[,default]) 删除字典 key(键)所对应的值,返回被删除的值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
集合:
无序的不重复元素序列。
创建
创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
set1 = {
1, 2, 3, 4} # 直接使用大括号创建集合
set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合
set3 = set() # 创建空集合
a = set('abracadabra')
b = set('alacazam')
print(a)
# {'a', 'r', 'b', 'c', 'd'}
print(a - b) # 集合a中包含而集合b中不包含的元素
# {'r', 'd', 'b'}
print(a | b) # 集合a或b中包含的所有元素
# {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
print(a & b) # 集合a和b中都包含了的元素
# {'a', 'c'}
print(a ^ b) # 不同时包含于a和b的元素
# {'r', 'd', 'b', 'm', 'z', 'l'}
添加元素
set1.add( x ) # x 可以有多个,用逗号分开。
set1.update( x ) # x 可以有多个,用逗号分开。
移除元素
set1.remove( x ) # 将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
set1.discard( x ) # 将元素 x 从集合 s 中移除,如果元素不存在,不会发生错误。
set1.pop() # 随机删除集合中的一个元素
计算元素个数
len(set1)
清空集合
set1.clear()
判断元素是否在集合中
x in set1
集合常用的方法
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
| len() | 计算集合元素个数 |
流程控制
Python 中的流程控制包括条件语句和循环语句。条件语句用于根据条件执行不同的代码块,而循环语句则用于重复执行一段代码。
if 条件控制
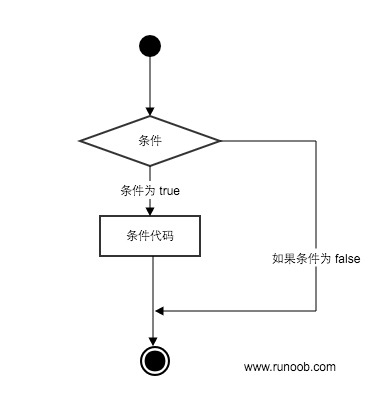
if 常见条件
| 操作符 | 描述 |
|---|---|
< |
小于 |
<= |
小于或等于 |
> |
大于 |
>= |
大于或等于 |
== |
等于,比较两个值是否相等 |
!= |
不等于 |
if 语句
if age <= 0:
print("你是在逗我吧!")
else age == 1:
print("相当于 14 岁的人。")
if 嵌套
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
num=int(input("输入一个数字:"))
if num%2==0:
if num%3==0:
print ("你输入的数字可以整除 2 和 3")
else:
print ("你输入的数字可以整除 2,但不能整除 3")
else:
if num%3==0:
print ("你输入的数字可以整除 3,但不能整除 2")
else:
print ("你输入的数字不能整除 2 和 3")
match…case
Python 3.10 增加了 match…case 的条件判断,不需要再使用一连串的 if-else 来判断了
match subject:
case <pattern_1>:
<action_1>
case <pattern_2>:
<action_2>
case <pattern_3>:
<action_3>
case _:
<action_wildcard>
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
mystatus=400
print(http_error(400))
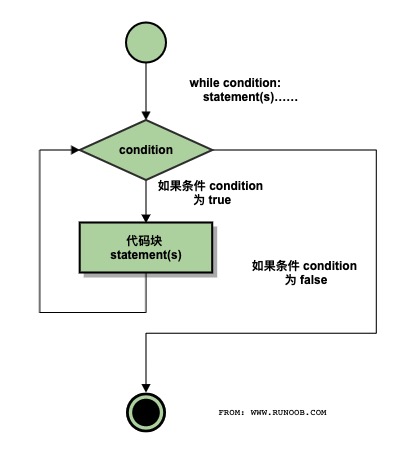
while 循环
while 判断条件(condition):
执行语句(statements)……
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (n,sum))
1 到 100 之和为: 5050
无限循环
var = 1
while var == 1 : # 表达式永远为 true
num = int(input("输入一个数字 :"))
print("你输入的数字是: ", num)
print ("Good bye!")
输入一个数字 :5
你输入的数字是: 5输入一个数字 :
……
while 循环使用 else 语句
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
0 小于 5
1 小于 5
2 小于 5
3 小于 5
4 小于 5
5 大于或等于 5
flag = 1
while (flag): print ('欢迎访问菜鸟教程!')
print ("Good bye!")
欢迎访问菜鸟教程!
欢迎访问菜鸟教程!
欢迎访问菜鸟教程!
欢迎访问菜鸟教程!
欢迎访问菜鸟教程!
……
for 循环
for <variable> in <sequence>:
<statements>
else:
<statements>
for item in iterable:
# 循环主体
else:
# 循环结束后执行的代码
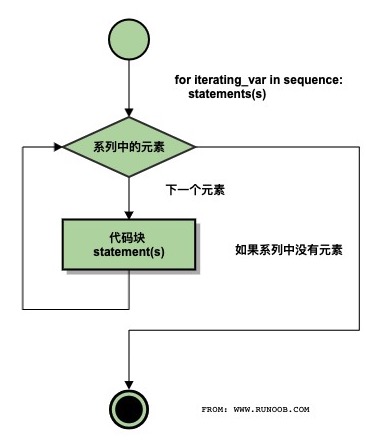
python 遍历列表,字符串 等
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
print(site)
Baidu
Runoob
Taobao
配合range使用
for number in range(1, 6):
print(number)
range 函数
range (起,止,步长) 可以为负数
print(range(10)) # 输出: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 从 1 到 5,步长为 2
print(range(1, 6, 2)) # 输出: [1, 3, 5]
for…else
for x in range(6):
print(x)
else:
print("Finally finished!")
0
1
2
3
4
5
Finally finished!
break 和 continue 语句及循环中的 else 子句
break 执行流程图: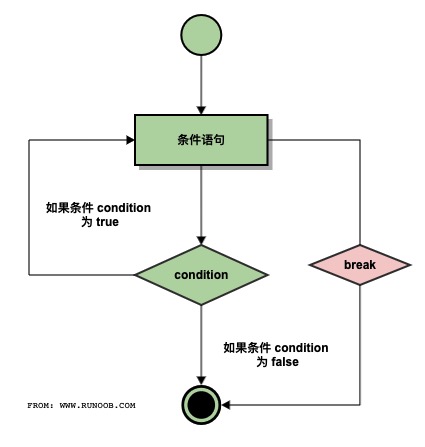 continue 执行流程图:
continue 执行流程图: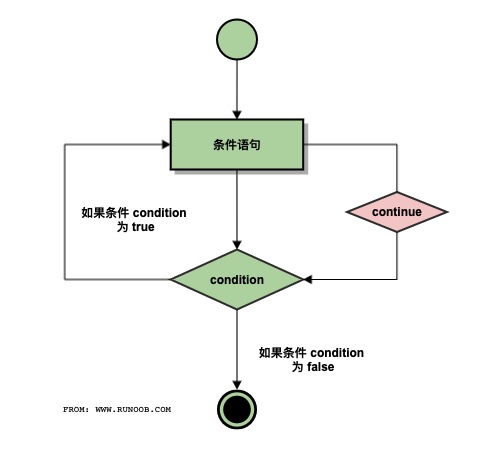

while 中使用 break:
n = 5
while n > 0:
n -= 1
if n == 2:
break
print(n)
print('循环结束。')
4
3
循环结束。
n = 5
while n > 0:
n -= 1
if n == 2:
continue
print(n)
print('循环结束。')
4
3
1
0
循环结束。
pass 语句
Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句,如下实例
class MyEmptyClass:
pass
不写东西会报错 pass 空操作刚刚好
#!/usr/bin/python3
for letter in 'Runoob':
if letter == 'o':
pass
print ('执行 pass 块')
print ('当前字母 :', letter)
print ("Good bye!")
当前字母 : R
当前字母 : u
当前字母 : n
执行 pass 块
当前字母 : o
执行 pass 块
当前字母 : o
当前字母 : b
Good bye!
文件处理
Python 中可以使用内置的 open() 函数来打开文件,并使用 read(), readline(), readlines() 等方法来读取文件内容。还可以使用 write(), writelines() 等方法来写入文件内容。完成文件操作后,需要使用 close() 方法关闭文件。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode 的参
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
file对象
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next()**Python 3 中的 File 对象不支持 next() 方法。**返回文件下一行。 |
| 6 | file.read([size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | file.readline([size])读取整行,包括 “\n” 字符。 |
| 8 | file.readlines([sizeint])读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 | file.seek(offset[, whence])移动文件读取指针到指定位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | file.truncate([size])从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
# 读取文件
file = open("example.txt", "r") # 打开一个名为example.txt的文件,以只读模式打开
# 读取文件
file = open("example.txt", "r")
content = file.read() # 读取整个文件的内容
print(content) # 输出文件内容
file.close() # 关闭文件
# 写入文件
file = open("example.txt", "w") # 打开一个名为example.txt的文件,以写入模式打开
file.write("Hello, world!") # 向文件中写入内容
file.close() # 关闭文件
# 追加文件
file = open("example.txt", "a") # 打开一个名为example.txt的文件,以追加模式打开
file.write("Hello again!") # 向文件中追加内容
file.close() # 关闭文件
com/python3/python3-file-seek.html)移动文件读取指针到指定位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | file.truncate([size])从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
# 读取文件
file = open("example.txt", "r") # 打开一个名为example.txt的文件,以只读模式打开
# 读取文件
file = open("example.txt", "r")
content = file.read() # 读取整个文件的内容
print(content) # 输出文件内容
file.close() # 关闭文件
# 写入文件
file = open("example.txt", "w") # 打开一个名为example.txt的文件,以写入模式打开
file.write("Hello, world!") # 向文件中写入内容
file.close() # 关闭文件
# 追加文件
file = open("example.txt", "a") # 打开一个名为example.txt的文件,以追加模式打开
file.write("Hello again!") # 向文件中追加内容
file.close() # 关闭文件