题目
HDFS文件写入和读取流程
HDFS组成架构
介绍下HDFS,说下HDFS优缺点,以及使用场景
HDFS作用
HDFS的容错机制
HDFS的存储机制
HDFS的副本机制
HDFS的常见数据格式,列式存储格式和行存储格式异同点,列式存储优点有哪些?
HDFS如何保证数据不丢失?
HDFS NameNode高可用如何实现?需要哪些角色?
HDFS的文件结构?
HDFS的默认副本数?为什么是这个数量?如果想修改副本数怎么修改?
介绍下HDFS的Block
HDFS的块默认大小,64M和128M是在哪个版本更换的?怎么修改默认块大小?
HDFS的block为什么是128M?增大或减小有什么影响?
HDFS HA怎么实现?是个什么架构?
导入大文件到HDFS时如何自定义分片?
HDFS的mapper和reducer的个数如何确定?reducer的个数依据是什么?
HDSF通过那个中间组件去存储数据
HDFS跨节点怎么进行数据迁移
HDFS的数据-致性靠什么保证?
HDFS怎么保证数据安全
HDFS中向DataNode写数据失败了怎么办
Hadoop2.xHDFS快照
HDFS文件存储的方式?
HDFS写数据过程,写的过程中有哪些故障,分别会怎么处理?
NameNode存数据吗?
使用NameNode的好处
HDFS中DataNode怎么存储数据的
直接将数据文件上传到HDFS的表目录中,如何在表中查询到该数据?
答案
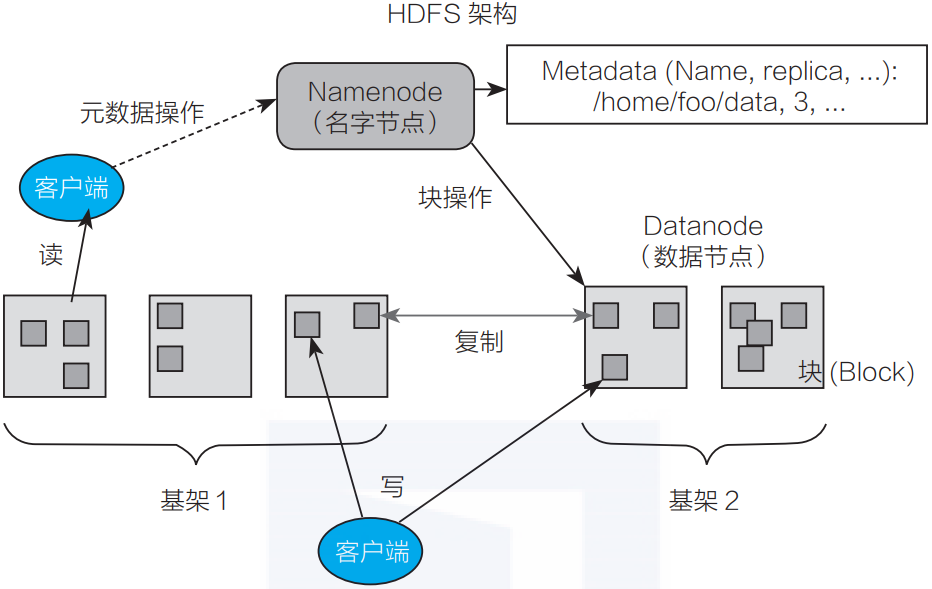
HDFS文件写入和读取流程
写文件流程

要点:
1、NN会触发副本放置策略返回Client一个DN排序
2、Client写文件会直连DN,流式传输,走一个pipline,变种的并行
3、最值钱是下面这个


- 发送创建文件请求:调用分布式文件系统 DistributedFileSystem.create( )方法;
- NameNode 创建文件记录:分布式文件系统 DistributedFileSystem 发送 RPC 请求给 NameNode,NameNode 检查权限后创建一条记录,返回输出流 FSDataOutputStream,封装了输出流 DFSOutputDtream;
- 客户端写入数据:输出流 DFSOutputDtream 将数据分成一个个的数据包,并写入内部队列。DataStreamer 根据 DataNode 列表来要求 NameNode 分配适合的新块来存储数据备份。 一组 DataNode 构成管线(管线的 DataNode 之间使用 Socket 流式通信);
- 使用管线传输数据:DataStreamer 将数据包流式传输到管线第一个DataNode,第一个 DataNode 再传到第二个DataNode,直到完成;
- 确认队列:DataNode 收到数据后发送确认,管线的 DataNode 所有的确认组成一个确认队列。所有 DataNode 都确认,管线数据包删除;
- 关闭:客户端对数据量调用 close( ) 方法。将剩余所有数据写入DataNode管线,联系NameNode并且发送文件写入完成信息之前等待确认;
- NameNode确认:
- 故障处理:若过程中发生故障,则先关闭管线,把队列中所有数据包添加回去队列,确保数据包不漏。为另一个正常 DataNode 的当前数据块指定一个新的标识,并将该标识传送给 NameNode,一遍故障 DataNode 在恢复后删除上面的不完整数据块。从管线中删除故障 DataNode 并把余下的数据块写入余下正常的 DataNode。NameNode 发现复本两不足时,会在另一个节点创建一个新的复本;
在数据的读取过程中难免碰到网络故障,脏数据,DataNode 失效等问题,这些问题 HDFS 在设计的时候都早已考虑到了。下面来介绍一下数据损坏处理流程:
- 当 DataNode 读取 block 的时候,它会计算 checksum。
- 如果计算后的 checksum,与 block 创建时值不一样,说明该 block 已经损坏。
- Client 读取其它 DataNode上的 block。
- NameNode 标记该块已经损坏,然后复制 block 达到预期设置的文件备份数 。
- DataNode 在其文件创建后验证其 checksum。
读文件的流程


如图所示,读文件的流程主要包括以下6个步骤:
- 打开分布式文件:调用分布式文件 DistributedFileSystem.open( ) 方法;
- 寻址请求:从 NameNode 处得到 DataNode 的地址,DistributedFileSystem使用 RPC 方式调用了NameNode,NameNode 返回存有该副本的DataNode 地址,DistributedFileSystem 返回了一个输入流对象(FSDataInputStream),该对象封装了输入流 DFSInputStream;
- 连接到DataNode:调用输入流 FSDataInputStream.read( ) 方法从而让DFSInputStream 连接到 DataNodes;
- 从 DataNode 中获取数据:通过循环调用 read( ) 方法,从而将数据从 DataNode 传输到客户端;
- 读取另外的 DataNode 直到完成:到达块的末端时候,输入流 DFSInputStream 关闭与 DataNode 连接, 寻找下一个 DataNode;
- 完成读取,关闭连接:即调用输入流 FSDataInputStream.close( );
HDFS组成架构
介绍下HDFS,说下HDFS优缺点,以及使用场景
HDFS作用
HDFS的容错机制
HDFS的存储机制
HDFS的副本机制
HDFS的常见数据格式,列式存储格式和行存储格式异同点,列式存储优点有哪些?
HDFS如何保证数据不丢失?
HDFS NameNode高可用如何实现?需要哪些角色?
HDFS的文件结构?
HDFS的默认副本数?为什么是这个数量?如果想修改副本数怎么修改?
介绍下HDFS的Block
HDFS的块默认大小,64M和128M是在哪个版本更换的?怎么修改默认块大小?
HDFS的block为什么是128M?增大或减小有什么影响?
HDFS HA怎么实现?是个什么架构?
导入大文件到HDFS时如何自定义分片?
HDFS的mapper和reducer的个数如何确定?reducer的个数依据是什么?
HDSF通过那个中间组件去存储数据
HDFS跨节点怎么进行数据迁移
HDFS的数据-致性靠什么保证?
HDFS怎么保证数据安全
HDFS中向DataNode写数据失败了怎么办
Hadoop2.xHDFS快照
HDFS文件存储的方式?
HDFS写数据过程,写的过程中有哪些故障,分别会怎么处理?
NameNode存数据吗?
使用NameNode的好处
HDFS中DataNode怎么存储数据的
直接将数据文件上传到HDFS的表目录中,如何在表中查询到该数据?