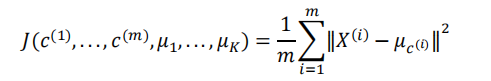1、微博聚类分析
要实现广告的精准投放,需要使用聚类找出兴趣一致的用户群体,这样就需要对用户进行聚类找出行为一致的用户,当对所有用户完成聚类之后,再使用关键词分析找出每个聚类群体中的用户的讨论主题,如果主题符合广告内容或者和广告内容相关,那么当前广告就可以推荐给当前用户群体,实现精准投放广告。
2、微博营销案例
object KMeans11 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("KMeans1").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.textFile("./original.txt")
/**
* wordRDD 是一个KV格式的RDD
* K:微博ID
* V:微博内容分词后的结果 ArrayBuffer
*/
var wordRDD = rdd.mapPartitions(iterator => {
val list = new ListBuffer[(String, ArrayBuffer[String])]
while (iterator.hasNext) {
//创建分词对象
val analyzer = new IKAnalyzer(true)
val line = iterator.next()
val textArr = line.split("\t")
val id = textArr(0)
val text = textArr(1)
//分词
val ts : TokenStream = analyzer.tokenStream("", text)
val term : CharTermAttribute = ts.getAttribute(classOf[CharTermAttribute])
ts.reset()
val arr = new ArrayBuffer[String]
while (ts.incrementToken()) {
arr.+=(term.toString())
}
list.append((id, arr))
analyzer.close()
}
list.iterator
})
wordRDD = wordRDD.cache()
/**
* HashingTF 使用hash表来存储分词
*
* 1000:只是计算每篇微博中1000个单词的词频 最大似然估计思想
*/
val hashingTF: HashingTF = new HashingTF(1000)
/**
* tfRDD
* K:微博ID
* V:Vector(tf,tf,tf.....)
*
* hashingTF.transform(x._2) 计算分词频数(TF)
*/
val tfRDD = wordRDD.map(x => {
(x._1, hashingTF.transform(x._2))
})
/**
* 得到IDFModel,要计算每个单词在整个语料库中的IDF
*/
val idf: IDFModel = new IDF().fit(tfRDD.map(_._2))
/**
* K:weibo ID
* V:每一个单词的TF-IDF值
* tfIdfs这个RDD中的Vector就是训练模型的训练集
*
*/
val tfIdfs: RDD[(String, Vector)] = tfRDD.mapValues(idf.transform(_))
//设置聚类个数
val kcluster = 20
val kmeans = new KMeans()
kmeans.setK(kcluster)
//使用的是kemans++算法来训练模型
kmeans.setInitializationMode("k-means||")
//设置最大迭代次数
kmeans.setMaxIterations(100)
val kmeansModel: KMeansModel= kmeans.run(tfIdfs.map(_._2))
// kmeansModel.save(sc, "d:/model001")
//打印模型的20个中心点
println(kmeansModel.clusterCenters)
/**
* 模型预测
*/
val modelBroadcast = sc.broadcast(kmeansModel)
/**
* predicetionRDD KV格式的RDD
* K:微博ID
* V:分类号
*/
val predicetionRDD = tfIdfs.mapValues(sample => {
val model = modelBroadcast.value
model.predict(sample)
})
// predicetionRDD.saveAsTextFile("d:/resultttt")
/**
* 总结预测结果
* tfIdfs2wordsRDD:kv格式的RDD
* K:微博ID
* V:二元组(Vector(tfidf1,tfidf2....),ArrayBuffer(word,word,word....))
*/
val tfIdfs2wordsRDD = tfIdfs.join(wordRDD)
/**
* result:KV
* K:微博ID
* V:(类别号,(Vector(tfidf1,tfidf2....),ArrayBuffer(word,word,word....)))
*/
val result = predicetionRDD.join(tfIdfs2wordsRDD)
/**
* 查看0号类别中tf-idf比较高的单词,能代表这类的主题
*/
result
.filter(x => x._2._1 == 0)
.flatMap(line => {
val tfIdfV: Vector = line._2._2._1
val words: ArrayBuffer[String] = line._2._2._2
val tfIdfA: Array[Double] = tfIdfV.toArray
val wordL = new ListBuffer[String]()
val tfIdfL = new ListBuffer[Double]()
var index = 0
for(i <- 0 until tfIdfA.length ;if tfIdfV(i) != 0){
wordL.+=(words(index))
tfIdfL.+=(tfIdfA(index))
index += 1
}
println(wordL.length + "===" + tfIdfL.length)
val list = new ListBuffer[(Double, String)]
for (i <- 0 until wordL.length) {
list.append((tfIdfV(i), words(i)))
}
list
})
.sortBy(x => x._1, false)
.map(_._2)
.distinct()
.take(30).foreach(println)
sc.stop()
}
}