Kafka Avro序列化之三:使用Schema Register实现
- 开发
- 45
-
为什么需要Schema Register
注册表
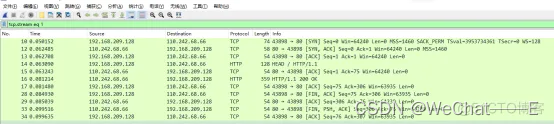
无论是使用传统的Avro API自定义序列化类和反序列化类 还是 使用Twitter的Bijection类库实现Avro的序列化与反序列化,这两种方法都有一个缺点:在每条Kafka记录里都嵌入了schema,这会让记录的大小成倍地增加。但是不管怎样,在读取记录时仍然需要用到整个 schema,所以要先找到 schema。有没有什么方法可以让数据共用一个schema?
我们遵循通用的结构模式并使用"schema注册表"来达到目的。"schema注册表"的原理如下:
原文地址:https://blog.csdn.net/u011026329/article/details/135011525
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1735944359624445952.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!