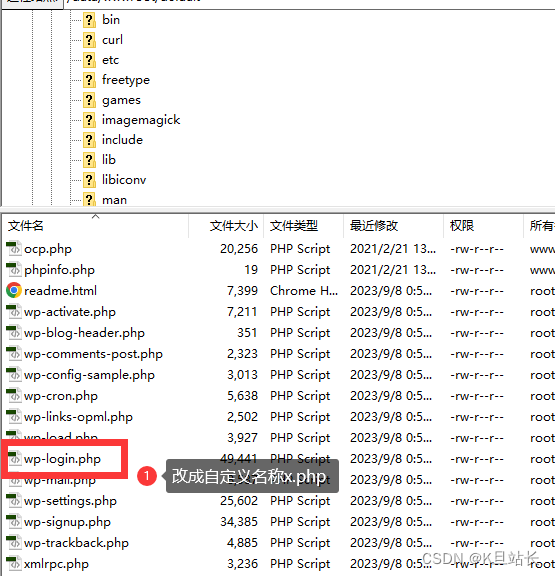
在信息时代,数据的重要性日益凸显。无论是商业决策、市场调研还是学术研究,数据的获取和分析都是不可或缺的环节。然而,手动收集大量数据费时费力,而且容易出错。在这样的背景下,虚拟多登浏览器作为一种自动化网络爬虫工具,以其快速、高效的数据收集能力备受瞩目。
1. 什么是虚拟多登浏览器?
VMLogin虚拟多登浏览器 (vmlogin.com.cn) 是一种利用多个虚拟浏览环境实现同时多开的软件工具,可以应用多种业务场景,其中包括就网络爬虫和数据收集,实现并行化数据采集。它通过同时运行多个浏览器实例,可以同时处理多个页面请求,从而大幅度提高数据收集的速度和效率。
2. 虚拟多登浏览器的优势
2.1 加速数据收集:同时处理多个页面请求,从而显著加快数据的收集速度。不同于传统的单一浏览器方式,虚拟多登浏览器更好地模拟了多用户的行为,降低了被网站识别为机器人的风险,提高了爬取数据的成功率。
2.2 优化爬虫策略:根据需要灵活配置虚拟浏览器的数量和参数,实现更好的任务分配和资源利用。这样可以提高爬虫的稳定性和可靠性,并避免被目标网站封禁或限制访问。
2.3 隐私保护:模拟多个用户的行为,使得网络爬虫更难被目标网站识别为机器人,并能处理网站交互操作,提高爬取数据的成功率。此外,虚拟多登浏览器还可以通过动态IP代理等技术手段,隐藏真实的IP地址,增加匿名性和隐私保护。
3. 使用自动化工具
目前市面上有多种自动化的工具可供选择,例如Selenium、Scrapy、Puppeteer等。另外,VMLogin浏览器也提供了丰富的功能和多个API接口,能够自动执行作业,简化爬虫的开发过程,并提供多线程、分布式等高级功能,进一步提高数据收集的效率。
在数据驱动的时代,它不仅能够加速数据收集,提高效率,还能为爬虫提供更好的隐私保护环境。通过合理配置虚拟浏览器的数量和设置,我们能够快速、稳定地获取所需数据,并在商业或学术领域中获得竞争优势。

























![[Knowledge Distillation]论文分析:Distilling the Knowledge in a Neural Network](https://img-blog.csdnimg.cn/direct/7c8dd08cb1d645a49e8d2b43455e982e.png)