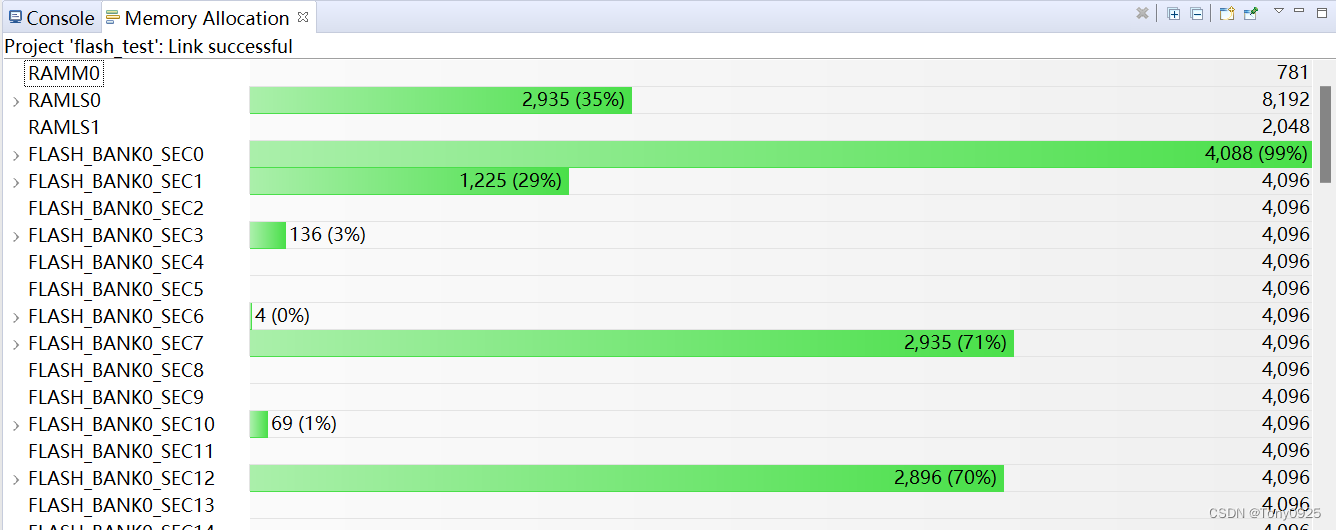
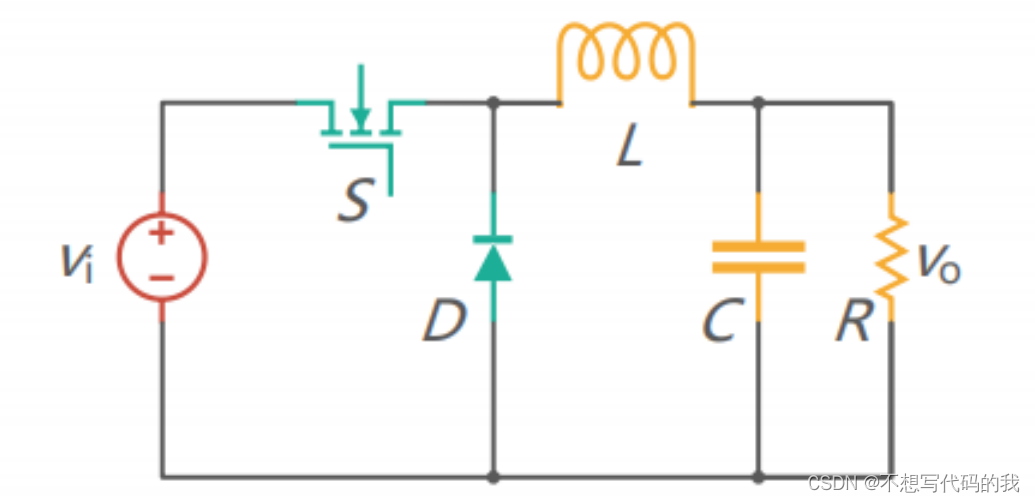
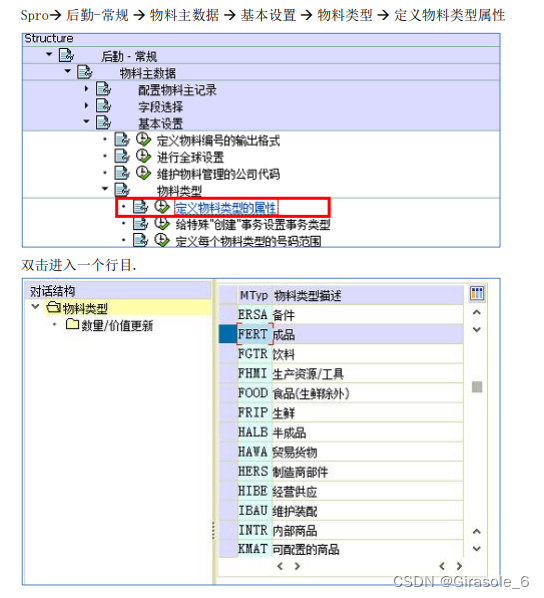
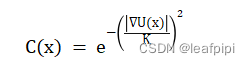import pandas as pd
df = pd.read_excel(r'C:\Users\wangkejun\Desktop\1.xls')
# 提取一一对应的数据
sku_list = []
channel_list = []
for sku, channel in zip(df['XXX'], df['XXXX']):
if pd.isna(channel): # 判断是否为缺失值
continue # 是缺失值则跳过该行数据
if ',' in str(sku): # 将sku转换为字符串类型
sku_items = str(sku).split(',')
channel_items = channel.split(',')
# 处理长度不一致的情况
min_len = min(len(sku_items), len(channel_items))
sku_list.extend(sku_items[:min_len])
channel_list.extend(channel_items[:min_len])
# 创建新的DataFrame
new_df = pd.DataFrame({
'XXX': sku_list,
'XXXX': channel_list
})
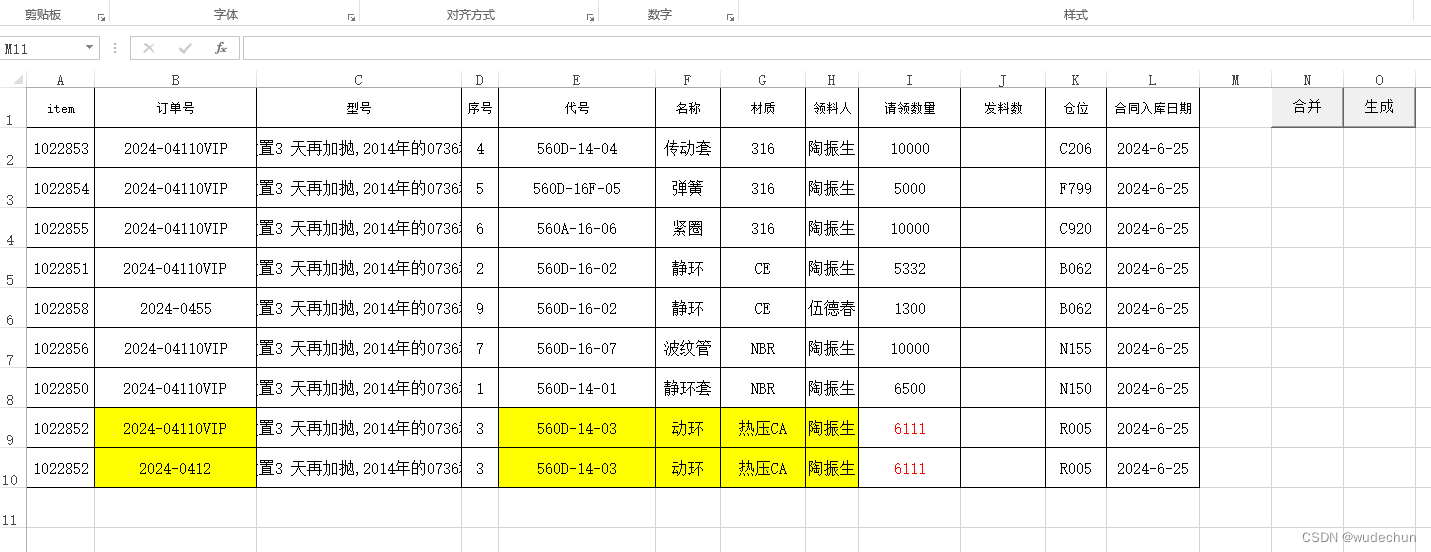
new_df.to_excel(r'C:\Users\wangkejun\Desktop\1.xlsx')原数据
![]()
结果
![]()
- 使用zip()函数将两列数据进行逐行遍历,sku和channel分别对应每一行的"XXXX"和"XXXX";
- 判断channel是否为缺失值,如果是则跳过该行数据,不做处理;
- 如果sku中包含逗号(,),则说明一个发货单中有多个产品,需要将sku和channel分别按照逗号进行拆分;
- 处理长度不一致的情况,将sku和channel的长度取最小值,只保留相同数量的数据,并将其分别存入sku_list和channel_list中。