全文检索介绍
全文检索的发展过程:
- 数据库使用SQL语句:select * from table where data like “%检索内容%”
- 出现lucene全文检索工具(缺点:暴露的接口相对复杂,且没有效率)
- 出现分布式检索服务框架solr(缺点:建立索引期间。solr搜索能力极度下降,造成实时索引效率不高)
- 出现 Elasticsearch ,是以lucene为基础,基于Restful接口进行发布
非结构化数据查找方法
- 顺序扫描法:遍历所有文件,找到所包含的字符
- 全文检索:将非结构化数据中的一部分信息提取,重新组织,使其变得具有一定结构,然后对此有一定结构的数据进行检索。这部分从非结构数据中提取重新组织的信息称之为索引,这种先建立索引,再对索引进行搜索的过程叫做全文检索(full-text search)
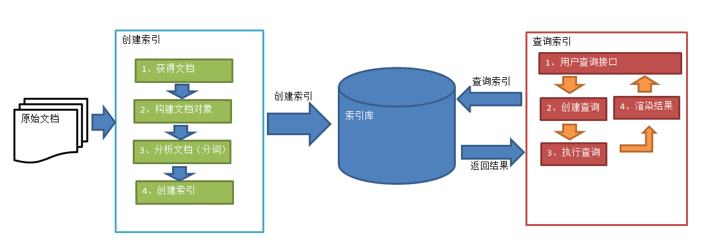
Lucene全文检索流程
ES
ES简介
ES与Solr对比
- Solr使用zookeeper进行分布式管理,而ES自身带有分布式协调管理
- Solr支持更多格式数据,而ES仅支持json
- Solr官方提供功能更多,而ES本身更注重核心功能,高级功能由第三方插件提供
- ES在处理实时搜索应用时效高于Solr
ES架构模块
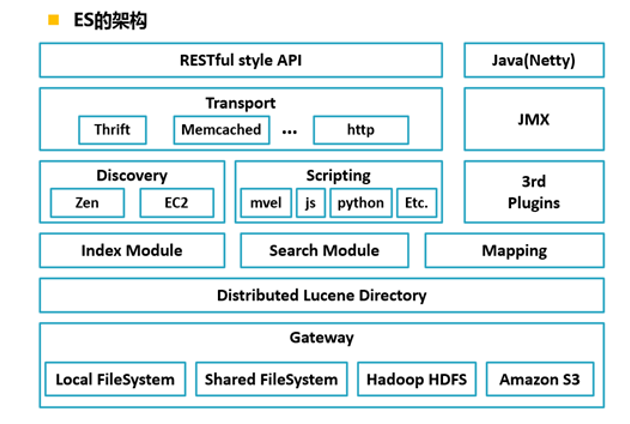
- Gateway:存储索引的文件系统,支持多种类型(Local本地、Shared分片、Hadoop、Amazon)
- Distributed Lucene Directory:分布式的Lucene框架
- Lucene之上是ES 的模块,包括:索引模块、搜索模块、映射解析模块
- ES之上是Discovery、Scripting和第三方插件
- Discovery:ES 的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部master选举等,支持多种发现机制,如Zen、EC2
- Scripting:用来支持查询语句插入JavaScript、python等脚本语言,Scripting模块负责解析这些脚本,但使用这些脚本性能较低,同时ES也支持多种第三方插件
- 再往上Transport模块:主要是ES的传输模块和JMX(Java的管理框架)传输模块,支持多种传输协议,如Thrift、Memacached、http等,默认是http
- 再往上就是ES提供的用户接口
核心概念
- 索引ndex:就是一堆有相似结构的文档数据,用于区分文档成组,即分到一组的文档集合
- 类型Type:用于区分索引中的文档,即在索引中对数据逻辑分区。比如将博客平台所有数据存储到一个索引中,在该索引中,可为用户数据、博客数据、评论数据等分别定义一个type
- 文档Document:指定了唯一 ID 的最底层或者根对象,ES的最小数据单元
- 字段Field:定义Document应有的字段
ES与MySQL类比:

集群cluster:由多个节点组织在一起,共同持有整个集群数据(注意:一个集群有唯一的名字标识,默认是“elasticsearch”。一个节点只能通过指定某个集群的名字加入该集群)
节点node:集群中的一个服务器
一个节点由一个名字标识,默认情况是随机的“漫威漫画角色名字”
一个节点可通过配置集群名称方式加入指定集群,默认下,每个节点都被安排到“elasticsearch”集群中
若启动第一个节点,会默认创建并加入到叫“elasticsearch”的集群分片shard
一个索引可存储超出某节点硬件限制的大量数据,比如一个10亿文档的索引占据1T磁盘空间,而任一节点都没有这么大的磁盘空间;或单个节点处理请求响应太慢。为解决此类问题,ES将索引划分为多份shard的能力,称为分片。
创建一个索引的时候,可指定分片数量,每个分片本身就是一个功能完整且独立的“索引”,该“索引”可被放置到集群的任何节点
分片的作用:
- 允许水平分割/扩展容量
- 允许在分片上进行分布式、并行的操作,进而提高性能/吞吐量
对于一个分片如何分布,文档是如何聚合响应搜索请求,完全由ES管理,对于用户是透明的
- 副本replica
在分布式环境下,任何分片/节点都可能失效,导致index无法搜索,所以为了保证数据安全,会将每个index分片进行复制备份,这种拷贝称为副本replica
副本的作用:
- 在分片/节点失效情况下,提供高可用性(注意到ES的副本分片从不与 原/master 分片置于同一节点上)
- 扩展搜索量/吞吐量,因为搜索可在所有复制上并行运行
总之,每个索引可被分为多个分片,每个索引可被复制0-n次。一旦创建副本,每个索引就有了主分片和副本分片。分片和副本的数量可在索引创建时指定,创建完成后,可改变副本数量,但无法改变分片的数量
默认情况下,ES分片配置是5、副本数配置是1(如果集群至少2个节点,该索引将会有5个主分片、5个副本分片(完全拷贝),该索引总共有10个分片)
分词查询
举例说明:
文本:“我正在学习数据结构和算法”
对文本查询一般分为三种:
- 模糊查询:类似sql中的like查询
“学习”、“数据结构”、“算法”能搜索到结果 - 精确搜索:文本内容与搜索关键词一致
关键词一定要是“我正在学习数据结构和算法”才匹配 - 分词搜索:对搜索关键字和搜索内容都进行分词,只要匹配到一个分词内容,就命中相关内容
“算法之美”也能搜索到结果,因为分词搜索,只需关键字的分词匹配到即可(用模糊查询是无法搜索出结果)
在ES中,使用term、match、match_phrase、keyword进行相关搜索
涉及多个关键字
text和keyword是数据类型,对磁盘待查询数据是否进行分词
- text:分词,在写入磁盘时,分割成多个独立单词,然后存入倒排索引。查询时也是以单词维度进行匹配
- keyword:不分词,存放整个短语
math和term是搜索方式,是数据查询时,要查询的短语是否进行分词
- match:对搜索的内容进行分词,拿分词数据去倒排索引中查询
- term:不对搜索内容进行分词,是完全匹配
数据准备,在索引base-product-spu-info中有一条数据
{
"spuName" : "【市场价2532】HUAWEI WATCH 2 Pro 4G智能手表 移动支付"
}
查看其分词结果:
GET base-product-spu-info/_analyze
{
"analyzer": "standard",
"text": "【市场价2532】HUAWEI WATCH 2 Pro 4G智能手表 移动支付"
}
// 分词结果:市|场|价|2532|huawei|watch|2|pro|4g|智|能|手|表|移|动|支|付
term搜索
term搜索对搜索词不分词,但还是会对要搜索的字段进行分词。一旦加上keyword属性,就不对数据进行分词,变成精确搜索
注意:默认情况下,不加keyword属性,使用的是text
- 搜索关键字“智”(term+text)
GET base-product-spu-info/_search
{
"query": {
"term": {
"spuName": {
"value": "智"
}
}
}
}
// 结果:搜索出数据
QueryBuilders.termQuery("spuName", "智");
- 搜索关键字“智能”
结果:无匹配数据(分词结果中无此分词) - 搜索关键字“Pro”
结果:无匹配数据 - 搜索关键字“pro”
结果:搜索出数据 - 搜素关键字“【市场价2532】HUAWEI WATCH 2 Pro 4G智能手表 移动支付”
结果:无匹配数据(因为搜索词未分词) - 搜索关键字“【市场价2532】HUAWEI WATCH 2 Pro 4G智能手表 移动支付”【加上keyword关键字】(term+keyword)
GET base-product-spu-info/_search
{
"query": {
"term": {
"spuName.keyword": {
"value": "【市场价2532】HUAWEI WATCH 2 Pro 4G智能手表 移动支付"
}
}
}
}
// 结果:搜索出数据
match搜索
match会对搜索词进行分词,再进行分词搜索(同时不加keyword的情况下,数据也会分词)
GET base-product-spu-info/_search
{
"query": {
"match": {
"spuName": "手机"
}
}
}
// 结果:搜索出数据(分词为“手|机”,命中数据分词)
QueryBuilders.matchQuery("spuName", "手机");
match_phrase搜索
match_phrase搜索为短语搜索,要求短语中所有分词必须同时出现在文档中,同时位置必须一致
GET base-product-spu-info/_search
{
"query": {
"match_phrase": {
"spuName": "智能手表"
}
}
}
// 结果:搜索出数据
QueryBuilders.matchPhraseQuery(“spuName”,"智能手表");
假若搜索关键字“智能手表1”,则无法匹配数据,因为分词“1”并不在数据分词中,所以无法命中。同样的,“手表智能”也无法命中
match_phrase_prefix
与match_phrase用法类似,区别在于,它允许对最后一个词条进行前缀匹配
GET base-product-spu-info/_search
{
"query": {
"match_phrase_prefix": {
"spuName": "智能手表"
}
}
}
// 结果:搜索出数据
QueryBuilders.matchPhrasePrefixQuery("spuName","智能手表")
说明:此处“智能手表”进行分词,其中“智|能|手”与分词进行匹配,“表”可进行前缀匹配,类似“表%”,意味着若分词表中存在“表现、表示、表哥我出来了哦”等分词时,也能命中。
总结
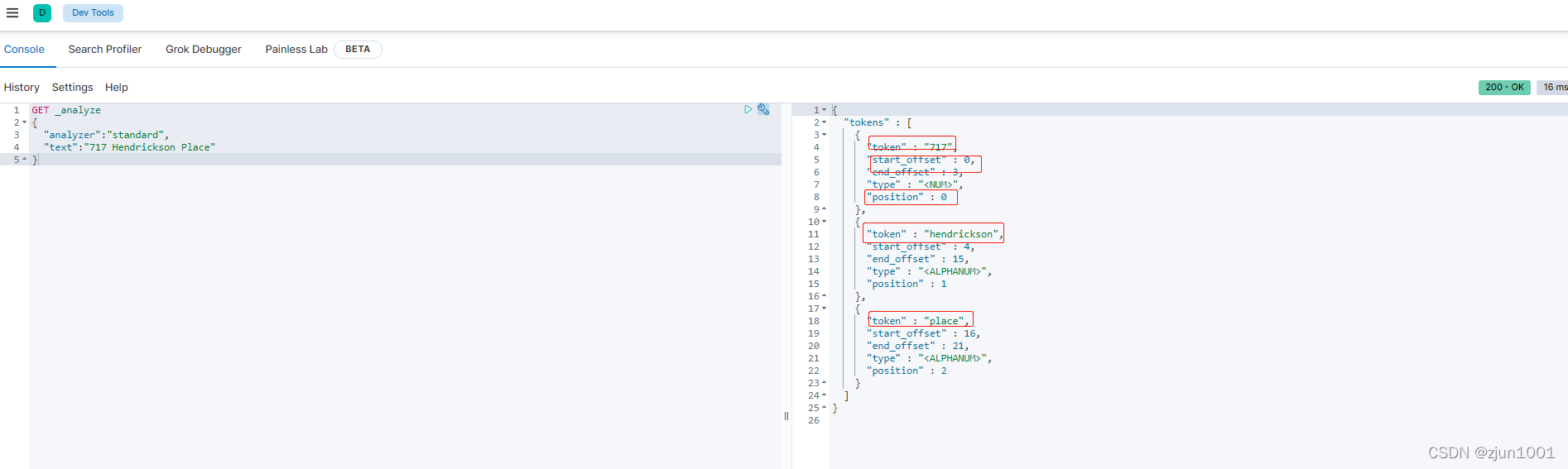
- token:分词后的单词,小写
- start_offset:在短语中的开始位置
- end_offset:短语中的结束位置
- position:单词在短语中的位置,即第几个单词
总结:比如有一个文档字段“717 Hendrickson Place”,分词结果如上图:
- 对关键字“717 Hendrickson Place”使用【term+keyword】搜索
结果:有结果(关键词不分词,精确匹配) - 对关键字“717 Hendrickson Place01”使用【term+keyword】搜索
结果:无匹配结果(改动了Place) - 对关键字“717 Hendrickson Place”使用【match+keyword】搜索
结果:有结果(数据字段不分词,精确匹配) - 对关键字“717 Hendrickson Place01”使用【match+keyword】搜索
结果:无匹配结果(数据字段不分词,精确匹配) - 对关键字“717 Hendrickson Place”使用【term+text】搜索
结果:无匹配结果(关键词未分词,字段数据分词,“717 Hendrickson Place”未名中分词) - 对关键字“717 Hendrickson Place”使用【match+text】搜索
结果:有结果(关键词和字段数据都分词,“717”分词命中) - 对关键字“717 Hendrickson Place01”使用【match+text】搜索
结果:有结果(这里改动了Place,“717”分词命中) - 对关键字“Hendrickson”使用【term+text】搜索
结果:无匹配结果(关键词未分词,字段数据分词,分词未命中) - 对关键字“hendrickson”使用【term+text】搜索
结果:有结果(Hendrickson改为小写 hendrickson)




















![关于ctf反序列化题的一些见解([MRCTF2020]Ezpop以及[NISACTF 2022]babyserialize)](https://img-blog.csdnimg.cn/direct/15a60bd5ee1545f5917e2ad1e2e7cb29.png)




![记录 | mac打开终端时报错:login: /opt/homebrew/bin/zsh: No such file or directory [进程已完成]](https://img-blog.csdnimg.cn/direct/690fc02b7d544103b30a65b0d78e884f.png#pic_center)