一:特殊类设计
1.1:设计一个类,不能被拷贝/继承
1.2:设计一个类,只能在堆/栈上创建对象
1.3:设计一个类,只允许创建一个对象(单例模式)
二:类型转换
2.1:C语言中的类型转换
2.2:C++中的类型转换
2.2.1:static_cast
2.2.2:reinterpret_cast
2.2.3:const_cast
2.2.4:dynamic_cast
2.3:RTTI
三:IO流
3.1:C++中的IO流
3.1.1:标准IO流
3.1.2:文件IO流
3.1.3:stringstream
一:特殊类设计
1.1:设计一个类,不能被拷贝/继承
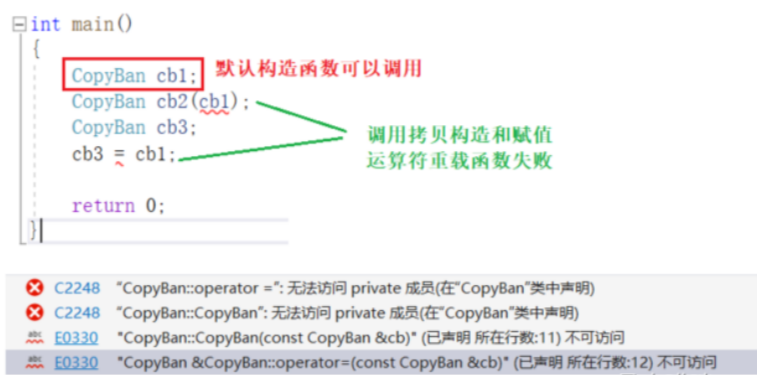
不能被拷贝:拷贝只会发生在两个场景中:拷贝构造函数以及赋值运算符重载!因此想要让一个类禁止拷贝,只需让该类不能调用拷贝构造函数以及赋值运算符重载即可!
在C++98中:如果想让一个类不能被拷贝,只需要将拷贝构造函数与赋值运算符重载只声明不定义,并且将其访问权限设置为私有即可。
只声明不定义:不定义是因为该函数根本不会调用,定义了其实也没有什么意义。
设置成私有:如果只声明没有设置成private,用户自己如果在类外定义了,就可以不能禁止拷贝了!
在C++11中:C++11扩展delete的用法,delete除了释放new申请的资源外,如果在默认成员函数后跟上=delete,则表示让编译器删除掉该默认成员函数!
不能被继承:
在C++98中:如果不想让一个类被继承,则只需要将这个类的构造函数封成私有(private),这样的话如果被继承,则子类无法调用父类的构造函数,即无法构造子类!
在C++11中:使用final关键字,用final修饰类,将final放到类名后面,表示该类不能被继承!
1.2:设计一个类,只能在堆/栈上创建对象
只能在堆上创建对象:
思路一:将析构函数封为私有+公有的删除函数!具体如下所示:
class HeapOnly
{
public:
HeapOnly(int x = 0)
:_x(x)
{
cout << "HeapOnly()" << endl;
}
//公有的删除函数!
void Delete_Hp()
{
delete this;
}
private:
~HeapOnly()//将析构函数封为私有
{
cout << "~HeapOnly()" << endl;
}
private:
int _x;
};
int main()
{
//此时就不能正常的创建对象了!
//HeapOnly h1(1);
//static HeapOnly h2(2);
//但是我们可以通过new来创建,虽然创建是创建出来了,但是无法删除,因为调不到析构函数!
HeapOnly* h3 = new HeapOnly;
//delete h3;//我们也不可以直接delete这个对象指针!
//我们只能在类中创建一个公有的删除函数,直接删除掉this指针!
h3->Delete_Hp();
return 0;
}我们一旦将析构函数封成私有,那么像平常那样创建普通对象的手段就不可以了,因为创建的普通对象必须在对象生命周期结束时默认调用析构函数,而析构函数私有,则会使对象无法析构!那么此时,我们只能通过new来创建一个对象指针,通过指针来访问这个对象!
但是对象指针仍然无法释放掉这个对象,此时我们需要在类中创建一个公有的删除函数,然后通过这个对象指针显式的调用!具体如下所示:
思路二:将构造函数封为私有+公有的、获取对象的静态成员函数+拷贝构造/赋值封掉!具体如下所示:
//思路二:构造函数私有+公有的、获取对象的静态成员函数!
class HeapOnly
{
public:
//公有的,静态的获取对象的成员函数!
static HeapOnly* CreateObj(int x = 0)
{
HeapOnly*ph= new HeapOnly(x);
return ph;
}
~HeapOnly()//将析构函数封为私有
{
cout << "~HeapOnly()" << endl;
}
//将拷贝构造和拷贝赋值封掉!防止在栈上拷贝/赋值对象!
HeapOnly(const HeapOnly& hp) = delete;
HeapOnly& operator=(const HeapOnly& hp) = delete;
private:
HeapOnly(int x = 0)
:_x(x)
{
cout << "HeapOnly()" << endl;
}
private:
int _x;
};
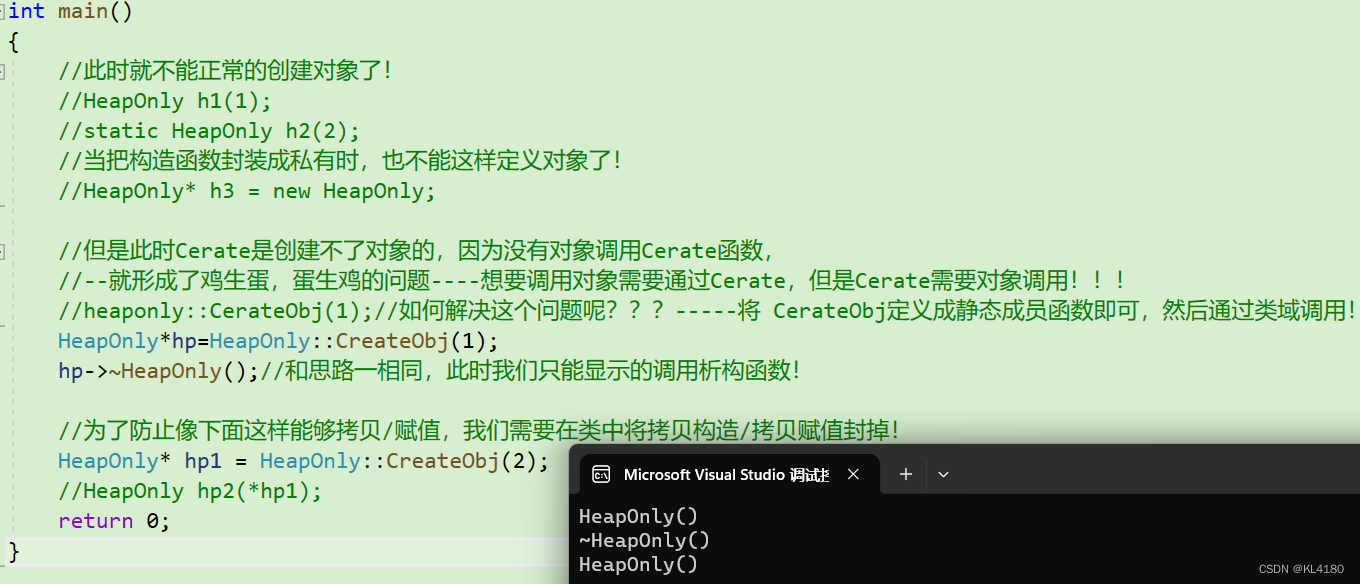
int main()
{
//此时就不能正常的创建对象了!
//HeapOnly h1(1);
//static HeapOnly h2(2);
//当把构造函数封装成私有时,也不能这样定义对象了!
//HeapOnly* h3 = new HeapOnly;
//但是此时Cerate是创建不了对象的,因为没有对象调用Cerate函数,
//--就形成了鸡生蛋,蛋生鸡的问题----想要调用对象需要通过Cerate,但是Cerate需要对象调用!!!
//heaponly::CerateObj(1);//如何解决这个问题呢???-----将 CerateObj定义成静态成员函数即可,然后通过类域调用!
HeapOnly*hp=HeapOnly::CreateObj(1);
hp->~HeapOnly();//和思路一相同,此时我们只能显示的调用析构函数!
//为了防止像下面这样能够拷贝/赋值,我们需要在类中将拷贝构造/拷贝赋值封掉!
HeapOnly* hp1 = HeapOnly::CreateObj(2);
//HeapOnly hp2(*hp1);
return 0;
}我们将构造函数封为私有,那么即使像思路一那样new一个对象指针也不行,根本没有办法构造对象,那么我们此时只能在类中创建一个公有的获取对象的成员函数,在这个成员函数内部调用构造函数,构造对象!
但是我们无法调用这个成员函数,因为调用成员函数我们需要类对象,而创建类对象我们需要这个成员函数,此时就形成了“鸡生蛋,蛋生鸡”的问题,那如何解决呢????---------只需要将这个成员函数设置为静态成员函数(即static成员函数),此时我们就可以在类外调用(用类域调用)!
同时为了防止拷贝(如果此时可以拷贝,那么拷贝的对象将在栈上!),我们需要将拷贝构造/赋值封掉(用C++11的方式封掉)!具体如下所示:
只能在栈上创建对象:
思路:封掉构造函数++公有的、获取对象的静态成员函数!
//请设计一个类,只能在栈上创建对象
//思路:封掉构造函数++公有的、静态获取对象的成员函数!
class StackOnly
{
public:
//和上面的思路二一样,唯一不同的是:这里是直接调用构造函数,而不是new一个对象指针!
static StackOnly CreateObj(int x)
{
return StackOnly(x);//调用构造函数,传值返回!!!
}
~StackOnly()
{
cout << "~StackOnly()" << endl;
}
//此时我们不能封掉拷贝构造/赋值,因为我们构造对象时是传值返回的,需要拷贝!!!
//StackOnly(const StackOnly& sk) = delete;
//StackOnly& operator=(const StackOnly& sk) = delete;
private:
StackOnly(int x = 0)
:_x(x)
{
cout << "StackOnly()" << endl;
}
private:
int _x;
};
int main()
{
//和之前一样,封掉拷贝构造,这三种创建对象的方法就不行了!
//StackOnly sk(1);
//static StackOnly sk1(2);
//StackOnly* sk3 = new StackOnly(3);
//此时我们就可以在栈上创建对象
StackOnly sk4 = StackOnly::CreateObj(4);
//但是此时我们却可以拷贝构造一个静态对象!因为我们没有封掉拷贝构造,那如何解决?封掉拷贝构
造/赋值???
//我们也不能封掉拷贝构造,因为构造对象时我们是传值返回,需要拷贝!
//所以在这里我们没有很好的办法能封死不让创建静态对象,我们只能封死不让在堆上创建对象!
static StackOnly sk5=sk4;
return 0;
}和上面只能在堆上创建对象的思路二一样,但是和它唯一不同的是:我们不能封掉拷贝构造/赋值,因为我们在栈上构造对象时是传值返回,需要调用构造函数!
但是我们如果不封掉拷贝构造/赋值,可能存在另一个问题:我们可以拷贝构造/赋值创建静态对象(static对象),这就不符合我们只能在栈上创建对象的需求了!可是我们没有很好的办法解决这个问题,因为我们不能禁掉拷贝构造/赋值!!!
1.3:设计一个类,只允许创建一个对象(单例模式)
单例模式(Singleton Pattern)是一种创建型设计模式!即一个类只能创建一个对象,该模式可以保证系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。比如在某个服务器程序中,该服务器的配置信息存放在一个文件中,这些配置数据由一个单例对象统一读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,这种方式简化了在复杂环境下的配置管理!单例模式有两种实现模式:
1.3.1:饿汉模式:就是说不管你将来用不用,程序启动时(main之前)就创建一个唯一的实例对象(静态成员变量初始化)!具体实现思想如下所示:
1:全局只能有一个实例,如何做到不能随便定义对象???----------将构造函数私有化!
2:构造函数私有化了,该如何获取到实例对象???----------创建一个公有的静态成员函数,获取实例对象!
3:如何保证获取到的实例对象是唯一的???----------定义一个全局的静态成员变量,同时在类外面初始化的时候创建实例对象!
具体实现如下所示:
//单例模式:饿汉模式:
class singleton
{
public:
//通过公有的静态成员函数获取全局唯一一份的实例化对象!
static singleton* GetInstance()
{
return _ins;
}
void Add(const string& str)
{
_vs.push_back(str);
}
void pint()
{
for (auto& e : _vs)
{
cout << e.c_str() << " ";
}
cout << endl;
}
~singleton()
{
cout << "~singleton()" << endl;
}
//同时我们需要将拷贝构造/赋值封掉!!!防止被拷贝!
singleton(const singleton& s) = delete;
singleton& operator=(const singleton& s) = delete;
private:
singleton()//将构造函数私有化,来实现单例,防止随意创建对象!
{
cout << "singleton()" << endl;
}
private:
vector<string> _vs;
static singleton* _ins;//定义一个全局的静态成员变量
};
//静态成员变量需要在类外面初始化,饿汉模式就是在初始化的时候就创建实例对象!
singleton* singleton::_ins = new singleton;
int main()
{
//此时只能通过成员函数获取实例对象,同时访问这个类!
singleton::GetInstance()->Add("大大怪");
singleton::GetInstance()->Add("小小怪");
singleton::GetInstance()->Add("开心");
//singleton::Add();这种写法是错误的,因为没有类对象访问不了类中的成员函数!
singleton::GetInstance()->pint();
//看一看这个实例的类型名称:
cout << typeid(singleton::GetInstance()).name() << endl;
return 0;
}这里我们可以看到,当我们想访问这个类中的任何成员函数/变量,只能通过GetInstance这个静态成员函数获取实例对象从而进行访问!即这个实例对象全局只有一份!而正是因为全局内只有一份实例对象的特性,使得饿汉模式在多线程下是线程安全的(即多线程下无论线程干了什么,都只是在改变同一个实例对象,同时创建对象是在main函数之前,main函数之前创建实例对象是没有线程安全问题的!);具体如下所示:
//饿汉模式下的多线程:
class singleton
{
public:
//通过公有的静态成员函数获取全局唯一一份的实例化对象!
static singleton* GetInstance()
{
return _ins;
}
void Add(const string& str)
{
_mtx.lock();
_vs.push_back(str);
_mtx.unlock();
}
void pint()
{
_mtx.lock();
for (auto& e : _vs)
{
cout << e.c_str() << endl;
}
cout << endl;
_mtx.unlock();
}
~singleton()
{
cout << "~singleton()" << endl;
}
private:
singleton()//将构造函数私有化,来实现单例,防止随意创建对象!
{
cout << "singleton()" << endl;
}
private:
mutex _mtx;//加锁保护线程中的操作,使对实例对象的操作是线程安全的!
vector<string> _vs;
static singleton* _ins;//定义一个全局的静态成员变量
};
//静态成员变量需要在类外面初始化,饿汉模式就是在初始化的时候就创建实例对象!
singleton* singleton::_ins = new singleton;
//多线程下的饿汉模式:
int main()
{
int n = 10;
srand((unsigned int)time(nullptr));
thread t1([n]()
{
for (size_t i = 0; i < n; ++i)
{
singleton::GetInstance()->Add("t1线程: " + to_string(rand()));
}
});
thread t2([n]()
{
for (size_t i = 0; i < n; ++i)
{
singleton::GetInstance()->Add("t2线程: " + to_string(rand()+i));
}
});
t1.join();
t2.join();
singleton::GetInstance()->pint();
return 0;
}
所以说如果我们想要在多线程下,保证类中的数据(成员变量等)全局有且只有一份,那么我们可以将其设计成单例模式(饿汉模式)!
与饿汉模式与之对应的单例模式是懒汉模式!!
1.3.2:懒汉模式:第一次使用实例对象时,才创建这个实例对象。
具体实现思想和饿汉模式差不多,唯一有区别的是:饿汉是在初始化静态成员变量时就直接创建(new)一个实例对象,而懒汉模式虽然也是定义一个静态成员变量,但是初始化为空,只是在第一次使用实例对象时(即调用GetInstance函数时)才创建(new)一个实例对象!具体实现如下所示:
class singleton
{
public:
//通过公有的静态成员函数获取全局唯一一份的实例化对象!
static singleton* GetInstance()
{
//如果是第一次调用GetInstance函数时,实例化对象肯定是nullptr!
//那么此时就创建(new)一个实例对象!
if (_ins == nullptr)
{
_ins = new singleton;
}
//如果不是第一次调用,那么此时直接将全局存在的唯一一份实例对象返回!
return _ins;
}
void Add(const string& str)
{
_mtx.lock();
_vs.push_back(str);
_mtx.unlock();
}
void pint()
{
_mtx.lock();
for (auto& e : _vs)
{
cout << e.c_str() << endl;
}
cout << endl;
_mtx.unlock();
}
~singleton()
{
cout << "~singleton()" << endl;
}
private:
singleton()//将构造函数私有化,来实现单例,防止随意创建对象!
{
cout << "singleton()" << endl;
}
private:
mutex _mtx;
vector<string> _vs;
static singleton* _ins;//定义一个全局的静态成员变量
};
//静态成员变量需要在类外面初始化,懒汉模式与饿汉模式不同,懒汉模式初始化为空!
//singleton* singleton::_ins = new singleton;//饿汉模式!
singleton * singleton::_ins = nullptr;//懒汉模式!
//懒汉模式:
int main()
{
//此时只能通过成员函数获取实例对象,同时访问这个类!
singleton::GetInstance()->Add("大大怪");
singleton::GetInstance()->Add("小小怪");
singleton::GetInstance()->Add("开心");
//singleton::Add();这种写法是错误的,因为没有类对象访问不了类中的成员函数!
singleton::GetInstance()->pint();
//看一看这个实例的类型名称:
cout << typeid(singleton::GetInstance()).name() << endl;
return 0;
}如上所示,这就是懒汉模式,可是我们发现,懒汉模式除了没有在初始化静态成员函数时创建对象(而是在GetInstance函数内创建对象)之外,和饿汉模式没有任何的区别呀!!!
其实不然,我们上面的懒汉模式存在线程安全的问题,因为在多线程并发时,如果多个线程同时调用了GetInstance函数想要创建实例对象时,if判断语句可能存在并发问题!所以我们需要加锁来保证创建实例对象时的线程安全!具体如下所示:
//多线程下的懒汉模式:
class singleton
{
public:
//虽然这样可以解决并发问题,但是这样加锁,我们每次获取实例对象都需要加锁解锁!
// 而我们的要求只是在第一次时加锁解锁保护线程安全!所以这样写不是最优解!
//static singleton* GetInstance()
//{
// _GImtx.lock();
// if (_ins == nullptr)
// {
// _ins = new singleton;
// }
// _GImtx.unlock();
// return _ins;
//}
//双检查加锁:
static singleton* GetInstance()
{
if (_ins == nullptr)//这个if判断是提高效率,防止每一次调用实例对象时都加锁解锁!
{
_GImtx.lock();
if (_ins == nullptr)//这一个if判断是解决并发问题,保证线程安全,只创建(new)一次!
{
_ins = new singleton;
}
_GImtx.unlock();
}
return _ins;
}
void Add(const string& str)
{
_mtx.lock();
_vs.push_back(str);
_mtx.unlock();
}
void pint()
{
_mtx.lock();
for (auto& e : _vs)
{
cout << e.c_str() << endl;
}
cout << endl;
_mtx.unlock();
}
~singleton()
{
cout << "~singleton()" << endl;
}
private:
singleton()//将构造函数私有化,来实现单例,防止随意创建对象!
{
cout << "singleton()" << endl;
}
private:
mutex _mtx;
vector<string> _vs;
static singleton* _ins;//定义一个全局的静态成员变量
static mutex _GImtx;//定义一把全局的静态锁,为了解决懒汉模式下创建实例对象的并发问题!
};
//静态成员变量需要在类外面初始化,懒汉模式与饿汉模式不同,懒汉模式初始化为空!
//singleton* singleton::_ins = new singleton;//饿汉模式!
singleton* singleton::_ins = nullptr;//懒汉模式!
mutex singleton::_GImtx;//初始化静态锁!
//多线程下的懒汉模式:
int main()
{
int n = 10;
srand((unsigned int)time(nullptr));
thread t1([n]()
{
for (size_t i = 0; i < n; ++i)
{
singleton::GetInstance()->Add("t1线程: " + to_string(rand()));
}
});
thread t2([n]()
{
for (size_t i = 0; i < n; ++i)
{
singleton::GetInstance()->Add("t2线程: " + to_string(rand()+i));
}
});
t1.join();
t2.join();
singleton::GetInstance()->pint();
return 0;
}此时,我们通过双检测加锁即可完美的解决懒汉模式线程不安全的问题!!!
那单例对象该如何释放呢???
答:一般情况下,不需要显式的释放单例对象!!!因为一般单例都要全局使用,所以我们基本上不要自己显示释放,----但是如果在一些特殊的场景下,有需要自己显示释放单例对象的可能,所以下面我们实现一下!
//单例模式的释放:一般单例都要使用全局,所以我们基本上不要自己显示释放,----但是又自己显示释放的可能,所以我们实现一下!
class singleton
{
public:
static singleton* GetInstance()
{
if (_ins == nullptr)//双检查加锁!
{
_GImtx.lock();
if (_ins == nullptr)
{
_ins = new singleton;
}
_GImtx.unlock();
}
return _ins;
}
//显示释放一下!
static void delete_Insrance()
{
_GImtx.lock();
if (_ins != nullptr)
{
delete _ins;//当delete掉这个实例对象时,它就会调用析构函数!
_ins = nullptr;
}
_GImtx.unlock();
}
void Add(const string& s1)
{
_mtx.lock();
_vs.push_back(s1);
_mtx.unlock();
}
void print()
{
_mtx.lock();
for (auto& e : _vs)
{
cout << e << endl;
}
_mtx.unlock();
}
//而此时就可以在析构函数中做持久化操作!
~singleton()
{
//持久化:比如要求程序结束的时候,将数据写到文件中去!那么此时,单例模式就在析构函数的时候做持久化比较好!
cout << "~singleton()" << endl;
}
private:
singleton()
{
cout << "singleton()" << endl;
}
private:
mutex _mtx;
vector<string> _vs;
static singleton* _ins;
static mutex _GImtx;
};
singleton* singleton::_ins = nullptr;
mutex singleton::_GImtx;
int main()
{
//此时只能通过成员函数获取实例对象,同时访问这个类!
singleton::GetInstance()->Add("大大怪");
singleton::GetInstance()->print();
singleton::GetInstance()->delete_Insrance();
return 0;
}但是这种显式调用释放单例模式的方法不太好,因为有时候我们可能忘记自己显示的释放,所以还有一种通过内部类的方式,来保证单例对象的自动回收!具体如下所示:
//内部类保证单例对象的自动回收:
class singleton
{
public:
static singleton* GetInstance()
{
if (_ins == nullptr)//双检查加锁!
{
_GImtx.lock();
if (_ins == nullptr)
{
_ins = new singleton;
}
_GImtx.unlock();
}
return _ins;
}
//通过内部类的方式保证单例对象的释放:
class GC
{
public:
~GC()
{
delete_Insrance();//调用单例对象的析构函数!
}
};
static GC _gc;//创建一个静态的GC对象,那么当程序结束时,静态成员变量要被销毁!
//销毁时,调用GC这个内部类的析构函数,而在GC类的析构函数中,
//我们显式的调用了单例对象的释放函数,即又再调用单例对象的析构函数!!!
//显示释放一下!
static void delete_Insrance()
{
_GImtx.lock();
if (_ins != nullptr)
{
delete _ins;//当delete掉这个实例对象时,它就会调用析构函数!
_ins = nullptr;
}
_GImtx.unlock();
}
void Add(const string& s1)
{
_mtx.lock();
_vs.push_back(s1);
_mtx.unlock();
}
void print()
{
_mtx.lock();
for (auto& e : _vs)
{
cout << e << endl;
}
_mtx.unlock();
}
~singleton()
{
cout << "~singleton()" << endl;
}
//我们为了防止拷贝也必须将单例模式的拷贝和运算符重载禁止掉,---上面因为有锁的存在,所
以没有禁止拷贝与赋值重载!
singleton(const singleton& s) = delete;
singleton& operator=(const singleton& s) = delete;
private:
singleton()
{
cout << "singleton()" << endl;
}
private:
mutex _mtx;
vector<string> _vs;
static singleton* _ins;
static mutex _GImtx;
};
singleton* singleton::_ins = nullptr;
mutex singleton::_GImtx;
singleton::GC singleton::_gc;
int main()
{
//此时只能通过成员函数获取实例对象,同时访问这个类!
singleton::GetInstance()->Add("大大怪");
singleton::GetInstance()->print();
//singleton::GetInstance()->delete_Insrance();
//此时就算我们不显式的调用释放函数,当函数结束时,静态的GC成员变量销毁会带着单例对象自动销毁!,
return 0;
}这里还有一点需要注意,就是懒汉/饿汉模式下我一直没有将拷贝构造/赋值封掉(单例模式下需要封掉拷贝构造赋值,防止拷贝实例对象);其实我们也不用封,因为我们懒汉/饿汉模式基本上是都需要加锁,锁是不允许拷贝的,所以我们此时不封也没问题,但是为了安全,我们还是顺手将其封死吧!具体我就不写了,用我们开篇说的delete关键字即可封死!
下面我们来分析分析饿汉与懒汉的优缺点:
饿汉----优点: 1:简单(相对于懒汉而言!因为懒汉需要加锁保证线程安全!);
饿汉----缺点:1:如果单例对象很大(初始化很慢---IO行为/读配置文件),main函数之前就要申请,如果申请了不使用,不仅会占用资源,而且程序启 动也会受到影响!
2:如果两个单例都是饿汉模式,并且有依赖关系,要求单例1先创建,单例2后创建-----但是饿汉模式无法决定谁先谁后的问题!
懒汉----优点:1:解决了饿汉的缺点!
懒汉---- 缺点: 1:相比于饿汉,懒汉复杂一点(双检查加锁)!
综上:如果这个单例对象在多线程高并发环境下频繁使用,性能要求较高,那么显然使用饿汉模式来避免资源竞争,提高响应速度更好!!!
如果单例对象构造十分耗时或者占用很多资源,比如加载插件啊, 初始化网络连接啊,读取文件啊等等,而有可能该对象程序运行时不会用 到,那么也要在程序一开始就进行初始化,就会导致程序启动时非常的缓慢。 所以这种情况使用懒汉模式(延迟加载)更好!!!
补充:其实在懒汉模式中,我们不需要双加锁,定义静态成员变量,在类外面声明等搞的那么复杂,其实在C++11之后,我们可以简化这些操作,不用再定义静态的成员变量,不用双加锁,具体如下所示:
static singleton &Getinstance()//切记是在C++11之后才可以这样写
{
// C++11 Staticlocalvariables 特性以确保C++11起,静态变量将能够在满⾜thread-safe的前提下唯⼀地被构造和析构;
static singleton _ins;//所以此时这里使用静态临时变量也可以保证线程安全!!!不用双加锁!同时这里的局部静态变量只会在第一次调用时初始化,所以保证了单例对象的唯一性!
return _ins;
}
二:类型转换
2.1:C语言中的类型转换
在C语言中,如果赋值运算符左右两侧类型不同,或者形参与实参类型不匹配,或者返回值类型与接收返回值类型不一致时,就需要发生类型转化,C语言中总共有两种形式的类型转换:隐式类型转换和显式类型转换。
1. 隐式类型转化:编译器在编译阶段自动进行,能转就转,不能转就编译失败;隐式转换的条件和规则由C语言标准定义,通常按照以下规则进行:
<1>如果一个表达式中既有整数类型,又有浮点类型,那么整数类型会自动转换成浮点类型。
<2>如果两个不同的整数类型进行运算,较小的类型会自动转换成较大的类型。
<3>如果一些特定类型的变量和常量进行运算,比如int和char,那么char类型会自动转换成int类型。
<4>如果一个指针类型和一个整数类型进行运算,那么整数类型会自动转换成指针类型。
2. 显式类型转化:需要用户自己处理;具体用法:“目的类型(表达式)”; 其中,目标类型是要转换到的数据类型,表达式是需要转换的值或变量。在强制转换中需要注意的是,如果将一个超出目标类型范围的值转换过去,可能会出现精度损失或者其他不确定的问题。因此,在进行强制类型转换时需要注意数据范围和精度问题。下面给出一个例子,具体如下所示:
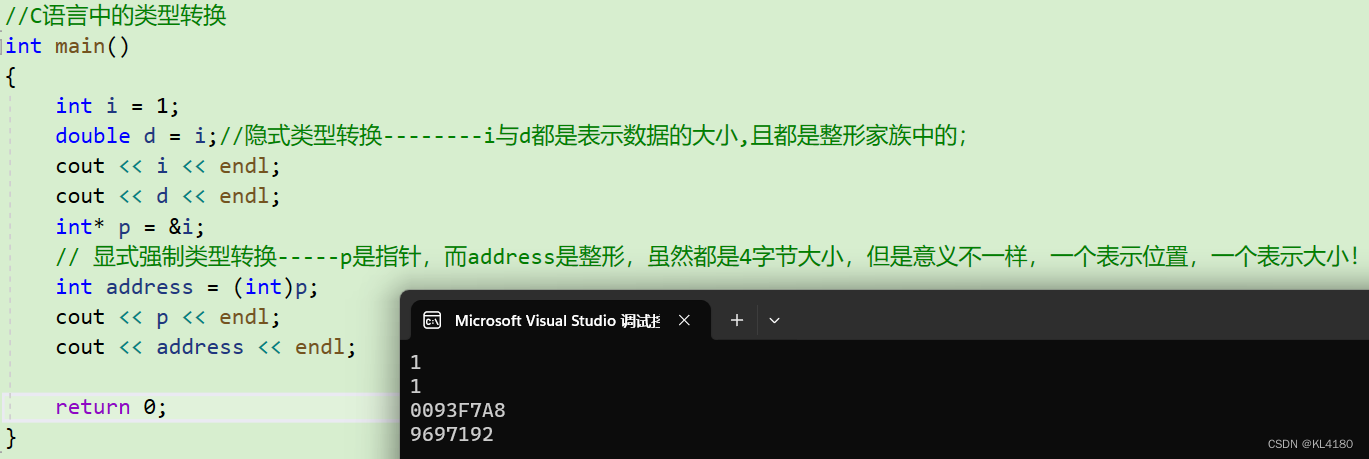
所以虽然C语言风格的转换格式看起来很简单,但是有不少缺点的:
1. 隐式类型转化有些情况下可能会出问题:比如数据精度丢失!
2. 显式类型转换将所有情况混合在一起,代码不够清晰!
因此C++提出了自己的类型转化风格;(注意:因为C++要兼容C语言,所以在C++中,还可以使用C语言的转化风格);
2.2:C++中的类型转换
标准C++为了加强类型转换的可视性,引入了四种命名的强制类型转换操作符:static_cast、reinterpret_cast、const_cast、dynamic_cast;下面我们挨个认识认识这些类型转换符!
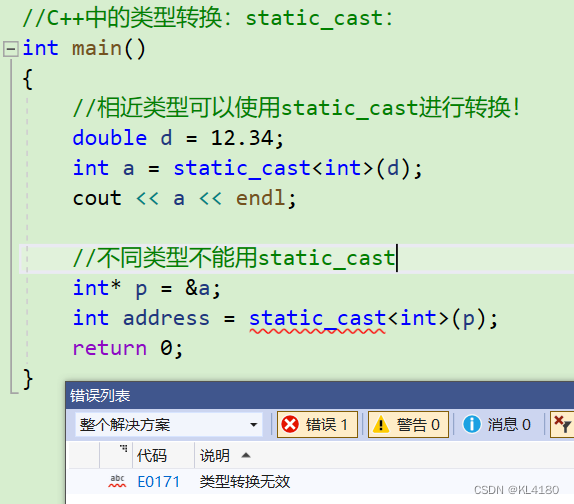
2.2.1:static_cast
static_cast用于非多态类型的转换(静态转换),编译器隐式执行的任何类型转换都可用static_cast,但它不能用于两个不相关的类型进行转换!
需要注意的是,static_cast执行的是编译时检查,而不进行运行时检查。因此,在进行转换时需要谨慎使用,并且只有在确保转换是安全的情况下使用。具体如下所示:
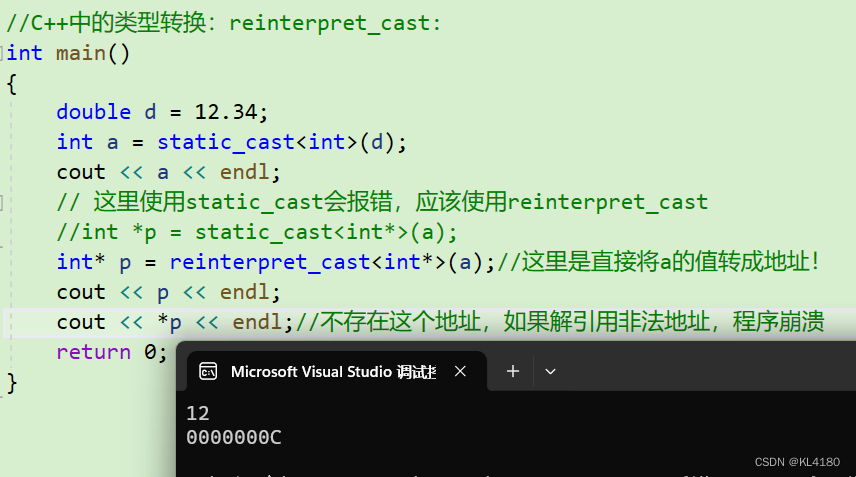
2.2.2:reinterpret_cast
reinterpret_cast操作符通常为操作数的位模式提供较低层次的重新解释,用于将一种类型转换为另一种不同的类型,而不用考虑类型之间的关系。该转换通常被认为是最不安全的类型转换,因为它可以将不同类型的指针互相转换,甚至可能导致未定义行为。具体如下所示:
2.2.3:const_cast
const_cast最常用的用途就是删除变量的const属性,方便赋值!它用于移除变量的常量属性或添加常量属性。它可以用于转换掉const或volatile限定符,从而允许对原本被视为常量的变量进行修改。具体如下所示:
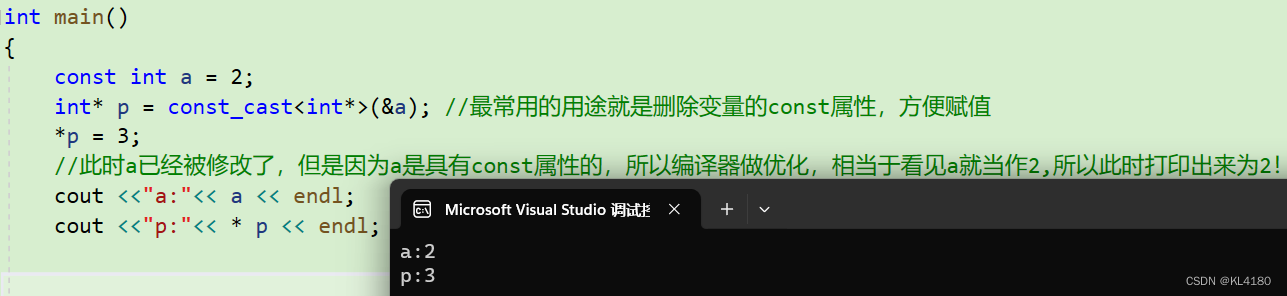
这里我们将带有const属性的变量a通过const_cast转换成一个指针,那么正常来说,我们就可以通过这个指针来修改a的值,但是我们将这个指针指向的空间赋值成3,即a此时也应该为3呀,为什么打印出来和*P的值不同,还是2呢???
答:因为a带有const的变量,所以编译器认为他不会改变,那么编译器将会进行优化,优化分为两种,第一种是将a存储到寄存器中,当需要读取const变量时就会直接从寄存器中进行读取!第二种是在编译时看见a就直接当作2,类似于宏定义一样直接替换!而我们通过指针修改的实际上是内存中的a的值,因此最终打印出a的值是未修改之前的值(寄存器中的a值或者是直接被替换的a)。但是a确确实实已经被修改了!!!
如果不想让编译器将const变量优化到寄存器当中,可以用volatile关键字对const变量进行修饰,这时当要读取这个const变量时编译器就会从内存中进行读取,那么取出的值就是真实的值,具体如下所示:
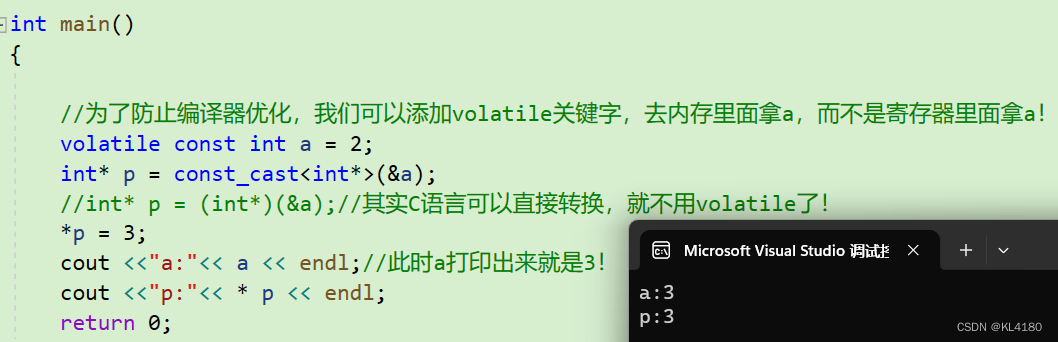
///
2.2.4:dynamic_cast
上面三种C++风格的类型转换对应着C语言中的隐式类型转换和强制类型转换,而dynamic_cast是C++中特有的类型转换!dynamic_cast用于将一个父类对象的指针/引用转换为子类对象的指针或引用(动态转换),也称向下转换!!!
那什么是向下转换???那有向下转换,是不是也有向上转换???
答:向下转换是指将 父类对象指针/引用转换成子类指针/引用!!!而向上转换我们一直都有,向上转换:子类指针/引用转换成父类对象指针/引用
,而这种向上转换的行为在继承中我们已经学过了,我们称之为:子类对父类的切割/切片!是语法天然支持的,即符合父类与子类的赋值兼容规则!
但是向下转换存在安全问题!!!有两种情况:
1:如果父类对象指针/引用指向的是一个父类对象,那么将其转换成子类对象指针/引用时存在内存安全问题,因为父类的成员一定比子类少,那么将父类强制转换成子类时,父类对象如果访问的是子类有而父类没有的成员时,就会存在访问越界的问题!
2:如果父类对象指针/引用指向的是一个子类对象,那么将其转换成子类对象指针/引用时没有任何安全问题,因为大家都是子类!
而C语言中的强制类型转换是不管你有没有访问越界的问题,它都给你强制转换成功,所以C++为了解决C语言都转换的问题,引入了dynamic_cast,
dynamic_cast的作用是:
在向下转换时,如果是父类对象转子类,即存在安全问题,那么此时转换不会成功,返回nullptr;
如果是子类转子类,没有安全问题,那么转换成功!
具体如下所示:

我们可以看到,当我们传递的是父类对象,那么当在fun函数中想将其转成子类时,C语言的强制类型转换直接给你转成功,它不管你有没有访问越界的问题,所以C语言这样做法是不对的!而C++的dynamic_cast会先检查是否存在安全问题,如果有,则转换失败,返回nullptr;只有我们是子类时,C++的dynamic_cast才给我们转换成功!保证向下转换的安全性!
但是这里需要注意一下: dynamic_cast只能用于父类含有虚函数的类!!!
因为当我们使用dynamic_cast将父类指针或引用转换为子类指针或引用时,dynamic_cast会检查实际对象的类型是否与我们要转换的目标类型匹配。这种类型检查需要通过虚函数表来实现。
而虚函数表是一个存储对象的虚函数地址的数据结构。由于派生类继承了父类的虚函数表,所以dynamic_cast能够访问派生类的动态类型信息,通过虚函数表在运行时判断是否可以进行类型转换。
所以如果父类没有定义虚函数,那么dynamic_cast将无法访问虚函数表,也就无法进行类型检查,因此编译器会报错。所以在使用dynamic_cast进行类型转换时,需要在父类中定义虚函数,以确保dynamic_cast能够正常工作。
2.3:RTTI
C++中的RTTI(Run-Time Type Information,运行时类型信息)是一种机制,用于在运行时获取和操作对象的类型信息,RTTI使得我们可以在运行时动态地获取对象的实际类型,并进行类型转换和类型判断,即运行时类型识别。
C++通过以下方式来支持RTTI:
1. typeid运算符:在运行时识别一个对象的类型!(简单用法可以看我lambda表达式那一节的博客,里面有用typeid打印像lambda表达式这样的匿名对象的类型,链接:http://t.csdnimg.cn/9NZeZ)!
2. dynamic_cast运算符:在运行时识别出一个父类的指针(或引用)指向的是父类对象还是子类对象!
3. decltype:在运行时获取表达式的数据类型!(可以看我C++11新特性那一节的博客,里面有说过简单用法,链接:http://t.csdnimg.cn/lJ7RB)!
三:IO流
3.1:C++中的IO流
在了解C++的IO流之前,我们需要先了解C语言中的IO,而C语言中我们用到的最频繁的输入输出方式就是scanf ()与printf()。 scanf(): 从标准输入设备(键盘)读取数据,并将值存放在变量中。printf(): 将指定的文字/字符串输出到标准输出设备(屏幕)。同时注意宽度输出和精度输出控制!
C语言是借助了相应的缓冲区来进行输入与输出,因为通过缓冲区可以屏蔽掉低级I/O的实现,低级I/O的实现依赖操作系统本身内核的实现,所以如果能够屏蔽这部分的差异,可以很容易写出可移植的程序。
然而C++由于类的出现,自定义类型的出现,C语言这套输入输出接口就显得捉襟见肘了,因为它没有办法能够很好的输入输出自定义类型,就算输入输出内置类型都还要指定格式,非常的麻烦,所以C++从运算符重载出手,重载了流插入和流提取运算符!!!
那什么是流呢?
“流”即是流动的意思,是物质从一处向另一处流动的过程,是对一种有序连续且具有方向性的数据( 其单位可以是bit,byte,packet )的抽象描述。
C++流是指信息从外部输入设备(如键盘)向计算机内部(如内存)输入和从内存向外部输出设备(显示器)输出的过程。这种输入输出的过程被形象的比喻为“流”。它的特性是:有序连续、具有方向性!为了实现这种流动,C++定义了I/O标准类库,这些每个类都称为流/流类,用以完成某方面的功能!
下面我们见一见C++的I/O标准类库:

如上所示,C++系统实现了一个庞大的类库,通过继承体系衍生出各种不同的IO类(图中的箭头表示的就是继承关系),其中ios为基类,其他类都是直接或间接派生自ios类; 这些派生出来的类分别对应着C语言的各种IO行为,比如,<istream>这一行的多个类对应着C语言中的sacnf/printf,<fstream>这一行的多个类对应着C语言中对文件进行操作的fscanf/fprintf/fwrite/fread;<sstream>这一行多个类对应着C语言中的sscanf/sprintf!
相比于C语言中的IO操作,这些类能更好的适用面向对象,能够更好的支持自定义类型的IO!
3.1.1:标准IO流
在C++的I/O标准类库中,存在着一个标准IO流类iostream,它继承于标准输入istream和标准输出ostream;
我们先认识认识标准输入:

C++标准库中的标准输入提供了一个全局流对象:cin!使用cin进行标准输入即数据通过键盘输入到程序中;而为了实现从键盘到程序(内存)中,标准输入重载了>>运算符!使用时:“cin>>x”;这样就表示将用户从标准输入(一般为键盘)读取到的值赋值给x,">>"符号生动形象的表明是从cin这个全局对象到x的,是向x“流动”的!

而我们平常使用时之所以可以直接对内置类型进行流插入,是因为库中帮我们写好了,如果是要对自定义类型进行流插入,则需要我们自己在类中自己重载流插入/流提取!

同时,标准输入是不允许拷贝的, 因为标准输入涉及到缓冲区等问题,如果拷贝的话很难搞,所以标准输入是防拷贝的!
标准输入类还提供了一些常用的成员函数,其中一些重要的函数包括:get(): 用于从流中读取一个字符,并返回读取的字符。getline(): 用于从流中读取一行字符,并将结果存储到指定的字符串中。read(): 用于从流中读取一定数量的字节,并将结果存储到指定的缓冲区中。至于其他的成员函函数用的时候再去官网学习即可!
在使用流插入时需要注意以下几点:
1. cin为缓冲流。键盘输入的数据保存在缓冲区中,当要提取时,是从缓冲区中拿。如果一次输入过多,会留在那儿慢慢用,如果输入错了,必须在回车之前修改,如果回车键按下就无法挽回了。只有把输入缓冲区中的数据取完后,才要求输入新的数据。
2. 输入的数据类型必须与要提取的数据类型一致,否则出错。出错只是在流的状态字state中对应位置位(置1),程序继续。
3. 空格和回车都可以作为数据之间的分格符,所以多个数据可以在一行输入,也可以分行输入。但如果是字符型和字符串,则空格(ASCII码为32)无法用cin输入,字符串中也不能有空格。回车符也无法读入!
int main()
{
string str;
while (cin >> str)
{
//那么现在有一个问题?--为什么cin对象可以转bool,用来做为循环判断的条件?
cout << str << endl;
}
return 0;
}我们经常在一些Oj中可以看到这样的循环,用全局的cin对象流插入时做循环条件!!!就可以一直输入数据了,如果想结束输入,有两种方法:
1:ctrl+c---强杀进程(就是给进程发信号,我们在Linux学习中深刻的学习过);2:ctrl+z+enter(换行)----流对象提取到结束(类似文件读到结尾);
但是我们知道,能做循环条件基本上就是整形,指针,返回值bool,而这里的cin>>str的返回值是一个cin对象(这里是调用了string的流提取函数:istream& operator>> (istream& is, string& str));那cin对象是如何做while循环的判断条件的呢???
答:因为cin重载了一个 explicit operator bool() const 函数;---支持自定义类型转内置类型!

下面给出一个例子,用于理解自定义类型转内置类型的情况,具体如下所示:
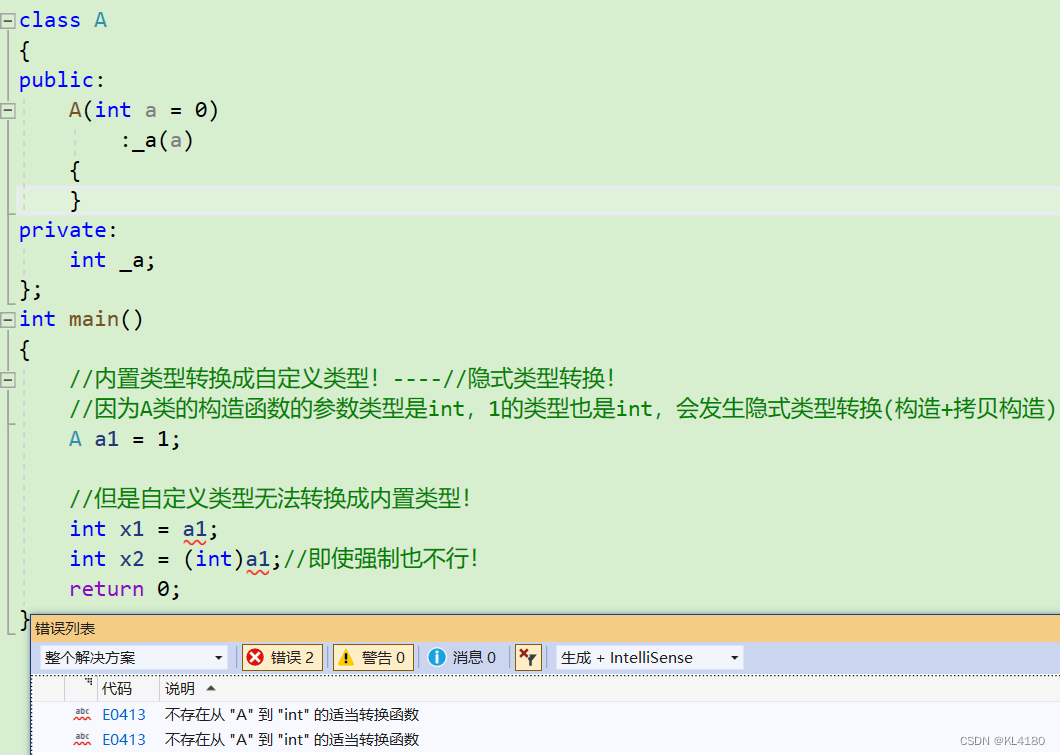
我们可以看到,内置类型转自定义类型可以,但是自定义类型转内置类型就不可以了,那如何可以让自定义类型转内置类型呢???
答:只需要重载int即可,具体如下所示:
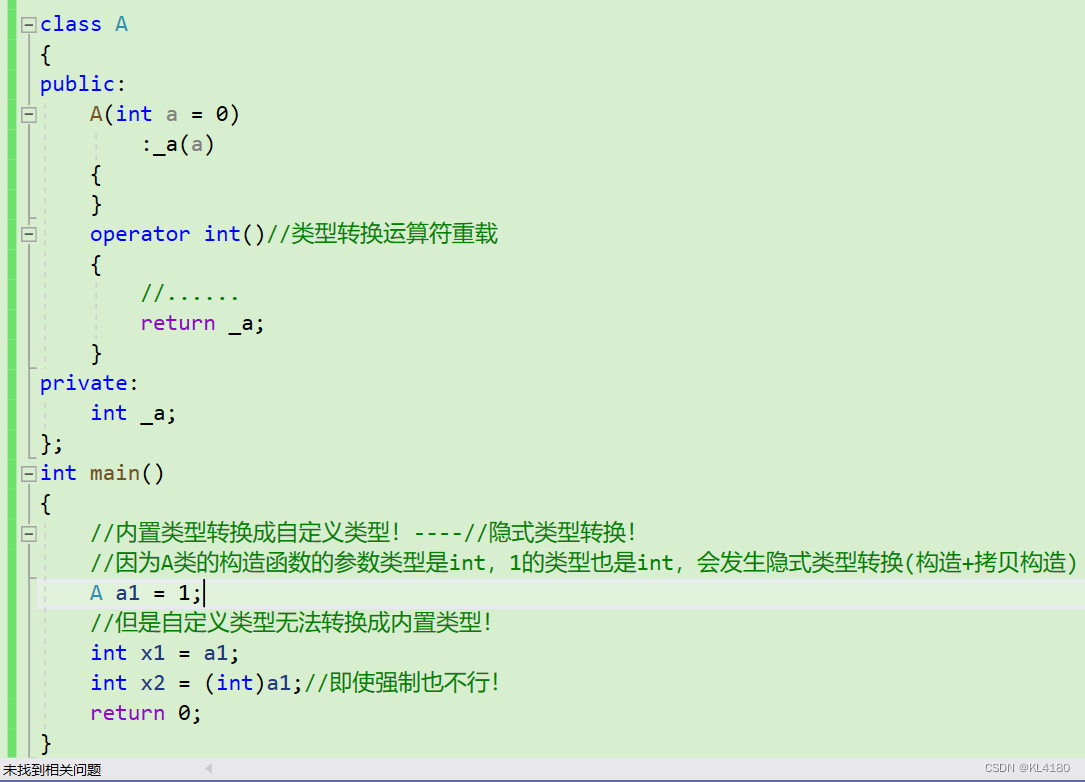
operator int() 是一种类型转换运算符重载,用于将自定义类型的对象转换为整数类型。这样就可以解决不能转换的问题!
同理,cin对象能转成bool类型和我们这个例子的原理一样,因为标准输入里面重载了operator bool(),就可以将cin对象转成bool类型,从而就可以将cin对象流插入用作while循环判断的条件!
标准输出:
标准输出(ostream)和标准输入类似,标准输出重载了"<<"!同时标准输出类中的operator<<也将内置类型的流提取也全都写好了,如果是自定义类型流提取,则需要我们自己实现!
标准输出提供了3个全局流对象cout、cerr、clog,使用cout进行标准输出,即数据从内存流向控制台(显示器)。同时C++标准库还提供了cerr用来进行标准错误的输出,以及clog进行日志的输出,虽然cout、cerr、clog是ostream类的三个不同的对象,但是这三个对象现在基本没有区别,只是应用场景不同!具体如下所示:

无论使用哪个ostream全局流对象,结果都是在显示器上输出字符串,所以仅仅是应用的场景不同,但是结果相同 !
下面,我们给出一个自定义的日期类,对上面标准输入、标准输出所描述的一些知识点,操作进行实现!比如流插入,流提取,自定义类型转内置类型等,具体如下所示:
class Date
{
//需要将重载的流插入流提取设置成友元函数,访问流插入流提取时访问日期类的私有成员!!!
friend ostream& operator << (ostream& out, const Date& d);
friend istream& operator >> (istream& in, Date& d);
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{}
//这个是为了验证当我们输入日期类中的年为0时,while循环条件是否为false,退出循环!
operator bool()//自定义类型转内置类型!
{
// 这里是随意写的,假设输入_year为0,则结束!
if (_year == 0)
return false;
else
return true;
}
private:
int _year;
int _month;
int _day;
};
//重载流插入流提取:
istream& operator >> (istream& in, Date& d)
{
in >> d._year >> d._month >> d._day;
return in;
}
ostream& operator << (ostream& out, const Date& d)
{
out << d._year << " " << d._month << " " << d._day;
return out;
}
// C++ IO流,使用面向对象+运算符重载的方式
// 能更好的兼容自定义类型,流插入和流提取
int main()
{
//可以直接对内置类型进行流插入--C++库中进行了函数重载(operator>>(各种内置类型))
int i = 0;
double j =0;
cin >> i;
cin >> j;
// 自动识别类型的本质--C++库中进行了函数重载(operator<<(各种内置类型))
// 内置类型可以直接使用--因为库里面ostream类型已经实现了
cout << i << endl;
cout << j << endl;
// 自定义类型输入输出则需要我们自己重载<< 和 >>
Date d;
cin >> d;
cout << d;
//自定义类型(日期类)转内置类型(bool),用来做while循环的判断条件!
while (d)
{
cin >> d;
cout << d;
}
return 0;
}3.1.2:文件IO流
ifstream 和 ofstream 是 C++ 标准库中提供的用于文件输入和输出的类。它们都派生自 istream 和 ostream 类,用于处理输入和输出流。ifstream (input file stream) 是用于从文件中读取数据的类。fstream (output file stream) 是用于向文件中写入数据的类。这两个类可以与文件流对象结合使用,以打开特定的文件,从文件中读取数据或将数据写入到文件中。下面我们先认识认识ifstream类和ofstream类中的成员函数;
ofstream(向文件中写入):

所以我们可以从构造函数看出,我们基本上有两种打开文件进行操作的方式(不包含移动构造)!
第一种:直接用带参的构造函数,拿文件名(可以是char*类型的,也可以是string类型)和文件操作类型直接构造ofstream类对象;
第二种:先调用无参的构造函数,构造ofstream类对象,然后再通过类对象调用open函数打开文件并操作!
向文件写入函数:
写入函数也有两种,一种是调用write函数进行写入,另一种是调用重载的"<<",具体如下所示:

调用write函数时,我们需要将要写入文件中的数据的类型转成字符串类型,同时,还要知道要要写入的数据的大小!
调用operator<<时,我们需要注意,我们只能向文件中写入内置类型的数据,如果是自定义类型,那么自定义类型就需要重载流插入和流提取!
ifstream(从文件中读取数据):

ifstream类的构造函数和ofstream类的构造函数基本上没有差别,基本上也两种方法构造ifstream对象!只是在文件操作的缺省值上,ifstream类与ofstream类有些许的不同,ofstream类对文件操作的缺省值是out(打开文件并写入);而ifstream类对文件操作的缺省值是in(打开文件并读取)!
从文件中读取函数:
读取函数也有两种,一种是调用read函数进行读取,另一种是调用重载的">>",具体如下所示:
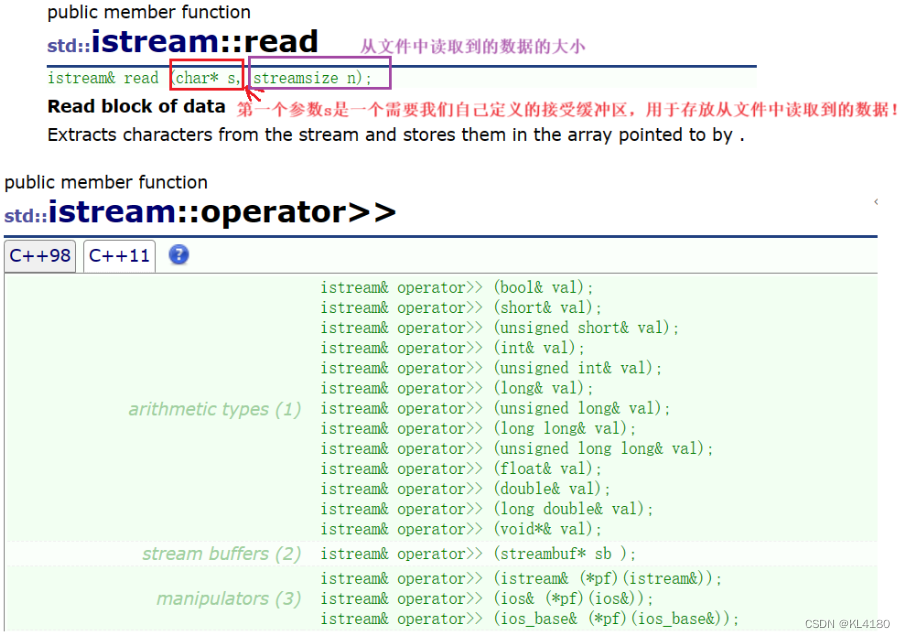
调用read函数时,我们需要自己定义一个接受缓冲区,用于存放从文件中读取到的数据!
调用operator>>时,和向文件写入时的operator<<一样,只只针对内置类型,自定义类型需要我们自己重载!
对文件的操作方式:

最常用的就是in,out,binary,app这四个操作,同时,这四个操作可以搭配使用,比如我想对文件进行二进制写入:out | binary!!! 又比如我想对文件进行二进制读取:in | binary!!!或者二进制追加写:out | binary | app!!!;可以根据我们的需要进行搭配!
那这里为什么用“|”符合就可以将这些文件操作搭配在一起???
答:因为in,out这样的标志位是表示对文件各种不同操作,其本质都是数字,都是像0x1,0x2,0x4,0x8.....这样用比特位表示的数,这样一个整形就可以表示32个标志位,而“|”就是或运算符,当它们进行或运算时,就表示着这它们所代表的位置置1,然后传参时,就可以用一个整形参数表示不同的文件操作(这里在linux学习中用过)!
关闭文件:
无论是iftream还是ofstream都有一个close接口,用来关闭打开的文件,但是一般情况下不需要调用,因为文件也是通过RAII的方式在管理,当ifstream或者ofstream对象声明周期结束时,在析构函数中会自定关闭打开的文件。但是如果在一个同程序里面调用ofstream类创建对象向文件中写入,同时又利用ifstream类创建对象将刚才写入的数据读出来时,我们会发现读取不到刚才写入到文件中的数据!具体如下所示:
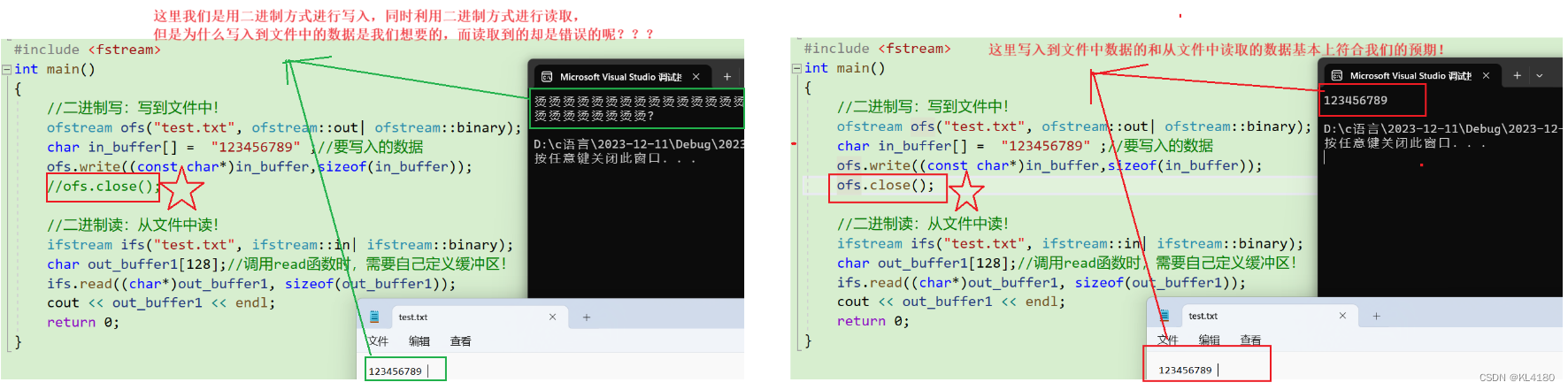
在C++文件IO中,当使用 ofstream 进行文件写入后,需要关闭文件流或者调用 flush() 方法来确保数据被完全写入到文件中。 如果文件写入成功并且被关闭或者缓冲区中的数据被刷新到文件中,ifstream 才能能够读取到刚刚写入的数据。如果文件没有正确写入或者文件流没有关闭,ifstream 可能无法读取到刚刚写入的数据。所以上述例题结果不同的原因就是:没有关闭文件流/调用flush()刷新函数!!!
这里还有一个问题,就是为什么我们明明是二进制写入到文件中,而文件中却还是字符串???
答:对于字符数据,无论你以二进制方式写入文件还是以文本方式写入文件,实际上它们在文件中的存储方式并没有区别。本质上,字符数据在内存中也是以二进制形式存储的。所以我们写入到文件中的数据不是“二进制”!!!
下面我们对自定义类型进行文件的输入输出操作(以我们上面的日期类为例)!!!
struct ServerInfo
{
char _address[32];//IP地址
int _port;//端口
Date _date;//日期
};我们定义一个包含网络信息的结构体,同时在其内部定义一个自定义的日期类对象,表示网络信息的时间,下面我们对这个结构体进行文件的输入输出!
struct ConfigManager
{
public:
ConfigManager(const char* filename)
:_filename(filename)
{}
//二进制写
void WriteBin(const ServerInfo& info)
{
ofstream ofs(_filename, ofstream::out | ofstream::binary);
ofs.write((const char*)&info, sizeof(info));
}
//二进制读
void ReadBin(ServerInfo& info)
{
ifstream ifs(_filename, ofstream::in | ofstream::binary);
ifs.read((char*)&info, sizeof(info));
}
//如果C语言想搞文本读写是很麻烦的,因为有不同的类型,我们要一直转换类型,转成字符串!
// 但是C++文件流的优势就是可以对内置类型和自定义类型,都使用 一样的方式,去流插入和流提取数据;能更方便的进行文本读写!
// 当然这里自定义类型Date需要重载>> 和 <<
// istream& operator >> (istream& in, Date& d)
// ostream& operator << (ostream& out, const Date& d)
//文本写:写入的时候我们需要通过空格/换行进行分割,要不然读取的时候就直接一块读了,
void WriteText(const ServerInfo & info)
{
ofstream ofs(_filename);
ofs << info._address << endl;
ofs << info._port << endl;
ofs << info._date << endl;//这里我们就可以直接用运算符重载<<来实现字符串的文本读写!!!
}
//文本读:
void ReadText(ServerInfo& info)
{
ifstream ifs(_filename);
ifs >> info._address >> info._port >> info._date;
}
private:
string _filename; // 配置文件
};我们封装了一个类,类中提供将结构体进行文件操作的四个成员函数(二进制写,二进制读,文本写,文本读),同时因为无论怎样操作,我们都需要文件名称,所以我们将文件名称搞成成员变量!!!
下面我们来看看调用不同的文件操作成员函数,会有什么不同的结果,具体如下所示:

但是这里需要注意一点,就是在二进制读写的时候,特别是写的时候,我们不能二进制的写入string类型的数据!!!具体如下所示:
//在二进制读写中不能使用string:
struct ServerInfo
{
string _address;//二进制读写不能用string,只能用char数组!!!为什么呢???
int _port; //答:因为string里面的空间是指针指向的,此时如果二进制读写,写的是string里面的指针,并没有将指针指向的内容写入!!!
Date _date; //然后当写入完成后,指针销毁,当再去二进制读的时候,因为这个指针已经被销毁了,所以读到了野指针!!!
};
struct ConfigManager
{
public:
ConfigManager(const char* filename)
:_filename(filename)
{}
//二进制写
void WriteBin(const ServerInfo& info)
{
ofstream ofs(_filename, ofstream::out | ofstream::binary);
ofs.write((const char*)&info, sizeof(info));
}
//二进制读
void ReadBin(ServerInfo& info)
{
ifstream ifs(_filename, ofstream::in | ofstream::binary);
ifs.read((char*)&info, sizeof(info));
}
private:
string _filename; // 配置文件
};
int main()
{
ServerInfo winfo = { "192.0.0.1", 80, { 2022, 4, 10 } };
string str;
cin >> str;
// 二进制读写
ConfigManager cf_bin("test.bin");
if (str == "二进制写")
{
cf_bin.WriteBin(winfo);//二进制写
}
else if (str == "二进制读")
{
ServerInfo rbinfo;//定义一个读缓冲区
cf_bin.ReadBin(rbinfo);//二进制读
cout << rbinfo._address << endl;
cout << rbinfo._port << endl;
cout << rbinfo._date << endl;
}
return 0;
}
因为string里面的空间是指针指向的,此时如果二进制读写,写的是string里面的指针,并没有将指针指向的内容写入!!!然后当写入完成后,指针销毁,当再去二进制读的时候,因为这个指针已经被销毁了,所以读到了野指针!从而导致程序崩溃!!!
3.1.3:stringstream
在C语言中,如果想要将一个整形变量的数据转化为字符串格式,有两种方式:
1. 使用itoa()函数; 2. 使用sprintf()函数
但是两个函数在转化时,都得需要先给出保存结果的空间,那空间要给多大呢,就不太好界定,而且转化格式不匹配时,可能还会得到错误的结果甚至程序崩溃!所以C++为了解决这个问题,提供了istringstrem类和ostringstream类!
而stringstream则是继承于二者,它提供了一种将数据类型转换为字符串、将字符串转换为数据类型的便捷方式!
下面我们先看看istringstrem类和ostringstream类的用法:
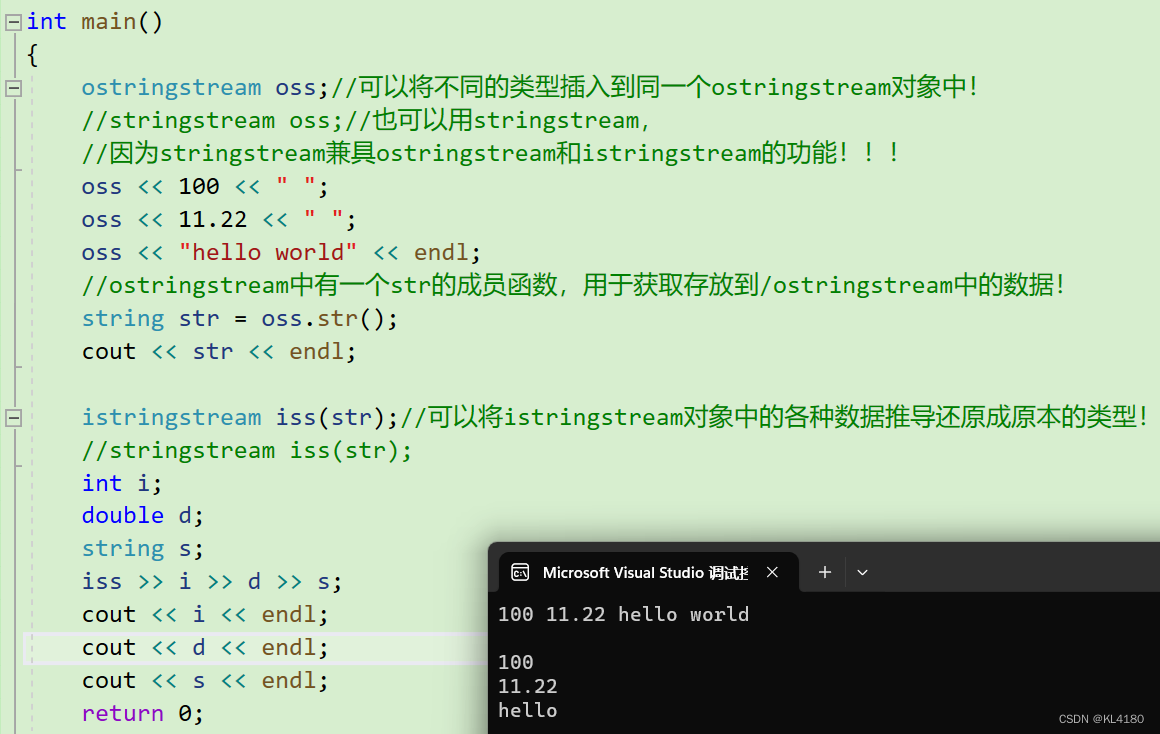
那它们这样有什么意义呢???
答:它们的意义在于序列化(ostringstream类)与反序列化(istringstrem类)!!!
比如,在网络通信中,我们想要发送一些结构性数据(保护各种属性,比如发送的内容,时间等);此时我们就不能通过字符串的方式一个一个的发生出去(容易引发错误,万一少一个或者多一个,容易造成混淆),所以为了安全,我们把结构化数据里面的字符串整合一下,变成一个大字符串发送出去,这就是序列化,而根据上面的例子,ostringstream类正好可以将各种不同类型的数据转换成一个大字符串!
而反序列化就是将发送过来的大字符串进行解析,将大字符串中的各种数据推导回原来的类型!这不就是istringstrem类可以做的事情嘛!!!
所以下面我们模拟一下网络通信中,将一个结构化数据序列化,反序列化!!!
//序列化与反序列化:稍微复杂一点(一个结构体)
struct ChatInfo
{
string _name; // 名字
int _id; // id
Date _date; // 时间
string _msg; // 聊天信息
};
int main()
{
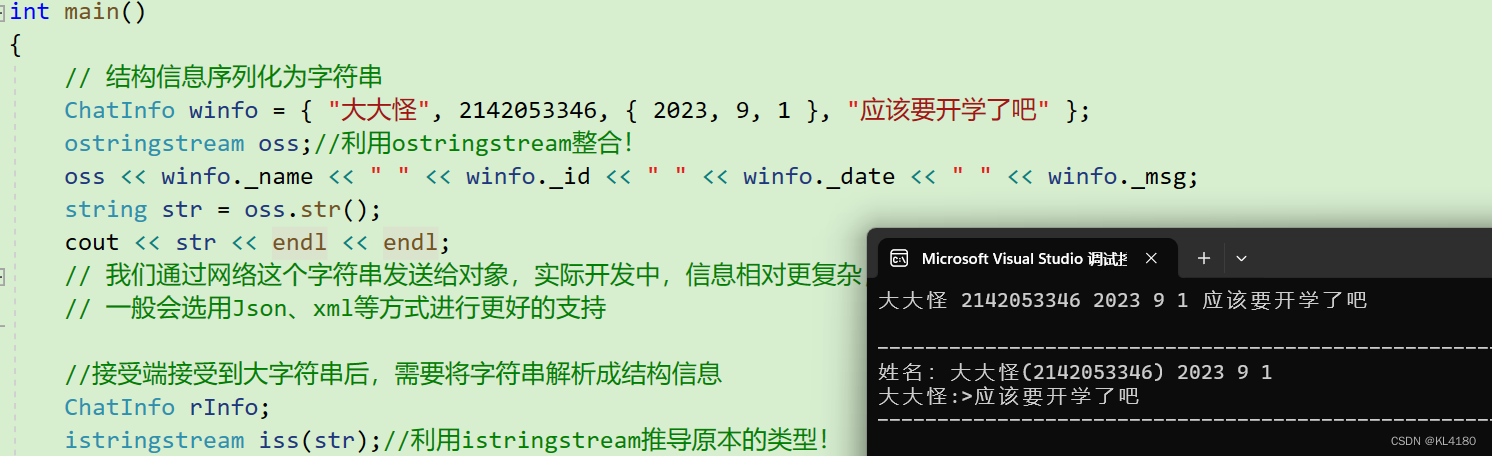
// 结构信息序列化为字符串
ChatInfo winfo = { "大大怪", 2142053346, { 2023, 9, 1 }, "应该要开学了吧" };
ostringstream oss;//利用ostringstream整合!
oss << winfo._name << " " << winfo._id << " " << winfo._date << " " << winfo._msg;
string str = oss.str();
cout << str << endl << endl;
// 我们通过网络这个字符串发送给对象,实际开发中,信息相对更复杂,
// 一般会选用Json、xml等方式进行更好的支持
//接受端接受到大字符串后,需要将其反序列化,解析成结构化信息
ChatInfo rInfo;
istringstream iss(str);//利用istringstream推导原本的类型!
iss >> rInfo._name >> rInfo._id >> rInfo._date >> rInfo._msg;
cout << "-------------------------------------------------------" << endl;
cout << "姓名:" << rInfo._name << "(" << rInfo._id << ") ";
cout << rInfo._date << endl;//这里需要注意用空格/换行进行分割,要不然数据打印时就粘在一起了!
cout << rInfo._name << ":>" << rInfo._msg << endl;
cout << "-------------------------------------------------------" << endl;
return 0;
}
因为stringstream继承于ostringstream类和istringstrem类,所以上述序列化和反序列化我们也可以用stringstream来做,这里我就不示范了!!!
注意:
1. stringstream实际是在其底层维护了一个string类型的对象用来保存结果。
2. 多次数据类型转化时,一定要用clear()来清空,才能正确转化,但clear()不会将stringstream底层的string对象清空。
3. 可以使用s.str("")方法将底层string对象设置为""空字符串。
4. 可以使用s.str()将让stringstream返回其底层的string对象。
5. stringstream使用string类对象代替字符数组,可以避免缓冲区溢出的危险,而且其会对参数类型进行推演,不需要格式化控制,也不会出现格式化失败的风险,因此使用更方便,更安全!