目录
1、论文简介
- 论文题目——《Simple and Deep Graph Convolutional Networks》
- 论文作者——Ming Chen,Zhewei Wei ,Zengfeng Huang,Bolin Ding&Yaliang Li
- 论文地址——Simple and Deep Graph Convolutional Networks》
- 源码———论文源码链接
2、论文核心介绍
2.1、研究动机
图神经网络是一种强大的处理图结构数据的有效学习方法。图神经网络及其变体在真实数据集上显示出了优异的性能。但目前的大多数GCN模型都很浅,GCN和GAT都是在两层的模型上实现最佳性能。浅层的网络结构限制了他们从高阶邻居中提取信息的能力。
然而,堆叠多层和添加非线性往往会降低模型的性能,出现过平滑的现象,原因是随着堆叠层数的增加,GCN中节点的表示会收敛到某个值,因此变得无法区分。
那么,那图神经网络真的可以达到深层吗?答案是肯定的!
2.2、创新点
在传统GCN的基础上,引入两个简单的技术:初始剩余连接和恒等映射来真正实现深层的图卷积神经网络。
- 初始残差连接是将 H ( l ) H^{(l)} H(l)与第一层 H ( 0 ) H^{(0)} H(0)的初始残差连接相结合;
- 增加了一个恒等式映射 I n I_n In到第 l l l层权重矩阵 W ( ℓ ) W^{(ℓ)} W(ℓ)中。
2.3、具体实现
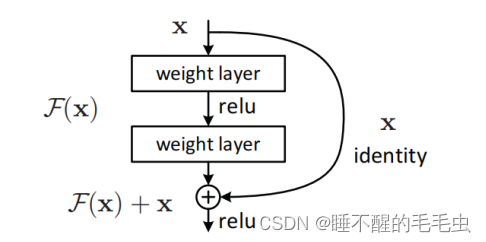
GCNII模型灵感来自于2016年计算机视觉领域解决相似问题的ResNet模型,ResNet模型采用残差连接使模型可以训练更深层的网络。同样采用初始残差的APPNP模型,采用线性聚合方式很难达到深层,说明仅仅在图神经网络模型中添加残差连接是不充分的,并不能使图神经网络引向更深的模型。为此,GCNII模型采用初始残差连接和恒等映射两个技巧,可以达到深层的模型而不会导致过平滑的现象。
2.3.1、初始残差链接
为了模拟ResNet中的残差连接,GCN提出了将平滑表示 P H ( ℓ ) \mathrm{PH^{(ℓ)}} PH(ℓ)与 H ( ℓ ) \mathrm{H^{(ℓ)}} H(ℓ)相结合的残差连接,但是这种残差连接并没有实质上解决过平滑的问题,随着网络层数的增多,模型的性能仍会降低。
因此,GCNII模型中没有使用上一层的残差连接,而是初始表 H ( 0 ) \mathrm{H^{(0)}} H(0),称为初始残差连接。这样即使堆叠了很多层,初始剩余连接确保每个节点的最终表示都至少保留输入层的一小部分信息,作者简单将 α l \alpha_{l} αl设置为0.1或0.2,以便每个节点的最终表示都至少包含输入特征的一小部分信息。
值得注意的是, H ( 0 ) \mathrm{H^{(0)}} H(0)不一定是特征矩阵 X \mathrm{X} X。如果特征维数 d \mathrm{d} d比较大,可以在 X \mathrm{X} X上应用全连接神经网络,以在前向传播之前获得较低维的初始表示 H ( 0 ) \mathrm{H^{(0)}} H(0)。
2.3.2、恒等映射
恒等映射确保深层GCNII模型至少实现与其浅层版本相同的性能。通过将 β l \beta_{l} βl设置得足够小,深度的GCNII会忽略权重矩阵 W ( ℓ ) W^{(ℓ)} W(ℓ)。
已经观察到特征矩阵在不同维度之间的频繁交互降低了模型在半监督任务中的性能。然而,将平滑表示 P H ( ℓ ) \mathrm{PH^{(ℓ)}} PH(ℓ)直接映射到输出则会减少了这种交互。
恒等映射被证明在半监督任务中特别有用。Hardt&Ma,2017证明了形式为 H ( l + 1 ) = H ( l ) ( W ( l ) + I n ) \mathrm{H^{(l+1)}=H^{(l)}(W^{(l)}+I_n)} H(l+1)=H(l)(W(l)+In)满足以下性质:
- 最优权矩阵 W ( ℓ ) W^{(ℓ)} W(ℓ)具有小范数;
这个性质允许我们强正则化 W ( ℓ ) W^{(ℓ)} W(ℓ)避免过度拟合 - 唯一的临界点是全局极小值。
在训练数据有限的半监督任务中是可取的
- 最优权矩阵 W ( ℓ ) W^{(ℓ)} W(ℓ)具有小范数;
Oono&Suzuki从理论上证明了K层GCNS的节点特征会收敛到一个子空间,从而导致信息丢失。特别地,收敛速度依赖于 S K S^K SK,S是权重矩阵 W ( ℓ ) W^{(ℓ)} W(ℓ),ℓ=0,…,K−1的最大奇异值。通过将 W ( ℓ ) W^{(ℓ)} W(ℓ)替换为 ( 1 − β l ) I n + β l W ( l ) (1-\beta_l)\mathrm{I_n}+\beta_lW^{(l)} (1−βl)In+βlW(l)并对 W ( ℓ ) W^{(ℓ)} W(ℓ)施加正则化,强制 W ( ℓ ) W^{(ℓ)} W(ℓ)的范数小。因此,上式的奇异值将接近1。因此,最大奇异值s也将接近1,这意味着 S K S^K SK过大,信息损失得到缓解。设置 β l \beta_l βl的原则是确保权重矩阵的衰减随着层数的增加而自适应地增加。
2.3.3、模型
GCNII模型分层结构可以被描述为
H ( l + 1 ) = σ ( ( ( 1 − α l ) A ^ H ( l ) + α l H ( 0 ) ) ( ( 1 − β l ) I n + β l W ( l ) ) ) H^{(l+1)} = \sigma(((1-\alpha_l)\hat{A}H^{(l)}+\alpha_lH^{(0)})((1-\beta_l)I_n+\beta_lW^{(l)})) H(l+1)=σ(((1−αl)A^H(l)+αlH(0))((1−βl)In+βlW(l)))
初始残差连接确保每个结点堆叠多层的最终表征至少包含来自输入的部分表征。
为了弥补APPNP的缺陷,GCNII借鉴ResNet模型中恒等映射的思想。恒等映射可以使深层GCNII模型实现与浅层GCNII模型达到相同的性能,同时使模型能够关注局部的邻域信息,最后还可以防止过拟合。
从谱域的角度来看,一个k层的GCNII可以模型任意的系数的k阶多项式谱图滤波器,感兴趣的读者可以去读这篇论文。
3、源码复现
详细源码请参考百度网盘连接
链接:https://pan.baidu.com/s/1IV9Kdg9TyWSWxMC9qZsIiA
提取码:6666
3.1、Torch复现
import torch
from torch import nn
from torch.nn import functional as F
from torch.nn import Module
from torch.nn import Linear
from torch.nn.parameter import Parameter
from torch.nn import functional as F
import torch
import math
class GraphConvLayer(Module):
def __init__(self, unit_num,alpha,beta,device) -> None:
super(GraphConvLayer,self).__init__()
self.alpha = alpha
self.beta = beta
self.device = device
self.W = Parameter(torch.empty(size=(unit_num,unit_num)))
self.init_param()
pass
def init_param(self):
torch.nn.init.xavier_uniform_(self.W.data,gain=1.414)
def forward(self,P,H,H0):
#P : N*N
#H : N*C
#H0 : N *F
#W : C*C
initial_res_connect = (1-self.alpha)*torch.mm(P,H)+self.alpha * H0
I = torch.eye(self.W.shape[0]).to(self.device)
identity_map = (1-self.beta) * I + self.beta * self.W
output = torch.mm(initial_res_connect,identity_map)
return F.relu(output)
class GCNII(Module):
def __init__(self, input_dim,hidden_dim,output_dim,k,alpha,lamda,dropout,device):
super(GCNII,self).__init__()
self.layer1 = Linear(input_dim,hidden_dim)
self.layer2 = Linear(hidden_dim,output_dim)
self.convs = nn.ModuleList()
self.convs.append(self.layer1)
self.k = k
self.dropout = dropout
#self.layers = []
for i in range(k):
beta = math.log(lamda / (i+1) + 1)
self.convs.append(GraphConvLayer(hidden_dim,alpha,beta,device))
self.convs.append(self.layer2)
self.reg_param = list(self.convs[1:-1].parameters())
self.non_linear_param = list(self.convs[0:1].parameters())+list(self.convs[-1:].parameters())
#直接在低维变换效果不好,高维变换再映射到低维空间
#self.layers.append(GraphConvLayer(output_dim,alpha,beta,device))
# for i,layer in enumerate(self.layers):
# self.add_module(f'{i}',layer)
def forward(self,features,adj):
#H0 = self.layer1(features)
H0 = F.dropout(features,self.dropout,training= self.training)
H0 = F.relu(self.convs[0](H0))
H = H0
#for layer in self.layers:
for layer in self.convs[1:-1]:
H = F.dropout(H,self.dropout,training= self.training)
H = layer(adj,H,H0)
H = F.dropout(H,self.dropout,training= self.training)
output = self.convs[-1](H)
#output = self.layer2(H)
return F.log_softmax(output,dim=1)
class GCNII_START(Module):
def __init__(self, input_dim,hidden_dim,output_dim,k,alpha,lamda,dropout,device) :
super(GCNII_START,self).__init__()
self.layer1 = Linear(input_dim,hidden_dim)
self.layer2 = Linear(hidden_dim,output_dim)
self.dropout = dropout
self.layers = []
for i in range(k):
beta = lamda /(i+1)
self.layers.append(GraphConvLayer_START(hidden_dim,alpha,beta,device))
for i,layer in enumerate(self.layers):
self.add_module(f'{
i}',layer)
def forward(self,features,adj):
H0 = F.dropout(features,self.dropout,training= self.training)
H0 = F.relu(self.layer1(H0))
H = H0
for layer in self.layers:
H = F.dropout(H,self.dropout,training=self.training)
H = layer(adj,H,H0)
H = F.dropout(H,self.dropout,training= self.training)
output = self.layer2(H)
return F.log_softmax(output,dim=1)
pass
class GraphConvLayer_START(Module):
def __init__(self, unit_num,alpha,beta,device):
super(GraphConvLayer_START,self).__init__()
self.alpha = alpha
self.beta = beta
self.device = device
self.W1 = Parameter(torch.empty(size=(unit_num,unit_num)))
self.W2 = Parameter(torch.empty(size=(unit_num,unit_num)))
self.init_param()
def init_param(self):
nn.init.xavier_uniform_(self.W1.data,gain=1.414)
nn.init.xavier_uniform_(self.W2.data,gain=1.414)
def forward(self,P,H,H0):
I = torch.eye(self.W1.shape[0]).to(self.device)
propagation = torch.mm(P,H)
initial_res = H0
identity_map1 =(1-self.beta)*I+self.beta*self.W1
identity_map2 =(1-self.beta)*I+self.beta*self.W2
output = (1-self.alpha)*torch.mm(propagation,identity_map1) + self.alpha * torch.mm(initial_res,identity_map2)
return F.relu(output)
3.2、DGL复现
DGL复现精度可达0.8510(仅在cpu上)
import os
os.environ["DGLBACKEND"] = "pytorch"
import dgl
import dgl.function as fn
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class GraphConvLayer(nn.Module):
def __init__(self,infeat,alpha,beta) -> None:
super(GraphConvLayer,self).__init__()
self.alpha = alpha
self.beta = beta
self.W = nn.Parameter(torch.empty(size=(infeat,infeat)))
nn.init.xavier_uniform_(self.W.data,gain=1.414)
def forward(self,x,g):
with g.local_scope():
h0 = g.ndata['init_feat']
#添加自环
g = dgl.add_self_loop(g)
#计算正则
degs = g.in_degrees().to(x).clamp(min=1)
norm = torch.pow(degs,-0.5)
norm = norm.to(x.device).unsqueeze(1)
x = x * norm
g.ndata['h'] = x
g.update_all(fn.copy_u('h','m'),fn.sum('m','h'))
h = g.ndata['h'].to(x)
h = h * norm
r = (1-self.alpha) * h + self.alpha * h0
out = (1-self.beta) * r + self.beta * torch.mm(r,self.W)
return out
class GCNII(nn.Module):
def __init__(self,infeat,hidfeat,outfeat,alpha,lamda,dropout,k) -> None:
super(GCNII,self).__init__()
self.dropout = dropout
self.convs = nn.ModuleList()
for i in range(k):
#theta = lamda /(i+1)
beta = math.log(lamda/(i+1)+1)
self.convs.append(GraphConvLayer(hidfeat,alpha,beta))
self.fcs = nn.ModuleList()
self.fcs.append(nn.Linear(infeat,hidfeat))
self.fcs.append(nn.Linear(hidfeat,outfeat))
self.params1 = list(self.convs.parameters())
self.params2 = list(self.fcs.parameters())
self.act_fn = nn.ReLU()
self.sg = nn.Sigmoid()
self.init_param()
def init_param(self):
self.fcs[0].reset_parameters()
self.fcs[1].reset_parameters()
def forward(self,x,g):
x = F.dropout(x,self.dropout,training=self.training)
x = self.act_fn(self.fcs[0](x))
print(x.device())
g.ndata['init_feat'] = x
h = x
for conv in self.convs:
h = self.act_fn(conv(h,g))
h = F.dropout(h,self.dropout,training=self.training)
h = self.fcs[-1](h)
return F.log_softmax(h,dim=1)