目录
一、源码测试
1. 下载源码
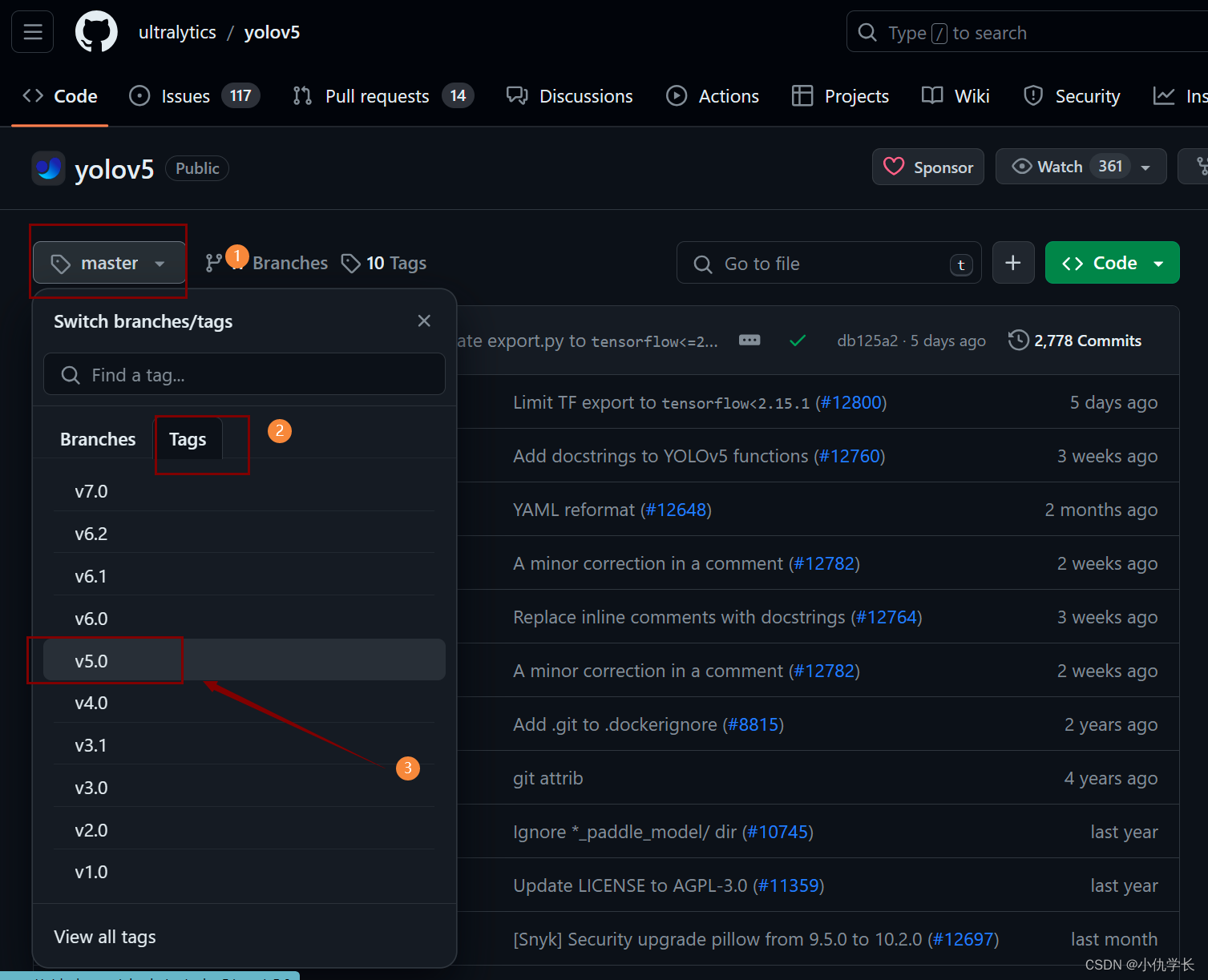
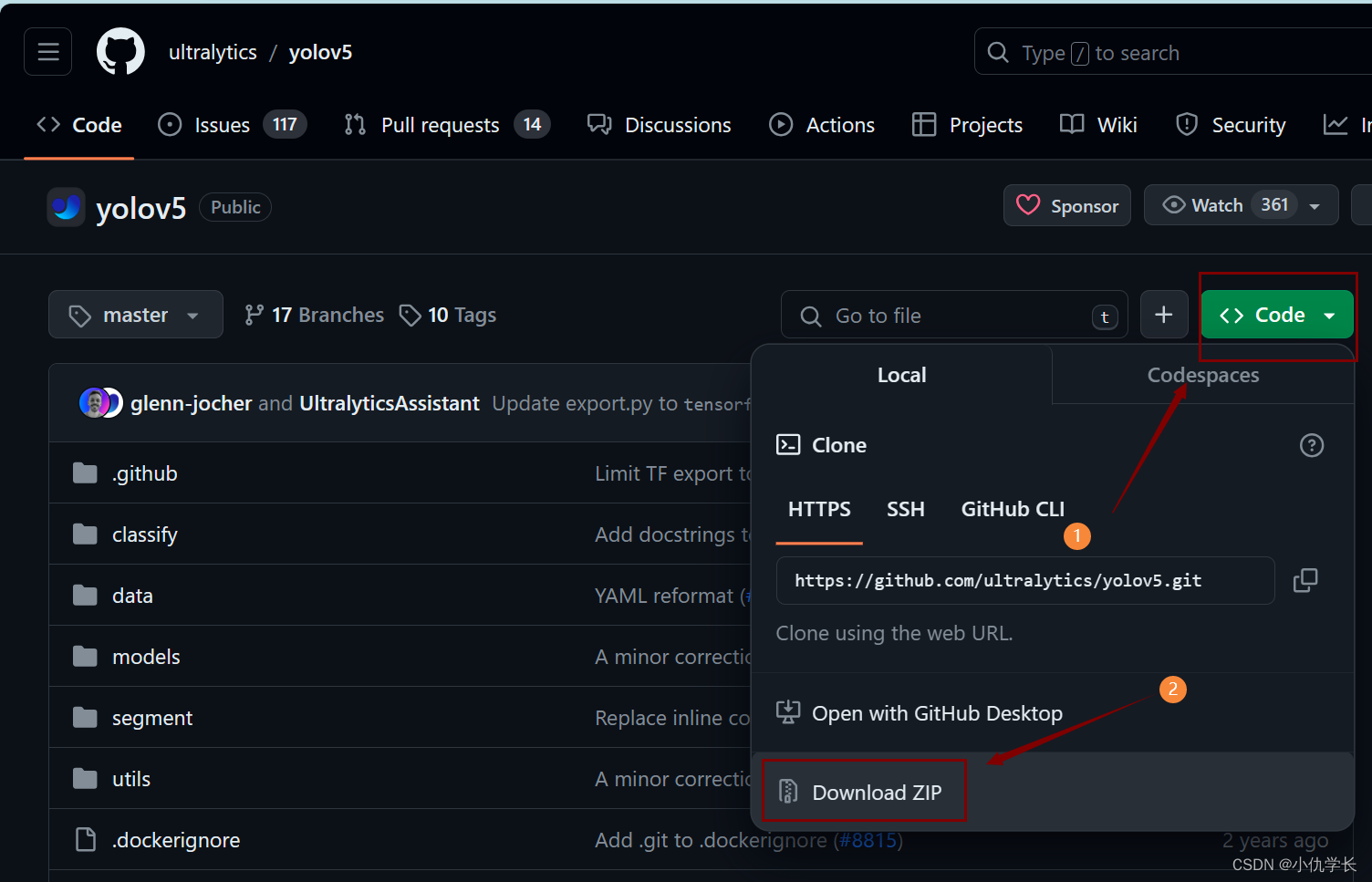
2. 解压后,将原本文件名yolov5-5.0进行重命名。如:yolov5。
3. 创建虚拟环境
(1)使用conda创建新的虚拟环境,python版本3.8!
conda create -n yolov5 python=3.8
(2) conda activate yolov5 激活环境。
(3)cd 进入源码文件夹requirements的目录下,通过 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple ,安装所有的模块文件。
(4)卸载numpy文件,重新装另一个版本的。因为后面会因为这个出错,所以提前准备好。
pip uninstall numpy
pip install numpy==1.22.0
坑1:使用pip时一直出错,看一下是否开着“科学上网vpn”,一定要关掉以后再进行pip操作!
4. 修改源码文件
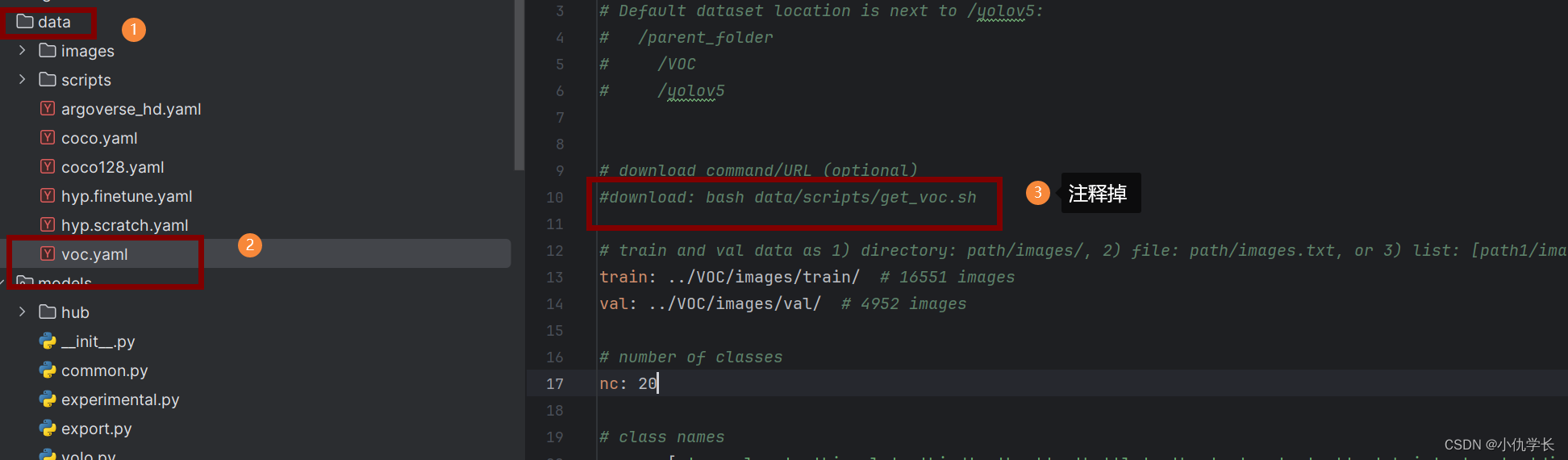
(1) 修改VOC.yaml文件
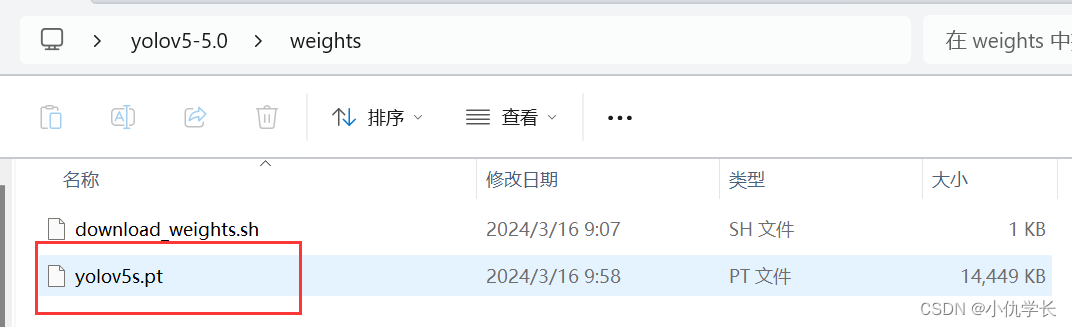
(2)下载预训练模型权重,将其放在weights文件夹中。
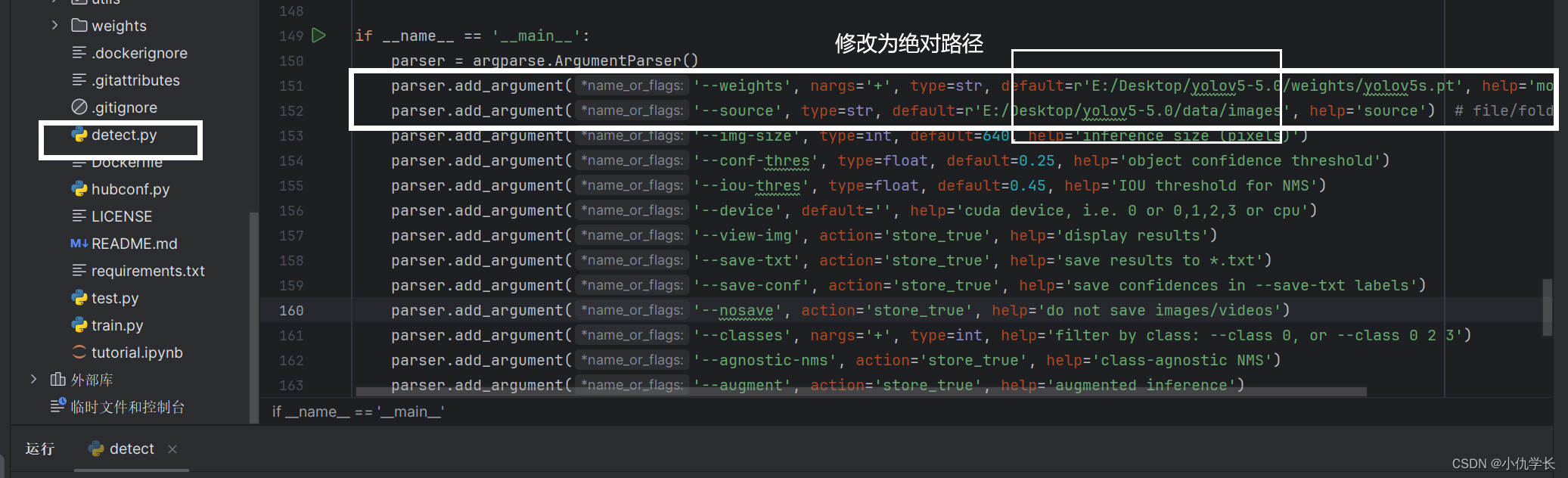
(3)修改detect.py文件
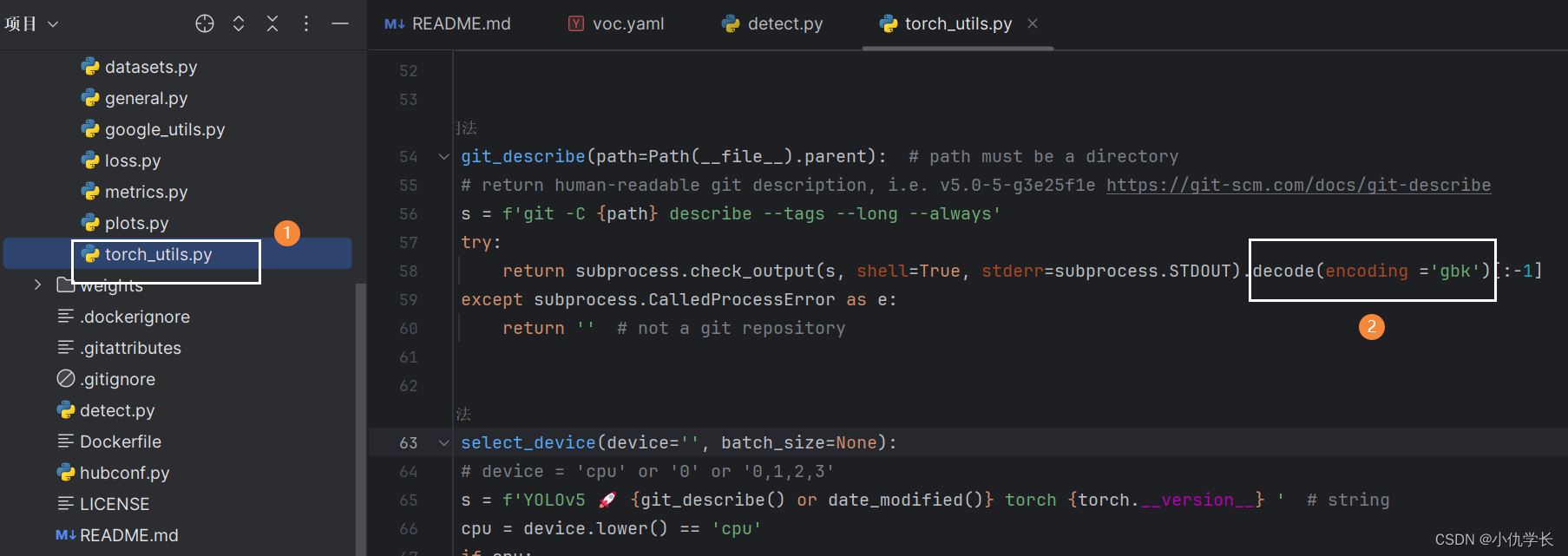
(4)修改torch_utils.py文件
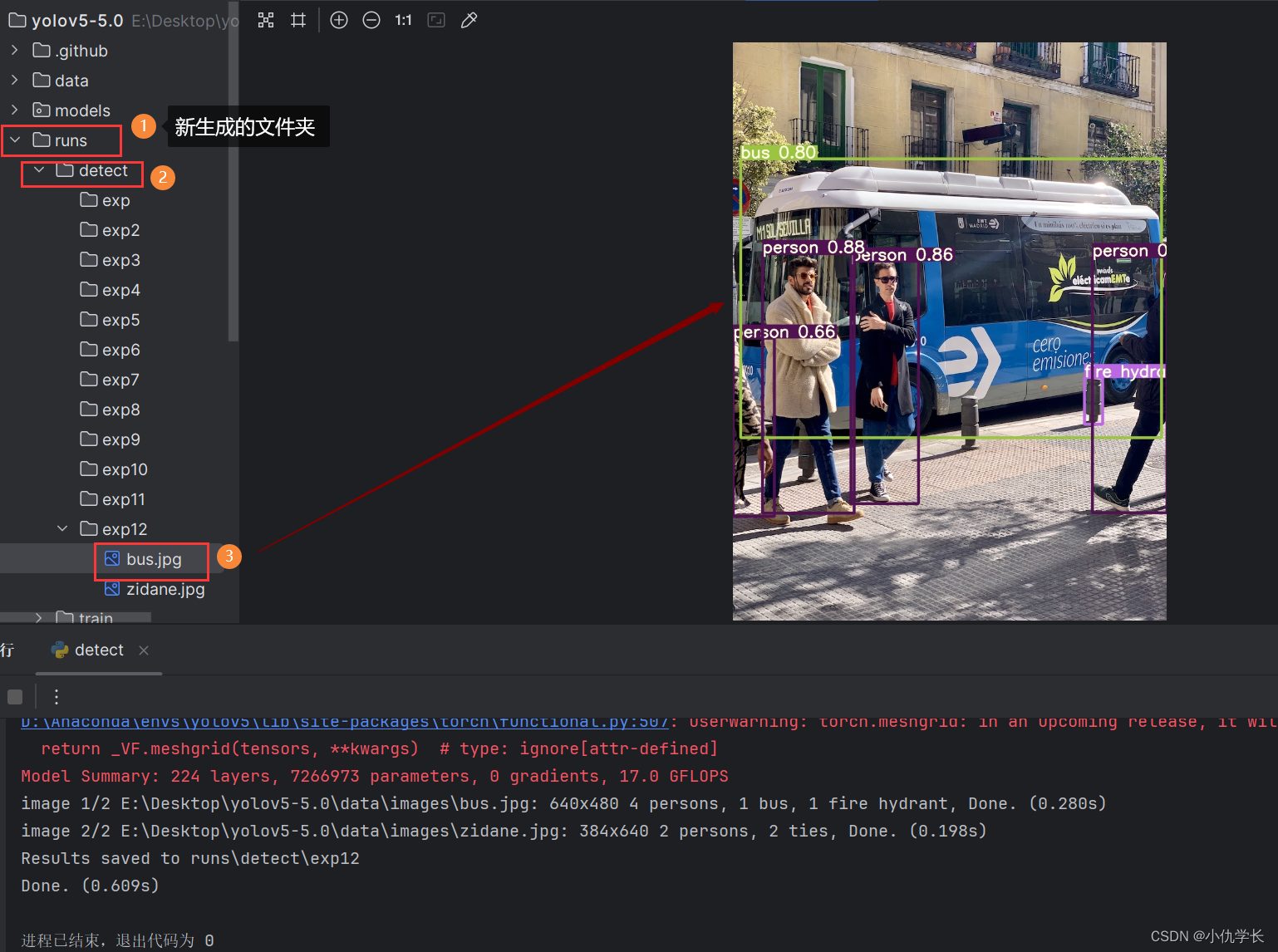
5. 运行源码文件查看效果
进入创建好的虚拟环境,运行detect.py。运行完成后,稍等一段时间,等它生成新的exp文件夹。
二、自建数据集复现
1. 准备数据集
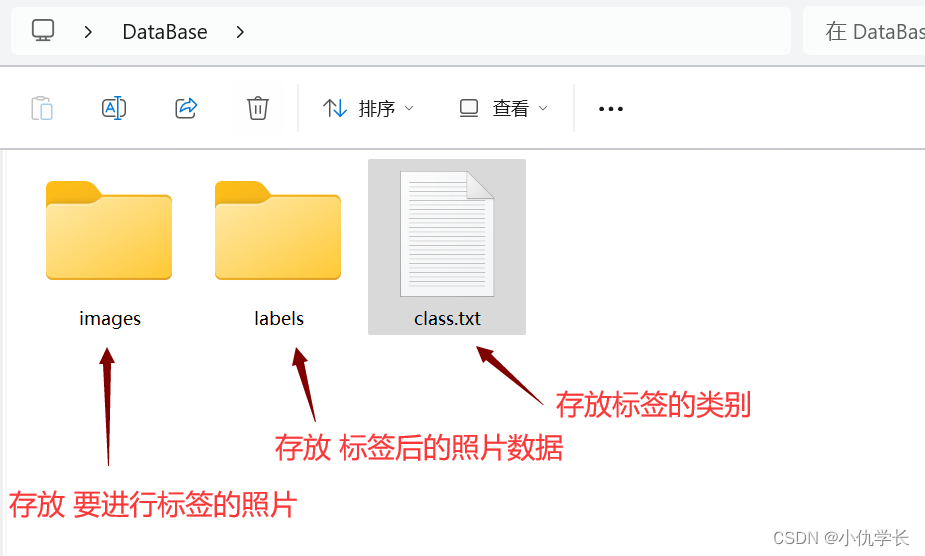
(1)建立文件夹,名称自定义。

(2)进入该文件夹,建立两个新的文件夹。一个存放将要进行标签的图片,另一个存标签后的图片数据。再创建一个txt文件,里面存放标签的类别。
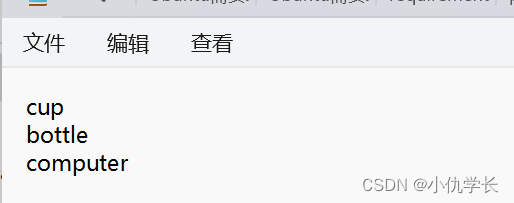
因为我要鉴别电脑,瓶子和杯子,所以我的class.txt文件存放内容如下:
(3) 将自己拍的照片数据集,存放到 images 文件夹中。准备进行标签。
2. 在本机下载labelImg标签软件
(1)进入虚拟环境。
(2)下载labelImg软件。
pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install labelImg -i https://pypi.tuna.tsinghua.edu.cn/simple
(3)安装完成后,在终端输入命令labelImg,即可打开软件!切记!打开软件时,要在虚拟环境下打开!
坑1:若出现标签时闪退的问题!则是python的版本太高了。需要创建虚拟环境时,使用python版本3.8!
3. 进行图像标签

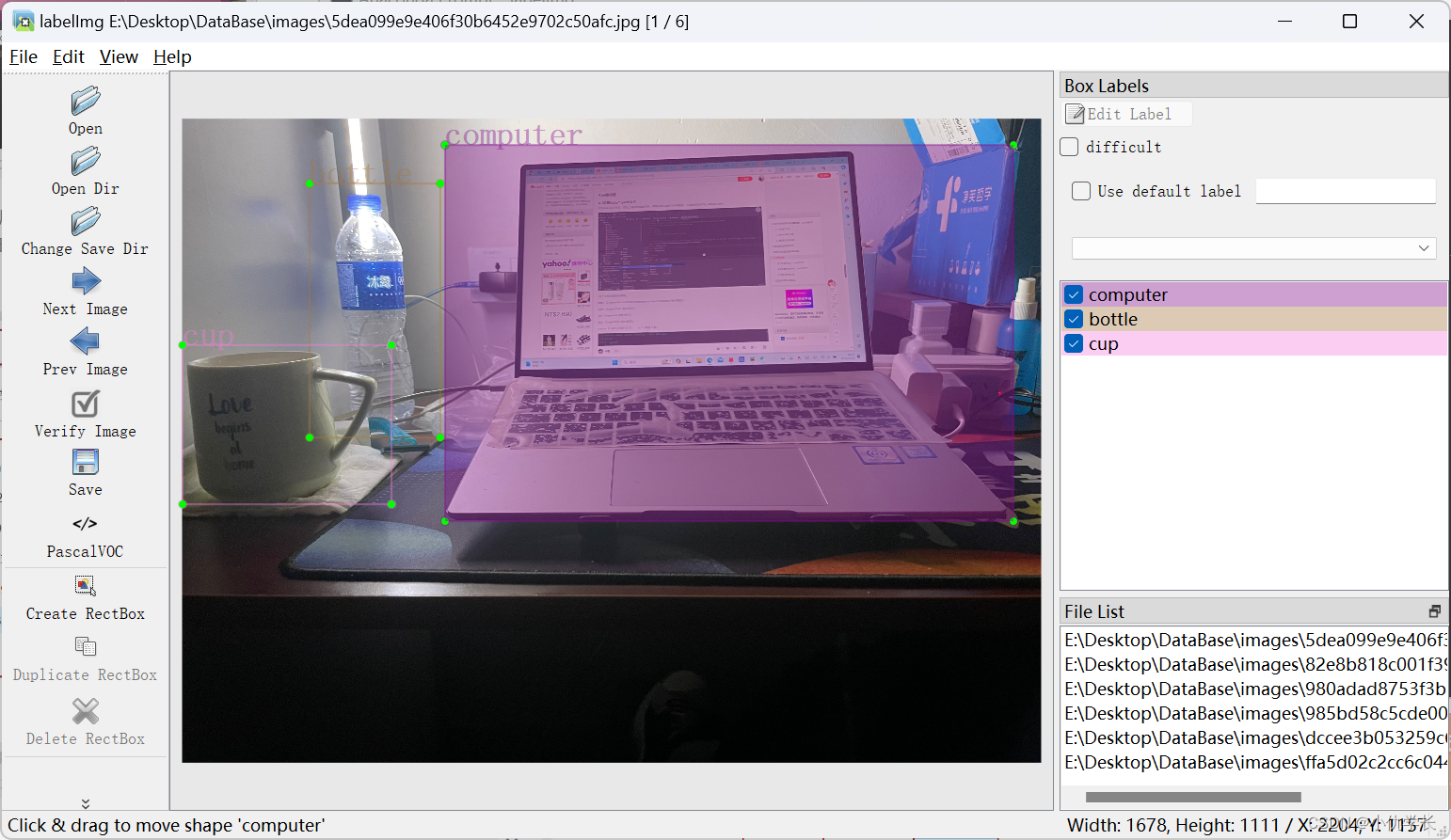
(1) 进行标签操作。按下‘w’ 会有框进行选中,将选中的图片设置好标签。
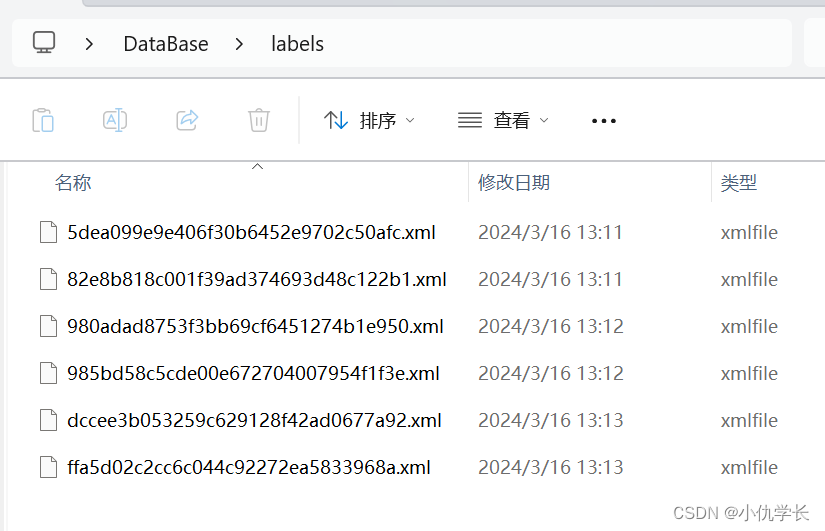
(2)设置好一张就点击下一张,所有图片设置完成后,关闭软件即可。我们就可以在labels文件夹中看到标签后的图片数据。
4. 将数据 xml 格式转换为 txt 格式
(1)在总文件夹中新建change.py文件、labels_txt文件夹。labels里面存放的是xml类型的文件。labels_txt存放转为txt格式的文件。
(2)通过pycharm打开该总文件夹,并配置之前创建的虚拟环境。
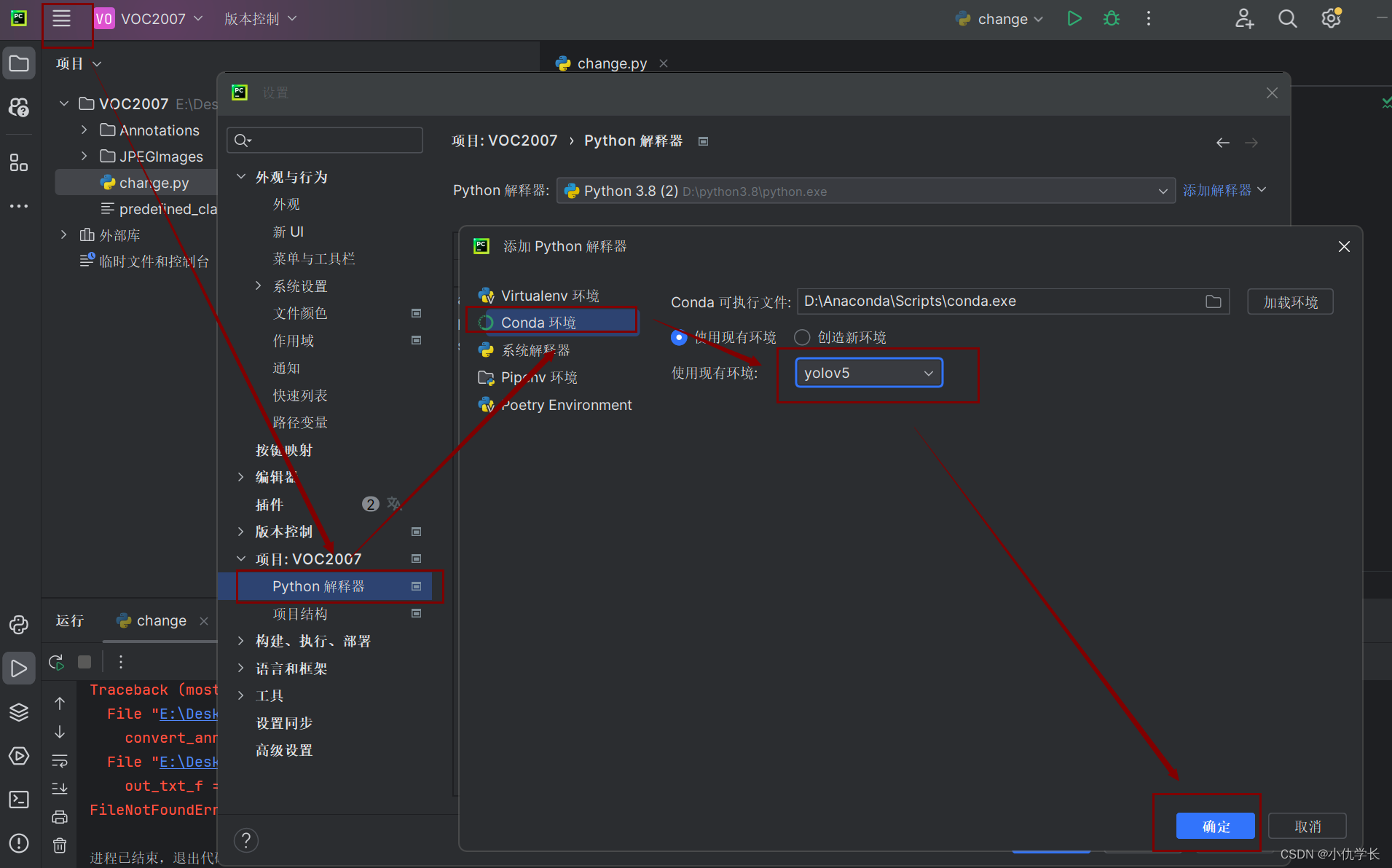
(3)将下面的代码粘贴到change.py中。只需要修改main函数里的文件夹路径,改为自己的即可。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 需要转换的类别,需要一一对应
classes1 = ['cup', 'bottle', 'computer']
# 2、voc格式的xml标签文件路径
xml_files1 = r'E:\Desktop\DataBase\labels'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'E:\Desktop\DataBase\label_txt'
convert_annotation(xml_files1, save_txt_files1, classes1)
代码需要修改的内容如下:
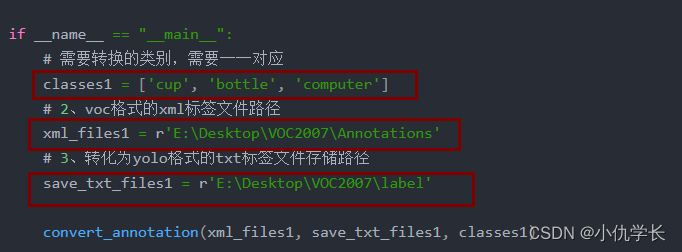
通过下面这样可以查看文件夹路径,修改上面代码即可。
(4)运行change.py,发现labels_txt文件夹中多出了转换后的txt文件。
(5)删除原来的 labels文件夹,并将 labels_txt文件夹重命名为labels。
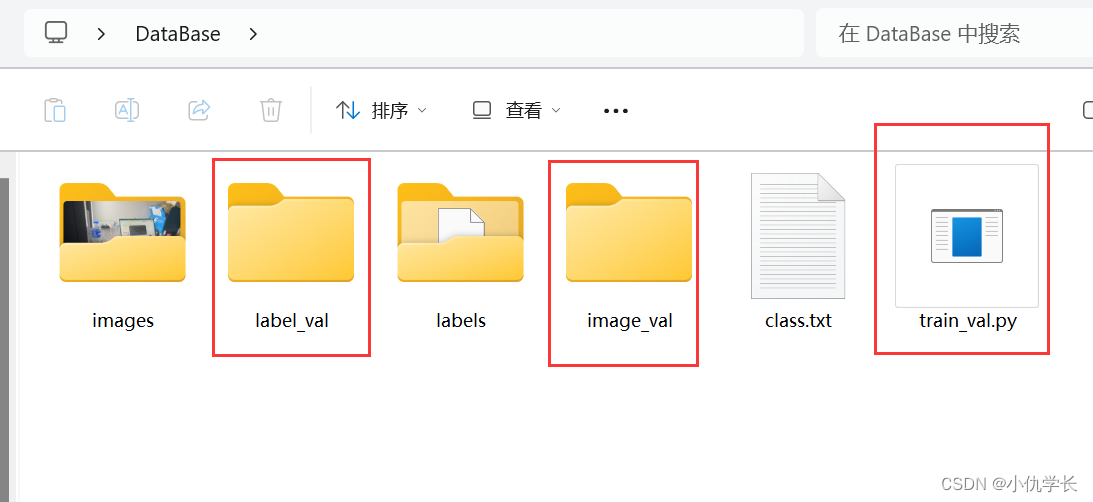
4. 训练集和测试集划分
(1)建立train_val.py文件、label_val文件夹,以及image_val文件夹。
(2) train_val.py文件使用以下代码:
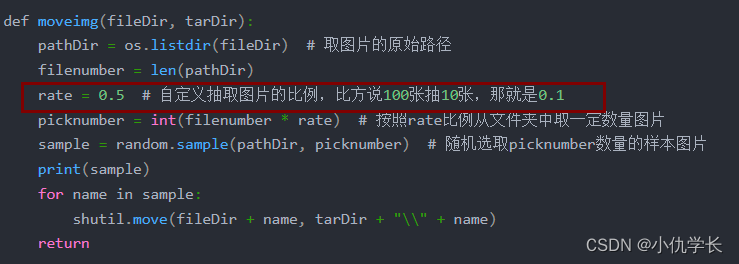
import os, random, shutil
def moveimg(fileDir, tarDir):
pathDir = os.listdir(fileDir) # 取图片的原始路径
filenumber = len(pathDir)
rate = 0.5 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber = int(filenumber * rate) # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
print(sample)
for name in sample:
shutil.move(fileDir + name, tarDir + "\\" + name)
return
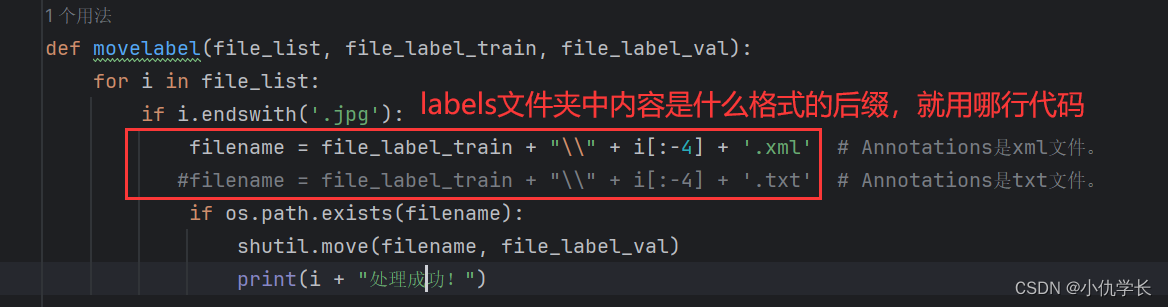
def movelabel(file_list, file_label_train, file_label_val):
for i in file_list:
if i.endswith('.jpg'):
#filename = file_label_train + "\\" + i[:-4] + '.xml' # labels里面是xml文件。
filename = file_label_train + "\\" + i[:-4] + '.txt' # labels里面是txt文件。
if os.path.exists(filename):
shutil.move(filename, file_label_val)
print(i + "处理成功!")
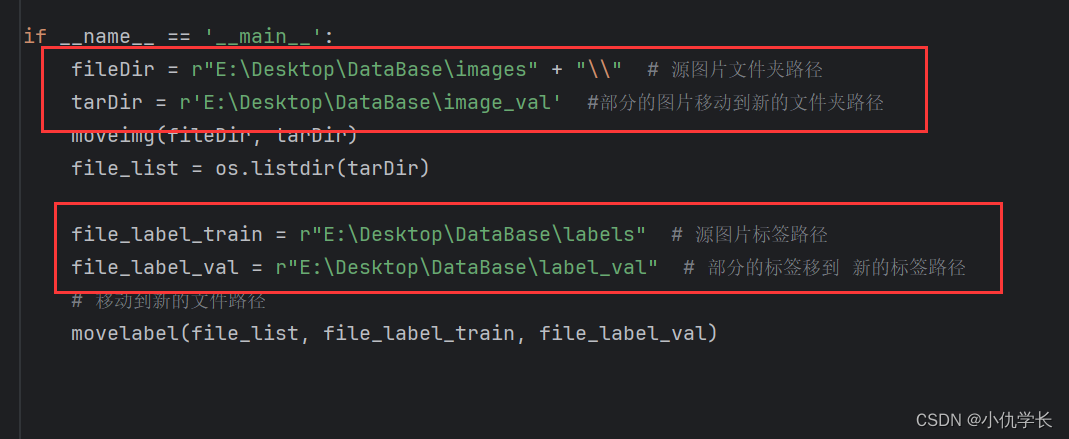
if __name__ == '__main__':
fileDir = r"E:\Desktop\DataBase\images" + "\\" # 源图片文件夹路径
tarDir = r'E:\Desktop\DataBase\image_val' #部分的图片移动到新的文件夹路径
moveimg(fileDir, tarDir)
file_list = os.listdir(tarDir)
file_label_train = r"E:\Desktop\DataBase\labels" # 源图片标签路径
file_label_val = r"E:\Desktop\DataBase\label_val" # 部分的标签移到 新的标签路径
# 移动到新的文件路径
movelabel(file_list, file_label_train, file_label_val)
代码需要修改的地方如下:
(3) 运行train_val.py 代码。
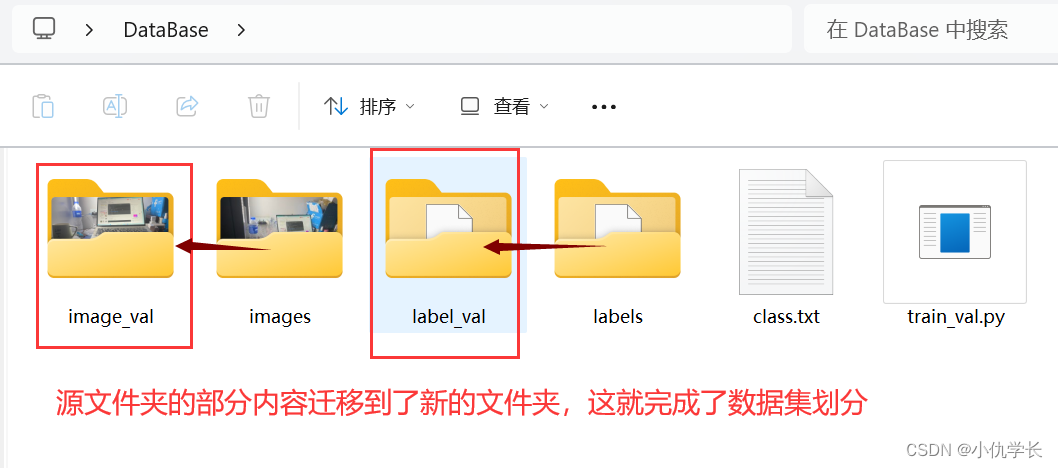
(4)将源文件夹重命名为下面所示。
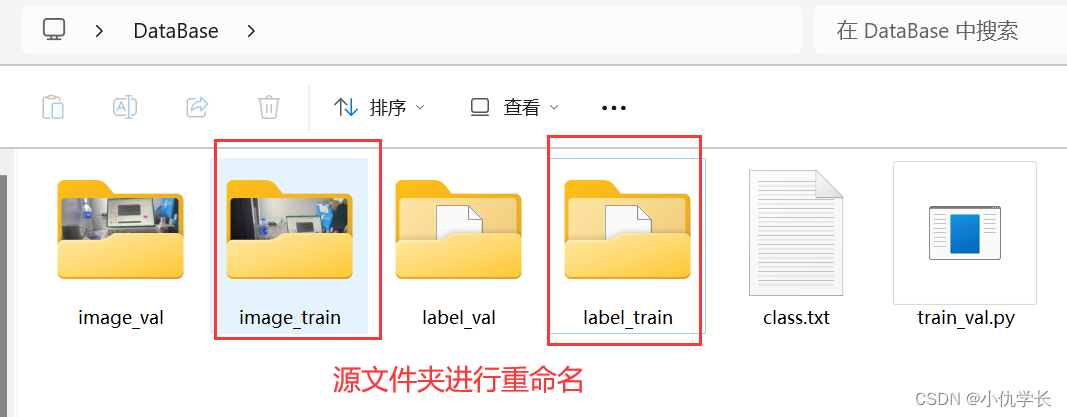
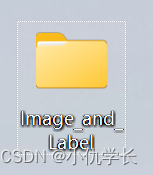
(5)在桌面新建一个文件夹Image_and-Label。并Image_and-Label文件夹中再新建两个文件夹,images 和 labels。用于存放分类好的数据。
(6) 文件夹进行数据复制
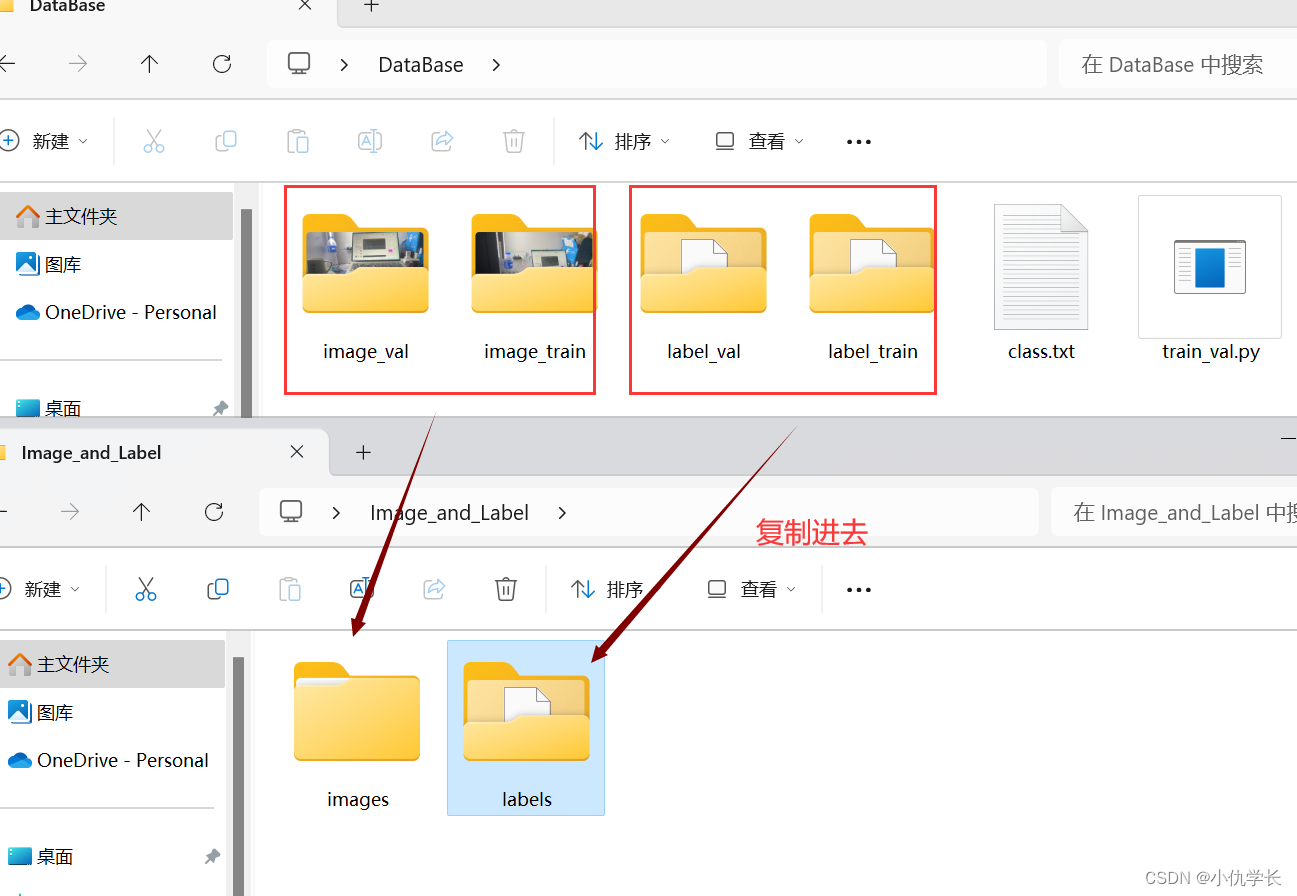
(7)文件夹重命名。将前缀去掉!
(8)再将Image_and-Label文件夹放入代码的工程目录下。
(9)此时数据就已经准备完成了。
5、获得预训练权重
将下载好的权重文件放到工程的weights文件下。
6. 修改代码配置文件
预训练模型和数据集都准备好了,就可以开始训练自己的yolov5目标检测模型了,训练目标检测模型需要修改两个yaml文件中的参数。
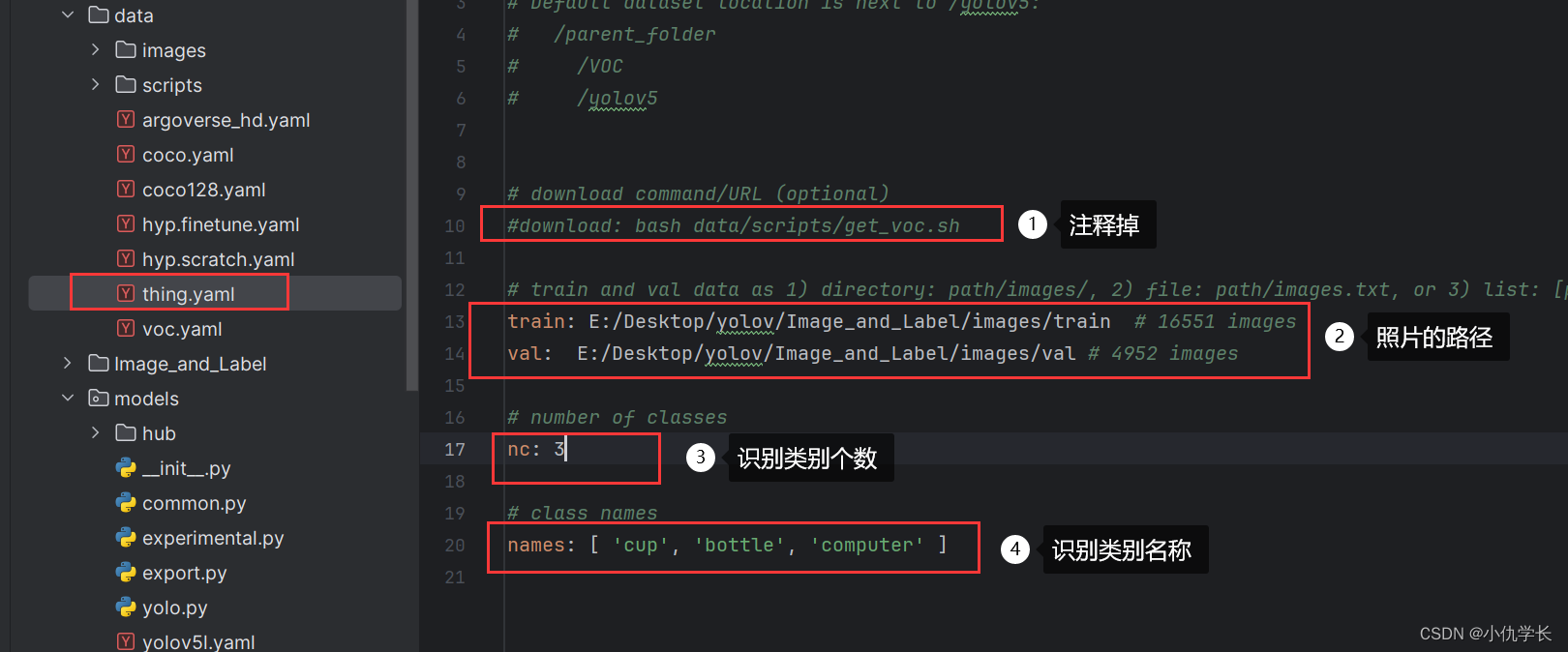
(1)修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名。这里我改为thing.yaml。
打开文件修改下面的配置:
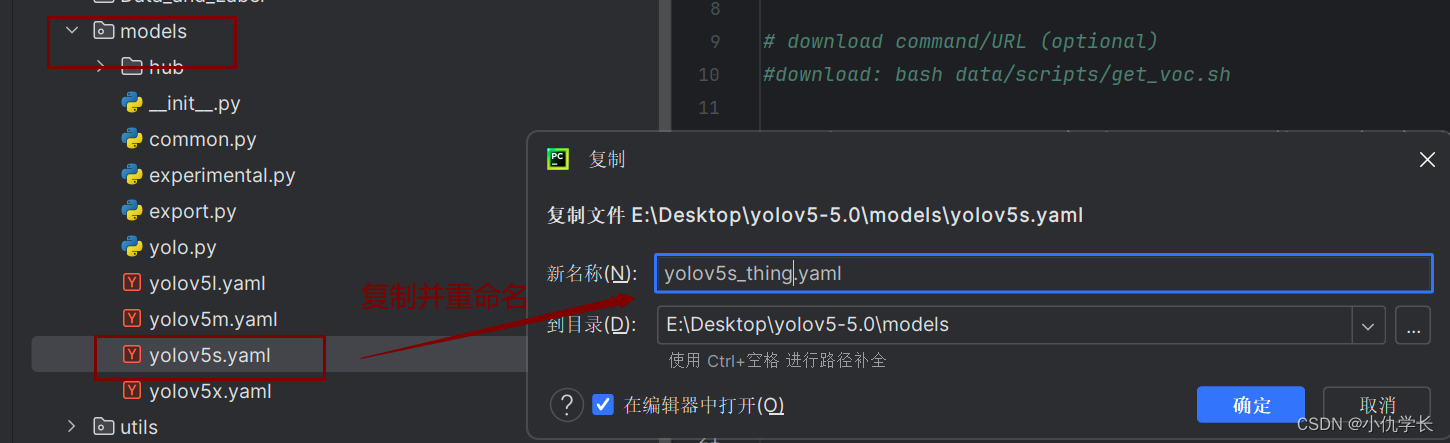
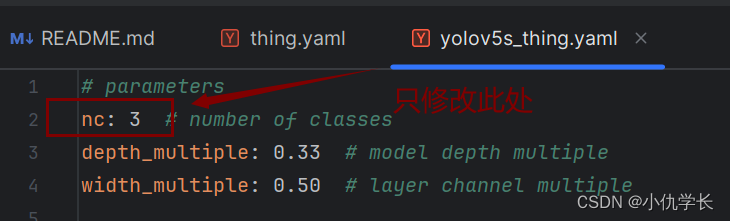
(2)复制module文件夹下的yolov5s.yaml文件,并重命名。修改复制后的文件的参数。
打开文件,并修改识别的类别数目:
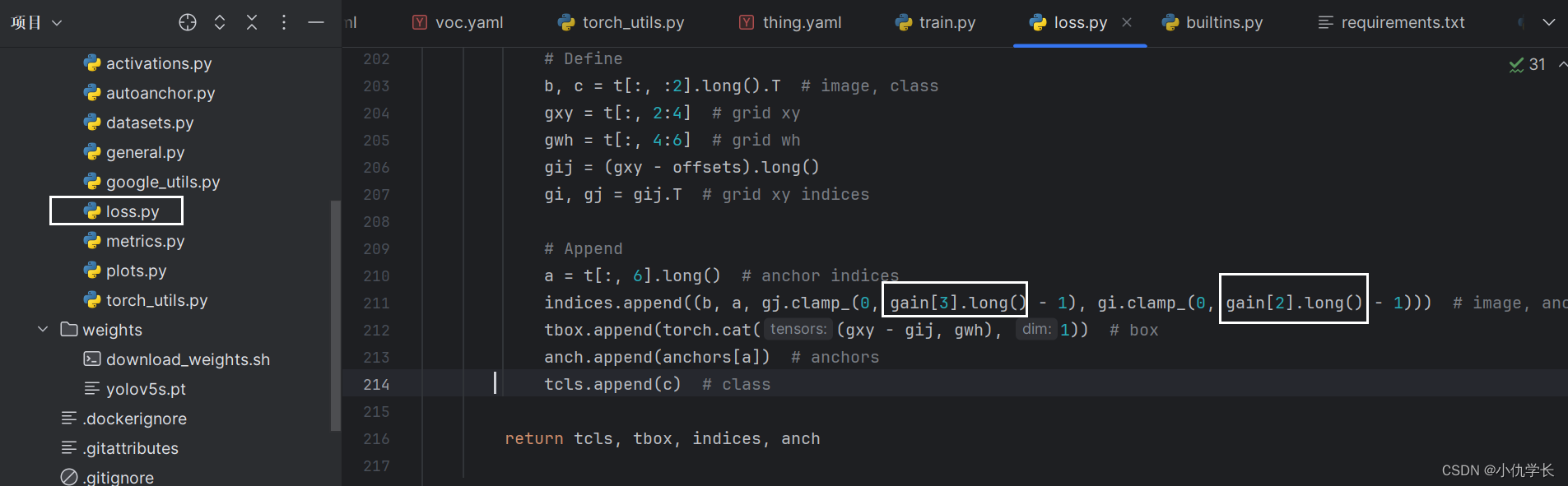
(3)修改utils文件夹下的lose文件参数。
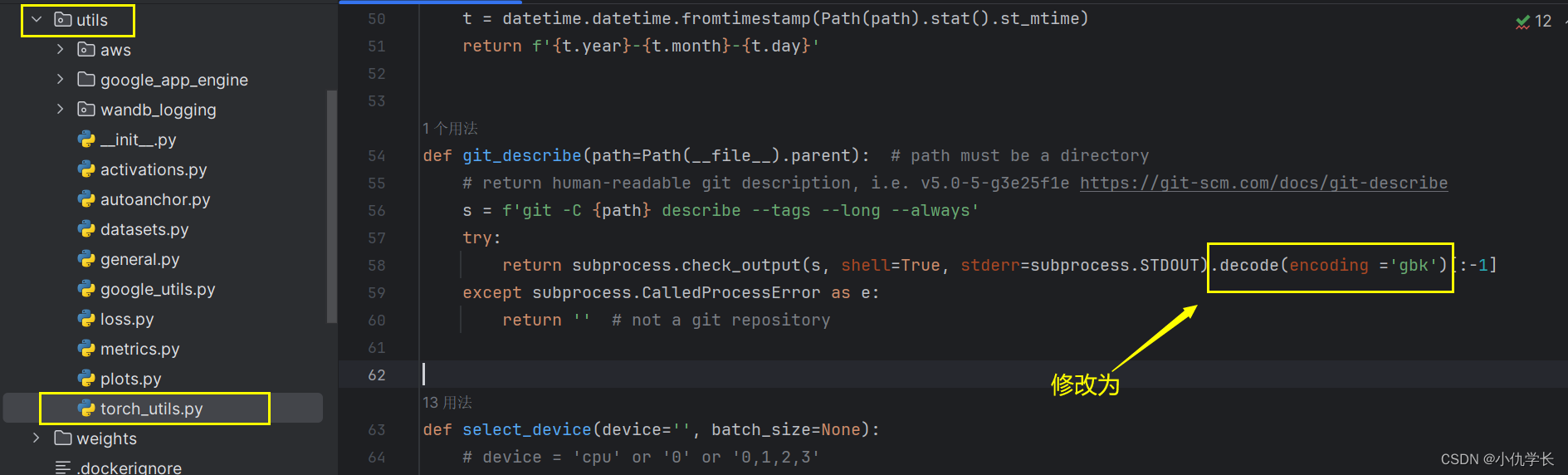
(4)修改utils文件夹下的 torch_utils.py文件参数。
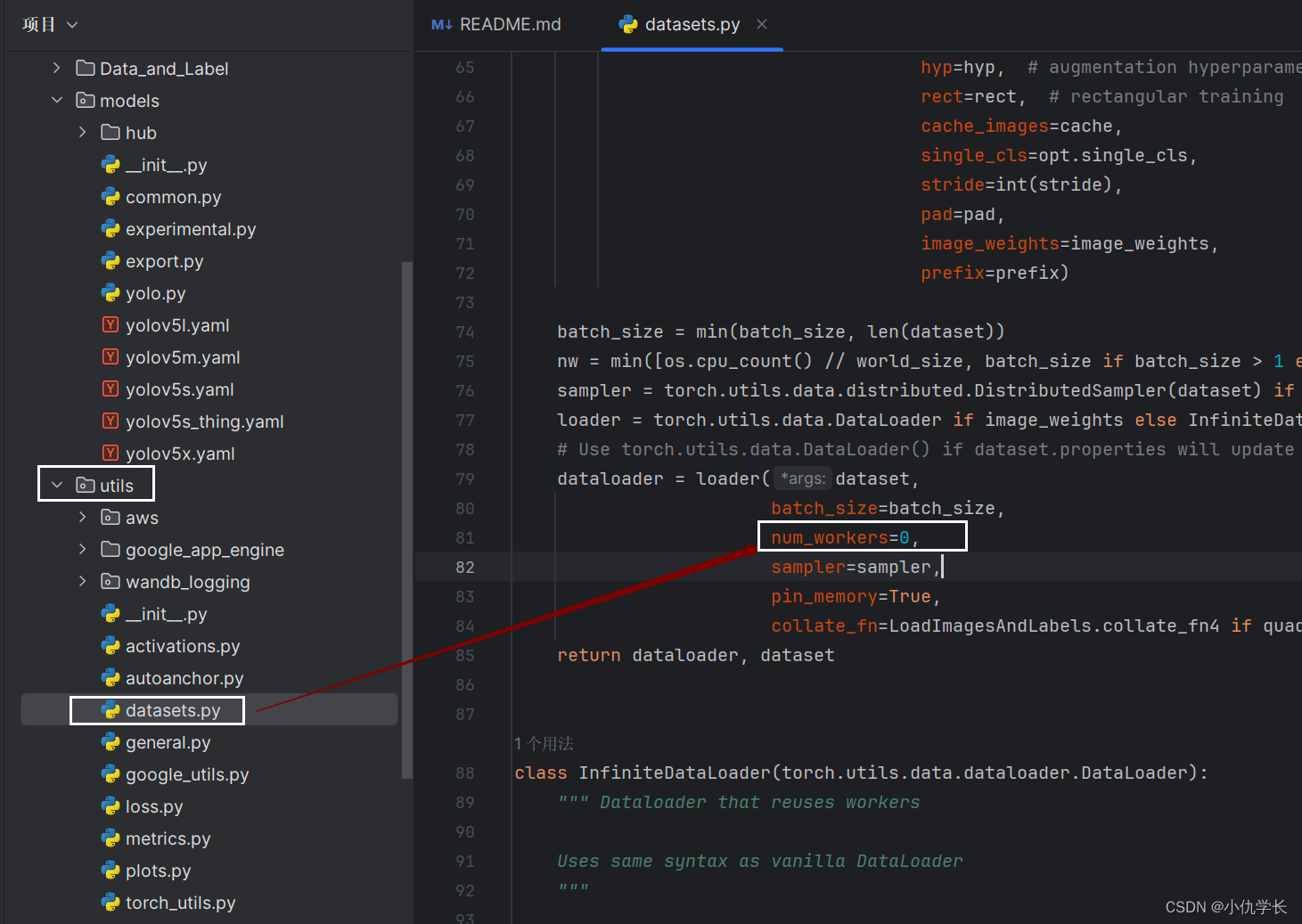
(5)修改utils文件夹下的 datasets.py文件参数。
(6)修改train.py参数

还有几个参数根据自己情况修改。
<1> 模型的训练轮次,这里是训练的300轮。自定!

<2>每次放入模型里图片的个数。自定!默认为16,我这里演示图片较少,我填的是2。

<3>使用cpu的核心数。根据自己电脑修改。自定!

至此,就可以运行train.py函数训练自己的模型了。
(7) 可以通过下面的命令获得网址,将网址打开可查看训练过程。
tensorboard --logdir=runs/train

(8)训练完成后,生成两个权重文件,这里我们使用best.pt。作为我们验证集的使用。

(9)修改detect.py参数,并运行。
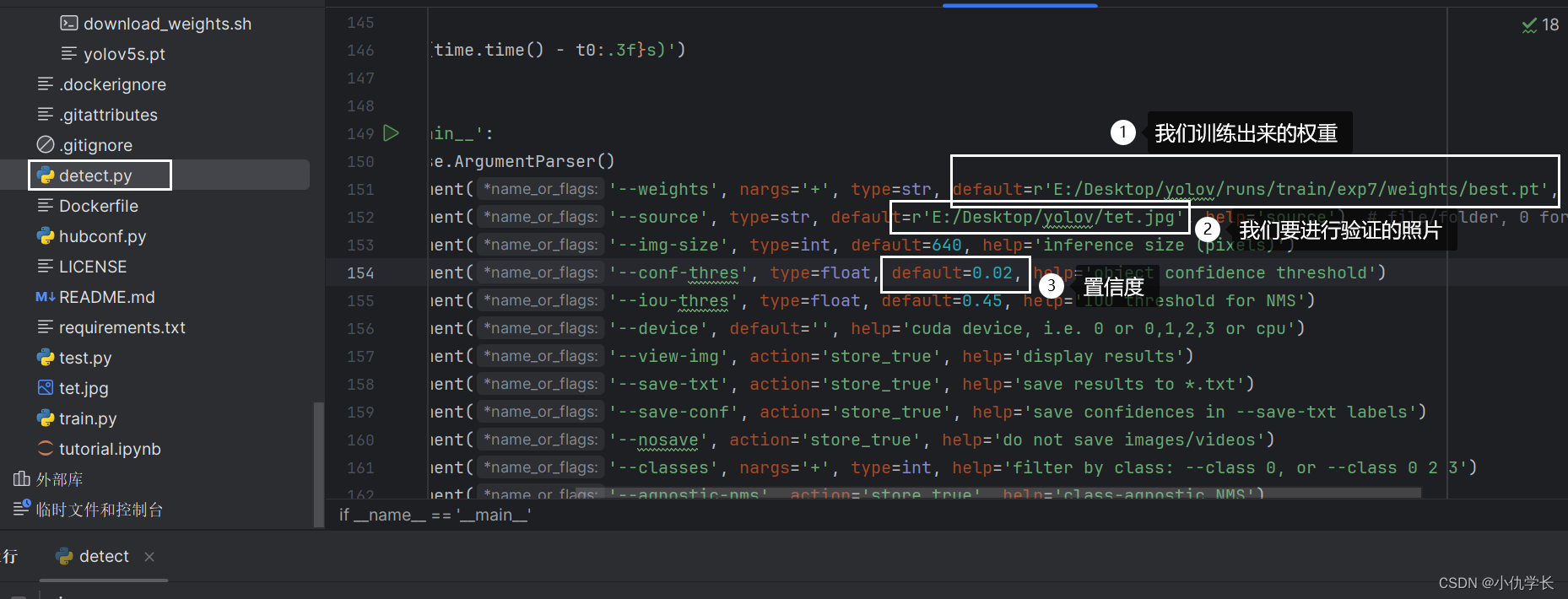
(10)查看验证照片的结果。如果不显示框,说明置信度太大了,将置信度调小一些。
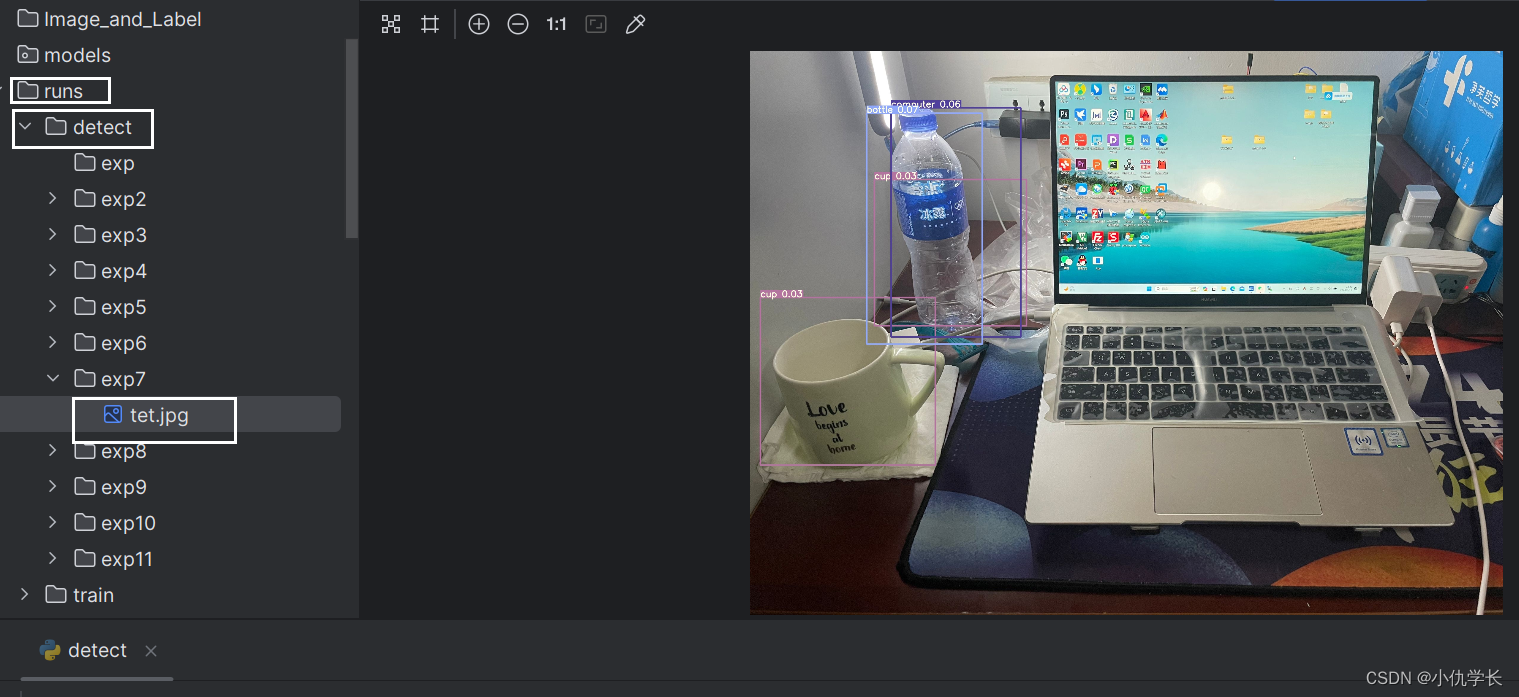
对视频进行测试和图片的测试是一样的,只不过是将图片的路径改为视频的路径而已。利用摄像头进行测试只需将路径改写为0,再找到datasets.py这个py文件修改下面的参数即可。