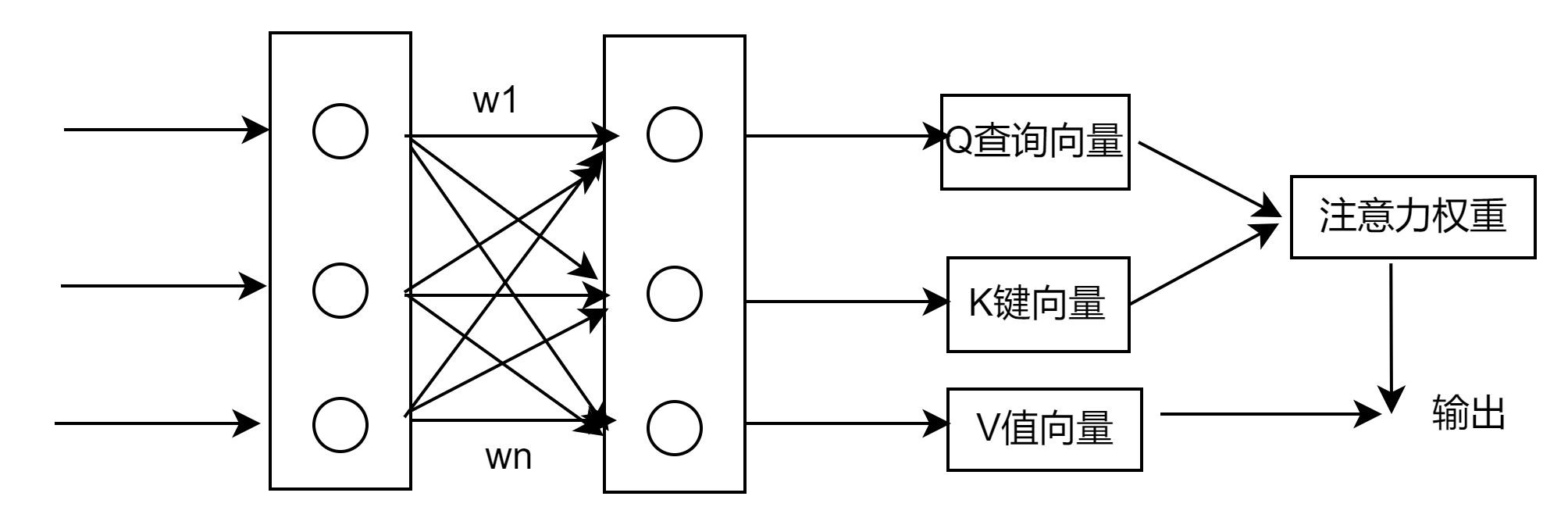
在文章《从熵不变性看Attention的Scale操作》中,我们就从“集中注意力”的角度考察过Attention机制,当时我们以信息熵作为“集中程度”的度量,熵越低,表明Attention越有可能集中在某个token上。
但是,对于一般的Attention机制来说,Attention矩阵可能是非归一化的,比如《FLASH:可能是近来最有意思的高效Transformer设计》介绍的GAU模块,以及《相对位置编码Transformer的一个理论缺陷与对策》所引入的l2归一化Attention,甚至从更一般的Non-Local
Neural
Networks角度来看,Attention矩阵还未必是非负的。这些非归一化的乃至非负的Attention矩阵自然就不适用于信息熵了,因为信息熵是针对概率分布的。为此,我们考虑在《如何度量数据的稀疏程度?》介绍的l1/l2形式的稀疏程度指标:
S ( x ) = E [ ∣ x ∣ ] E [ x 2 ] S(x) = \frac{E[|x|]}{\sqrt{E[x^2]}} S(x)=E[x2]E[∣x∣]该指标跟信息熵相似,S(x)越小意味着对应的随机向量越稀疏,越稀疏意味着越有可能“一家独大”,这对应于概率中的one
hot分布,跟信息熵不同的是,它适用于一般的随机变量或者向量。
稀疏程度指标 S(x) 是用来衡量一个随机变量或随机向量中非零元素的重要性和数量。这个指标与信息熵有关联,但它的侧重点在于度量数据的稀疏程度,即数据中非零元素的平均能量与整个数据的平均能量之比。
在 l1/l2 形式中,S(x) 被定义为:
S ( x ) = E [ ∣ x ∣ ] E [ x 2 ] S(x) = \frac{E[|x|]}{\sqrt{E[x^2]}} S(x)=E[x2]E[∣x∣]
其中 E 表示期望值。S(x) 的值越小,意味着数据 x 的稀疏程度越高。具体来说:
- E [ ∣ x ∣ ] E[|x|] E[∣x∣] 测量的是 x 的绝对值的期望值,这可以理解为数据中非零元素的平均绝对值。
- E [ x 2 ] \sqrt{E[x^2]} E[x2] 测量的是 x 的平方的期望值的平方根,这可以理解为数据中所有元素(包括零和非零)的平均能量。
因此,S(x) 能够反映数据中非零元素相对于整个数据的重要性。如果 S(x) 接近于 0,这通常意味着数据非常稀疏,大部分元素都是零,只有少数非零元素对整体能量有显著贡献。这种情况下,数据可能近似于 one-hot 分布,即大部分元素为零,只有一个元素为非零。
需要注意的是,虽然 S(x) 可以用来衡量稀疏程度,但它并不直接度量信息熵。信息熵通常用于度量一个随机变量的不确定性或信息含量,而 S(x) 更侧重于度量数据中非零元素的重要性和数量。
简化形式 #
对于注意力机制,我们记 a = ( a 1 , a 2 , ⋯ , a n ) a=(a1,a2,⋯,an) a=(a1,a2,⋯,an),其中 a j ∝ f ( q ⋅ k j ) aj∝f(q⋅kj) aj∝f(q⋅kj),那么
S ( a ) = E k [ ∣ f ( q ⋅ k ) ∣ ] E k [ f 2 ( q ⋅ k ) ] − − − − − − − − − − √ ( 2 ) S(a)=Ek[|f(q⋅k)|]Ek[f2(q⋅k)]−−−−−−−−−−√(2) S(a)=Ek[∣f(q⋅k)∣]Ek[f2(q⋅k)]−−−−−−−−−−√(2)接下来都考虑 n → ∞ n→∞ n→∞的极限。假设 k ∼ N ( μ , σ 2 I ) k∼N(μ,σ2I) k∼N(μ,σ2I),那么可以设 k = μ + σ ε k=μ+σε k=μ+σε,其中 ε ∼ N ( 0 , I ) ε∼N(0,I) ε∼N(0,I),于是
S ( a ) = E ε [ ∣ f ( q ⋅ μ + σ q ⋅ ε ) ∣ ] E ε [ f 2 ( q ⋅ μ + σ q ⋅ ε ) ] − − − − − − − − − − − − − − − − − √ ( 3 ) S(a)=Eε[|f(q⋅μ+σq⋅ε)|]Eε[f2(q⋅μ+σq⋅ε)]−−−−−−−−−−−−−−−−−√(3) S(a)=Eε[∣f(q⋅μ+σq⋅ε)∣]Eε[f2(q⋅μ+σq⋅ε)]−−−−−−−−−−−−−−−−−√(3)注意ε所服从的分布 N ( 0 , I ) N(0,I) N(0,I)是一个各向同性的分布,与《n维空间下两个随机向量的夹角分布》推导的化简思路一样,由于各向同性的原因, q ⋅ ε q⋅ε q⋅ε相关的数学期望只与 q q q的模长有关,跟它的方向无关,于是我们可以将 q q q简化为(∥q∥,0,0,⋯,0),那么对ε的数学期望就可以简化为
S ( a ) = E ε [ ∣ f ( q ⋅ μ + σ ∥ q ∥ ε ) ∣ ] E ε [ f 2 ( q ⋅ μ + σ ∥ q ∥ ε ) ] − − − − − − − − − − − − − − − − − √ ( 4 ) S(a)=Eε[|f(q⋅μ+σ∥q∥ε)|]Eε[f2(q⋅μ+σ∥q∥ε)]−−−−−−−−−−−−−−−−−√(4) S(a)=Eε[∣f(q⋅μ+σ∥q∥ε)∣]Eε[f2(q⋅μ+σ∥q∥ε)]−−−−−−−−−−−−−−−−−√(4)其中ε∼N(0,1)是一个随机标量。
您所描述的简化形式是针对注意力机制中的某个指标 S ( a ) S(a) S(a)。首先,我们记 a = ( a 1 , a 2 , ⋯ , a n ) a=(a1,a2,⋯,an) a=(a1,a2,⋯,an),其中 a j ∝ f ( q ⋅ k j ) aj∝f(q⋅kj) aj∝f(q⋅kj)。然后,我们考虑 n → ∞ n→∞ n→∞的极限。为了简化计算,假设 k ∼ N ( μ , σ 2 I ) k∼N(μ,σ2I) k∼N(μ,σ2I),那么可以设 k = μ + σ ε k=μ+σε k=μ+σε,其中 ε ∼ N ( 0 , I ) ε∼N(0,I) ε∼N(0,I)。
接下来,我们利用各向同性的性质来简化计算。由于 ε ε ε 所服从的分布 N ( 0 , I ) N(0,I) N(0,I)是一个各向同性的分布,与《n 维空间下两个随机向量的夹角分布》推导的化简思路一样,由于各向同性的原因, q ⋅ ε q⋅ε q⋅ε 相关的数学期望只与 q q q 的模长有关,跟它的方向无关。于是我们可以将 q q q 简化为 ( ‖ q ‖ , 0 , 0 , ⋯ , 0 ) (‖q‖,0,0,⋯,0) (‖q‖,0,0,⋯,0),那么对 ε ε ε 的数学期望就可以简化为:
S ( a ) = E ε [ ∣ f ( q ⋅ μ + σ ‖ q ‖ ε ) ∣ ] E ε [ f 2 ( q ⋅ μ + σ ‖ q ‖ ε ) ] S(a) = Eε[|f(q⋅μ+σ‖q‖ε)|]Eε[f^2(q⋅μ+σ‖q‖ε)] S(a)=Eε[∣f(q⋅μ+σ‖q‖ε)∣]Eε[f2(q⋅μ+σ‖q‖ε)]
其中 ε ∼ N ( 0 , 1 ) ε∼N(0,1) ε∼N(0,1) 是一个随机标量。这样,我们就成功地将原本复杂的计算简化为了更易于处理的随机标量计算。
这里是引用现在可以对常见的一些f进行计算对比了。目前最常用的Attention机制是 f = e x p f=exp f=exp,此时求期望只是常规的一维高斯积分,容易算得
S ( a ) = e x p ( − 12 σ 2 ∥ q ∥ 2 ) ( 5 ) S(a)=exp(−12σ2∥q∥2)(5) S(a)=exp(−12σ2∥q∥2)(5)当 σ → ∞ σ→∞ σ→∞或 ∥ q ∥ → ∞ ∥q∥→∞ ∥q∥→∞时,都有 S ( a ) → 0 S(a)→0 S(a)→0,也就是理论上标准Attention确实可以任意稀疏地“集中注意力”,同时这也告诉了我们让注意力更集中的方法:增大q的模长,或者增大各个k之间的方差,换言之拉开k的差距。
另一个例子是笔者喜欢的GAU(Gated Attention
Unit),它在开始提出的时候是 f = r e l u 2 f=relu2 f=relu2(不过笔者后来自己用的时候复原为Softmax了,参考《FLASH:可能是近来最有意思的高效Transformer设计》和《听说Attention与Softmax更配哦~》),此时积分没有 f = e x p f=exp f=exp那么简单,不过也可以直接用Mathematica硬算,结果是
S ( a ) = e − β 22 γ 2 ( 2 − − √ β γ + π − − √ e β 22 γ 2 ( β 2 + γ 2 ) ( e r f ( β 2 √ γ ) + 1 ) ) π − − √ 422 − − √ β γ e − β 22 γ 2 ( β 2 + 5 γ 2 ) + 2 π − − √ ( β 4 + 6 β 2 γ 2 + 3 γ 4 ) ( e r f ( β 2 √ γ ) + 1 ) − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − √ ( 6 ) S(a)=e−β22γ2(2−−√βγ+π−−√eβ22γ2(β2+γ2)(erf(β2√γ)+1))π−−√422−−√βγe−β22γ2(β2+5γ2)+2π−−√(β4+6β2γ2+3γ4)(erf(β2√γ)+1)−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−√(6) S(a)=e−β22γ2(2−−√βγ+π−−√eβ22γ2(β2+γ2)(erf(β2√γ)+1))π−−√422−−√βγe−β22γ2(β2+5γ2)+2π−−√(β4+6β2γ2+3γ4)(erf(β2√γ)+1)−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−√(6)其中 β = q ⋅ μ , γ = σ ∥ q ∥ β=q⋅μ,γ=σ∥q∥ β=q⋅μ,γ=σ∥q∥。式子很恐怖,但是无所谓,画图即可: relu2注意力的稀疏程度曲线图 relu2注意力的稀疏程度曲线图
可以看到,只有 β < 0 β<0 β<0时,原版GAU的稀疏度才有机会趋于0。这也很直观,当偏置项小于0时,才有更多的机会让relu的结果为0,从而实现稀疏。这个结果也说明了跟f=exp的标准注意力不同,k的bias项可能会对 f = r e l u 2 f=relu2 f=relu2的GAU有正面帮助。
您举了两个例子,分别是常见的高斯注意力(Gaussian Attention)和笔者喜欢的 GAU(Gated Attention Unit)。通过对这两种注意力机制的稀疏程度进行分析,我们可以更深入地了解它们的特点。
- 高斯注意力:对于高斯注意力,我们使用 f = e x p f=exp f=exp。这种情况下,求期望只是常规的一维高斯积分。根据您给出的公式(5),我们可以得到 S ( a ) = e x p ( − 12 σ 2 ∥ q ∥ 2 ) S(a)=exp(−12σ2∥q∥2) S(a)=exp(−12σ2∥q∥2)。当 σ → ∞ σ→∞ σ→∞ 或 ∥ q ∥ → ∞ ∥q∥→∞ ∥q∥→∞ 时,都有 S ( a ) → 0 S(a)→0 S(a)→0。这意味着理论上标准注意力确实可以任意稀疏地“集中注意力”。同时,这个结果也告诉了我们让注意力更集中的方法:增大 q q q 的模长,或者增大各个 k k k 之间的方差,换言之拉开 k k k 的差距。
- GAU(Gated Attention Unit):对于 GAU,您提到开始提出的时候是 f = r e l u 2 f=relu2 f=relu2。这种情况下,积分没有 f = e x p f=exp f=exp 那么简单。根据您给出的公式(6),我们可以得到 S ( a ) = e − β 22 γ 2 ( 2 − − √ β γ + π − − √ e β 22 γ 2 ( β 2 + γ 2 ) ( e r f ( β 2 √ γ ) + 1 ) ) π − − √ 422 − − √ β γ e − β 22 γ 2 ( β 2 + 5 γ 2 ) + 2 π − − √ ( β 4 + 6 β 2 γ 2 + 3 γ 4 ) ( e r f ( β 2 √ γ ) + 1 ) − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − √ S(a)=e−β22γ2(2−−√βγ+π−−√eβ22γ2(β2+γ2)(erf(β2√γ)+1))π−−√422−−√βγe−β22γ2(β2+5γ2)+2π−−√(β4+6β2γ2+3γ4)(erf(β2√γ)+1)−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−√ S(a)=e−β22γ2(2−−√βγ+π−−√eβ22γ2(β2+γ2)(erf(β2√γ)+1))π−−√422−−√βγe−β22γ2(β2+5γ2)+2π−−√(β4+6β2γ2+3γ4)(erf(β2√γ)+1)−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−√。从公式中可以看出,只有 β < 0 β<0 β<0 时,原版 GAU 的稀疏度才有机会趋于 0。这也说明了跟 f = e x p f=exp f=exp 的标准注意力不同,k 的 bias 项可能会对 f = r e l u 2 f=relu2 f=relu2 的 GAU 有正面帮助。
通过以上分析,我们可以看出不同注意力机制在稀疏程度方面的差异。这些差异有助于我们根据具体任务需求选择合适的注意力机制。
下面我们再来看一个最简单的例子:不加f,或者等价地说 f = i d e n t i c a l f=identical f=identical。这种情况下对应的就是最简单的一种线性Attention,同样可以用Mathematica硬算得:
S ( a ) = 2 π − − √ γ e − β 22 γ 2 + β e r f ( β 2 √ γ ) β 2 + γ 2 − − − − − − √ ( 7 ) S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√(7) S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√(7)下面是几个不同β的函数图像: 极简线性注意力的稀疏程度曲线图 极简线性注意力的稀疏程度曲线图
注意,此时的S(a)是关于β偶函数(读者不妨尝试证明一下),所以β<0时图像跟它相反数的图像是一样的,因此上图只画了β≥0的结果。从图中可以看出,不加任何激活函数的线性Attention的稀疏程度并不能接近0,而是存在一个较高的下限,这意味着当输入序列足够长时,这种线性Attention并没有办法“集中注意力”到关键位置上。
您提到了一个最简单的注意力机制例子:不加 f f f,或者等价地说 f = i d e n t i c a l f=identical f=identical。这种情况下对应的就是最简单的一种线性 Attention。根据您给出的公式(7),我们可以得到 S ( a ) = 2 π − − √ γ e − β 22 γ 2 + β e r f ( β 2 √ γ ) β 2 + γ 2 − − − − − − √ S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√ S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√。
您还提到了 S ( a ) S(a) S(a) 是关于 β β β 的偶函数,所以 β < 0 β<0 β<0 时图像跟它相反数的图像是一样的。因此,在上图中只画了 β ≥ 0 β≥0 β≥0 的结果。从图中可以看出,不加任何激活函数的线性 Attention 的稀疏程度并不能接近 0,而是存在一个较高的下限。这意味着当输入序列足够长时,这种线性 Attention 并没有办法“集中注意力”到关键位置上。
通过这个例子,我们可以看出激活函数 f 在注意力机制中的重要作用。引入适当的激活函数(如 exp、relu2 等)可以帮助注意力更好地集中在关键位置上,从而提高模型的性能。这也是为什么在实际应用中,我们经常会看到各种不同的注意力机制变种,它们通过引入不同的激活函数来适应不同的任务需求。
从《线性 Attention 的探索:Attention 必须有个 Softmax 吗?》我们知道,线性 Attention 的一般形式为 a j ∝ g ( q ) ⋅ h ( k j ) a_j \propto g(q) \cdot h(k_j) aj∝g(q)⋅h(kj),其中 g,h 是值域非负的激活函数。我们记 q ′ = g ( q ) q' = g(q) q′=g(q), k ′ = h ( k ) k' = h(k) k′=h(k),那么 a j ∝ q ′ ⋅ k ′ a_j \propto q' \cdot k' aj∝q′⋅k′,并且可以写出:
S ( a ) = E [ ϵ ⋅ q ′ ⋅ k ′ ] E [ ϵ ⋅ q ′ ⋅ k ′ ⋅ k ′ ⋅ q ′ ] = q ′ ⋅ E [ ϵ ⋅ k ′ ] ⋅ q ′ q ′ ⋅ E [ ϵ ⋅ k ′ ⋅ k ′ ⋅ q ′ ] ⋅ q ′ = q ′ ⋅ μ ′ ⋅ q ′ q ′ ⋅ ( μ ′ ⋅ μ ′ T + Σ ′ ) ⋅ q ′ = 1 1 + q ′ ⋅ Σ ′ ⋅ q ′ ⋅ ( q ′ ⋅ μ ′ ) 2 S(a) = \frac{E[\epsilon \cdot q' \cdot k']}{\sqrt{E[\epsilon \cdot q' \cdot k' \cdot k' \cdot q']}} = \frac{q' \cdot E[\epsilon \cdot k'] \cdot q'}{\sqrt{q' \cdot E[\epsilon \cdot k' \cdot k' \cdot q'] \cdot q'}} = \frac{q' \cdot \mu' \cdot q'}{\sqrt{q' \cdot (\mu' \cdot \mu'^T + \Sigma') \cdot q'}} = \frac{1}{1 + q' \cdot \Sigma' \cdot q'} \cdot (q' \cdot \mu')^2 S(a)=E[ϵ⋅q′⋅k′⋅k′⋅q′]E[ϵ⋅q′⋅k′]=q′⋅E[ϵ⋅k′⋅k′⋅q′]⋅q′q′⋅E[ϵ⋅k′]⋅q′=q′⋅(μ′⋅μ′T+Σ′)⋅q′q′⋅μ′⋅q′=1+q′⋅Σ′⋅q′1⋅(q′⋅μ′)2
这是关于非负型线性 Attention 的一般结果,现在还没做任何近似,其中 μ ′ \mu' μ′, Σ ′ \Sigma' Σ′ 分别是 k ′ k' k′ 序列的均值向量和协方差矩阵。
从这个结果可以看出,非负型线性 Attention 也可能任意稀疏(即 S ( a ) → 0 S(a) \rightarrow 0 S(a)→0),只需要均值趋于 0,或者协方差趋于 ∞ \infty ∞,也就是说 k ′ k' k′ 序列的信噪比尽可能小。然而 k ′ k' k′ 序列是一个非负向量序列,信噪比很小的非负序列意味着序列中大部分元素都是相近的,于是这样的序列能表达的信息有限,也意味着线性 Attention 通常只能表示绝对位置的重要性(比如 Attention 矩阵即某一列都是 1),而无法很好地表达相对位置的重要性,这本质上也是线性 Attention 的低秩瓶颈的体现。
为了更形象地感知 S ( a ) S(a) S(a) 的变化规律,我们不妨假设一种最简单的情况: k ′ k' k′ 的每一个分量是独立同分布的,这时候均值向量可以简化为 μ ′ = 1 \mu' = 1 μ′=1,协方差矩阵则可以简化为 Σ ′ = σ ′ 2 I \Sigma' = \sigma'^2 I Σ′=σ′2I,那么 S ( a ) S(a) S(a) 的公式可以进一步简化为:
S ( a ) = 1 1 + σ ′ ⋅ μ ′ ⋅ ∥ q ′ ∥ 2 ∥ q ′ ∥ 1 S(a) = \frac{1}{1 + \sigma' \cdot \mu' \cdot \frac{\|q'\|^2}{\|q'\|_1}} S(a)=1+σ′⋅μ′⋅∥q′∥1∥q′∥21
从这个结果可以看出,要想线性注意力变得稀疏,一个方向是增大 σ ′ ⋅ μ ′ \sigma' \cdot \mu' σ′⋅μ′,即降低 k ′ k' k′ 序列的信噪比,另一个方向则是增大 ∥ q ′ ∥ 2 ∥ q ′ ∥ 1 \frac{\|q'\|^2}{\|q'\|_1} ∥q′∥1∥q′∥2,该因子最大值是 d − 1 2 d^{-\frac{1}{2}} d−21,其中 d 是 q,k 的维数,所以增大它意味着要增大 d,而增大了 d 意味着提高了注意力矩阵的秩的上限,缓解了低秩瓶颈。
从《Google新作试图“复活”RNN:RNN能否再次辉煌?》中,我们了解到线性RNN模型系列,它们的特点是带有一个显式的递归,这可以看成一个简单的Attention: a = ( a 1 , a 2 , ⋯ , a n − 1 , a n ) = ( λ n − 1 , λ n − 2 , ⋯ , λ , λ 1 ) a=(a_1,a_2,\cdots,a_{n-1},a_n)=(\lambda_{n-1},\lambda_{n-2},\cdots,\lambda,\lambda_1) a=(a1,a2,⋯,an−1,an)=(λn−1,λn−2,⋯,λ,λ1)。其中, λ ∈ ( 0 , 1 ] \lambda\in(0,1] λ∈(0,1]。我们可以算出:
S ( a ) = 1 − λ n n ( 1 − λ ) n − 1 + λ 1 n − 1 ( 1 − λ ) n − 1 + λ 1 n ( 1 − λ ) n − 2 + ⋯ + λ n 2 ( 1 − λ ) + λ n n S(a) = 1 - \lambda_n^n (1-\lambda)^{n-1} + \lambda_1^{n-1} (1-\lambda)^{n-1} + \lambda_1^n (1-\lambda)^{n-2} + \cdots + \lambda_n^2 (1-\lambda) + \lambda_n^n S(a)=1−λnn(1−λ)n−1+λ1n−1(1−λ)n−1+λ1n(1−λ)n−2+⋯+λn2(1−λ)+λnn
当 λ < 1 \lambda<1 λ<1 时,只要 n → ∞ n\rightarrow\infty n→∞,总有 S ( a ) → 0 S(a)\rightarrow 0 S(a)→0。所以对于带有显式Decay的线性RNN模型来说,稀疏性是不成问题的,它的问题是只能表达随着相对位置增大而衰减的、固定不变的注意力,从而无法自适应地关注到距离足够长的Context。
通过这个例子,我们可以看出线性RNN模型系列在注意力分配方面的局限性。为了更好地适应不同的任务需求,我们可以尝试结合其他注意力机制,如门控注意力等,以提高模型的表达能力。
稀疏程度指标 S(x) 是用来衡量一个随机变量或随机向量中非零元素的重要性和数量。这个指标与信息熵有关联,但它的侧重点在于度量数据的稀疏程度,即数据中非零元素的平均能量与整个数据的平均能量之比。
在 l1/l2 形式中,S(x) 被定义为:
S ( x ) = E [ ∣ x ∣ ] E [ x 2 ] S(x) = \frac{E[|x|]}{\sqrt{E[x^2]}} S(x)=E[x2]E[∣x∣]
其中 E 表示期望值。S(x) 的值越小,意味着数据 x 的稀疏程度越高。具体来说:
- ( E[|x|] ) 测量的是 x 的绝对值的期望值,这可以理解为数据中非零元素的平均绝对值。
- ( \sqrt{E[x^2]} ) 测量的是 x 的平方的期望值的平方根,这可以理解为数据中所有元素(包括零和非零)的平均能量。
因此,S(x) 能够反映数据中非零元素相对于整个数据的重要性。如果 S(x) 接近于 0,这通常意味着数据非常稀疏,大部分元素都是零,只有少数非零元素对整体能量有显著贡献。这种情况下,数据可能近似于 one-hot 分布,即大部分元素为零,只有一个元素为非零。
需要注意的是,虽然 S(x) 可以用来衡量稀疏程度,但它并不直接度量信息熵。信息熵通常用于度量一个随机变量的不确定性或信息含量,而 S(x) 更侧重于度量数据中非零元素的重要性和数量。
您所描述的简化形式是针对注意力机制中的某个指标 S(a)。首先,我们记 a=(a1,a2,⋯,an),其中 aj∝f(q⋅kj)。然后,我们考虑 n→∞ 的极限。为了简化计算,假设 k∼N(μ,σ2I),那么可以设 k=μ+σε,其中 ε∼N(0,I)。
接下来,我们利用各向同性的性质来简化计算。由于 ε 所服从的分布 N(0,I) 是一个各向同性的分布,与《n 维空间下两个随机向量的夹角分布》推导的化简思路一样,由于各向同性的原因, q⋅ε 相关的数学期望只与 q 的模长有关,跟它的方向无关。于是我们可以将 q 简化为 (‖q‖,0,0,⋯,0),那么对 ε 的数学期望就可以简化为:
S ( a ) = E ε [ ∣ f ( q ⋅ μ + σ ‖ q ‖ ε ) ∣ ] E ε [ f 2 ( q ⋅ μ + σ ‖ q ‖ ε ) ] S(a) = Eε[|f(q⋅μ+σ‖q‖ε)|]Eε[f^2(q⋅μ+σ‖q‖ε)] S(a)=Eε[∣f(q⋅μ+σ‖q‖ε)∣]Eε[f2(q⋅μ+σ‖q‖ε)]
其中 ε∼N(0,1) 是一个随机标量。这样,我们就成功地将原本复杂的计算简化为了更易于处理的随机标量计算。
您举了两个例子,分别是常见的高斯注意力(Gaussian Attention)和笔者喜欢的 GAU(Gated Attention Unit)。通过对这两种注意力机制的稀疏程度进行分析,我们可以更深入地了解它们的特点。
- 高斯注意力:对于高斯注意力,我们使用 f=exp。这种情况下,求期望只是常规的一维高斯积分。根据您给出的公式(5),我们可以得到 S(a)=exp(−12σ2∥q∥2)。当 σ→∞ 或 ∥q∥→∞ 时,都有 S(a)→0。这意味着理论上标准注意力确实可以任意稀疏地“集中注意力”。同时,这个结果也告诉了我们让注意力更集中的方法:增大 q 的模长,或者增大各个 k 之间的方差,换言之拉开 k 的差距。
- GAU(Gated Attention Unit):对于 GAU,您提到开始提出的时候是 f=relu2。这种情况下,积分没有 f=exp 那么简单。根据您给出的公式(6),我们可以得到 S ( a ) = e − β 22 γ 2 ( 2 − − √ β γ + π − − √ e β 22 γ 2 ( β 2 + γ 2 ) ( e r f ( β 2 √ γ ) + 1 ) ) π − − √ 422 − − √ β γ e − β 22 γ 2 ( β 2 + 5 γ 2 ) + 2 π − − √ ( β 4 + 6 β 2 γ 2 + 3 γ 4 ) ( e r f ( β 2 √ γ ) + 1 ) − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − √ S(a)=e−β22γ2(2−−√βγ+π−−√eβ22γ2(β2+γ2)(erf(β2√γ)+1))π−−√422−−√βγe−β22γ2(β2+5γ2)+2π−−√(β4+6β2γ2+3γ4)(erf(β2√γ)+1)−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−√ S(a)=e−β22γ2(2−−√βγ+π−−√eβ22γ2(β2+γ2)(erf(β2√γ)+1))π−−√422−−√βγe−β22γ2(β2+5γ2)+2π−−√(β4+6β2γ2+3γ4)(erf(β2√γ)+1)−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−√。从公式中可以看出,只有 β < 0 β<0 β<0 时,原版 GAU 的稀疏度才有机会趋于 0。这也说明了跟 f = e x p f=exp f=exp 的标准注意力不同,k 的 bias 项可能会对 f = r e l u 2 f=relu2 f=relu2 的 GAU 有正面帮助。
通过以上分析,我们可以看出不同注意力机制在稀疏程度方面的差异。这些差异有助于我们根据具体任务需求选择合适的注意力机制。
下面我们再来看一个最简单的例子:不加 f f f,或者等价地说 f = i d e n t i c a l f=identical f=identical。这种情况下对应的就是最简单的一种线性Attention,同样可以用Mathematica硬算得:
S ( a ) = 2 π − − √ γ e − β 22 γ 2 + β e r f ( β 2 √ γ ) β 2 + γ 2 − − − − − − √ ( 7 ) S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√(7) S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√(7)
注意,此时的S(a)是关于β偶函数(读者不妨尝试证明一下),所以β<0时图像跟它相反数的图像是一样的,因此上图只画了β≥0的结果。从图中可以看出,不加任何激活函数的线性Attention的稀疏程度并不能接近0,而是存在一个较高的下限,这意味着当输入序列足够长时,这种线性Attention并没有办法“集中注意力”到关键位置上。
您提到了一个最简单的注意力机制例子:不加 f,或者等价地说 f=identical。这种情况下对应的就是最简单的一种线性 Attention。根据您给出的公式(7),我们可以得到 S ( a ) = 2 π − − √ γ e − β 22 γ 2 + β e r f ( β 2 √ γ ) β 2 + γ 2 − − − − − − √ S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√ S(a)=2π−−√γe−β22γ2+βerf(β2√γ)β2+γ2−−−−−−√。
您还提到了 S(a) 是关于 β 的偶函数,所以 β<0 时图像跟它相反数的图像是一样的。因此,在上图中只画了 β≥0 的结果。从图中可以看出,不加任何激活函数的线性 Attention 的稀疏程度并不能接近 0,而是存在一个较高的下限。这意味着当输入序列足够长时,这种线性 Attention 并没有办法“集中注意力”到关键位置上。
通过这个例子,我们可以看出激活函数 f 在注意力机制中的重要作用。引入适当的激活函数(如 exp、relu2 等)可以帮助注意力更好地集中在关键位置上,从而提高模型的性能。这也是为什么在实际应用中,我们经常会看到各种不同的注意力机制变种,它们通过引入不同的激活函数来适应不同的任务需求。
从《线性 Attention 的探索:Attention 必须有个 Softmax 吗?》我们知道,线性 Attention 的一般形式为 (a_j \propto g(q) \cdot h(k_j)),其中 g,h 是值域非负的激活函数。我们记 (q’ = g(q)), (k’ = h(k)),那么 (a_j \propto q’ \cdot k’),并且可以写出:
S ( a ) = E [ ϵ ⋅ q ′ ⋅ k ′ ] E [ ϵ ⋅ q ′ ⋅ k ′ ⋅ k ′ ⋅ q ′ ] = q ′ ⋅ E [ ϵ ⋅ k ′ ] ⋅ q ′ q ′ ⋅ E [ ϵ ⋅ k ′ ⋅ k ′ ⋅ q ′ ] ⋅ q ′ = q ′ ⋅ μ ′ ⋅ q ′ q ′ ⋅ ( μ ′ ⋅ μ ′ T + Σ ′ ) ⋅ q ′ = 1 1 + q ′ ⋅ Σ ′ ⋅ q ′ ⋅ ( q ′ ⋅ μ ′ ) 2 S(a) = \frac{E[\epsilon \cdot q' \cdot k']}{\sqrt{E[\epsilon \cdot q' \cdot k' \cdot k' \cdot q']}} = \frac{q' \cdot E[\epsilon \cdot k'] \cdot q'}{\sqrt{q' \cdot E[\epsilon \cdot k' \cdot k' \cdot q'] \cdot q'}} = \frac{q' \cdot \mu' \cdot q'}{\sqrt{q' \cdot (\mu' \cdot \mu'^T + \Sigma') \cdot q'}} = \frac{1}{1 + q' \cdot \Sigma' \cdot q'} \cdot (q' \cdot \mu')^2 S(a)=E[ϵ⋅q′⋅k′⋅k′⋅q′]E[ϵ⋅q′⋅k′]=q′⋅E[ϵ⋅k′⋅k′⋅q′]⋅q′q′⋅E[ϵ⋅k′]⋅q′=q′⋅(μ′⋅μ′T+Σ′)⋅q′q′⋅μ′⋅q′=1+q′⋅Σ′⋅q′1⋅(q′⋅μ′)2
这是关于非负型线性 Attention 的一般结果,现在还没做任何近似,其中 (\mu’), (\Sigma’) 分别是 (k’) 序列的均值向量和协方差矩阵。
从这个结果可以看出,非负型线性 Attention 也可能任意稀疏(即 (S(a) \rightarrow 0)),只需要均值趋于 0,或者协方差趋于 (\infty),也就是说 (k’) 序列的信噪比尽可能小。然而 (k’) 序列是一个非负向量序列,信噪比很小的非负序列意味着序列中大部分元素都是相近的,于是这样的序列能表达的信息有限,也意味着线性 Attention 通常只能表示绝对位置的重要性(比如 Attention 矩阵即某一列都是 1),而无法很好地表达相对位置的重要性,这本质上也是线性 Attention 的低秩瓶颈的体现。
为了更形象地感知 (S(a)) 的变化规律,我们不妨假设一种最简单的情况:(k’) 的每一个分量是独立同分布的,这时候均值向量可以简化为 (\mu’ = 1),协方差矩阵则可以简化为 (\Sigma’ = \sigma’^2 I),那么 (S(a)) 的公式可以进一步简化为:
S ( a ) = 1 1 + σ ′ ⋅ μ ′ ⋅ ∥ q ′ ∥ 2 ∥ q ′ ∥ 1 S(a) = \frac{1}{1 + \sigma' \cdot \mu' \cdot \frac{\|q'\|^2}{\|q'\|_1}} S(a)=1+σ′⋅μ′⋅∥q′∥1∥q′∥21
从这个结果可以看出,要想线性注意力变得稀疏,一个方向是增大 (\sigma’ \cdot \mu’),即降低 (k’) 序列的信噪比,另一个方向则是增大 (\frac{|q’|^2}{|q’|_1}),该因子最大值是 (d^{-\frac{1}{2}}),其中 d 是 q,k 的维数,所以增大它意味着要增大 d,而增大了 d 意味着提高了注意力矩阵的秩的上限,缓解了低秩瓶颈。
从《Google新作试图“复活”RNN:RNN能否再次辉煌?》中,我们了解到线性RNN模型系列,它们的特点是带有一个显式的递归,这可以看成一个简单的Attention: a = ( a 1 , a 2 , ⋯ , a n − 1 , a n ) = ( λ n − 1 , λ n − 2 , ⋯ , λ , λ 1 ) a=(a_1,a_2,\cdots,a_{n-1},a_n)=(\lambda_{n-1},\lambda_{n-2},\cdots,\lambda,\lambda_1) a=(a1,a2,⋯,an−1,an)=(λn−1,λn−2,⋯,λ,λ1)。其中, λ ∈ ( 0 , 1 ] \lambda\in(0,1] λ∈(0,1]。我们可以算出:
S ( a ) = 1 − λ n n ( 1 − λ ) n − 1 + λ 1 n − 1 ( 1 − λ ) n − 1 + λ 1 n ( 1 − λ ) n − 2 + ⋯ + λ n 2 ( 1 − λ ) + λ n n S(a) = 1 - \lambda_n^n (1-\lambda)^{n-1} + \lambda_1^{n-1} (1-\lambda)^{n-1} + \lambda_1^n (1-\lambda)^{n-2} + \cdots + \lambda_n^2 (1-\lambda) + \lambda_n^n S(a)=1−λnn(1−λ)n−1+λ1n−1(1−λ)n−1+λ1n(1−λ)n−2+⋯+λn2(1−λ)+λnn
当 λ < 1 \lambda<1 λ<1 时,只要 n → ∞ n\rightarrow\infty n→∞,总有 S ( a ) → 0 S(a)\rightarrow 0 S(a)→0。所以对于带有显式Decay的线性RNN模型来说,稀疏性是不成问题的,它的问题是只能表达随着相对位置增大而衰减的、固定不变的注意力,从而无法自适应地关注到距离足够长的Context。
通过这个例子,我们可以看出线性RNN模型系列在注意力分配方面的局限性。为了更好地适应不同的任务需求,我们可以尝试结合其他注意力机制,如门控注意力等,以提高模型的表达能力。