SQL语句的执行顺序怎么理解?
我们常常会被SQL其书写顺序和执行顺序之间的差异所迷惑。理解这两者的区别,对于编写高效、可靠的SQL代码至关重要。今天,让我们用一些生动的例子和场景来深入探讨SQL的执行顺序。
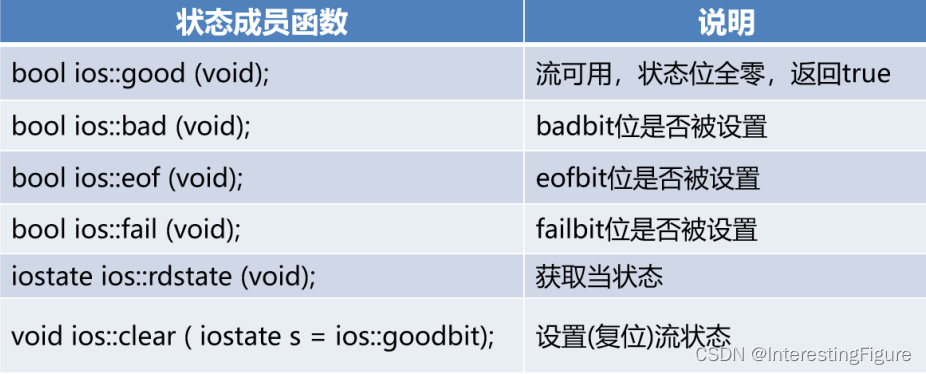
一、书写顺序 VS 执行顺序
SQL语句的书写顺序遵循的是逻辑直观性,使人能够轻易理解和组织查询的内容。然而,它的执行顺序是基于数据库查询优化器的内部机制,旨在提高查询的效率。

书写顺序
我们通常按照以下顺序编写SQL语句:
SELECTFROMJOINWHEREGROUP BYHAVINGORDER BYLIMIT
执行顺序
而其执行顺序却是这样的:
FROMONJOINWHEREGROUP BY(CUBE|ROLLUP)HAVINGSELECTDISTINCTORDER BYLIMIT
二、深入理解执行顺序
FROM 和 JOIN(笛卡尔积、筛选器、外部行)
FROM子句是查询的起点,用于确定基础表。JOIN和ON子句决定如何将这些表连接起来。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
WHERE(筛选行)
WHERE子句过滤掉不符合条件的行。
GROUP BY(分组)
GROUP BY对符合条件的行进行分组。
HAVING(分组后筛选)
HAVING子句筛选分组后的结果。
SELECT 和 DISTINCT(选择与去重)
SELECT确定最终展示的列。DISTINCT用于去除重复的行。
ORDER BY 和 LIMIT(排序和限制)
ORDER BY对结果进行排序。LIMIT限制返回的行数。
三、实际案例分析
1. 基础查询
考虑一个简单的查询:
SELECT name, age
FROM users
WHERE age > 30
ORDER BY age;
这个查询首先从users表中选择年龄大于30的记录(FROM和WHERE),然后选择name和age列(SELECT),最后按年龄排序(ORDER BY)。
2. JOIN查询
涉及JOIN的复杂查询:
SELECT u.name, u.age, o.order_id
FROM users u
JOIN orders o ON u.user_id = o.user_id
WHERE u.age > 30
ORDER BY o.order_date;
在这个例子中,我们首先确定了两个表(FROM users和JOIN orders),根据用户ID将它们连接起来(ON u.user_id = o.user_id),过滤出年龄大于30的用户(WHERE),然后选择特定的列进行展示(SELECT),最后按订单日期排序(ORDER BY)。
3. 性能优化场景
假设有一个大型的用户表和订单表,我们需要有效地查询某个年龄段的用户及其订单。正确理解执行顺序有助于我们优化这个查询,例如,首先过滤出特定年龄段的用户,然后再去JOIN订单表,这样可以显著减少JOIN的计算量。
四、ORDER BY的特殊情况
在你提出的问题中,ORDER BY按照SCORE列排序,但SELECT子句中并没有选择这一列。这是一个常见的误区。实际上,在执行ORDER BY时,数据库会考虑所有的列,即使这些列没有在SELECT子句中明确指出。因此,即使SCORE列在SELECT子句中没有出现,它仍然可以用于排序。
五、使用聚合函数
考虑这样一个查询:我们想要找出每个部门平均工资最高的前三名员工。
SELECT department_id, employee_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id, employee_id
HAVING AVG(salary) > 10000
ORDER BY department_id, avg_salary DESC
LIMIT 3;
在这个查询中,我们首先从employees表中选择数据(FROM),根据department_id和employee_id进行分组(GROUP BY),只选择平均工资超过10000的组(HAVING),然后选择部门ID、员工ID和平均工资(SELECT),按部门排序且工资降序(ORDER BY),最后选择每个部门的前三名(LIMIT)。
六、多表连接
假设我们需要查询所有顾客的订单信息,包括顾客姓名和订单细节。
SELECT c.name, o.order_details
FROM customers c
JOIN orders o ON c.id = o.customer_id
WHERE o.order_date > '2023-01-01'
ORDER BY c.name, o.order_date;
这个查询首先确定了连接customers和orders表(FROM和JOIN),根据顾客ID连接(ON),筛选出2023年1月1日之后的订单(WHERE),选择顾客姓名和订单详情(SELECT),并按顾客姓名和订单日期排序(ORDER BY)。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
七、子查询
子查询可以用于多种场合,比如在WHERE子句中筛选记录。
SELECT name, age
FROM users
WHERE id IN (SELECT user_id FROM orders WHERE order_date > '2023-01-01')
ORDER BY age;
在这个例子中,SELECT子查询首先找出2023年1月1日之后下单的用户ID,然后外层查询根据这些ID选择用户的名字和年龄(FROM和WHERE),最后按年龄排序(ORDER BY)。
八、使用CASE语句
CASE语句可以用来在查询中添加逻辑。
SELECT name,
CASE
WHEN age < 20 THEN '少年'
WHEN age BETWEEN 20 AND 60 THEN '成年'
ELSE '老年'
END AS age_group
FROM users
ORDER BY age;
这里,CASE语句根据年龄分组(在SELECT中处理),首先从users表选择数据(FROM),然后按年龄排序(ORDER BY)。
九、窗口函数
窗口函数可以用来执行复杂的数据分析任务。
SELECT name,
age,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank
FROM employees;
在此查询中,RANK()窗口函数被用来计算每个部门内员工的工资排名(在SELECT中处理),首先选择所有员工(FROM),没有指定特别的排序或限制条件。
这些SQL案例中,可以提炼出几个关键的最佳实践和技巧
1. 优化数据筛选(WHERE和JOIN)
- 有效使用WHERE子句:在连接表格前先用WHERE子句过滤掉不需要的数据,可以减少处理的数据量,从而提高查询效率。
- 明智选择JOIN类型:根据查询需求选择合适的JOIN类型(INNER JOIN, LEFT JOIN, RIGHT JOIN等),可以有效控制结果集的大小和准确性。
2. 熟练使用聚合和分组(GROUP BY和HAVING)
- 合理使用聚合函数:在GROUP BY子句中使用聚合函数(如AVG, SUM, COUNT等)可以有效地对数据进行总结和分析。
- 精确过滤分组结果:HAVING子句用于过滤分组后的结果,特别是在处理聚合数据时,它比WHERE子句更加灵活。
3. 掌握数据排序和限制(ORDER BY和LIMIT)
- 有效利用ORDER BY:正确使用ORDER BY子句可以确保结果集按照特定的顺序返回,这对于报告和用户界面显示非常重要。
- 合理应用LIMIT:LIMIT子句非常有用,尤其是在处理大数据集时,它可以限制返回的结果数量,加快查询速度并减少内存消耗。
4. 灵活应用子查询和CASE语句
- 子查询的强大功能:子查询可以在主查询之前或之内执行,使得SQL语句更加强大和灵活。
- 使用CASE语句进行条件逻辑处理:CASE语句可以在SELECT、WHERE和ORDER BY子句中使用,实现复杂的条件逻辑。
5. 理解窗口函数
- 窗口函数的应用:窗口函数(如RANK, ROW_NUMBER等)可以用于执行复杂的数据分析和处理,如排名、分区数据处理等。
6. 性能优化
- 索引的重要性:合理使用索引可以显著提高查询效率,尤其是在大数据量的表上。
- 避免不必要的复杂性:过于复杂的JOIN和子查询可能导致性能下降,应当避免不必要的复杂性。
7. 清晰易懂的代码
- 代码可读性:写出清晰、易于理解的SQL代码对于维护和团队协作非常重要。
通过运用这些技巧,你可以编写出既高效又易于理解的SQL查询,这对于处理各种数据分析和数据库操作任务至关重要。记住,良好的SQL实践不仅仅关乎代码本身,还涉及到如何在特定的数据环境中最有效地运用这些代码。
推荐一个学习 MySQL 的专栏
- 01、MySQL MariaDB 基础教程
- 02、MySQL 简介
- 03、MySQL MariaDB 安装
- 04、MySQL 管理
- 05、MySQL 日常管理
- 06、MySQL PHP 语法
- 07、MySQL 创建连接
- 08、MySQL 获取数据库列表
- 09、MySQL 创建数据库
- 10、MySQL 删除数据库
- 11、MySQL 选择数据库
- 12、MySQL 数据类型
- 13、MySQL 列出数据表
- 14、MySQL 创建数据表
- 15、MySQL 删除表
- 16、MySQL 插入数据
- 17、MySQL 获取插入数据的 ID
- 18、MySQL SELECT FROM 查询数据
- 19、MySQL WHERE 子句有条件的查询数据
- 20、MySQL UPDATE 更新数据
- 21、MySQL DELETE FROM 语句删除数据
- 22、MySQL 返回删改查受影响的行数
- 23、MySQL LIKE 子句模糊查询数据
- 24、MySQL UNION 操作符查询多张表
- 25、MySQL ORDER BY 排序
- 26、MySQL GROUP BY 分组查询数据
- 27、MySQL JOIN 进行多表查询
- 28、MySQL NULL 值处理
- 29、MySQL REGEXP 子句正则表达式查询
- 30、MySQL 数据库事务
- 31、MySQL ALTER 命令
- 32、MySQL 索引
- 33、CREATE TEMPORARY TABLE 创建临时表
- 34、MySQL DROP TABLE 删除临时表
- 35、MySQL INSERT INTO SELECT 复制表
- 36、MySQL 获取服务器元数据
- 37、MySQL 自增序列 AUTO_INCREMENT
- 38、MySQL 处理重复数据
- 39、MySQL 安全及防止 SQL 注入攻击
- 40、MySQL 导出数据
- 41、MySQL 导入数据
总结
理解SQL的执行顺序不仅能帮助我们写出更有效的查询,还能让我们更好地理解数据库是如何处理我们的请求的。通过实际案例的分析和理解,我们可以更好地掌握SQL查询的艺术。记住,每一条SQL语句都像是一次小小的旅行,从FROM出发,经过一系列的处理,最终到达SELECT的归宿。
在SQL的世界里,旅途的顺序和规划同样重要,它决定了查询的效率和准确性。我们要做的,就是成为这个旅程的优秀规划师。
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
项目文档&视频:
本文,已收录于,我的技术网站 ddkk.com,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!@架构师专栏