笔记来源于:
https://www.youtube.com/watch?v=phQK8xZpgoU&t=172s
https://www.youtube.com/watch?v=XLyPFnephpY&t=645s
Machine/Deep Learning
机器学习概况来说,让机器具备自动找函式的能力 (Machine Learning 约等于 Looking for function)
三种机器学习: 回归,分类,生成式学习
函数输出来进行分类
1、 回归: 韩式的输出是一个数值
例子:预测明天的PM2.5值
2、分类:函式的输出是一个类别(选择题)
例子:email过滤垃圾邮件,让机器做一个选择题
输入是邮件,输出是垃圾邮件/不是垃圾邮件
机器学习有一个更困难的问题: 结构化学习(Structured Learning),让机器生成有结构的物件,例如影像,文字,又叫生成式学习(Generative Learning)
结构化学习,生成式学习是一门很难的技术,不知道什么时候才能达到生成式学习
不知道什么时候才能到达暗黑大陆
ChatGPT是哪一类呢?
chatgpt实际做的事情: 文字接龙,模型解的是分类的问题
使用者感受到的功能: 一个字一个字生成,可能感受到的是生成式学习
实际上,chatgpt要解的是生成式学习这个问题做下简化,拆解成多个分类问题
生成式学习有很多个策略,有哪些?
机器学习就是让机器找一个函式,那机器怎么找?

归纳成三个步骤,比较好理解
前置作业: 决定要找什么样的函式,这个和技术无关,取决于你要做什么样的应用
例子: 宝可梦,提升战斗力,或者判断是否是宝可梦
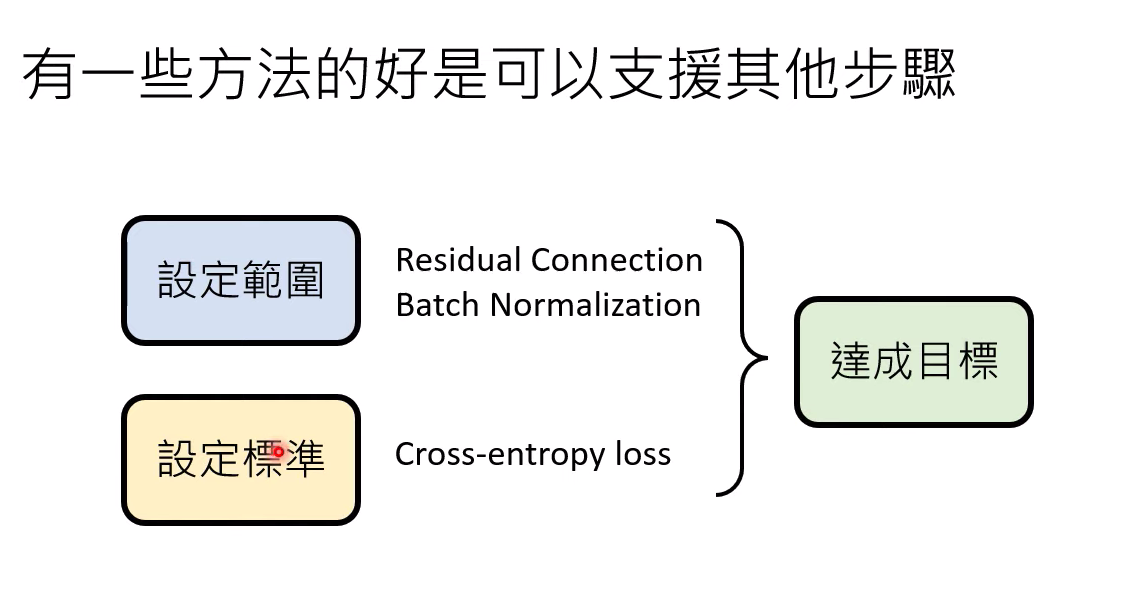
1、 设定范围
找出候选函数的集合,就是model
深度学习中,类神经网络的结构,例如CNN,RNN,Transformer等,指的就是不同的函式集合
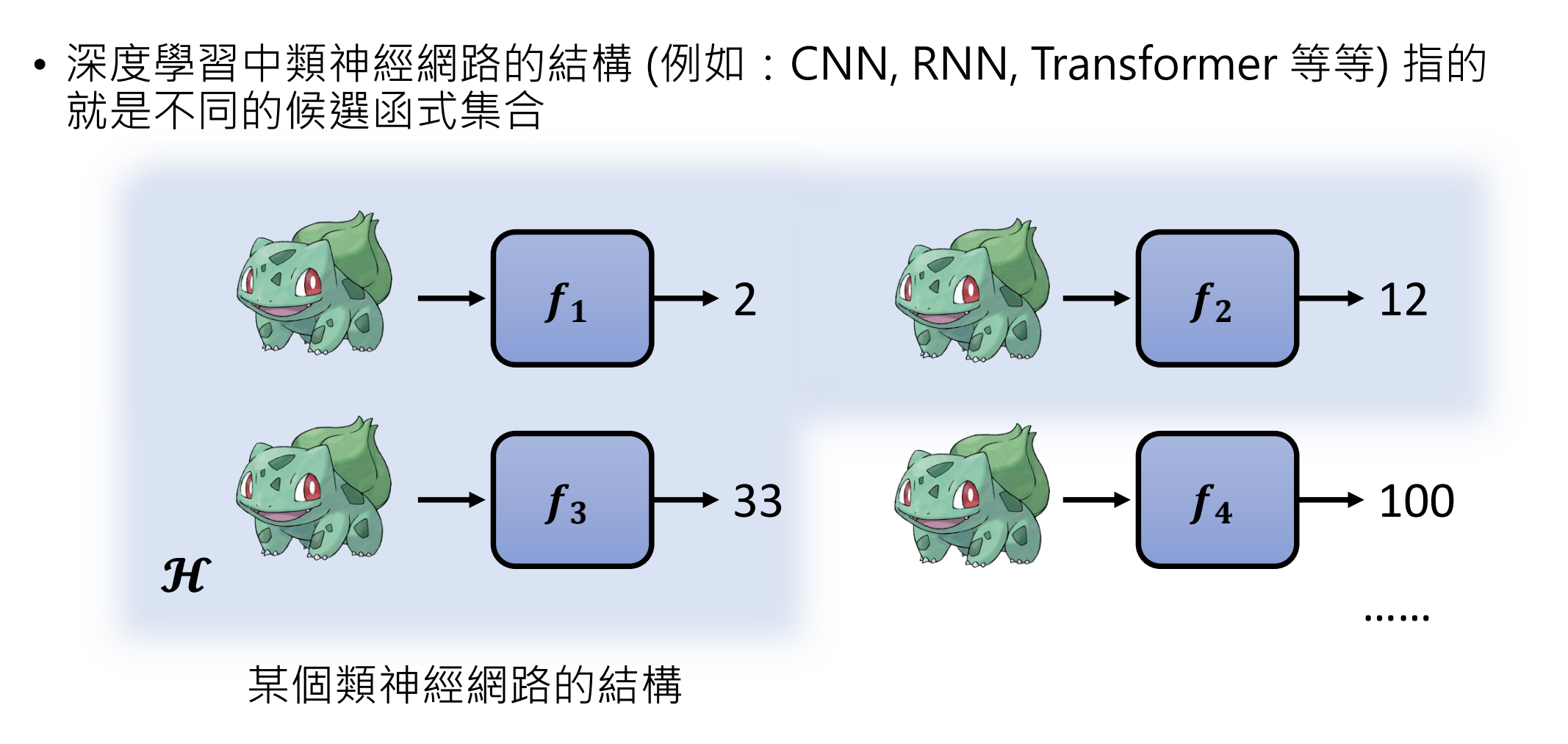
为什么类神经网络的结构就是一个候选函式的集合?
视频解析: https://www.youtube.com/watch?v=Dr-WRlEFefw
参考资料:https://ruanyifeng.com/blog/2017/07/neural-network.html
近年来,计算机视觉慢慢由CNN转向transform的趋势

step1: 这个function其实就是一个Neural network
我们把一个Logistic Regression 称之为Neuron,整个称之为Neural Network。 也就是一个Neural network里面包含一大堆的Logistic Regression
每个Logistic Regression,它都有自己的weight和自己的bias,这些weight和bias集合起来,就是这个network的parameter

如何去连接不同的Neuron network? Full Connect Feedforward Network
通过不同的连接方式,就得到了不同的structure
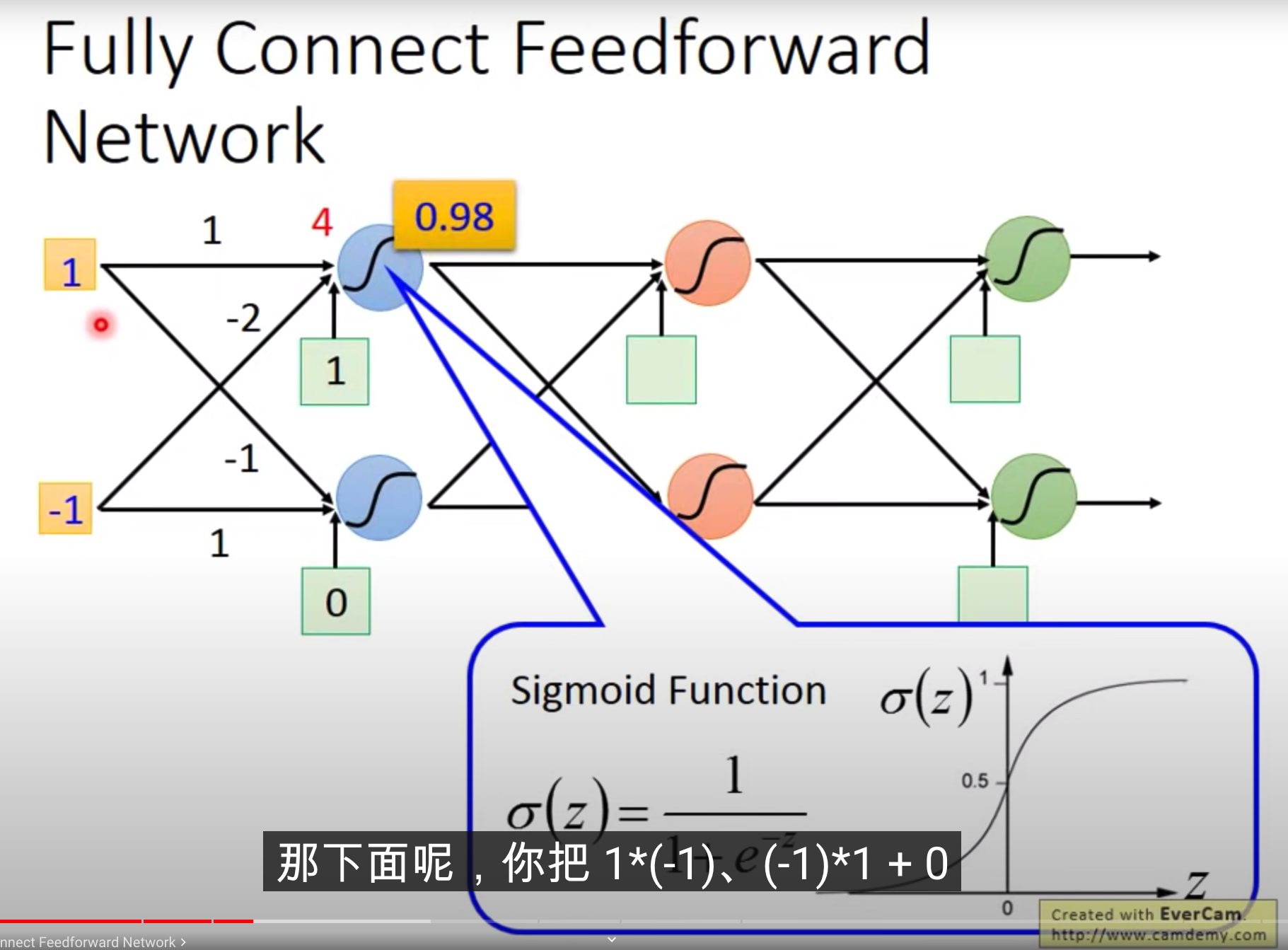
1*1+(-1)*(-2)再加上bias 1,通过sigmoid function以后,计算得到值

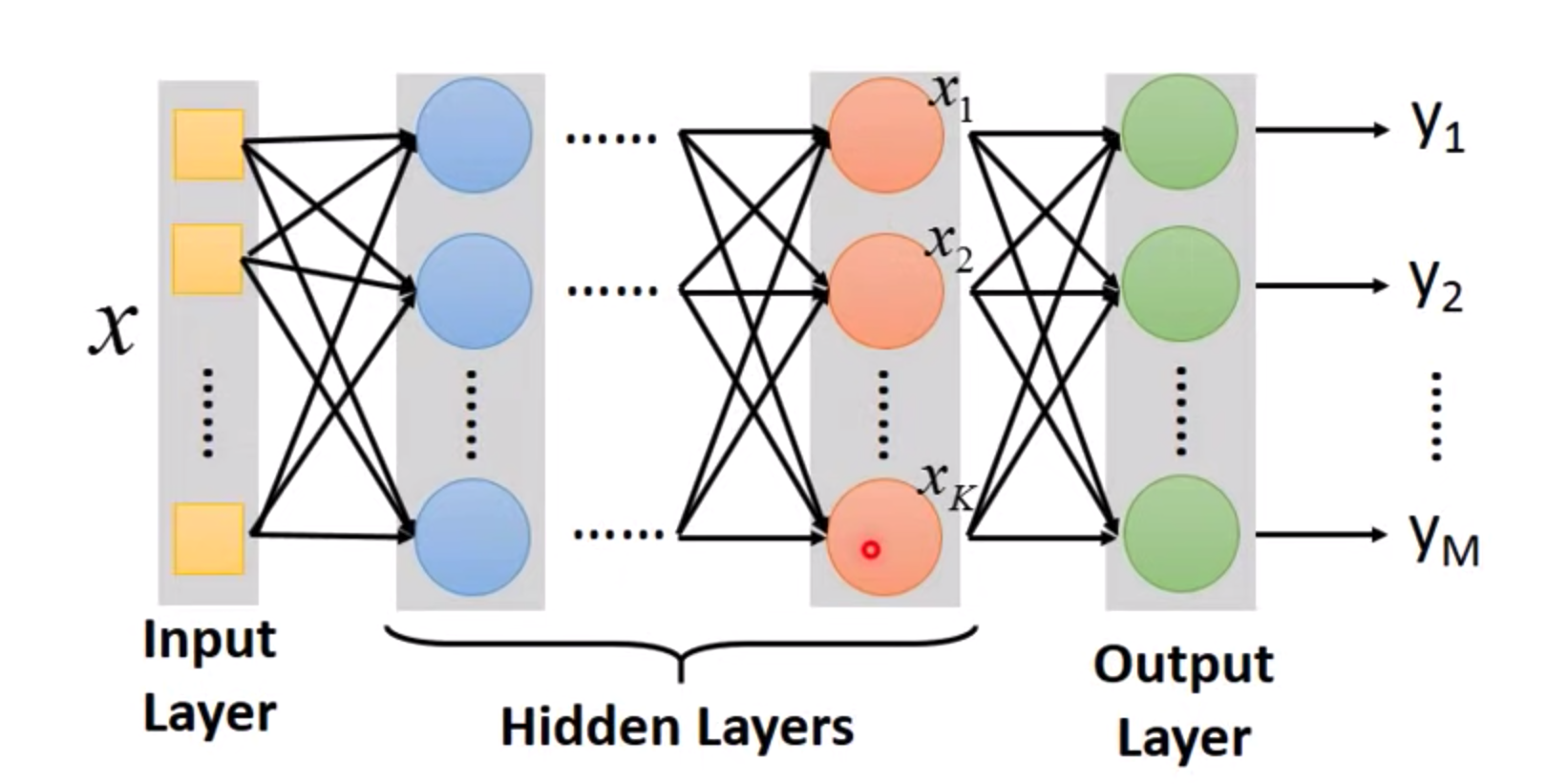
一个neural network你可以把它看作是一个function,input是一个vector,output也是一个vector
如果不知道参数 weight和bias,只是定出了这个network的structure,只是定义好了这个network怎么样连接,
它其实就是定义了一个function set,我们可以给这个network设定不同的参数,它就变成了不同的function,把这些可能的function集合起来
我们就得到了一个function set

为什么我们要设定范围? 为什么我们要选出候选函式的范围? 为什么不把所有的函式纳入进来?
1、标准训练数据下,loss小,但是测试不好,例如是硬记答案,我们要找在各个环境都表现很好的函式。。。
2、 过滤掉不行的函式,所以一开始划定范围,不在这个范围的直接淘汰,这个范围也很有讲究。。。
3、这个范围选择有标准的数学理论支撑,参见视频:
卷积神经网络:https://www.youtube.com/watch?v=OP5HcXJg2Aw
浅谈机器学习原理:https://www.youtube.com/watch?v=_j9MVVcvyZI

2、 设定标准
设定一个评估函式好坏的标准
怎么设定一个最好的标准,loss越小,代表函数最好,loss越大,代表不好
这个loss设定怎么来呢? 自己来设置
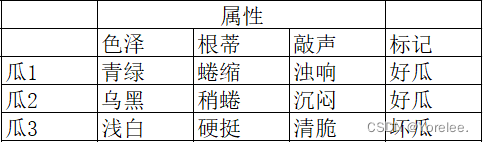
例子:宝可梦,战斗力
专业人士设置标准答案,根据函式的输出和标准答案的差距,所有的差距加起来代表函式的好坏

L(f1)=15 入参为函式,大L也是一个函式,用来计算函式的好坏
怎么样来定义这个loss function?
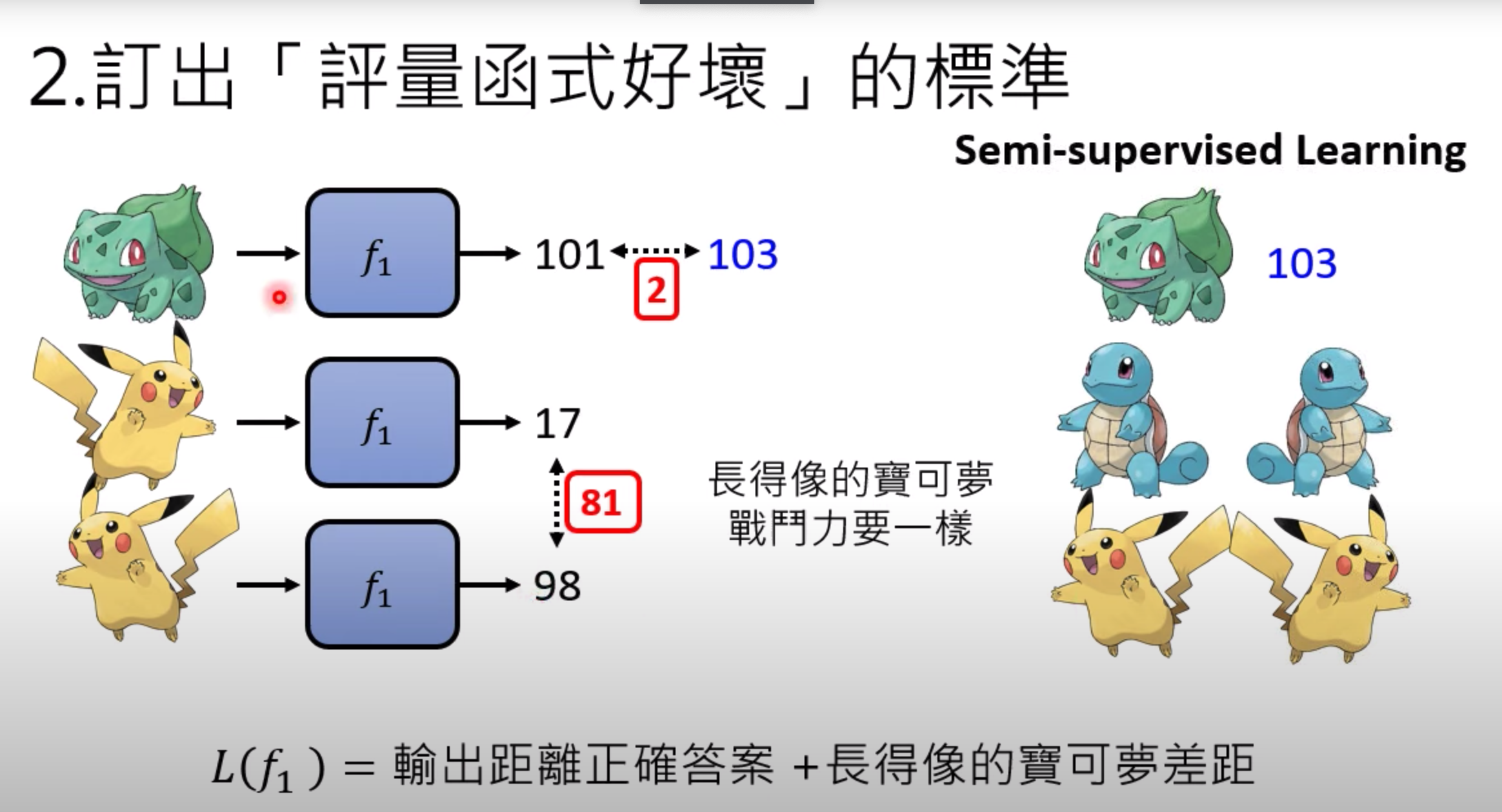
假设有另外的情况,有部分的数据有标准答案,路边抓过来一些宝可梦,那怎么来评估战斗力?这种情况下
怎么来评估这些没有正确标注的宝可梦的战斗力?
第一步,把宝可梦丢到这个函式里面,如果有返回,则使用
没有的话,我们可以定一些假设,长得像宝可梦的战斗力要一样
(那怎么定义长得像呢? 比如像素的相似度 这个你自己来根据资料来灵活定义)
一个好的函式,可以评估出没有标注过的数据
问题: 在训练数据上面评估的loss函数小,但是在训练数据上面不一定好
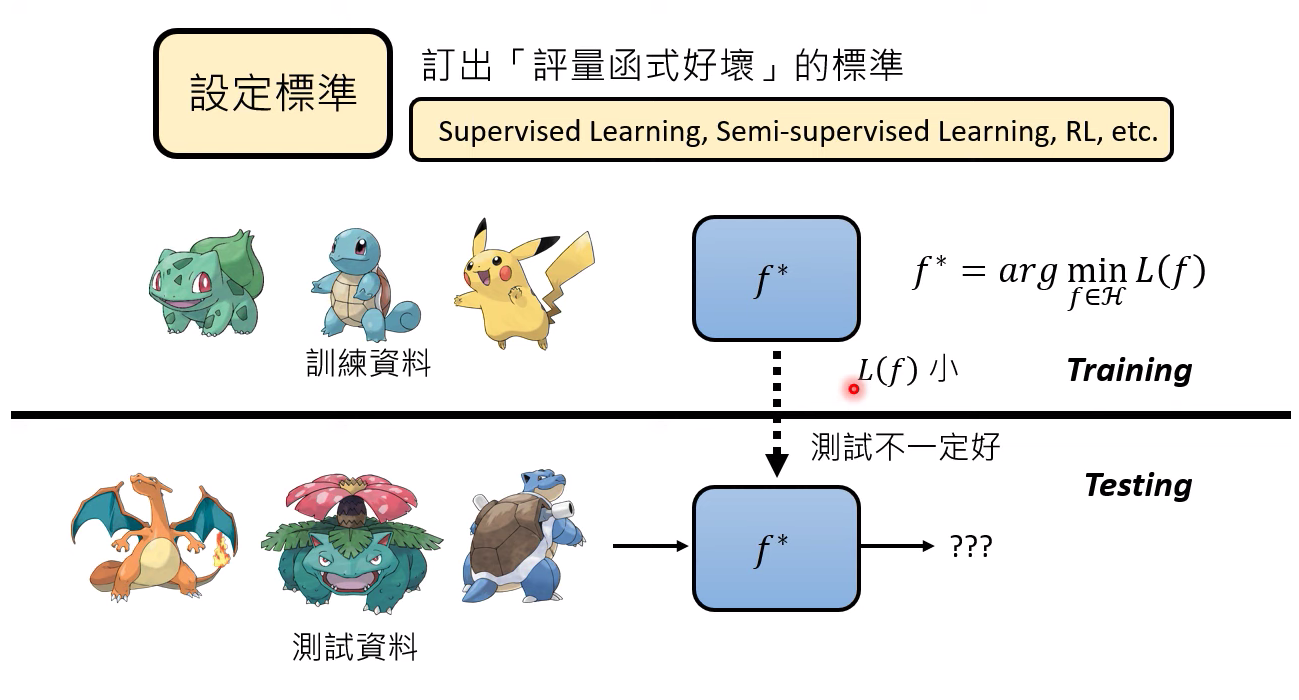
可能的原因是什么呢?
1、 数据量太小
2、有很多其他的理论知识。。。。
怎么解决?
我们在Loss上做一些额外的考量,如Regularization,具体做法原理视频没讲。。。。。。。
3、 达成目标
找出最好的函式,什么叫做好呢? 就是上面的loss,loss越小,函式越好
这个找出函式最佳的方式叫做Optimization

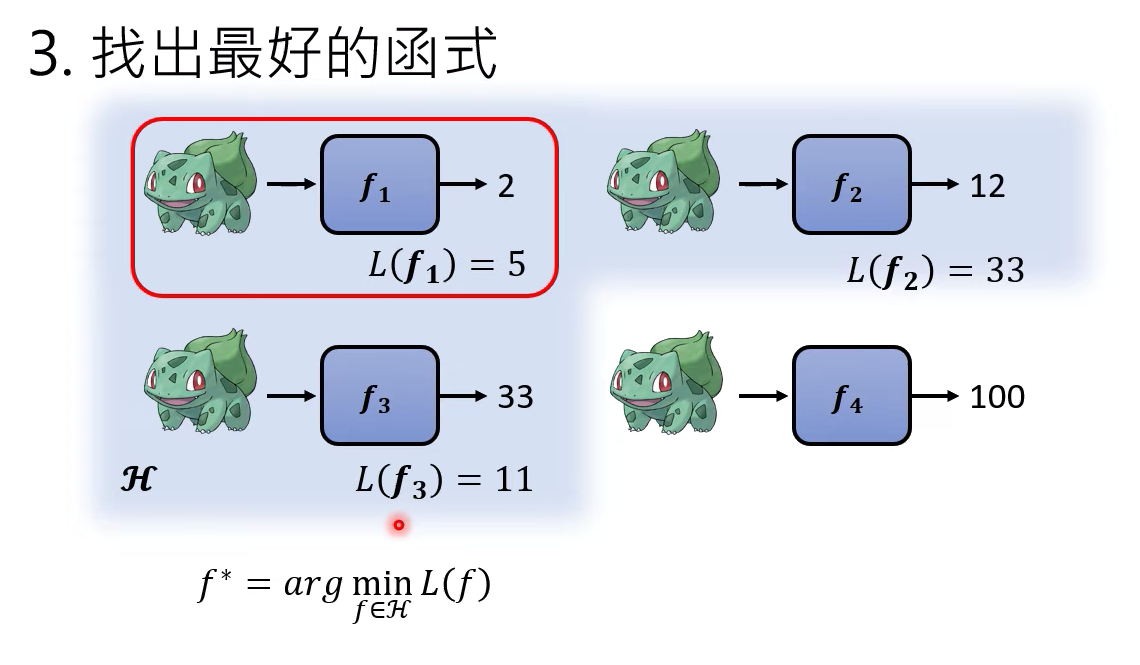
如何进一步去找最好评估的loss函式,可以学习下这几个视频。。。我没来的及学习

最佳化演算法
什么是达成目标比较好的方式?
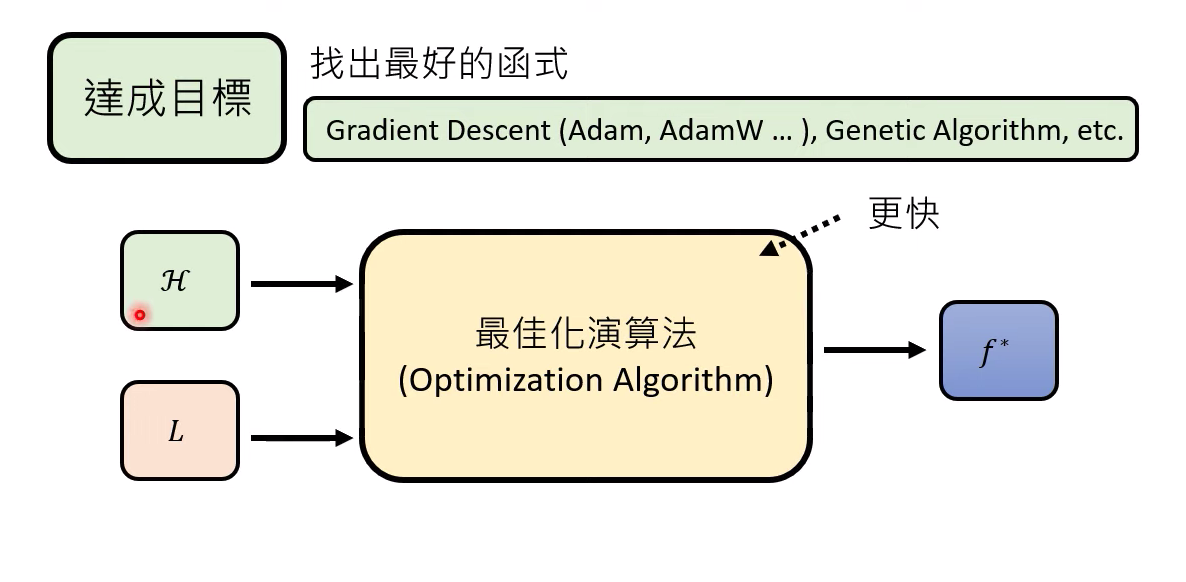
把最佳化演算法看作一个巨大的funciton,输入是定义好的函式集合 H和评估函式好坏的标准L,
输出一个最好的函式,这个函式在大L里面的值越小越好
怎么评估这个function的好坏?
1、 我们期待这个function能够在同样输入H和L的前提下,越快输出越好
2、有时候需要L(f*)越小越好,但是通常找不出大L最低的function(不清楚为啥。。。。),但是我们期待最佳化演算法找出来的L(f*) 越低越好
我们需要先设定 Learning Rate,Batch Size,How to Init,这些就叫做超参数,纯手工去调(技术活)
参数狗。。。 不是类神经网络里面的参数

一个好的最佳化演算法,我们期待最佳化演算法对于超参数不敏感。。。。这样就可以用预设值了
--------------------------------------------------------------------------------------------------------------------------------