源代码: Lib/bisect.py
本模块提供对维护一个已排序列表而无须在每次插入后对该列表重排序的支持。 对于具有大量条目需要大量比较运算的长列表,这改进了原来的线性搜索或频繁重排序。
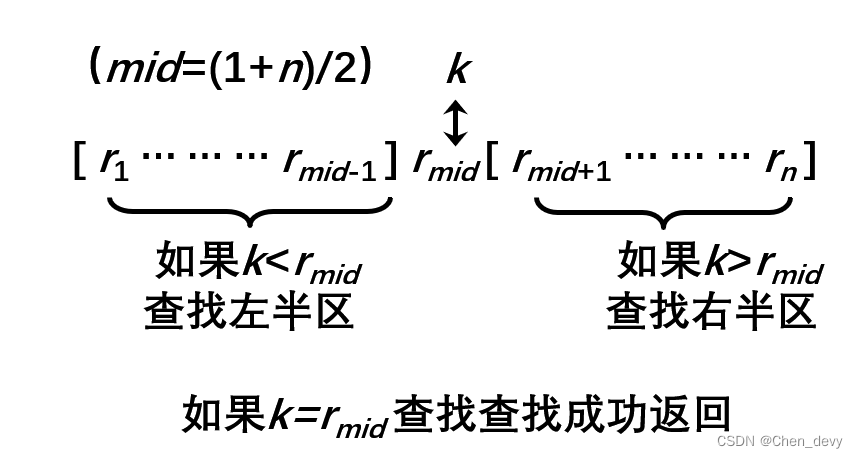
本模块被命名为 bisect 是因为它使用了基本的二分算法。 不同于其他搜索特定值的二分算法工具,本模块中的函数被设计为定位插入点。 相应的,这些函数绝不会调用 __eq__() 方法来确定是否找到特定值。 相反,这些函数只会调用 __lt__() 方法并将返回一个数组的值之间的插入点。
定义了以下函数:
bisect.bisect_left(a, x, lo=0, hi=len(a), *, key=None)
在 a 中找到 x 合适的插入点以维持有序。参数 lo 和 hi 可以被用于确定需要考虑的子集;默认情况下整个列表都会被使用。如果 x 已经在 a 里存在,那么插入点会在已存在元素之前(也就是左边)。如果 a 是列表(list)的话,返回值是可以被放在 list.insert() 的第一个参数的。
返回的插入点 ip 将数组 a 分为两个切片使得对于左侧切片 all(elem < x for elem in a[lo : ip]) 为真值而对于右侧切片 all(elem >= x for elem in a[ip : hi]) 为真值。
key 指定带有单个参数的 key function 用来从数组的每个元素中提取比较键。 为了支持搜索复杂记录,键函数不会被应用到 x 值。
如果 key 为 None,则将直接比较元素而不调用任何键函数。
在 3.10 版更改: 增加了 key 形参。
bisect.bisect_right(a, x, lo=0, hi=len(a), *, key=None)
bisect.bisect(a, x, lo=0, hi=len(a), *, key=None)
类似于 bisect_left(),但是返回的插入点是在 a 中任何现有条目 x 之后(即其右侧)。
返回的插入点 ip 将数组 a 分为两个切片使得对于左侧切片 all(elem <= x for elem in a[lo : ip]) 为真值而对于右则切片 all(elem > x for elem in a[ip : hi]) 为真值。
在 3.10 版更改: 增加了 key 形参。
bisect.insort_left(a, x, lo=0, hi=len(a), *, key=None)
按照已排序顺序将 x 插入到 a 中。
此函数首先会运行 bisect_left() 来定位一个插入点。 然后,它会在 a 上运行 insert() 方法在适当的位置插入 x 以保持排序顺序。
为了支持将记录插入到表中,key 函数(如果存在)将被应用到 x 用于搜索步骤但不会用于插入步骤。
请记住 O(log n) 搜索是由缓慢的 O(n) 抛入步骤主导的。
在 3.10 版更改: 增加了 key 形参。
bisect.insort_right(a, x, lo=0, hi=len(a), *, key=None)
bisect.insort(a, x, lo=0, hi=len(a), *, key=None)
类似于 insort_left(),但是会把 x 插入到 a 中任何现有条目 x 之后。
此函数首先会运行 bisect_right() 来定位一个插入点。 然后,它会在 a 上运行 insert() 方法在适当的位置插入 x 以保持排序顺序。
为了支持将记录插入到表中,key 函数(如果存在)将被应用到 x 用于搜索步骤但不会用于插入步骤。
请记住 O(log n) 搜索是由缓慢的 O(n) 抛入步骤主导的。
在 3.10 版更改: 增加了 key 形参。
性能说明
当使用 bisect() 和 insort() 编写时间敏感的代码时,请记住以下概念。
二分法对于搜索一定范围的值是很高效的。 对于定位特定的值,则字典的性能更好。
insort() 函数的时间复杂度为
O(n)因为对数时间的搜索步骤被线性时间的插入步骤所主导。这些搜索函数都是无状态的并且会在它们被使用后丢弃键函数的结果。 因此,如果在一个循环中使用搜索函数,则键函数可能会在同一个数据元素上被反复调用。 如果键函数速度不够快,请考虑用 functools.cache() 来包装它以避免重复计算。 另外,也可以考虑搜索一个预先计算好的键数组来定位插入点(如下面的示例小节所演示的)。
参见
Sorted Collections 是一个使用 bisect 来管理数据的已排序多项集的高性能模块。
SortedCollection recipe 使用 bisect 构建了一个功能完整的多项集类,拥有直观的搜索方法和对键函数的支持。 所有键函数都 是预先计算好的以避免在搜索期间对键函数的不必要的调用。
搜索有序列表
上面的 bisect functions 对于找到插入点是有用的,但在一般的搜索任务中可能会有点尴尬。 下面的五个函数展示了如何将其转换为针对有序列表的标准查找函数:
def index(a, x):
'Locate the leftmost value exactly equal to x'
i = bisect_left(a, x)
if i != len(a) and a[i] == x:
return i
raise ValueError
def find_lt(a, x):
'Find rightmost value less than x'
i = bisect_left(a, x)
if i:
return a[i-1]
raise ValueError
def find_le(a, x):
'Find rightmost value less than or equal to x'
i = bisect_right(a, x)
if i:
return a[i-1]
raise ValueError
def find_gt(a, x):
'Find leftmost value greater than x'
i = bisect_right(a, x)
if i != len(a):
return a[i]
raise ValueError
def find_ge(a, x):
'Find leftmost item greater than or equal to x'
i = bisect_left(a, x)
if i != len(a):
return a[i]
raise ValueError
例子
bisect() 函数对于数字表查询也是适用的。 这个例子使用 bisect() 根据一组有序的数字划分点来查找考试成绩对应的字母等级: (如) 90 及以上为 'A',80 至 89 为 'B',依此类推:
>>>
>>> def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'): ... i = bisect(breakpoints, score) ... return grades[i] ... >>> [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]] ['F', 'A', 'C', 'C', 'B', 'A', 'A']
bisect() 和 insort() 对于列表和元组也是适用的。 key 参数可以提取用于表中记录排序的字段:
>>>
>>> from collections import namedtuple
>>> from operator import attrgetter
>>> from bisect import bisect, insort
>>> from pprint import pprint
>>> Movie = namedtuple('Movie', ('name', 'released', 'director'))
>>> movies = [
... Movie('Jaws', 1975, 'Spielberg'),
... Movie('Titanic', 1997, 'Cameron'),
... Movie('The Birds', 1963, 'Hitchcock'),
... Movie('Aliens', 1986, 'Cameron')
... ]
>>> # Find the first movie released after 1960
>>> by_year = attrgetter('released')
>>> movies.sort(key=by_year)
>>> movies[bisect(movies, 1960, key=by_year)]
Movie(name='The Birds', released=1963, director='Hitchcock')
>>> # Insert a movie while maintaining sort order
>>> romance = Movie('Love Story', 1970, 'Hiller')
>>> insort(movies, romance, key=by_year)
>>> pprint(movies)
[Movie(name='The Birds', released=1963, director='Hitchcock'),
Movie(name='Love Story', released=1970, director='Hiller'),
Movie(name='Jaws', released=1975, director='Spielberg'),
Movie(name='Aliens', released=1986, director='Cameron'),
Movie(name='Titanic', released=1997, director='Cameron')]
如果键函数较为消耗资源,可以通过搜索一个预先计算的键列表来查找记录的索引以避免重复的函数调用:
>>>
>>> data = [('red', 5), ('blue', 1), ('yellow', 8), ('black', 0)]
>>> data.sort(key=lambda r: r[1]) # Or use operator.itemgetter(1).
>>> keys = [r[1] for r in data] # Precompute a list of keys.
>>> data[bisect_left(keys, 0)]
('black', 0)
>>> data[bisect_left(keys, 1)]
('blue', 1)
>>> data[bisect_left(keys, 5)]
('red', 5)
>>> data[bisect_left(keys, 8)]
('yellow', 8)





















![[ 蓝桥杯Web真题 ]-布局切换](https://img-blog.csdnimg.cn/img_convert/afcab4336107b62c57eac3f8349bed93.jpeg)