目录
python3 dirsearch.py -h 查看工具使用帮助
python dirsearch.py -u https://www.google.com/ --proxy http://127.0.0.1:7890
python3 dirsearch.py -u http://example.com -t 10
python3 dirsearch.py -u http://example.com -r
python3 dirsearch.py -l url.txt
简介
Dirsearch是一个基于python的命令行工具,主要用于扫描Web服务器目录结构,查找潜在的敏感或隐藏的文件和目录。也就是我们常说的目录爆破工具。
特性
- 快速扫描:dirsearch 允许用户快速扫描Web服务器上的目录结构,以查找潜在的敏感或隐藏的文件和目录。
- 多线程支持: 支持多线程,使其能够更高效地处理大量请求。
- 自定义字典: 用户可以使用自定义字典文件,以便根据他们的需要定制扫描。
- 多种选项: 提供多种选项,包括指定目标URL、设置文件扩展名、配置代理、设置超时等。
- 颜色化输出: 输出结果使用彩色标记,使用户更容易识别发现的目录和文件。
- HTTP代理支持: 允许配置代理,以便在需要时通过代理进行扫描。
- 报告生成: 生成扫描结果的报告,以便更方便地查看和分析。
- GitHub项目: 作为一个开源项目,你可以在 GitHub 上找到其源代码,并参与到项目的发展中。
安装
前提:需要保证已经有了python,如果没有python的话,需要先下载个python,并且配置一下环境变量。建议直接去kali里面安装,安装完就可以直接使用,不用配置什么东西,很方便。主要记录工具的使用
由于我的物理机和kali中都已经有了Dirsearch,这里就在服务器上装一下。
如果在kali中去克隆dirsearch.git的话,不要开vpn,不然会连不上。
git clone https://github.com/maurosoria/dirsearch.git

然后安装依赖项,安装完即可使用
cd dirsearch
pip install -r requirements.txt
这里指定python3去执行这个脚本,在GitHub上可以看到该工具要求的python版本,那么如果是Windows使用该工具的话,注意不要使用python2去运行该脚本。
使用
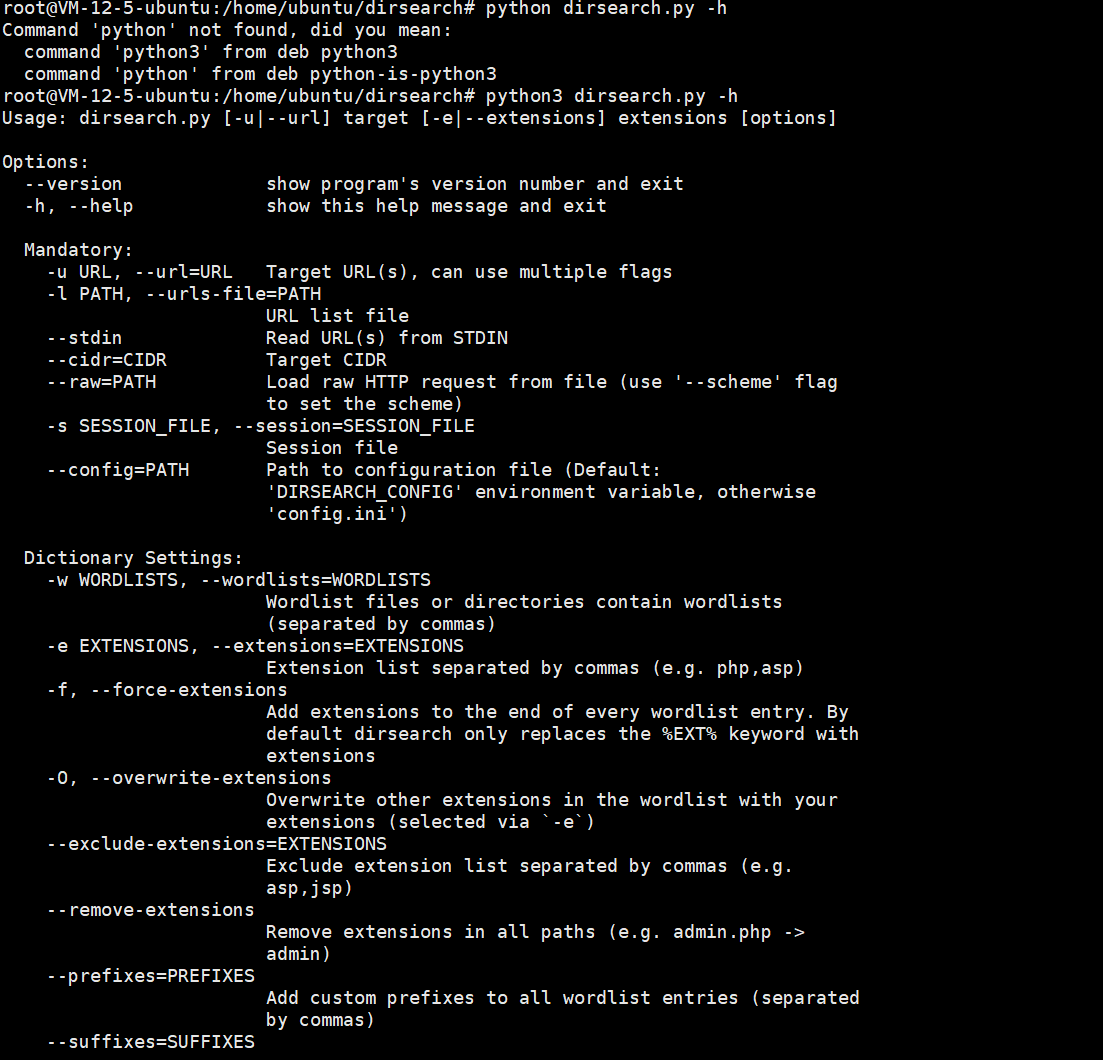
python3 dirsearch.py -h 查看工具使用帮助
常用命令
python3 dirsearch.py -u URL
对指定的目标URL执行默认扫描
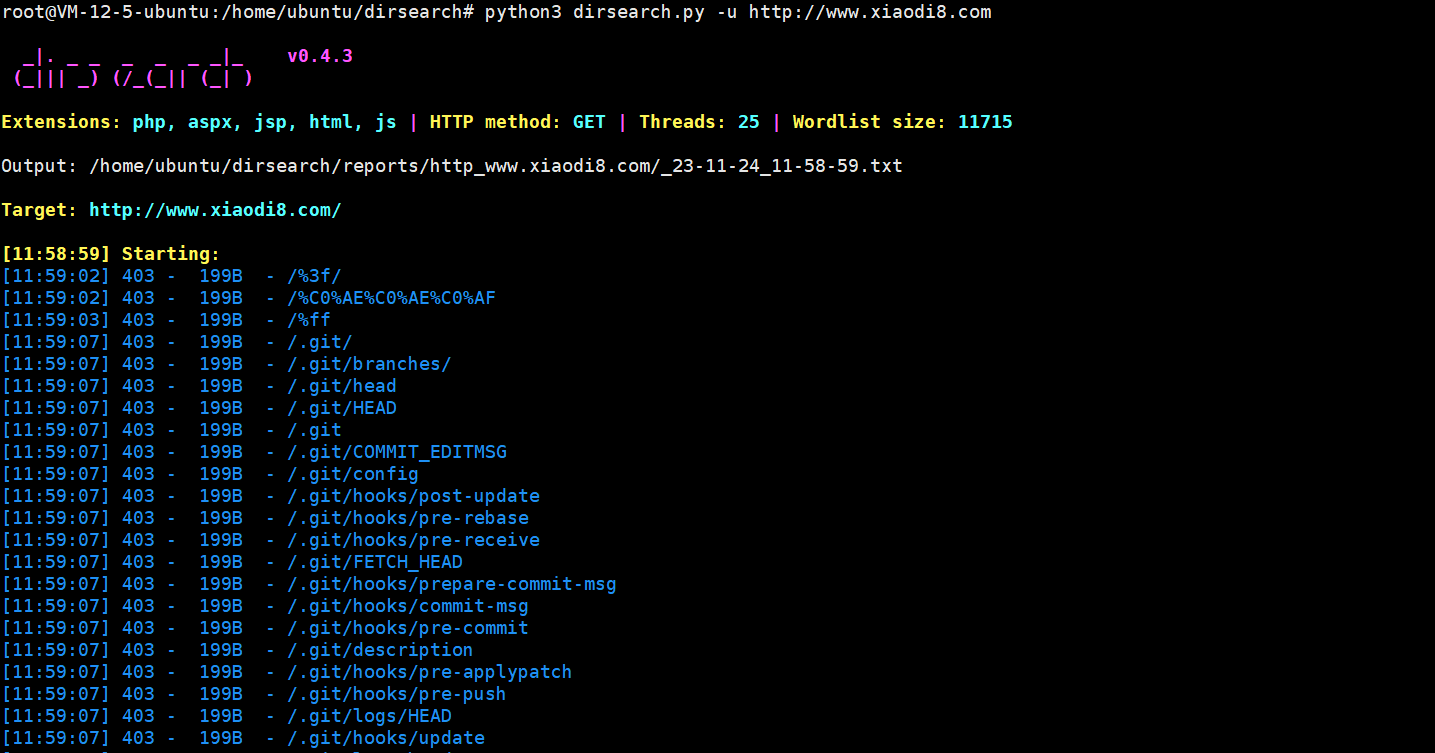
状态码200的会绿色标注
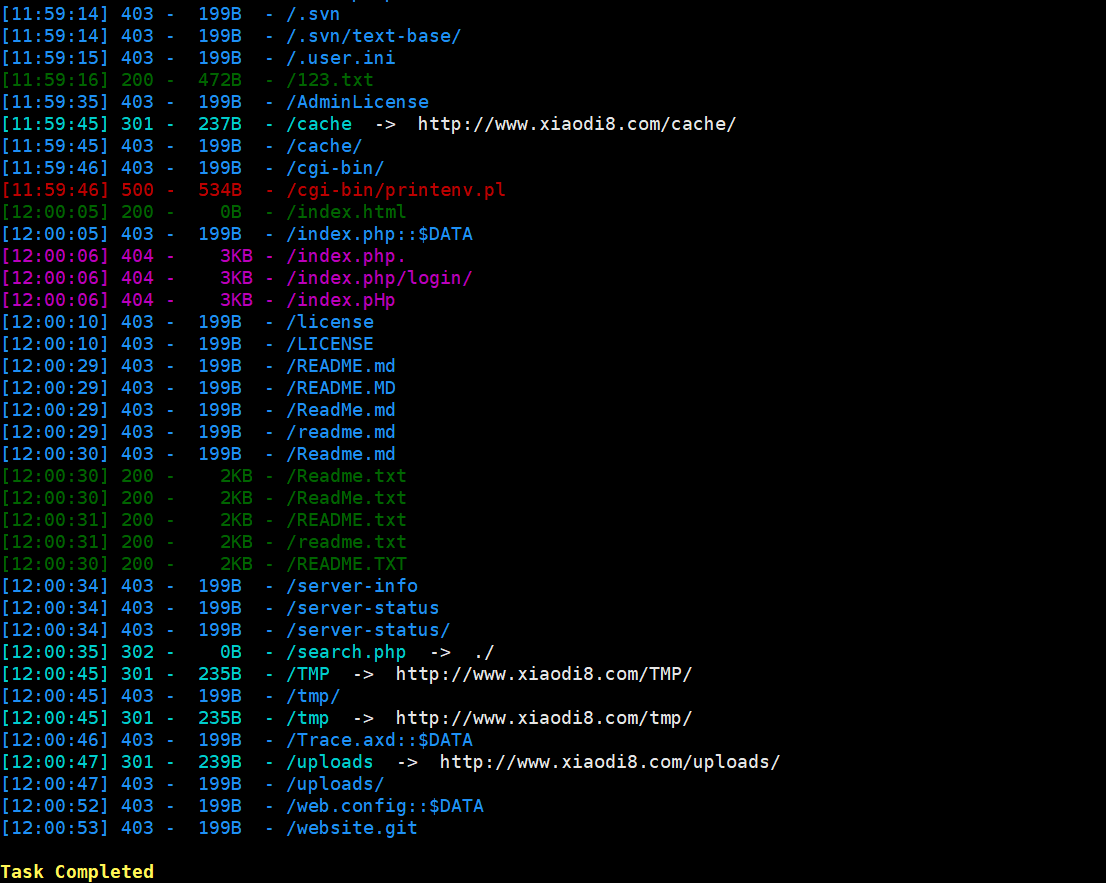
扫描完成后会自动创建reports目录,并将扫描结果保存到该目录

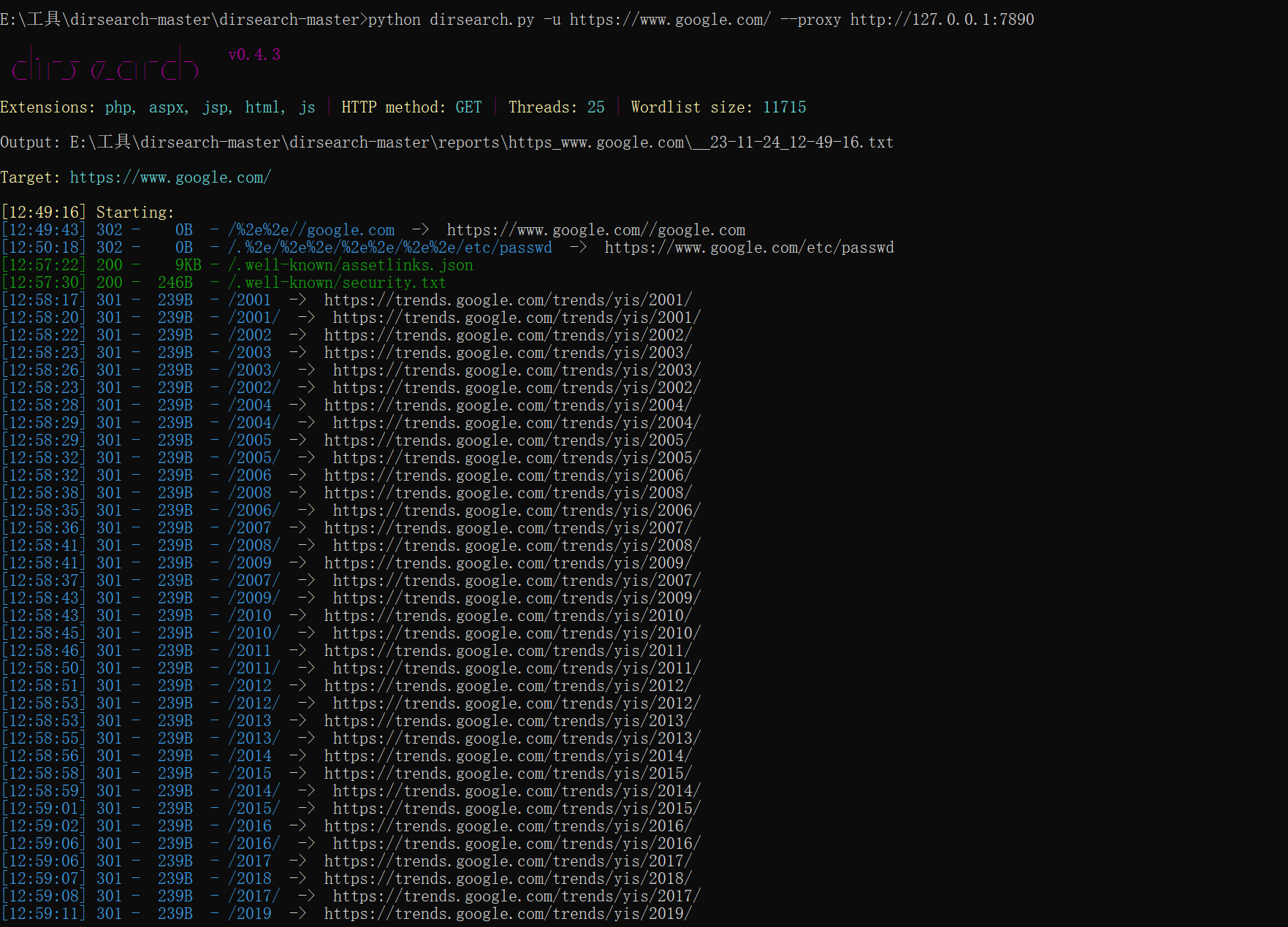
python dirsearch.py -u https://www.google.com/ --proxy http://127.0.0.1:7890
使用--proxy 代理地址,可以使用代理去扫描,这里科学上网扫了一下Google,但是科学上网嘛,额。。。。。懂得都懂。
(这里用我的本机扫一下Google,因为我本机环境变量配置过了,python就是python3)
python3 dirsearch.py -u http://www.xiaodi8.com -e txt -w db/dicc.txt
-e参数代表指定扫描的文件扩展名,比如这里指定txt,但是好像没啥没啥用。指定txt,但还是有其他的扩展名输出。正常建议不加这个参数。
-w参数指定自定义字典。这里指定dirsearch它自己的字典,位于db目录下的dicc.txt。
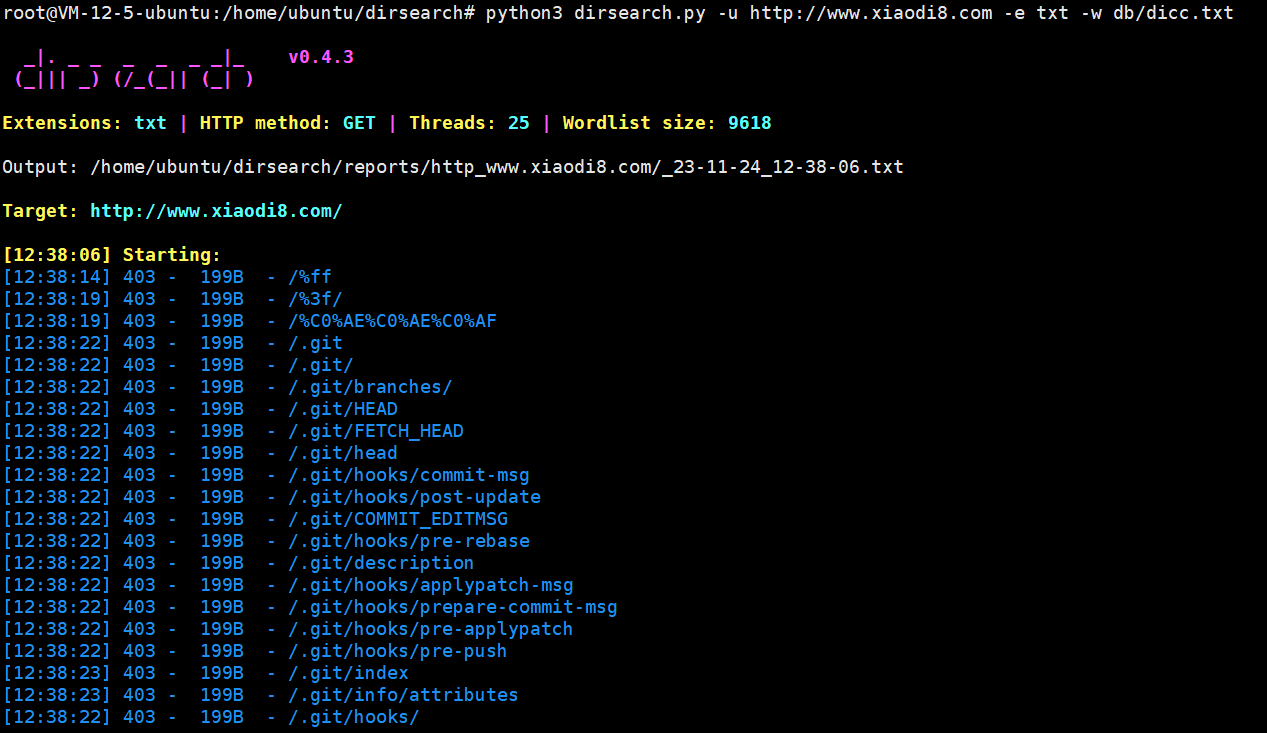
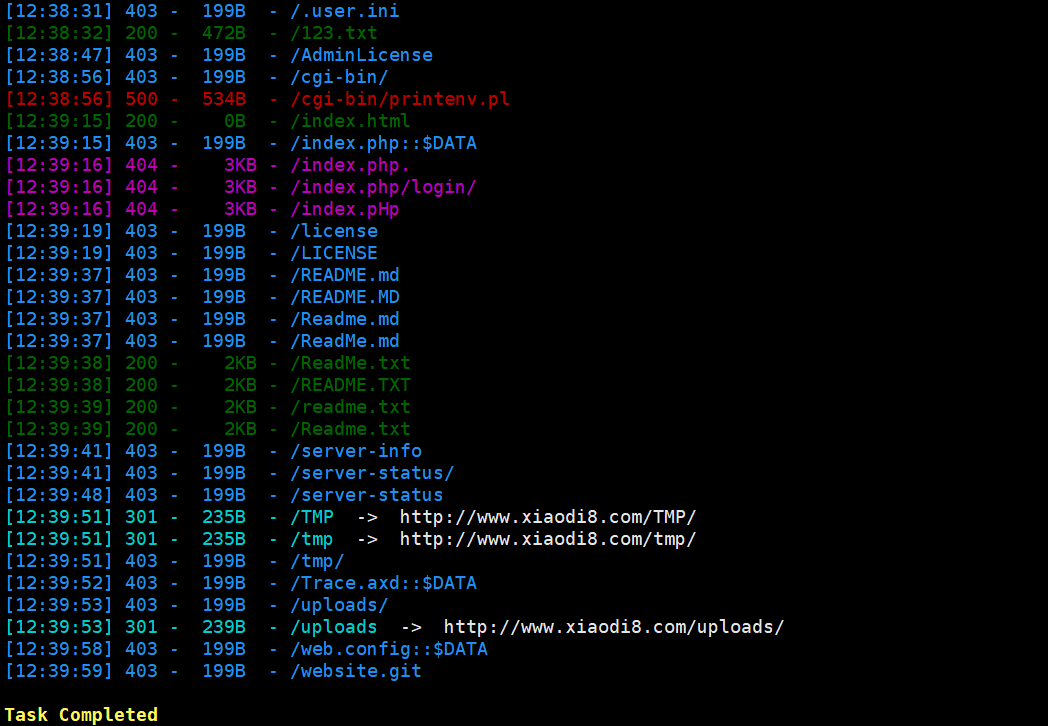
这里可以看到指定扩展名和不指定好像没啥区别,实际使用不用-e也没啥
python3 dirsearch.py -u http://example.com -t 10
-t参数可以设置线程数
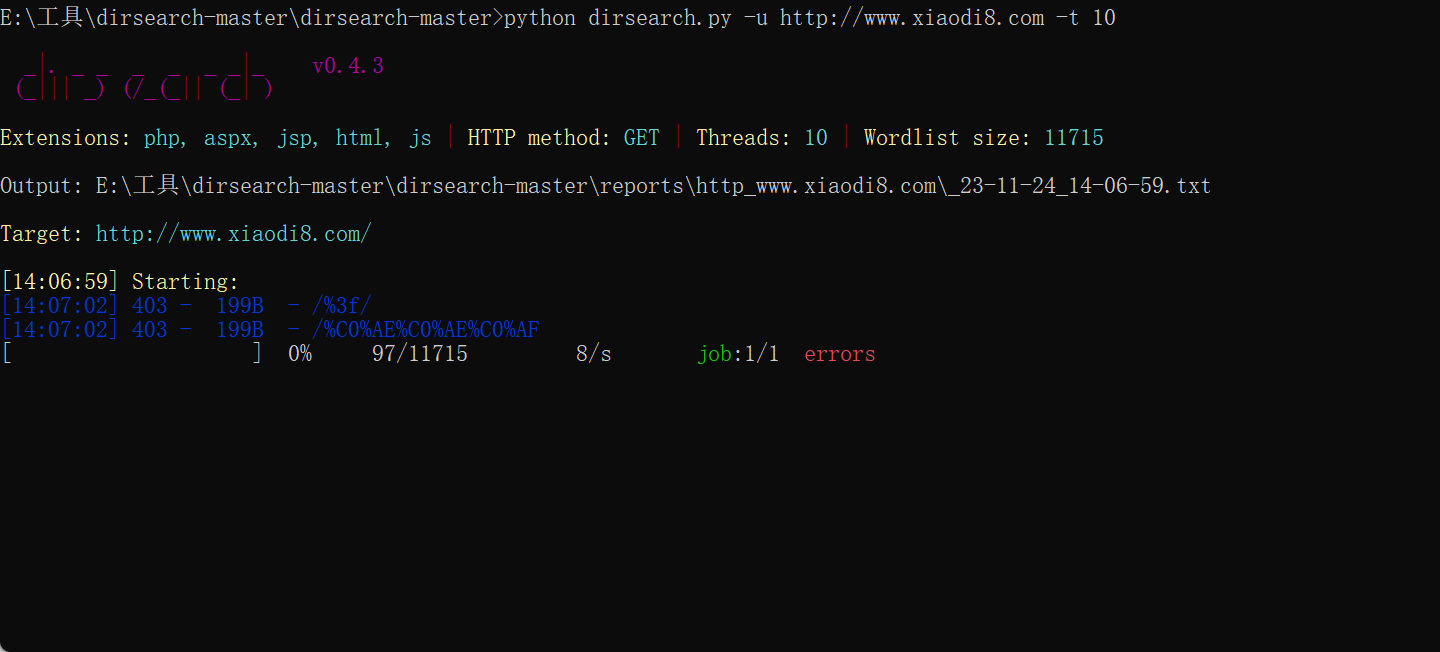
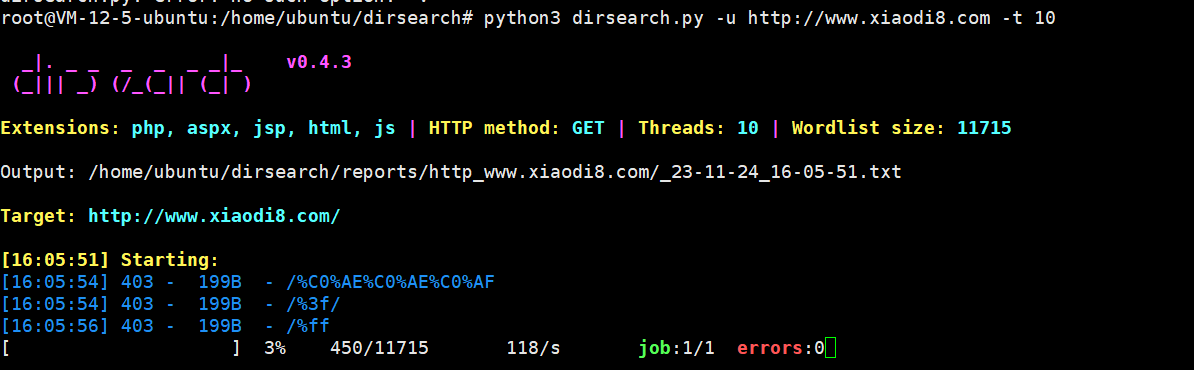
上面那个图是在我物理机上试的,下面这个是在服务器上试的。
这里10个线程不代表速度就是10个每秒,10个线程表示同时请求的数量为10,而每秒的请求次数还受到服务器响应时间、网络延迟以及请求的具体性质等多个因素的影响。
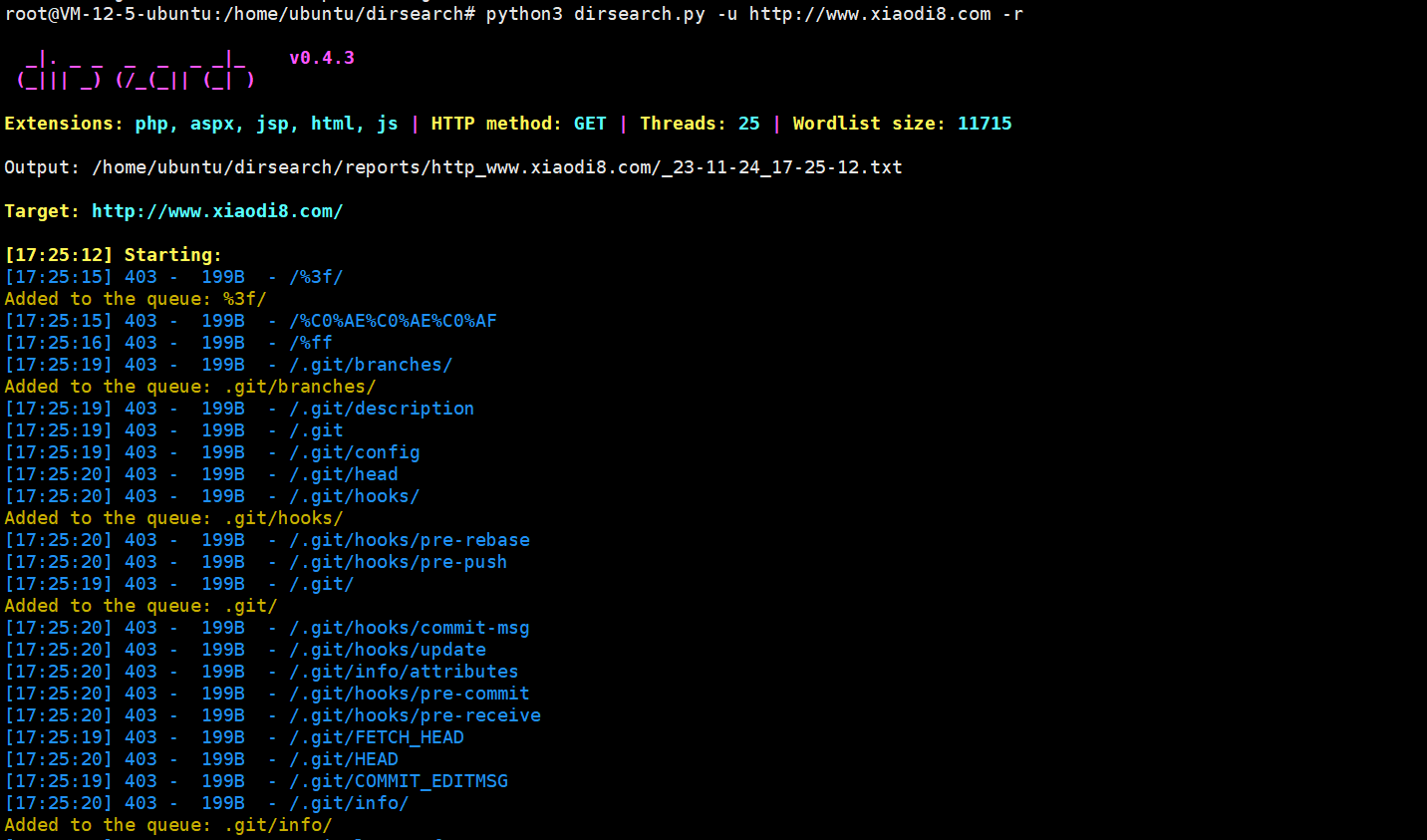
python3 dirsearch.py -u http://example.com -r
-r参数代表使用递归查询
递归查询(recursive search)是指在扫描目标网站时,不仅仅查找目标网站的根目录下的文件和文件夹,还会深入到子目录中进行查找。
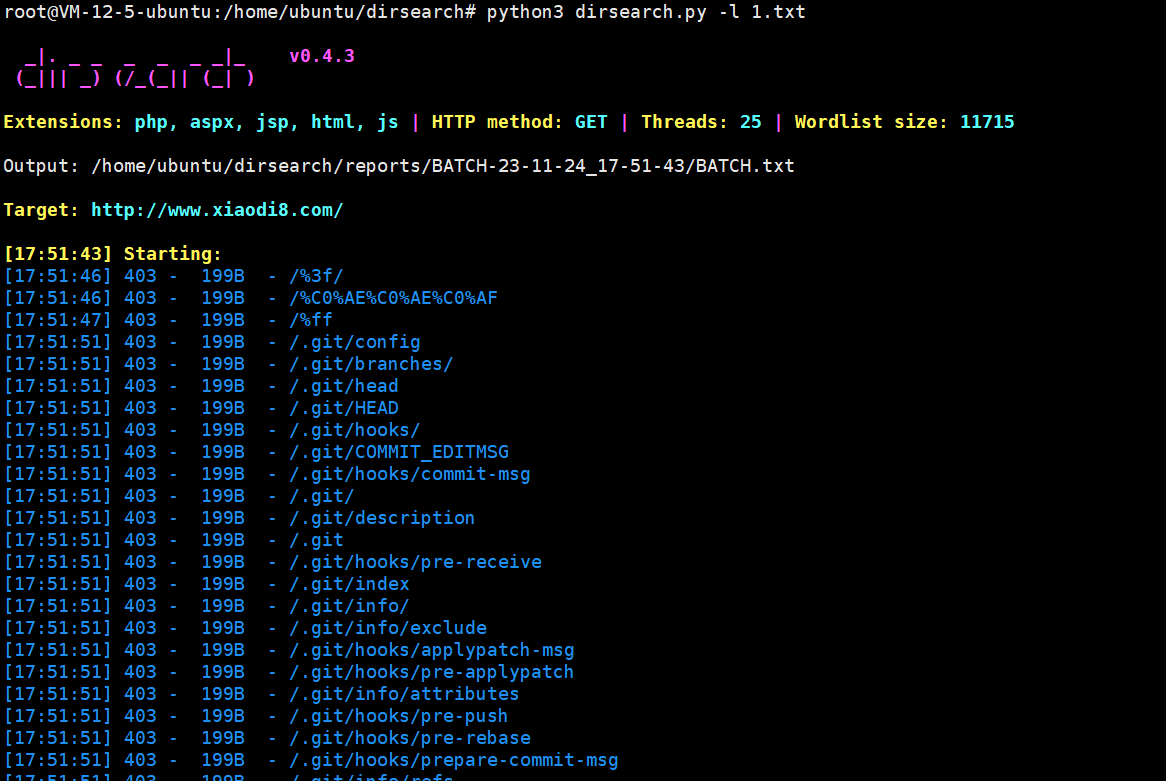
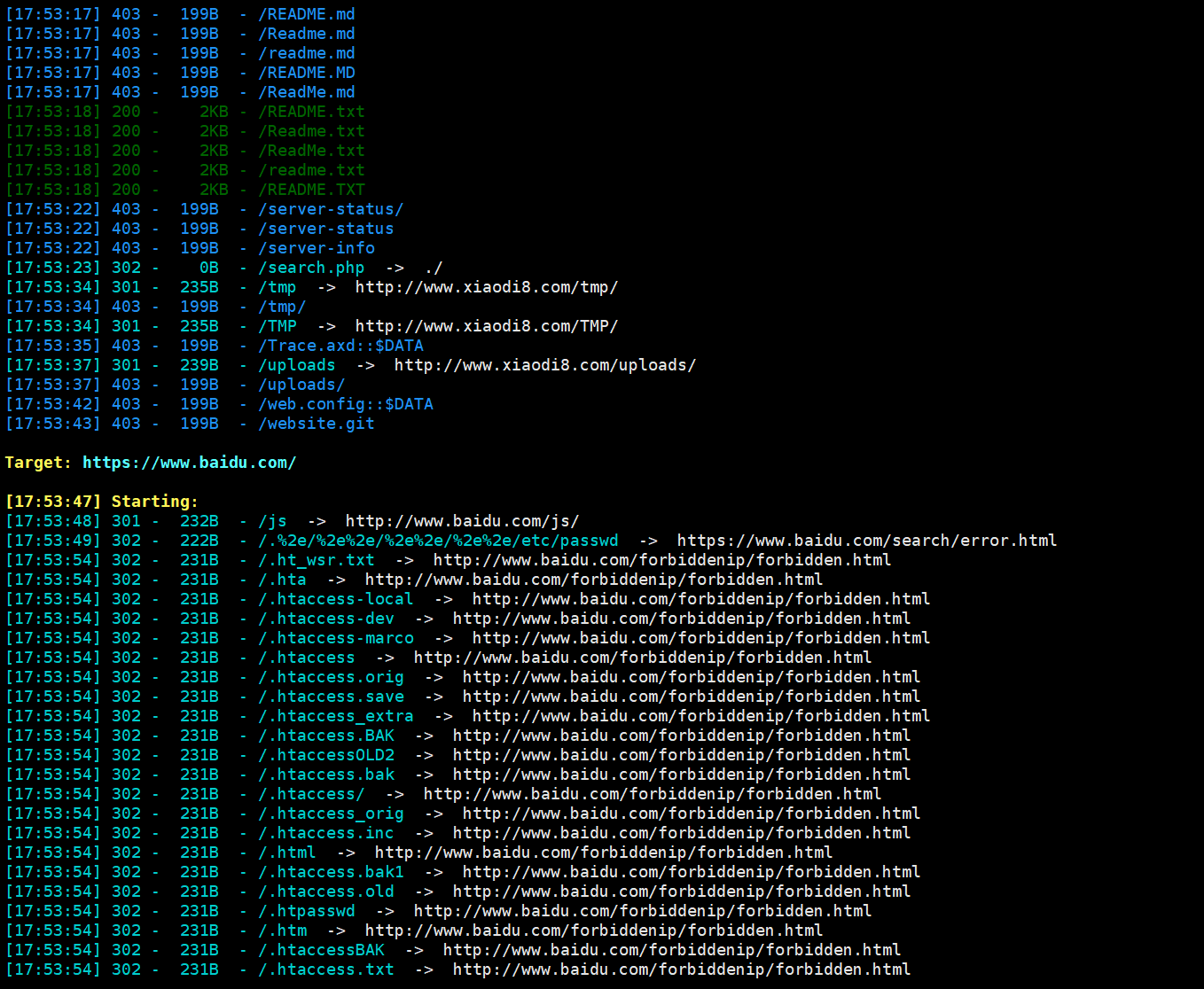
python3 dirsearch.py -l url.txt
将需要扫描的url放到url.txt,去批量扫描。
可以看到这里1.txt中有两个地址,dirsearch会按照顺序去一个一个扫描,最终将扫描结果保存到reports里面