1、什么是React?
React是一个用于构建用户界面的JavaScript库。
2、React的特点是什么?
React的主要特点包括:
- 组件化
- 虚拟DOM
- 单向数据流
- JSX语法
- 高效的性能
- 生态系统丰富
3、什么是JSX?
JSX是一种JavaScript的语法扩展,它允许我们在JavaScript中编写类似HTML的代码。它是React的核心之一,用于描述UI组件的结构和样式。
4、React中的组件有哪些类型?
React中的组件可以分为两种类型:
- 函数组件:使用函数来定义组件。
- 类组件:使用ES6类来定义组件。
4.1、类组件和函数式组件的区别
(1)语法:类组件使用ES6的class语法创建组件,而函数式组件使用函数声明来创建组件。
(2)状态管理:类组件可以使用state来管理组件的内部状态,而函数式组件则通常使用userState Hook来管理状态。
(3)生命周期:类组件可以使用生命周期方法,如componentDidMount、componentDidUpdate等来管理组件的生命周期,而函数式组件则使用useEffect Hook来管理。
(4)调用方式:如果是一个函数组件,调用则是执行函数即可,如果是一个类组件,则需要将组件进行实例化,然后调用实例对象的render方法
(5)性能:函数式组件通常比类组件更轻量级,因为类组件需要实例化,而函数式组件只是普通函数调用。
5、React 事件机制
<div onClick={this.handleClick.bind(this)}>点我</div>
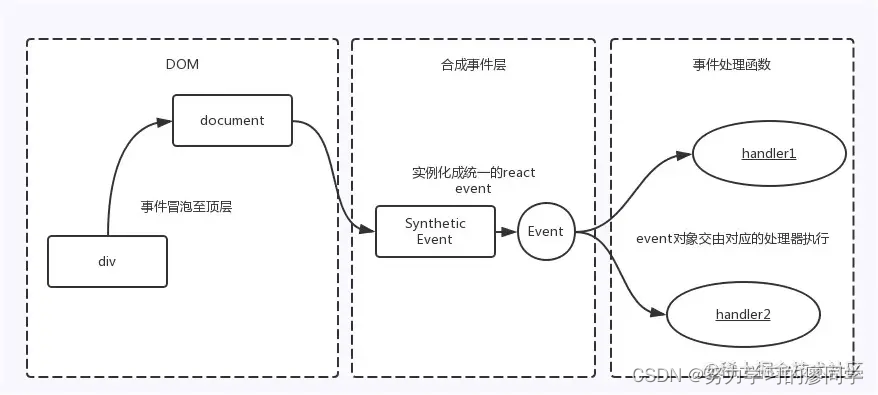
5.1、事件绑定
JSX 上写的事件并没有绑定在对应的真实 DOM 上,而是通过事件代理的方式,将所有的事件都统一绑定在了 document 上。这样的方式不仅减少了内存消耗,还能在组件挂载销毁时统一订阅和移除事件。另外冒泡到 document 上的事件也不是原生浏览器事件,而是 React 自己实现的合成事件(SyntheticEvent)。因此我们如果不想要事件冒泡的话,调用 event.stopPropagation 是无效的,而应该调用 event.preventDefault。
5.2、React的事件和普通的HTML事件有什么不同?(不懂)
区别:
- 对于事件名称命名方式,原生事件为全小写,react 事件采用小驼峰;
- 对于事件函数处理语法,原生事件为字符串,react 事件为函数;
- react 事件不能采用 return false 的方式来阻止浏览器的默认行为,而必须要地明确地调用
preventDefault()来阻止默认行为。
合成事件是 react 模拟原生 DOM 事件所有能力的一个事件对象,其优点如下:
- 兼容所有浏览器,更好的跨平台;
- 将事件统一存放在一个数组,避免频繁的新增与删除(垃圾回收)。
- 方便 react 统一管理和事务机制。
事件的执行顺序为原生事件先执行,合成事件后执行,合成事件会冒泡绑定到 document 上,所以尽量避免原生事件与合成事件混用,如果原生事件阻止冒泡,可能会导致合成事件不执行,因为需要冒泡到document 上合成事件才会执行。
SyntheticEvent源码需要探究与补充。原生事件?--合成事件?
5.3、React 组件中怎么做事件代理?它的原理是什么?(不懂)
React基于Virtual DOM实现了一个SyntheticEvent层(合成事件层),定义的事件处理器会接收到一个合成事件对象的实例,它符合W3C标准,且与原生的浏览器事件拥有同样的接口,支持冒泡机制,所有的事件都自动绑定在最外层上。
在React底层,主要对合成事件做了两件事:
- 事件委派: React会把所有的事件绑定到结构的最外层,使用统一的事件监听器,这个事件监听器上维持了一个映射来保存所有组件内部事件监听和处理函数。
- 自动绑定: React组件中,每个方法的上下文都会指向该组件的实例,即自动绑定this为当前组件。
6、 React.Component 和 React.PureComponent 的区别
(1)PureComponent表示一个纯组件,可以用来优化React程序,减少render函数执行的次数,从而提高组件的性能。在React中,当prop或者state发生变化时,可以通过在shouldComponentUpdate生命周期函数中执行return false来阻止页面的更新,从而减少不必要的render执行。React.PureComponent会自动执行 shouldComponentUpdate。
(2)不过,pureComponent中的 shouldComponentUpdate() 进行的是浅比较,也就是说如果是引用数据类型的数据,只会比较不是同一个地址,而不会比较这个地址里面的数据是否一致。浅比较会忽略属性和或状态突变情况,其实也就是数据引用指针没有变化,而数据发生改变的时候render是不会执行的。如果需要重新渲染那么就需要重新开辟空间引用数据。PureComponent一般会用在一些纯展示组件上。
(3)使用pureComponent的好处:当组件更新时,如果组件的props或者state都没有改变,render函数就不会触发。省去虚拟DOM的生成和对比过程,达到提升性能的目的。这是因为react自动做了一层浅比较。
7、React逻辑复用方式有哪些?
- HOC(高阶组件):高阶组件是一个函数,它接收一个组件作为参数并返回一个新的组件。高阶组件可以将一些通用的逻辑(如:数据获取、权限验证、错误处理等)封装到一个函数中,并将其作为高阶组件的参数传递给其他组件使用,HOC一般以withXxx命名,并可以结合装饰器优雅地使用。
- Render Props:通过在组件中传递一个函数作为prop,该函数将用于渲染组件的内容。这个函数可以接收组件需要的数据和方法,并返回React元素。
- 自定义Hooks:自定义Hooks,将通用逻辑封装到useXxx函数中,可以在多个组件内使用,常见的像数据请求、表单、防抖节流、拖拽等。
8、React 高阶组件是什么,适用什么场景
高阶组件(HOC)就是一个函数,且该函数接受一个组件作为参数,并返回一个新的组件,它只是一种组件的设计模式,这种设计模式是由react自身的组合性质必然产生的。我们将它们称为纯组件,因为它们可以接受任何动态提供的子组件,但它们不会修改或复制其输入组件中的任何行为。
1)HOC的优缺点
- 优点∶ 逻辑服用、不影响被包裹组件的内部逻辑。
- 缺点∶hoc传递给被包裹组件的props容易和被包裹后的组件重名,进而被覆盖???
2)适用场景
- 复用逻辑:高阶组件更像是一个加工 react 组件的工厂,批量对原有组件进行加工,包装处理。我们可以根据业务需求定制化专属的 HOC,这样可以解决复用逻辑。
- 强化 props:这个是 HOC 最常用的用法之一,高阶组件返回的组件,可以劫持上一层传过来的 props,然后混入新的 props,来增强组件的功能。代表作 react-router 中的 withRouter。
- 赋能组件:HOC 有一项独特的特性,就是可以给被 HOC 包裹的业务组件,提供一些拓展功能,比如说额外的生命周期,额外的事件,但是这种 HOC,可能需要和业务组件紧密结合。典型案例 react-keepalive-router 中的 keepaliveLifeCycle 就是通过 HOC 方式,给业务组件增加了额外的生命周期。
- 控制渲染:劫持渲染是 hoc 一个特性,在 wrapComponent 包装组件中,可以对原来的组件,进行条件渲染,节流渲染,懒加载等功能,后面会详细讲解,典型代表做 react-redux 中 connect 和 dva 中 dynamic 组件懒加载。
3)具体应用例子
- 权限控制: 利用高阶组件的 条件渲染 特性可以对页面进行权限控制,权限控制一般分为两个维度:页面级别和 页面元素级别
- 页面复用
9、哪些方法会触发 React 重新渲染?
(1)哪些方法会触发 react 重新渲染?
默认情况下,当组件的 state 或 props 发生变化时,组件将重新渲染。如果 render() 方法依赖于其他数据,则可以调用 forceUpdate() 强制让组件重新渲染。但是这里有个点值得关注,执行 setState 的时候不一定会重新渲染。当 setState 传入 null 时,并不会触发 render。只要父组件重新渲染了,即使传入子组件的 props 未发生变化,那么子组件也会重新渲染,进而触发 render
component.forceUpdate() 一个不常用的生命周期方法, 它的作用就是强制刷新
官网解释如下
调用 forceUpdate() 将致使组件调用 render() 方法,此操作会跳过该组件的 shouldComponentUpdate()。但其子组件会触发正常的生命周期方法,包括 shouldComponentUpdate() 方法。如果标记发生变化,React 仍将只更新 DOM。
通常你应该避免使用 forceUpdate(),尽量在 render() 中使用 this.props 和 this.state。
shouldComponentUpdate 在初始化 和 forceUpdate 不会执行。
(2)当调用setState时,React render 是如何工作的?
可以将"render"分为两个步骤:
虚拟 DOM 渲染:当
render方法被调用时,它返回一个新的组件的虚拟 DOM 结构。当调用setState()时,render会被再次调用,因为默认情况下shouldComponentUpdate总是返回true,所以默认情况下 React 是没有优化的。原生 DOM 渲染:React 只会在虚拟DOM中修改真实DOM节点,而且修改的次数非常少——这是很棒的React特性,它优化了真实DOM的变化,使React变得更快。
补充:重新渲染 render 会做些什么?
- 会对新旧 VNode 进行对比,也就是我们所说的Diff算法。
- 对新旧两棵树进行一个深度优先遍历,这样每一个节点都会一个标记,在到深度遍历的时候,每遍历到一和个节点,就把该节点和新的节点树进行对比,如果有差异就放到一个对象里面
- 遍历差异对象,根据差异的类型,根据对应对规则更新VNode
(3)state 和 props 区别是啥?
props和state是普通的 JS 对象。虽然它们都包含影响渲染输出的信息,但是它们在组件方面的功能是不同的。即
state是组件自己管理数据,控制自己的状态,可变;props是外部传入的数据参数,不可变;没有
state的叫做无状态组件,有state的叫做有状态组件;多用
props,少用state,也就是多写无状态组件
10、对有状态组件和无状态组件的理解及使用场景
(1)有状态组件 特点:
有状态组件是指具有内部状态(state)的组件。组件内部状态是在组件生命周期中可以被修改的数据,当状态发生变化时,React 会重新渲染组件。有状态组件通常是通过类定义的,继承自 React.Component,并且可以使用 state 属性
使用场景:
- 当组件需要管理内部状态,且该状态会随着用户操作、网络请求等而发生变化时,使用有状态组件。
- 有状态组件通常用于复杂的 UI 组件,例如表单、数据列表,或需要处理生命周期事件的组件。
(2)无状态组件 特点:
无状态组件是指没有内部状态的组件,也称为纯函数组件。这类组件通常是无状态的,不管理状态,只接收 props 并渲染 UI。无状态组件可以使用函数定义,也可以使用函数式组件的语法。
使用场景:
- 当组件只需要根据传入的 props 进行渲染,而不需要维护内部状态时,使用无状态组件。
- 无状态组件通常用于展示性组件,只负责接收数据并进行渲染,不包含复杂的业务逻辑。
11、请说岀 React从 EMAScript5编程规范到 EMAScript6编程规范过程中的几点改变。
(1)创建组件的方法不同。 EMAScript5版本中,定义组件用 React.createClass。EMAScript6版本中,定义组件要定义组件类,并继承 Component类。
(2)定义默认属性的方法不同。 EMAScript5版本中,用 getDefaultProps定义默认属性。EMAScript6版本中,为组件定义 defaultProps静态属性,来定义默认属性。
(3)定义初始化状态的方法不同。EMAScript5版本中,用 getInitialState定义初始化状态。EMAScript6版本中,在构造函数中,通过this. state定义初始化状态。 注意:构造函数的第一个参数是属性数据,一定要用 super继承。
(4)定义属性约束的方法不同。 EMAScript5版本中,用 propTypes定义属性的约束。 EMAScript6版本中,为组件定义 propsTypes静态属性,来对属性进行约束。
(5)使用混合对象、混合类的方法不同。 EMAScript5版本中,通过mixins继承混合对象的方法。 EMAScript6版本中,定义混合类,让混合类继承 Component类,然后让组件类继承混合类,实现对混合类方法的继承。
(6)绑定事件的方法不同。 EMAScript5版本中,绑定的事件回调函数作用域是组件实例化对象。 EMAScript6版本中,绑定的事件回调函数作用域是null。
(7)父组件传递方法的作用域不同。 EMAScript5版本中,作用域是父组件。 EMAScript6版本中,变成了null。
(8)组件方法作用域的修改方法不同。 EMAScript5版本中,无法改变作用域。 EMAScript6版本中,作用域是可以改变的。
// ES5
var MyComponent = React.createClass({
render: function() {
return
<h3>Hello Edureka!</h3>;
}
});
// ES6
class MyComponent extends React.Component {
render() {
return
<h3>Hello Edureka!</h3>;
}
}
// ES5
var App = React.createClass({
propTypes: { name: React.PropTypes.string },
render: function() {
return
<h3>Hello, {this.props.name}!</h3>;
}
});
// ES6
class App extends React.Component {
render() {
return
<h3>Hello, {this.props.name}!</h3>;
}
}
// ES5
var App = React.createClass({
getInitialState: function() {
return { name: 'world' };
},
render: function() {
return
<h3>Hello, {this.state.name}!</h3>;
}
});
// ES6
class App extends React.Component {
constructor() {
super();
this.state = { name: 'world' };
}
render() {
return
<h3>Hello, {this.state.name}!</h3>;
}
}
12、React.createClass和extends Component的区别有哪些?
createClass本质上是一个工厂函数,extends的方式更加接近最新的ES6规范的class写法。不推荐使用createClass,已经废除
var MyComponent = React.createClass({
render: function() {
return <div>Hello, {this.props.name}</div>;
}
});
13、React18 有哪些新变化?
React 的更新都是渐进式的更新,在 React18 中启用的新特性,其实在 v17 中(甚至更早)就埋下了。
- 并发渲染机制:根据用户的设备性能和网速对渲染过程进行适当的调整, 保证 React 应用在长时间的渲染过程中依旧保持可交互性,避免页面出现卡顿或无响应的情况,从而提升用户体验。
- 新的创建方式:现在是要先通过
createRoot()创建一个 root 节点,然后该 root 节点来调用render()方法; - 自动批处理优化:批处理: React 将多个状态更新分组到一个重新渲染中以获得更好的性能。(将多次 setstate 事件合并);在 v18 之前只在事件处理函数中实现了批处理,在 v18 中所有更新都将自动批处理,包括 promise 链、setTimeout 等异步代码以及原生事件处理函数;
- startTransition:主动降低优先级。比如「搜索引擎的关键词联想」,用户在输入框中的输入希望是实时的,而联想词汇可以稍稍延迟一会儿。我们可以用 startTransition 来降低联想词汇更新的优先级;
- useId:主要用于 SSR 服务端渲染的场景,方便在服务端渲染和客户端渲染时,产生唯一的 id;
14、怎么理解Fiber和并发模式?
14. 1、为什么要设计并发模式?
在React的旧版本中,当组件状态发生变化时,React会将整个组件树进行递归遍历,生成新的虚拟DOM树,并与旧的虚拟DOM树进行比较,找出需要更新的部分,然后将这些部分更新到DOM中。这种遍历方式虽然简单,但是在组件树变得非常大、复杂的情况下,会导致渲染和更新性能下降,造成页面卡顿甚至无法响应用户操作的情况。为了解决这个问题,React引入了并发模式。
14.2、 Fiber是什么?
- Fiber是一种数据结构,由VDOM转化生成。
- Fiber的思想是将组件树的遍历过程拆分成多个小的、可中断的任务,以实现更细粒度的控制和优化。
- 具体来说,Fiber将每个组件看作是一个执行单元,并将组件树转换成一棵Fiber树。每个Fiber节点都包含了组件的状态和一些额外的信息,例如优先级、副作用等。
- 在更新过程中,React会根据Fiber节点的优先级,将Fiber树转换成一个任务队列,然后按照优先级进行调度和执行。React还会利用浏览器提供的requestIdleCallback API来分配空闲时间,以避免阻塞渲染线程。
- 由于Fiber将组件树的遍历过程拆分成了多个小的、可中断的任务,因此React可以在需要更新的部分进行优化,从而提高渲染和更新的性能。例如,在执行更新任务时,React可以根据优先级调整任务的执行顺序,避免低优先级任务阻塞高优先级任务的执行,提高了应用程序的响应速度和性能。
14.3、并发模式是如何执行的?
React 中的并发,并不是指同一时刻同时在做多件事情。因为 js 本身就是单线程的(同一时间只能执行一件事情),而且还要跟 UI 渲染竞争主线程。若一个很耗时的任务占据了线程,那么后续的执行内容都会被阻塞。为了避免这种情况,React 就利用 fiber 结构和时间切片的机制,将一个大任务分解成多个小任务,然后按照任务的优先级和线程的占用情况,对任务进行调度。
- 对于每个更新,为其分配一个优先级 lane,用于区分其紧急程度。
- 通过 Fiber 结构将不紧急的更新拆分成多段更新,并通过宏任务的方式将其合理分配到浏览器的帧当中。这样就能使得紧急任务能够插入进来。
- 高优先级的更新会打断低优先级的更新,等高优先级更新完成后,再开始低优先级更新。
15、用户不同权限 可以查看不同的页面 如何实现?
15.1、Js方式
根据用户权限类型,把菜单配置成json, 没有权限的直接不显示
(1)定义权限配置: 在你的应用中定义不同权限对应的页面和菜单配置。
// 权限配置
const permissions = {
admin: ['dashboard', 'users', 'settings'],
user: ['dashboard', 'profile'],
};
// 菜单配置
const menuConfig = [
{ id: 'dashboard', label: 'Dashboard', link: '/dashboard' },
{ id: 'users', label: 'Users', link: '/users' },
{ id: 'settings', label: 'Settings', link: '/settings' },
{ id: 'profile', label: 'Profile', link: '/profile' },
];
(2)根据权限生成菜单: 在页面加载时,根据用户的权限动态生成菜单
// 根据权限生成菜单
function generateMenu(userPermissions) {
return menuConfig.filter(item => userPermissions.includes(item.id));
}
// 模拟当前用户权限
const currentUserPermissions = permissions.admin;
// 生成菜单
const userMenu = generateMenu(currentUserPermissions);
(3)在页面中渲染菜单: 在 React 组件中使用生成的菜单进行渲染。
import React from 'react';
const Sidebar = ({ menu }) => {
return (
<div>
<h2>Menu</h2>
<ul>
{menu.map(item => (
<li key={item.id}>
<a href={item.link}>{item.label}</a>
</li>
))}
</ul>
</div>
);
};
// 渲染菜单组件
const App = () => {
return <Sidebar menu={userMenu} />;
};
15.2、自己封装一个privateRouter组件
react 可以使用高阶组件,在高阶组件里面判断是否有权限,然后判断是否返回组件,无权限返回null
vue 可以使用自定义指令,如果没有权限移除组件(需要补充)
// 需要在入口处添加自定义权限指令v-auth,显示可操作组件
Vue.directive('auth', {
bind: function (el, binding, vnode) {
// 用户权限表
const rules = auths
for (let i = 0; i < rules.length; i++) {
const item = rules[i]
if(!binding.value || (binding.value == item.auth)){
// 权限允许则显示组件
return true
}
}
// 移除组件
el.parentNode.removeChild(el)
}
})
// 使用
<template>
<div>
<Button v-auth="admin_user_add">添加用户</Button>
<Button v-auth="admin_user_del">删除用户</Button>
<Button v-auth="admin_user_edit">编辑用户</Button>
</div>
</template>
16、setState 是同步异步?为什么?实现原理?
1. setState是同步执行的,但是state并不一定会同步更新。
2. setState在React生命周期和合成事件中批量覆盖执行
异步行为:
批处理更新: React 会对
setState进行批处理,将多个更新合并为一个,以提高性能。这就意味着,在一个生命周期内,多个setState调用可能被合并成一个单一的更新操作。在React的生命周期钩子和合成事件中,如果多次同步执行setState,会批量执行,类似于Object.assign,相同的key,后面的会覆盖前面的。异步更新队列: React 会将
setState的更新任务放入异步更新队列中,而不是立即执行。这使得 React 在适当的时机可以对更新进行优化,比如合并多个更新操作。
为什么是异步的:
性能优化: 异步更新可以提高性能,通过合并多个更新操作减少了不必要的重复渲染。
防止循环依赖: 异步更新可以防止由于组件之间的循环依赖而导致的无限循环更新。
React 组件的 props 变动,会让组件重新执行,但并不会引起 state 的值的变动。state 值的变动,只能由 setState() 来触发。因此若想在 props 变动时,重置 state 的数据,需要监听 props 的变动,如:
17、非嵌套关系组件的通信方式?
即没有任何包含关系的组件,包括兄弟组件以及不在同一个父级中的非兄弟组件。
- 可以使用自定义事件通信(发布订阅模式)。不推荐使用context,Context目前还处于实验阶段,可能会在后面的发行版本中有很大的变化
- 可以通过redux等进行全局状态管理
- 如果是兄弟组件通信,可以找到这两个兄弟节点共同的父节点, 结合父子间通信方式进行通信。
18、为什么 useState 要使用数组而不是对象
useState 返回的是 array 而不是 object 的原因就是为了降低使用的复杂度,返回数组的话可以直接根据顺序解构,而返回对象的话要想使用多次就需要定义别名了。
const [count, setCount] = useState(0)- 如果 useState 返回的是数组,那么使用者可以对数组中的元素命名,代码看起来也比较干净
- 如果 useState 返回的是对象,在解构对象的时候必须要和 useState 内部实现返回的对象同名,想要使用多次的话,必须得设置别名才能使用返回值
// 第一次使用
const { state, setState } = useState(false);
// 第二次使用
const { state: counter, setState: setCounter } = useState(0) 18、在 React中元素( element)和组件( component)有什么区别?
简单地说,在 React中元素(虛拟DOM)描述了你在屏幕上看到的DOM元素。 换个说法就是,在 React中元素是页面中DOM元素的对象表示方式。
在 React中组件是一个函数或一个类,它可以接受输入并返回一个元素。 注意:工作中,为了提高开发效率,通常使用JSX语法表示 React元素(虚拟DOM)。在编译的时候,把它转化成一个 React. createElement调用方法。
19、哪个生命周期发送ajax
useEffect componentDidMount
20、什么是 React的refs?
refs允许你直接访问DOM元素或组件实例。为了使用它们,可以向组件添加个ref属性。
(1)如果该属性的值是一个回调函数,它将接受底层的DOM元素或组件的已挂载实例作为其第一个参数。可以在组件中存储它。
export class App extends Component {
showResult() {
console.log(this.input.value);
}
render() {
return (
<div>
<input type="text" ref={(input) => (this.input = input)} />
<button onClick={this.showResult.bind(this)}>展示结果</button>
</div>
);
}
}
(2)如果该属性值是一个字符串, React将会在组件实例化对象的refs属性中,存储一个同名属性,该属性是对这个DOM元素的引用。可以通过原生的 DOM API操作它。
export class App extends Component {
showResult() {
console.log(this.refs.username.value);
}
render() {
return (
<div>
<input type="text" ref="username" />
<button onClick={this.showResu1t.bind(this)}>展示结果</button>
</div>
);
}
}
21、如何实现一个定时器的 hook
若在定时器内直接使用 React 的代码,可能会收到意想不到的结果。如我们想实现一个每 1 秒加 1 的定时器:
const App = () => {
const [count, setCount] = useState(0);
useEffect(() => {
const timer = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(timer);
}, []);
return <div className="App">{count}</div>;
};
可以看到,coun 从 0 变成 1 以后,就再也不变了。为什么会这样?
尽管由于定时器的存在,组件始终会一直重新渲染,但定时器的回调函数是挂载期间定义的,所以它的闭包永远是对挂载时 Counter 作用域的引用,故 count 永远不会超过 1。
// 监听 count 的变化,不过这里将定时器改成了 setTimeout
// 即使不修改,setInterval()的timer也会在每次渲染时被清除掉,
// 然后重新启动一个新的定时器
useEffect(() => {
const timer = setTimeout(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(timer);
}, [count]);22、虚拟 dom 有什么优点?真实 dom 和虚拟 dom,谁快?
Virtual DOM 是以对象的方式来描述真实 dom 对象的,那么在做一些 update 的时候,可以在内存中进行数据比对,减少对真实 dom 的操作减少浏览器重排重绘的次数,减少浏览器的压力,提高程序的性能,并且因为 diff 算法的差异比较,记录了差异部分,那么在开发中就会帮助程序员减少对差异部分心智负担,提高了开发效率。
虚拟 dom 好多这么多,渲染速度上是不是比直接操作真实 dom 快呢?并不是。虚拟 dom 增加了一层内存运算,然后才操作真实 dom,将数据渲染到页面上。渲染上肯定会慢上一些。虽然虚拟 dom 的缺点在初始化时增加了内存运算,增加了首页的渲染时间,但是运算时间是以毫秒级别或微秒级别算出的,对用户体验影响并不是很大。
为什么在本地开发时,组件会渲染两次?
在 React.StrictMode 模式下,如果用了 useState,usesMemo,useReducer 之类的 Hook,React 会故意渲染两次,为的就是将一些不容易发现的错误容易暴露出来,同时 React.StrictMode 在正式环境中不会重复渲染。
也就是在测试环境的严格模式下,才会渲染两次。
23、如何实现组件的懒加载
从 16.6.0 开始,React 提供了 lazy 和 Suspense 来实现懒加载。
import React, { lazy, Suspense } from 'react';
const OtherComponent = lazy(() => import('./OtherComponent'));
function MyComponent() {
return (
<Suspense fallback={<div>Loading...</div>}>
<OtherComponent />
</Suspense>
);
}24、性能优化
使用缓存,多用无状态组件,组件懒加载,key
基于 React 框架的特点,可以有哪些优化措施?
- 使用 React.lazy 和 Suspense 将页面设置为懒加载,避免 js 文件过大;
- 使用 SSR 同构直出技术,提高首屏的渲染速度;
- 使用 useCallback 和 useMemo 缓存函数或变量;使用 React.memo 缓存组件;
- 尽量调整样式或 className 的变动,减少 jsx 元素上的变动,尽量使用与元素相关的字段作为 key,可以减少 diff 的时间(React 会尽量复用之前的节点,若 jsx 元素发生变动,就需要重新创建节点);
- 对于不需要产生页面变动的数据,可以放到 useRef()中;
25、useState()的 state 是否可以直接修改?是否可以引起组件渲染?
首先声明,我们不应当直接修改 state 的值,一方面是无法刷新组件(无法将新数据渲染到页面中),再有可能会对下次的更新产生影响。
唯一有影响的,就是后续要使用该变量的地方,会使用到新数据。但若其他 useState() 导致了组件的刷新,刚才变量的值,若是基本类型(比如数字、字符串等),会重置为修改之前的值;若是复杂类型,基于 js 的 对象引用 特性,也会同步修改 React 内部存储的数据,但不会引起视图的变化。
26、React.Children.map 和 js 的 map 有什么区别?
JavaScript 中的 map 不会对为 null 或者 undefined 的数据进行处理,而 React.Children.map 中的 map 可以处理 React.Children 为 null 或者 undefined 的情况。
27、react中引入css的方式
(1)组件中引入 .module.css 文件
使用.module.css文件来为组件引入样式,这种方式也被称为CSS模块化。
在.module.css文件中定义的样式只能作用于当前组件内部,不会影响到其他组件或全局样式,这样可以避免样式冲突的问题。
(2)CSS in JS
CSS in JS 是一种前端开发技术,它将 CSS 样式表的定义和 JS 代码紧密结合在一起,以实现更高效、更灵活的样式控制。在 CSS in JS 中,开发者可以使用 JS 来编写 CSS 样式,可以在代码中通过变量或函数等方式来动态生成样式。这种方式可以避免传统 CSS 中的一些问题,如全局作用域、选择器嵌套、命名冲突等,同时也提供了更高的可重用性和可维护性。
在 React 中,有多种支持 CSS in JS 的第三方库,比较常用的有 styled-components、Emotion、JSS 等。这些库都提供了方便的 API 来定义和应用样式,并且可以自动管理 CSS 的引入和组件的封装。使用 CSS in JS 可以更好地与组件化开发思想结合,提高代码的可复用性和可维护性。
28、使用Hooks有踩过哪些坑?
- useEffect中没有正确设置依赖数组导致死循环。
- useEffect中没有清除副作用导致内存泄漏。
- 在条件语句和循环中使用Hooks导致报错。
- 闭包陷阱。
29、 React Router中有哪些组件?
BrowserRouter:用于在应用程序中启用HTML5历史路由。
HashRouter:用于在应用程序中启用哈希路由。
Route:用于定义应用程序中的路由规则。
Switch:用于在多个路由规则中选择一个。
Link:用于在应用程序中导航到其他页面。
30、react-redux
(1)有什么缺点(不懂)
- 一个组件所需要的数据,必须由父组件传过来,而不能像
flux中直接从store取。 - 当一个组件相关数据更新时,即使父组件不需要用到这个组件,父组件还是会重新
render,可能会有效率影响,或者需要写复杂的shouldComponentUpdate进行判断。
(2)Redux中有以下核心概念:
- Store:用于管理应用程序的状态。
- Action:用于描述发生的事件。在Redux中使用 Action的时候, Action文件里尽量保持 Action文件的纯净,传入什么数据就返回什么数据,最妤把请求的数据和 Action方法分离开,以保持 Action的纯净。
- Reducer:用于处理Action并更新状态。
- Dispatch:用于将Action发送到Reducer。
(3)redux中间件--处理异步与promise
中间件提供第三方插件的模式,自定义拦截
action->reducer的过程。变为action->middlewares->reducer。这种机制可以让我们改变数据流,实现如异步action,action过滤,日志输出,异常报告等功能
redux-logger:提供日志输出redux-thunk:处理异步操作redux-promise:处理异步操作,actionCreator的返回值是promise
下面是一个使用 redux-thunk 处理异步操作的示例:
import { createStore, applyMiddleware } from 'redux';
import thunk from 'redux-thunk';
// 定义 action 类型
const FETCH_DATA_REQUEST = 'FETCH_DATA_REQUEST';
const FETCH_DATA_SUCCESS = 'FETCH_DATA_SUCCESS';
const FETCH_DATA_FAILURE = 'FETCH_DATA_FAILURE';
// 同步 action 创建函数
const fetchDataRequest = () => ({
type: FETCH_DATA_REQUEST,
});
const fetchDataSuccess = (data) => ({
type: FETCH_DATA_SUCCESS,
payload: data,
});
const fetchDataFailure = (error) => ({
type: FETCH_DATA_FAILURE,
payload: error,
});
// 异步 action 创建函数(使用 redux-thunk)
const fetchData = () => {
return (dispatch) => {
dispatch(fetchDataRequest());
// 异步操作(例如 API 请求)
fetch('https://api.example.com/data')
.then(response => response.json())
.then(data => dispatch(fetchDataSuccess(data)))
.catch(error => dispatch(fetchDataFailure(error)));
};
};
// Reducer
const reducer = (state = {}, action) => {
switch (action.type) {
case FETCH_DATA_REQUEST:
// 处理请求中的状态
return { ...state, loading: true };
case FETCH_DATA_SUCCESS:
// 处理请求成功的状态
return { ...state, loading: false, data: action.payload };
case FETCH_DATA_FAILURE:
// 处理请求失败的状态
return { ...state, loading: false, error: action.payload };
default:
return state;
}
};
// 创建 store,应用中间件
const store = createStore(reducer, applyMiddleware(thunk));
// 分发异步 action
store.dispatch(fetchData());
31、简述flux 思想
Flux的最大特点,就是数据的"单向流动"。
- 用户访问
View View发出用户的ActionDispatcher收到Action,要求Store进行相应的更新Store更新后,发出一个"change"事件View收到"change"事件后,更新页面
32、什么是React Native?
React Native是一个用于构建原生移动应用程序的React库。它允许我们使用JavaScript和React构建跨平台的应用程序,并且可以在iOS和Android上运行。
React Native中有哪些核心组件?
React Native中有以下核心组件:
View:类似于HTML中的div元素,用于包含其他组件。
Text:用于显示文本。
Image:用于显示图像。
TextInput:用于获取用户输入的文本。
ScrollView:用于滚动页面。
FlatList:用于显示列表。
TouchableOpacity:用于创建可点击的元素。
33、 什么是React Native Navigation?
React Native Navigation是一个用于在React Native应用程序中实现导航的库。它提供了一组易于使用的API,用于管理应用程序的导航栈和屏幕之间的转换。它支持多种导航类型,例如堆栈导航、标签导航和抽屉导航,并且可以与Redux等状态管理库集成使用。React Native Navigation还具有高性能、流畅的动画效果和自定义主题的能力,使得开发人员可以轻松地创建美观、易于使用的导航界面。
一、常用的hooks
useState(): 允许在函数组件中使用状态。使用useState() 声明一个状态变量,并使用它来存储组件的状态。每次更改状态时,组件将重新渲染。
useEffect():用于处理副作用。副作用指在React组件之外进行的操作,例如从服务器获取数据,处理DOM元素等。使用useEffect() hook,您可以执行此类操作,而无需在类组件中编写生命周期方法。
useContext(): 允许您在React中使用上下文。上下文是一种在组件树中传递数据的方法,可以避免通过Props一层层传递数据。使用useContext() hook,您可以访问整个应用程序中定义的上下文对象。
useReducer(): 是useState() hook的替代品,用于管理更复杂的状态。它使用Reducer函数来管理组件状态,Reducer函数接收当前状态和要进行的操作,然后返回新状态。详细使用方式见此文章。
useCallback(): 用于避免在每次渲染时重新创建回调函数。当您需要将回调函数传递给子组件时,这非常有用,因为它可以避免子组件不必要地重新渲染。点击去学习
useMemo(): 用于缓存计算结果,以避免在每次渲染时重新计算。这非常有用,特别是当计算成本很高时。
useRef(): 用于创建对DOM元素的引用。它还可以用于存储组件之间共享的变量,这些变量不会在组件重新渲染时发生更改。
import React, { useReducer } from 'react';
// 定义 reducer 函数
const counterReducer = (state, action) => {
switch (action.type) {
case 'INCREMENT':
return { count: state.count + 1 };
case 'DECREMENT':
return { count: state.count - 1 };
default:
return state;
}
};
// 初始状态
const initialState = { count: 0 };
// 使用 useReducer Hook
const Counter = () => {
const [state, dispatch] = useReducer(counterReducer, initialState);
return (
<div>
<p>Count: {state.count}</p>
<button onClick={() => dispatch({ type: 'INCREMENT' })}>Increment</button>
<button onClick={() => dispatch({ type: 'DECREMENT' })}>Decrement</button>
</div>
);
};
export default Counter;
34、什么是Expo?
Expo是一个用于构建React Native应用程序的开发工具和服务平台。它提供了一些有用的功能,例如快速原型设计、自动构建和发布、设备测试等。
35、设计原则solid
(1)单一职责原则:一个类只负责一件事,只有一个引起它变化的原因。
(2)开闭原则:软件中的对象(类,模块,函数等等)应该对于扩展是开放的,但是对于修改是封闭的。应用单一职责只需要梳理和归纳,而应用开闭原则的关键则在于抽象。
(3)里氏替换原则:若对每个类型S的对象o1,都存在一个类型T的对象o2,使得在所有针对T编写的程序P中,使用o1替换o2后,程序P行为功能不变,则S是T的子类型。
(4)接口隔离原则:不应该强制客户代码依赖它不需要的方法。
(5)依赖倒置原则:高层模块不应该依赖底层模块,两者都应该依赖抽象。



























![[ 蓝桥杯Web真题 ]-Markdown 文档解析](https://img-blog.csdnimg.cn/direct/05ec9015f07242cfaf4c8147c864286b.png)
