目录
简述
在前端领域Babel、TypeScript、Rollup、ESLint 、ide(vscode)等都有一个共同点就是把源码作为输入,然后经过一系列的操作转换成浏览器最终要执行的代码。那这一切都离不开词法分析。
还有像小程序这种,也是把你写的JS最终转换成小程序支持的语法。
讲到词法分析,就要了解计算机的编程语言的一些背景
为什么会出现编程语言
为什么计算机能识别我们的代码:
通常计算机的硬件只能识别机器码(二进制数据)、但这些二进制数据,人是几乎看不懂。为了让人能够看懂机器在做什么,为了让机器明白我们的想要表达的意思,完成我们的指令,所以才出现了让人类更容易懂的编程语言。
所以也就是说任何语言最终都被会编译成机器码被硬件解释执行,反过来说就是编程语言越低层,越复杂或执行更快
在计算机中,不同层次的编程语言经历了一系列的转换和执行过程。以下是这些编程语言在计算机中执行的一般过程和顺序:
机器码(Machine Code):
- 机器码是计算机能够直接执行的二进制指令,每个指令对应于底层硬件的一个操作。
- 机器码由CPU直接执行,不需要任何进一步的转换。
汇编语言(Assembly Language):
- 汇编语言是机器码的助记符表示,提供了对机器码更人类友好的表达方式。
- 汇编语言需要经过汇编器的处理,将汇编代码转换为机器码。
C语言:
- C语言是一种高级语言,需要经过编译器的处理,将源代码转换为机器码。
- 编译器首先进行预处理,包括宏替换、头文件包含等操作,然后进行词法分析、语法分析,生成中间代码,最后进行优化和生成目标机器的机器码。
C++语言:
- C++是C语言的扩展,也需要经过编译器的处理,编译过程类似于C语言。
- C++包括了面向对象的特性,因此编译器还需要进行类的实例化、继承等相关操作。
C#语言:
- C#是一种高级语言,通常运行在.NET平台上。C#源代码通过编译器编译成中间语言(IL,Intermediate Language)。
- 运行时,IL代码由Common Language Runtime(CLR)解释执行或即时编译成机器码。CLR提供了内存管理、类型安全检查等服务。
Java语言:
- Java是一种面向对象的高级语言,源代码编译成字节码。字节码是一种中间语言。
- 运行时,Java程序在Java虚拟机(JVM)上执行,JVM负责将字节码解释执行或即时编译成机器码。JVM提供了垃圾回收、安全性检查等服务。
总体而言,从底层到高层,编程语言经历了从机器码到汇编语言,再到高级语言的编译或解释过程。高级语言提供了更高的抽象层次和开发效率,但通常需要经过更多层次的转换和执行过程。不同的语言和平台可能有些许差异,但这是一个一般的执行过程框架。
为什么能常说C、C++语言比C#或java性能好呢
说C和C++比Java和.NET(C#)性能好,通常是因为C和C++更接近底层硬件,提供更直接的内存控制,并且没有虚拟机的运行时开销。这样的优势在一些特定的应用场景中可能导致更高的性能。
以下是一些可能导致C和C++相对于Java和.NET更高性能的因素:
内存管理:
- C和C++: 程序员有更直接的控制权来管理内存,包括手动分配和释放内存。这使得可以更精确地管理内存,减少不必要的内存开销。
- Java和.NET: 这些语言依赖于垃圾回收机制,由运行时环境负责管理内存。垃圾回收可能会引入一些不确定的延迟,以及与对象生命周期管理相关的运行时开销。
执行方式:
- C和C++: 编译型语言,代码直接编译成机器码,无需中间虚拟机的解释或即时编译。
- Java和.NET: 这些语言是解释型或即时编译型的,它们的代码通常在虚拟机上执行。虚拟机的运行时开销可能会导致性能损失。
直接硬件访问:
- C和C++: 提供了对硬件的直接访问,可以更细粒度地进行优化和控制。
- Java和.NET: 由于安全性和平台独立性的考虑,这些语言通常限制了对底层硬件的直接访问。
编译器优化:
- C和C++: 由于是编译型语言,编译器有更多的机会进行优化,包括静态分析和各种优化技术。
- Java和.NET: 即时编译器在运行时进行优化,但它可能无法进行与整个程序相关的优化,因为它只能看到程序的一部分。
需要注意的是,这并不是说Java和.NET一定性能较差。这些语言在许多应用场景中表现得非常出色,并且通过不断的优化和改进,它们在性能上的差距也在逐渐缩小。选择编程语言通常应该基于具体的需求和项目的特点,综合考虑开发效率、安全性、可维护性以及性能等因素。
编程语言类别
编程语言可以按照不同的准则进行分类。以下是一种通用的分类方式,将编程语言分为几大类:
按照执行方式分类:
- 编译型语言(Compiled Languages): 这类语言的源代码在运行之前需要通过编译器转换为机器码或中间代码。C、C++和Java(通过Java虚拟机的字节码)是编译型语言的例子。
- 解释型语言(Interpreted Languages): 这类语言的源代码在运行时由解释器逐行解释执行。JavaScript、Python和Ruby是解释型语言的例子。
- 即时编译型语言(Just-In-Time Compiled Languages): 这类语言是一种混合型,它们在运行时将源代码或中间代码即时编译为机器码。例如,Java的HotSpot虚拟机中的即时编译就是这样的一种机制。
按照应用领域分类:
- 通用编程语言(General-Purpose Languages): 这类语言设计用于解决各种问题,包括C、C++、Python和Java。
- 领域特定语言(Domain-Specific Languages,DSLs): 这类语言专门设计用于解决特定领域的问题,例如SQL用于数据库查询、HTML和CSS用于前端开发。
按照数据类型分类:
- 静态类型语言(Static Typing Languages): 这类语言要求在编译时明确指定变量的数据类型,例如C++、Java和C#。
- 动态类型语言(Dynamic Typing Languages): 这类语言在运行时确定变量的数据类型,例如JavaScript、Python和Ruby。
按照编程范式分类:
- 过程式语言(Procedural Languages): 这类语言的重点是过程和函数的调用,C就是一种典型的过程式语言。
- 面向对象语言(Object-Oriented Languages): 这类语言的设计思想是基于对象的概念,包括C++、Java、Python等。
- 函数式语言(Functional Languages): 这类语言强调函数的使用和函数式编程的理念,如Haskell、Scala和Clojure。
代码实现一个从源码到到AST再到Interpreter
通过上面的一个些概述我们了解了一些基本的编译语言的运行逻辑。我们一起动手实现一个简单的javascript解释器:
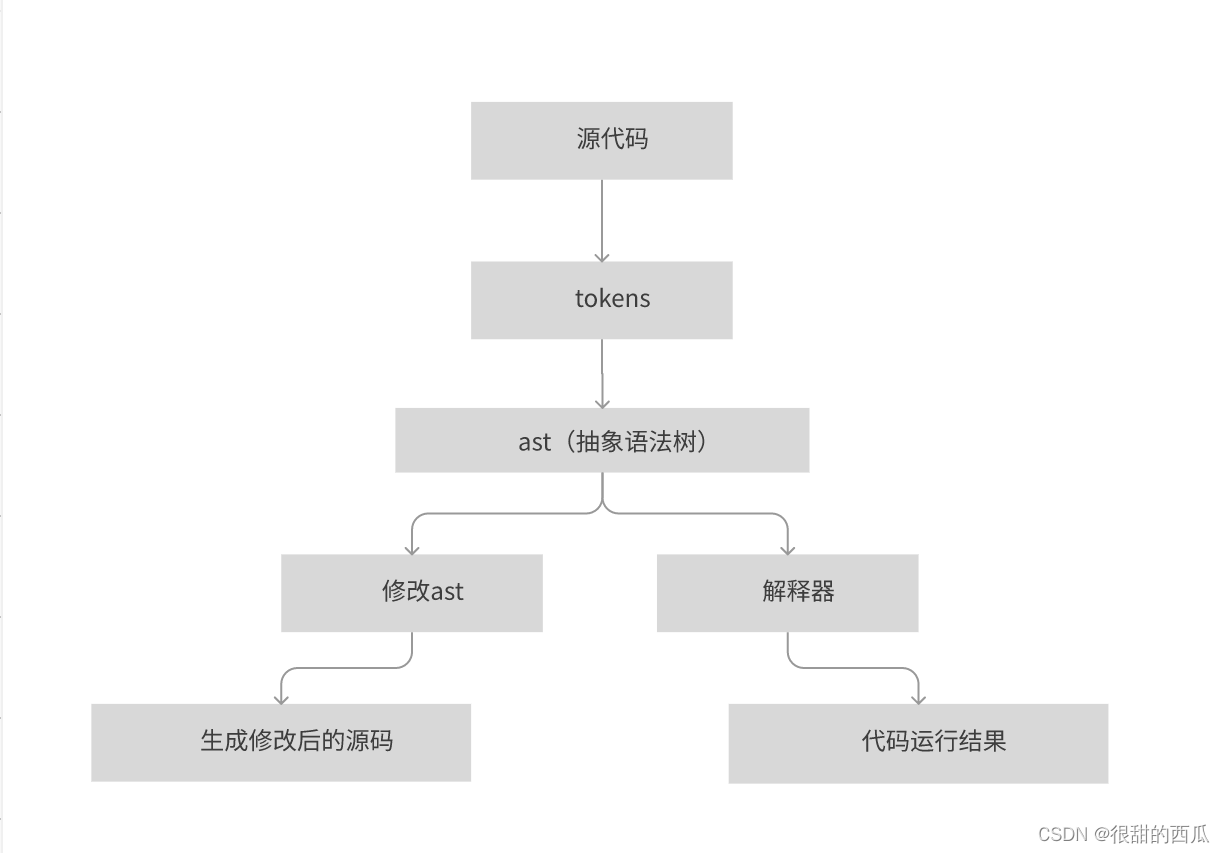
实现前,我们列一下具体要实现哪些步骤:
词法分析器(Lexer):
- 创建一个词法分析器,将 JavaScript 代码分解为标记(tokens)。标记是语法分析的基本单元,代表代码的不同部分,如关键字、标识符、运算符等。
语法分析器(Parser):
- 实现一个语法分析器,将标记序列转换为抽象语法树(AST)。AST是一个树状结构,反映了代码的语法结构。
执行器(Interpreter):
- 开发一个执行器,遍历抽象语法树并执行相应的操作。这可能涉及到变量存储、运算符处理、函数调用等。
支持基本语言特性:
- 实现一些基本的 JavaScript 特性,例如变量、数据类型、运算符等。逐步增加支持的语法和功能。
处理函数和作用域:
- 支持 JavaScript 的函数和作用域,这将涉及到函数声明、函数调用、闭包等概念。
请注意,这只是一个简单的起点。实际上,实现一个完整的 JavaScript 解释器需要考虑众多复杂的语言特性,包括原型链、异步操作、DOM 操作等。如果你的目标是学习和实验,可以逐步增加支持的功能。如果你的目标是创建一个可用的解释器,可能需要更深入的了解 JavaScript 语言规范和相关的计算机科学概念。
词法分析器(Lexer)
这一步主要是将输入的源码转换成程序更好识别的tokens)。
通过定义基本的词法规则,如果标识符Identity(变量)、运算符Operator(+、-、*、/)、关键字Keyword(if、for)
然后通过这些规则将源码变成tokens,看下代码可能你会更清楚。
// 代码的令牌标记,存储源码位置和描述了源码的用处
const token=(type,value,start)=>{
return {type,value,start}
}
/**
* 词法分析
* @param {string} source 源码
* @returns {Token[]}
*/
const lexer=(source)=>{
const tokens=[]
let pos=0,peekPos=pos,ch,value;
const length=source.length;
const digit_reg=/[0-9]/
const literal_reg=/[a-zA-Z_]$/
// 是否数字
const isDigit=(ch)=>{
return digit_reg.test(ch)
}
// 是否字母
const isLiteral=(ch)=>{
return literal_reg.test(ch)
}
const token=(type,value)=>{
tokens.push({type,value,start:peekPos})
}
const keywords={
let:true,
if:true,
for:true
}
while(pos<length){
peekPos=pos;
ch=source.charAt(peekPos)
// 空白、换行、逗号、分号就跳过
if(ch===' '||ch==='\n'||ch==='\t'||ch===','||ch===';'){
pos++
}else if(ch==='{'){
pos++
token('lbrace',ch) // 左大括号
}else if(ch==='}'){
pos++
token('rbrace',ch) // 右大括号
}else if(ch==='('){
pos++
token('lparen',ch) // 左小括号
}else if(ch===')'){
pos++
token('rparen',ch) // 右小括号
}else if(ch==='+'||ch==='-'||ch==='*'||ch==='/'){
pos++
value=source.charAt(pos)
if(value==='='||(ch==='+'||ch==='-')&&value===ch){
ch+=value
pos++
}
token('binaryExpression',ch)
}else if(isDigit(ch)){
// 数字
while(pos<length&&isDigit(source.charAt(pos))){
pos++
}
token('num',source.substring(peekPos,pos))
}else if(isLiteral(ch)){
pos++
while(pos<length&&(isLiteral(source.charAt(pos))||isDigit(source.charAt(pos)))){
pos++
}
value=source.substring(peekPos,pos)
if(value==='true'||value==='false'){
// 布尔类型
token('boolean',value)
}else if(keywords[value]){
// 关键字
token('keyword',value)
}else{
// 变量
token('identity',value)
}
}else{
pos++
}
}
token('eof') // 添加结束标识
return tokens;
}语法分析器(Parser)
语法分析就是把tokens转换成Ast抽象树,ast树最终用来给解释器去执行,你也可以用来做转译,把js转成c++ 或直接转译成机器码,都是可以的。
- 语法分析器(Parser)负责将 tokens 转换为抽象语法树。它根据语法规则和语法结构,将 tokens 组织成树状结构,反映源代码的语法关系。
- 常用的算法有递归下降解析器(Recursive Descent Parser)、LL(1)分析器、LR(1)分析器等。这些算法根据文法规则递归或迭代地构建语法树。
代码:
const parse=(tokens)=>{
const program={
type:'Program',
body:[]
}
let i=0,length=tokens.length
/**************定义ast节点******************/
// 标识符
const nodeIdentity=(name,start,end)=>{
return {type:'Identity',name,start,end}
}
// 多个变量,let a,b,c
const nodeMultipleVariableDeclarator=(kind,declarations,start,end)=>{
return {type:'VariableDeclaration',kind,declarations,start,end}
}
// 单个
const nodeVariableDeclarator=(id,init,start,end)=>{
return {type:'VariableDeclaration',id,init,start,end}
}
// 定义文本和数字 ast节点
const nodeNumericLiteral=(value,start,end)=>{
return {type:'Literal',value:parseFloat(value),raw:value,start,end}
}
// 一元或二元运算符
const nodeBinaryExpression=(operator,left,right,start,end)=>{
return {type:'BinaryExpression',operator,left,right,start,end}
}
// 表达式语句
const nodeExpressionStatement=(expression,start,end)=>{
return {type:'ExpressionStatement',expression,start,end}
}
// 块语句
const nodeBlockStatement=(body,start,end)=>{
return {type:'BlockStatement',body,start,end}
}
// for语句
const nodeForStatement=(init,test,update,body,start,end)=>{
return {type:'ForStatement',init,test,update,body,start,end}
}
/**************定义ast节点 end *******************/
const read=()=>{
return tokens[i]
}
// 解析语句 for()
const parseStm=()=>{
const expr=parseExpr()
if(expr){
return nodeExpressionStatement(expr,expr.start,expr.end)
}
}
// 解析表达式:let a
const parseExpr=()=>{
return parseAdditionAndMinus()
}
// 解析加减法:+ -
const parseAdditionAndMinus=()=>{
let left=parseMultiplyAndDivision()
let current=read()
while(current&&(current.type==='addition'||current.type==='minus')){
i++;
let right=parseMultiplyAndDivision()
left=nodeBinaryExpression(current.value,left,right,left.start,right?.end)
current=read()
}
return left
}
// 解析:* /
const parseMultiplyAndDivision=()=>{
let left=parsePrimitive()
let current=read()
while(current&&(current.type==='multiply'||current.type==='divide')){
i++
let right=parsePrimitive()
left=nodeBinaryExpression(current.value,left,right,left.start,right?.end)
current=read()
}
return left
}
// 解析原始类型:number string null undefined boolean symbol
const parsePrimitive=()=>{
let current=read()
if(current.type==='num'){
i++;
return nodeNumericLiteral(current.value,current.start,current.start+current.value.length)
}else if(current.type==='lparen'){
// ((a+b)*c) >
i++
let node= parseExpr()
let rparen=read()
i++;
return node
}else if(current.type==='eof'){
i++
}
return null
}
while(i<length&&tokens[i].type!=='eof'){
const stm=parseStm()
if(stm){
program.body.push(stm)
}
i++
}
if(program.body.length){
program.start=program.body[0].start
program.end=program.body[program.body.length-1].end
}
return program
}解释器(Interpreter)
如果不理解解释器,可以把它想像在打开chrome调试逐步JS代码时,右边有一个执行环境的上下文作用域和调用栈。我们鼠标移到变量上会展示变量的值。这就是解释器在运行的过程。
const a=123
let b=a;想像一下,这代代码怎么解释:首先ast的结构大概是这样,读取a的时,会把a的初始值存储当前作用域中,读取b的时候,会拿a在当前作域用中取。如果当前作用域没有定义a就去上一级作用域取
const ast=[
{
"type": "VariableDeclaration",
"start": 0,
"end": 12,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 11,
"id": {
"type": "Identifier",
"start": 6,
"end": 7,
"name": "a"
},
"init": {
"type": "Literal",
"start": 8,
"end": 11,
"value": 123,
"raw": "123"
}
}
],
"kind": "const"
},
{
"type": "VariableDeclaration",
"start": 13,
"end": 21,
"declarations": [
{
"type": "VariableDeclarator",
"start": 17,
"end": 20,
"id": {
"type": "Identifier",
"start": 17,
"end": 18,
"name": "b"
},
"init": {
"type": "Identifier",
"start": 19,
"end": 20,
"name": "a"
}
}
],
"kind": "let"
}
] const interpreter=(program)=>{
const env={
}
const evalExpr=(node)=>{
if(node.type==='BinaryExpression'){
return evalBinaryExpression(node)
}else if(node.type==='Literal'){
return evalLiteral(node)
}
}
const evalLiteral=(node)=>{
return node.value
}
const evalBinaryExpression=(node)=>{
const operator=node.operator
if(operator==='+'){
return evalExpr(node.left)+evalExpr(node.right)
}else if(operator==='-'){
return evalExpr(node.left)-evalExpr(node.right)
}else if(operator==='*'){
return evalExpr(node.left)*evalExpr(node.right)
}else if(operator==='/'){
return evalExpr(node.left)/evalExpr(node.right)
}
}
const evalExprStm=(node)=>{
const expression=node.expression
return evalExpr(expression)
}
const evalExprProgram=(node)=>{
const body=node.body;
let result;
for(let i=0;i<body.length;i++){
result=evalExprStm(body[i])
}
return result
}
return evalExprProgram(program)
}
代码生成器(Code Generator)
一般我们写一个Babel插件,Babel插件中有一个visitor对象,也是基于访问者模式,我们想改变某个ast节点时,只需要定义相应的类型名,直接修改ast结构。最终Babel内部会有一个Babel/Generator生成最终修改的源码
const codeGen=(ast)=>{
// 访问者模式,DFS
const visit={
Program(node,ctx){
const body=node.body
for(let i=0;i<body.length;i++){
gen(body[i],ctx)
}
},
ExpressionStatement(node,ctx){
const expression=node.expression
gen(expression,ctx)
},
Literal(node,ctx){
//let parent=ctx.parents[ctx.parents.length-1]
ctx.source.push(node.value)
},
BinaryExpression(node,ctx){
let parent=ctx.parents[ctx.parents.length-2]
let paren=false
// 重新定义括号内的表达式的优先级
if(parent&&(parent.operator==='*'||parent.operator==='/')&&(node.operator==='+'||node.operator==='-')){
paren=true
}
if(node.left){
paren&&ctx.source.push('(')
gen(node.left,ctx)
}
ctx.source.push(node.operator)
if(node.right){
gen(node.right,ctx)
paren&&ctx.source.push(')')
}
}
}
const ctx={
parents:[],
source:[]
}
const gen=(node,ctx)=>{
const handle=visit[node.type]
if(handle){
ctx.parents.push(node)
let result=handle(node,ctx)
ctx.parents.pop()
if(result){
gen(result)
}
}
}
gen(ast,ctx)
return ctx.source.join(' ')
}
测试例子
const code=`10+(((10+20)-5)*5)*8+50`
const tokens=lexer(code)
const ast=parse(tokens)
console.log('tokens',tokens) // 生成tokens
console.log('ast',ast) // ast
console.log('custom-code',codeGen(ast)) // 通过ast还原源码
// 解释器执行代码,输出结果
console.log('interpreter-result',interpreter(ast)) // 输出:1060
console.log('eval-result',eval(code)) // 输出 1060