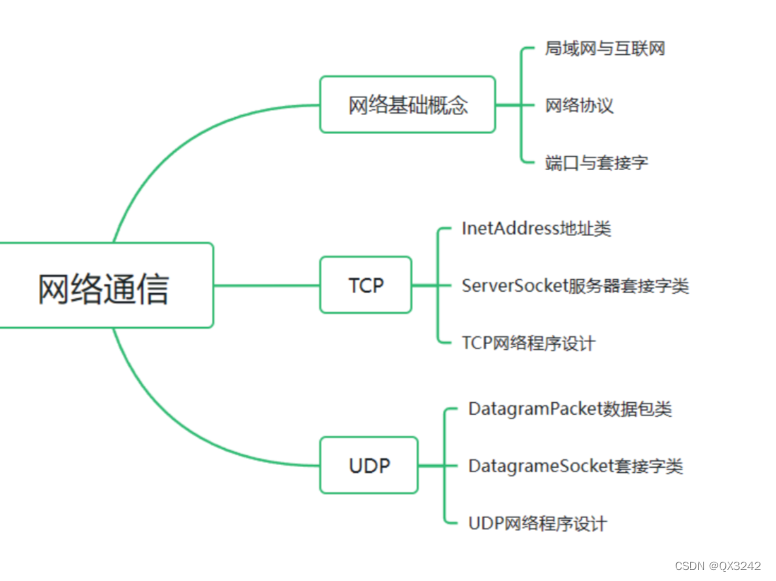
文章目录
进程和线程的概念
在Windows中提出了线程的概念,后来Linux进行了引入,但是Linux内核中并没有线程,即:Linux没有实际上的线程,Linux中的线程实际上仍是进程,但是它达成了和Windows中相同的效果。
进程和线程的区别
- 进程拥有自己独立的地址空间,多个线程共用一个地址空间
- 线程更加节省资源,效率不仅可以保持,而且能够更高
- 在一个地址空间中多个线程独享:每个线程都有属于自己的栈区、寄存器
- 在一个地址空间中多个线程共享:代码段、堆区、全局数据区,打开的文件(文件描述符)都是线程共享的
- 线程是程序中最小的执行单位,进程是操作系统中最小的资源分配单位
- 每个进程对应一个虚拟地址,一个进程只能抢一个CPU时间片
- 一个地址空间中可以划分出多个线程,在有效的资源基础上,能抢更多的CPU时间片
- CPU的调度和切换:线程的上下文切换1要比进程快得多
- 线程更加廉价,启动速度更快,退出也快,对系统资源的冲击小。
在处理多任务程序的时候使用多线程比使用多进程要更有优势,但是线程并不是越多越好,如何控制线程的个数?
- 文件IO操作:文件IO对CPU使用率不高,因此可以使用分时复用CPU时间片,线程个数 = 2 * CPU核心数(效率最高)
- 处理复杂的算法(主要是CPU进行计算,压力大),线程的个数 = CPU的核心数(效率最高)
C++多线程的基本内容
创建线程std::thread
创建线程的时候需要传入一个函数指针作为线程的运行函数:
#include <thread>
void func(){
std::cout << "Hello Thread! <<std::endl;
}
int main(){
// 线程创建启动
std::thread th1(func);
// 主线程阻塞等待子线程退出
th1.join();
}
其中,用到了函数join,它的作用是:使主线程阻塞等待子线程退出。因为主线程在子线程之前退出会将进程的资源释放,这会导致子线程无法访问资源。
线程ID
每个线程都有一个独一无二的线程ID,在线程中我们可以获得该线程的线程ID:(std::this_thread::get_id())
#include <iostream>
#include <thread>
void func(){
std::cout << "This thread's Thread_ID is: " << this_thread::get_id() << std::endl;
}
int main(){
std::thread th1(func);
th1.join();
}
std::thread对象生命周期和线程等待和分离
之前我们程序运行的时候使用了[[#创建线程std thread|join]],但是这里有个问题:它使得主线程阻塞等待子线程运行完毕再运行,因此没达到线程并行运行的目的,想要主线程和子线程同时运行我们就不能够使用join,而应该使用函数detach,detach的作用是:将子线程与主线程分离,分离后的子线程在后台运行,这个子线程也叫做“守护线程“。
但是,使用detach也有跟刚刚一样的问题:主线程若是在子线程结束前退出,资源被释放导致程序出错。
但是这个问题又不是一定会出现,在[[#进程和线程的概念]]中我们说到,子线程也有自己的资源:栈、寄存器,因此它只要不访问外部资源,即使主线程先于子线程退出它也不会出错。
线程参数传递引用类型
这里我们给出一段示例代码引出问题:
#include <thread>
#include <iostream>
void func(int& a){
std::cout << a;
}
int main(){
int temp = 100;
std::thread th(func, temp);
}
这样写不仅程序运行不起来,报的错也是莫名其妙的(至少我看不懂),这时就要使用std::ref了。
这是因为thread使用了模板特性,而使用了模板的函数想要使用引用传参就需要使用std::ref,因为函数模板的参数类型是编译期确定的,如果参数类型是引用并且直接传递,编译器会无法确定编译器是传递其引用或是拷贝,这就出错了。
因为编译器在编译期推断模板的参数类型的时候会忽略参数的引用性质,而错误的传递参数的实际类型。因此需要使用引用包装器std::reference_wrapper对引用进行一个包装,将引用类型包装在引用包装器中,传递的类型为引用包装器就不会出错。
因此上面的代码要更改为:
#include <iostream>
#include <thread>
void func(int& a){
std::cout << a;
}
int main(){
int temp = 100;
std::thread th(func, std::ref(temp));
}
成员函数作为线程入口和线程基类的封装
示例代码如下:
#include <iostream>
#include <thread>
#include <string>
class MyThread{
public:
void Main(){
std::cout << "MyThread Main" << this->name << " : " << age;
}
std::string name = "";
int age = 100;
};
int main(){
MyThread myth;
myth.name = "Test name 001";
myth.age = 20;
// 传递成员函数的指针和被调用的对象的地址
std::thread th(&MyThread::Main, &myth);
th.join();
return 0;
}
这里没什么需要过多解释的,有疑惑的应该只有创建线程时的传参吧。
现在我们就来解释为什么需要这么传参:
- 第一个参数:这个应该比较好理解,因为thread传参传入函数名实际上就是传入函数的地址,这是这里写的比较详细:首先使用作用域运算符规定了函数的位置,再使用取地址符显式传参。
- 第二个参数:为什么需要传入这个实例化对象呢?因为在函数MyThread::Main中使用了this指针,this指针是谁调用就指向谁,若是我们只传入函数对象,那么其中的this就是无指向的,这也就出错了。传入这个参数的作用就是规定this的指向。
lambda临时函数作为线程入口函数
lambda函数
在先前的文章中已经说过了lambda函数,这里再说一遍吧:
// lambda函数
// []:“捕获列表”,有两种形式:值捕获(=)和引用捕获(&),对应的就是函数的值传递和引用传递
// 默认情况下是值捕获,即拷贝一个副本,并且值捕获的时候[]可以是空的
// 引用捕获就是写上&
// 同时我们还可以在[]中指定捕获的对象,例如:[&temp]
// 若是[]中没有任何东西,就是“无捕获”的意思
// ():还是叫“形参列表”,作用也跟普通的函数一样
// mutable:其的意思就是可变,这个很简单,但是我们什么时候需要使用它呢?
// lambda捕获列表所捕获的变量在默认情况下都是不可变的(const)
// 这一点不管是值捕获还是引用捕获
// ->value_type:它用于指定函数的返回值类型
// 在C++11及其之前,lambda函数必须要指定其返回类型,例如:->int
// 但是在C++14之后就可以不写了,它会根据lambda函数的return语句自动推断返回值类型
// 这里的value_type可以使用decltype(expression)进行类型推断
auto func = []()mutable->value_type{
function_body;
}
lambda线程
先说说它最普通的用法,也就是在main函数中用于启动线程鸟哥的时候。
这里给出一段示例代码:
#include <thread>
#include <iostream>
#include <string>
int main(){
std::thread th([](const std::string& text){
std::cout << text << std::endl;
},
"Hello World"
);
th.join();
}
很容易就能理解,它本质上和使用一般的函数对象作为参数是一样的。这里需要强调的是lambda作为类的成员函数用于启动线程:
#include <thread>
#include <iostream>
#include <string>
class MyThread{
public:
void start(){
std::thread th([](){
std::cout << "this Thread's name is: " << this->name << std::endl;
});
th.join();
}
private:
std::string name = "Lambda Thread";
};
int main(){
MyThread temp;
temp.start();
}
这段代码放到编译器中会有报错,报错是在this上,内容是:
封闭函数“this”不能在 lambda 体中引用,除非其位于捕获列表中。
也就是说,在这个lambda表达式中找不到this指针,因此,我们需要手动将this指针加入捕获列表,也就是将lambda表达式更改为:
[this](){
std::cout << "this Thread's name is: " << this->name << std::endl;
}
除了这种改法,在捕获列表中写上"=“或者”&"都是可以的。
需要注意的是:我们不能够引用捕获this指针,也就是不能够写成[&this]。这是因为this指针是一个抽象的概念(一个隐式指针),它是无实体的,不是一个具体的对象,它也只有在成员函数被调用的时候才具有意义。
多线程同步和通信
多线程通信
线程状态说明
接下来都是些理论性的东西:
- 初始化(Init):该线程正在被创建
- 就绪(Ready):该线程正在就绪列表中,等待CPU调度
- 运行(Running):该线程正在运行
- 阻塞(Blocked):该线程正在被阻塞挂起。Blocked状态包括:pend(锁、事件、信号量等阻塞)、suspend(主动pend)、delay(延时阻塞)、pendtime(因为锁、事件、信号量等时间超时等待)
- 退出(Exit):该线程运行结束,等待父线程回收其控制资源块
竞争状态(Race condition)和临界区(Critical Section)
- 竞争状态:多线程同时读写共享数据
- 临界区:读写贡献数据的代码片段
为了避免数据访问冲突,我们就需要避免竞争状态。常用的方法是使用C++所提供的互斥锁或者互斥体对临界区进行加锁操作。
互斥锁mutex
这个需要使用同名头文件mutex,它可以将临界区上锁,使得临界区的数据访问在同一时间只能有一个线程参与,这里给出一个简短的示例代码:
#include <iostream>
#include <thread>
void func(){
std::cout << "Hello World" << std::endl;
}
int main(){
for(int temp=0; temp<10; temp++){
std::thread th(func);
th.detach();
}
}
我们希望输出十行"Hello World",并且每输入完一行就换行一次。
但是这段代码的实际输出结果一般都不是很规整,这就是因为存在临界区,在这里临界区就是“Hello World”输出语句。
于是我们可以使用互斥锁mutex进行上锁操作,代码如下:
#include <mutex>
#include <thread>
#include <iostream>
static std::mutex mtx;
void func(){
mtx.lock();
std::cout << "Hello World" << std::endl;
mtx.unlock();
}
int main(){
for(int temp=0; temp<10; temp++){
std::thread th(func);
th.detach();
}
}
现在虽然输出很规整了:每输出一行“Hello World”就会换行一次,但是还是有一点问题:“Hello World”没有输出10次,这就是主线程先于子线程退出导致的,怎么解决这里先不说。
说说原理吧:我们创建了一个互斥锁mtx,并且在使用了lock函数对临界区进上锁,在临界区代码执行完毕之后使用unlock进行解锁。其实上锁操作就是使线程阻塞运行:当一个线程获取到了互斥锁之后,其他线程尝试获取该锁时会被阻塞,直到锁被解除。
try_lock()
在上文中我们已经说了函数lock()的使用,还有一个和它功能类似的函数:try_lock,它的作用就是:尝试去获取互斥锁的所有权。我们看看它的函数声明:
template< class Lockable1, class Lockable2, class... LockableN >
int try_lock( Lockable1& lock1, Lockable2& lock2, LockableN&... lockn );
bool try_lock();
前者稍微更复杂一点,我后续会补充,我就先不做解释,先说后者吧:
它尝试获取互斥锁的所有权,如果成功获取则返回true,获取失败就返回false。
超时锁timed_mutex
超时锁tiemd_mutex能够使用函数try_lock_for对锁在规定的时间内反复尝试上锁。示例代码如下:
#include <chrono>
#include <thread>
#include <mutex>
#include <iostream>
std::timed_mutex mtx;
void func(int val){
for(; ; ){
// 如果没有成功获取锁,就在指定时间内反复尝试
if(!mtx.try_lock_for(std::chrono::milliseconds(1000))){
// 一行输出日志
std::cout << "[try to lock]" << std::endl;
}
// 成功获取到了锁
else{
std::cout << val << "[in]" << std::endl;
// 模仿业务,等待一段时间
std::this_thread::sleep_for(std::chrono::milliseconds(200));
mtx.unlock();
// 在互斥锁解锁后不能立马上锁(此处会立马进入下次循环)
// 立马上锁会导致其他线程无法获取互斥锁所有权
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
}
int main(){
for(int temp=1; temp<=3; temp++){
std::thread th(func, temp);
th.detach();
}
getchar();
}
超时锁没有什么太过特别的地方,只是说它支持时间操作,只要是支持时间操作的锁就能够使用try_lock_for。
递归锁(recursive_mutex)和recursive_timed_mutex
普通的锁(也就是mutex)在一个线程中只能获取一次它的所有权,如果该线程已经拥有mutex的所有权但是却再次加锁,这就会导致程序报错。例如:
#include <mutex>
#include <thread>
#include <iostream>
std::mutex mtx;
void func(){
mtx.lock();
mtx.lock();
std::cout << "Hello World" << std::endl;
mtx.unlock();
mtx.unlock();
}
int main(){
std::thread th(func);
}
在func中,我们对程序做了重复加锁的操作,编译器不会报错,程序也能运行,但是终端中并不会输出我们想要的结果,而是会输出:
terminate called without an active exception
这行报错的意思是:“程序在没有活动异常的情况下被强制终止执行”。
在这种情况下,我们就需要使用recursive_mutex了,即:同一个线程中,同一把锁可以锁多次。
recursive_mutex的内部维护了一个计数器,每次加锁时加一,每次解锁时减一,这里就又有个问题:计数器只有在0的时候,其他线程才能获取该互斥锁的所有权,正数和负数都是不行的,因此它锁几次就要解锁几次。
这里给出一个新的例子:
#include <iostream>
#include <mutex>
#include <thread>
std::recursive_mutex mtx;
void func1(){
mtx.lock();
std::cout << "[func1 is running]" << std::endl;
mtx.unlock();
}
void func2(){
mtx.lock();
std::cout << "[func2 is running]" << std::endl;
mtx.unlock();
}
void ThreadMain(){
// ThreadMain函数用于处理业务逻辑
mtx.lock();
func1();
func2();
mtx.unlock();
}
int main(){
std::thread th(ThreadMain);
th.join();
}
在线程th的业务处理函数ThreadMain中,使用了lock和unlock对func1和func2,但是同时func1和func2中也进行了加锁操作,这样就会面临一个重复加锁问题,这时候就需要使用recursive_mutex。
共享锁shared_mutex
这里我先不说过多,我多线程还是希望以11为主,因为现在主流还是11,14、17用的相对来说都少很多。
- C++14共享超时互斥锁:shared_timed_mutex
- C++17共享互斥shared_mutex
- 如果只有写时需要互斥,读取时不需要,用普通的mutex如何做?
利用栈的特性自动释放锁:RAII
RAII(Resource Acquisition Is Initialization)是使用局部对象管理资源的技术,即:资源获取即初始化,它的生命周期有操作系统管理,不允许人工介入,资源的销毁容易忘记,造成死锁或内存泄漏。
C++提供的RAII:lock_guard
这是最基础的互斥体所有权包装器
- C++11实现严格基于作用域的互斥体所有权包装器
- adopt_lock C++11类型为adopt_lock_t,假设调用方已拥有互斥锁的所有权
- 通过{}(作用域)控制锁的临界区
template<typename _Mutex>
class lock_guard
{
public:
typedef _Mutex mutex_type;
explicit lock_guard(mutex_type& __m) : _M_device(__m)
{
_M_device.lock(); }
lock_guard(mutex_type& __m, adopt_lock_t) noexcept : _M_device(__m)
{
} // calling thread owns mutex
~lock_guard()
{
_M_device.unlock(); }
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
private:
mutex_type& _M_device;
};
这是gcc编译器中,lock_guard的声明,我们可以发现,它使用了模板,可以指定mutex的种类,像之前提到的:shared_mutex、timed_mutex都可以。
可以看到它的原理其实很简单:在构造函数中lock(),在析构函数中unlock(),理解了它的原理使用起来肯定也不算难。
#include <mutex>
#include <thread>
#include <chrono>
#include <iostream>
static std::mutex mtx;
void func(const int& val){
while(true){
{
// 使用lock_guard进行自动上锁和自动解锁
std::lock_guard<std::mutex> lock_g(mtx);
std::cout << "Thread " << val << " is running" << std::endl;
}
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
int main(){
for(int temp=1; temp<=3; temp++){
std::thread th(func, temp);
th.detach();
}
getchar();
}
C++11的unique_lock
在上节我们说了最基本的互斥体所有权包装器lock_guard,它的功能十分的简单,仅仅是在其构造函数中调用lock()在析构函数中调用unlock(),C++11提供了更高级的一个包装器:unique_lock。
- unique_lock是C++11实现的可移动的互斥体所有权包装器
- unique_lock支持临时释放锁(unlock()后注意要重新lock())
- unique_lock支持adopt_lock(已经拥有锁,不加锁,出栈区会释放)
- unique_lock支持defer_lock(延后拥有,不加锁,出栈区不释放)
- unique_lock支持try_to_lock尝试获得互斥体的所有权而不阻塞,获取失败退出栈区也不会释放,通过owns_lock()函数判断
基础用法和lock_guard是一样的,就不多说了,高级内容后面我再补充,它能够传入一些参数,根据传入的参数不同可以做不同的操作。
结尾
但是只知道这些我们还是不能够写出C++多线程程序,我们还需要学习条件变量和原子操作,这两部分我将后续写单独的文章进行说明。
C++11条件变量condition_variable
进程/线程分时复用CPU时间片,在切换之前会将上一个任务的状态进行保存,下次切换这个任务的时候,加载这个状态继续运行,任务从保存到再次加载这个过程就是一次上下文切换。 ↩︎