目录
一、赛题数据
赛题地址:
零基础入门CV - 街景字符编码识别_学习赛_天池大赛-阿里云天池的赛制 (aliyun.com)
赛题数据来源自Google街景图像中的门牌号数据集(The Street View House Numbers Dataset, SVHN),并根据一定方式采样得到比赛数据集。
数据集报名后可见并可下载,该数据来自真实场景的门牌号。训练集数据包括3W张照片,验证集数据包括1W张照片,每张照片包括颜色图像和对应的编码类别和具体位置;为了保证比赛的公平性,测试集A包括4W张照片,测试集B包括4W张照片。数据下载可以报名后自行去下载。
所有的数据(训练集、验证集和测试集)的标注使用JSON格式,并使用文件名进行索引。如果一个文件中包括多个字符,则使用列表将字段进行组合。
| Field | Description |
|---|---|
| top | 左上角坐标Y |
| height | 字符高度 |
| left | 左上角坐标X |
| width | 字符宽度 |
| label | 字符编码 |
二、下载数据集
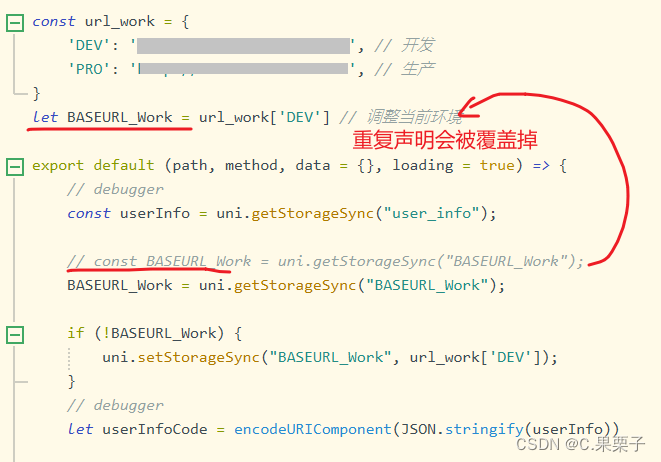
一开始自己手动下载数据集并解压,没有发现问题,直到写完模型训练的时候,发现数据集不齐的情况(至今也不知道什么原因QAQ)。自动下载解压可以看如下代码:
import pandas as pd
import os
import requests
import zipfile
import shutil
links = pd.read_csv('./content/mchar_data_list_0515.csv')
dir_name = 'NDataset'
mypath = './content/'
if not os.path.exists(mypath + dir_name):
os.mkdir(mypath + dir_name)
for i,link in enumerate(links['link']):
file_name = links['file'][i]
print(file_name, '\t', link)
file_name = mypath + dir_name + '/' + file_name
if not os.path.exists(file_name):
response = requests.get(link, stream=True)
with open( file_name, 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
zip_list = ['mchar_train', 'mchar_test_a', 'mchar_val']
for little_zip in zip_list:
if not os.path.exists(mypath + dir_name + '/' + little_zip):
zip_file = zipfile.ZipFile(mypath + dir_name + '/' + little_zip + '.zip', 'r')
zip_file.extractall(path = mypath + dir_name )
if os.path.exists(mypath + dir_name + '/' + '__MACOSX'):
shutil.rmtree(mypath + dir_name + '/' + '__MACOSX')运行结果:
三、Baseline简介
刚入手时,查看官网提供的baseline是入门的最好方法。
传送门:Datawhale 零基础入门CV赛事-Baseline-天池实验室-实时在线的数据分析协作工具,享受免费计算资源
运行模型的时候需要注意地址匹配。
下面简单介绍一下baseline的思路:
1、加载数据dataloader
以加载train_loader为例:
train_loader = torch.utils.data.DataLoader( #DataLoader作为pytorch中一个加载数据集的类。
SVHNDataset(train_path, train_label, #传入训练路径,训练标签。
transforms.Compose([
transforms.Resize((64, 128)), #调整图像大小为 (64, 128) 像素。
transforms.RandomCrop((60, 120)), #随机裁剪图像至 (60, 120) 像素大小。
transforms.ColorJitter(0.3, 0.3, 0.2), #随机调整图像的亮度、对比度和饱和度。
transforms.RandomRotation(10), #对图像进行最多 10 度的随机旋转,增加数据多样性。
transforms.ToTensor(), #将图像数据转换为 PyTorch 张量,以便深度学习模型处理。
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) #归一化
])),
batch_size=40, #指定每个数据批次加载器加载的样本数为40个。
shuffle=True, #在每个训练周期中随机打乱数据顺序。打乱数据有助于防止模型过度拟合到训练样本的顺序。
num_workers=10, #并行加载数据的工作进程数
)其中,在PyTorch中,transforms 是一个常用的模块,用于定义和应用各种数据转换。
transforms.Compose([...]) 创建了一个包含多个数据转换的列表,这些转换将按照列表中的顺序依次应用于输入的图像数据。每个转换都以 transforms. 开头,表示它们属于 PyTorch 的数据转换模块。
2、模型的建立(ResNet18)
baseline中使用resnet18网络结构,下面附上残差网络ResNet各种层数的结构如下:

因为resnet18是最基础的残差网络,下面仅介绍resnet18中主要的代码结构。
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
#使用resnet18预训练模型
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
#全连接层
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
#前向传播
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5#model_conv = models.resnet18(pretrained=True)
代码使用
resnet18函数创建了一个 ResNet-18 模型,并设置了pretrained=True,表示使用预训练的权重。预训练的权重意味着该模型已经在大规模图像数据上进行了训练,因此具有良好的特征提取能力。
#model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
原始的 ResNet-18 模型包含一个全局平均池化层(Global Average Pooling),用于将最后一个卷积层的特征图转换为一个固定大小的特征向量。这一行代码修改了平均池化层,修改为自适应平均池化,并将特征图的大小调整为 (1, 1)。
#model_conv = nn.Sequential(*list(model_conv.children())[:-1])
这行代码创建了一个新的模型,模型包括model_conv中除了最后一层的所有层。这种做法皆在于通过前面的层进行特征提取。
3、损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), 0.001)baseline中使用交叉熵损失作为损失函数,交叉熵损失在分类预测中具有突出的效果。
baseline中使用Adam作为优化器,Adam作为一种常用的梯度下降算法的变种,通常具有很好的性能。其中,学习率为0.001.
4、结果分析
运行官网提供的baseline,在阿里云天池平台提交后,score为0.3532(10个epoch),可见效果并不是很好。
四、改进一
#optimizer = torch.optim.Adam(model.parameters(), 0.001)
优化器默认的是学习率恒为0.001,根据梯度下降算法,通过将学习率设置为随着梯度更新,学习率递减的方法,有利于尽快收敛。
#scheduler = CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
这行代码创建了一个学习率调度器,并赋值给scheduler,其中使用了余弦退火学习率调度器。
余弦退火学习率调度器:学习率会在每个周期结束时按照余弦函数的形状进行更新,逐渐减小,直到达到指定的最小值。然后,它将重置并再次开始余弦退火。这个过程会在指定的周期数内不断重复,直到训练结束。 余弦退火学习率调度器有助于帮助模型跳出局部极小值,获得更好的性能。
optimizer = torch.optim.Adam(model.parameters(), 0.001)
#余弦退火调度器
scheduler = CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
#另外,需要再每个训练周期或者迭代结束后,动态的更新学习率调度器
train_loss = train(train_loader, model, criterion, optimizer, epoch)
scheduler.step()
在阿里云天池平台提交后,score为0.4703(10个epoch),可见效果有所改进。
五、改进二
class SVHN_Model1(nn.Module):
def __init__(self, smoothing=0.1):
self.smoothing = smoothing
super(SVHN_Model1, self).__init__()
#使用resnet18预训练模型
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
#全连接层
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
#引入标签平滑
new_c1 = (1.0 - self.smoothing) * c1 + self.smoothing / 11
new_c2 = (1.0 - self.smoothing) * c2 + self.smoothing / 11
new_c3 = (1.0 - self.smoothing) * c3 + self.smoothing / 11
new_c4 = (1.0 - self.smoothing) * c4 + self.smoothing / 11
new_c5 = (1.0 - self.smoothing) * c5 + self.smoothing / 11
return new_c1, new_c2, new_c3, new_c4, new_c5标签平滑是一种正则化技术,通过改变类别的概率分别,即降低类别高的概率值,增加类别低的概率值, 来减轻模型对于标签的过度自信。标签平滑的参数可以通过交叉验证方式进行选择。
通过引入标签平滑,精度大约有几个百分点的提升,可见要想快速提升精度,还需要做一步改进。
下一步将会从模型的选择和算法进行改进,尝试ResNet50和目标检测算法RCNN、YOLO系列。