C++ new表达式
C++语言规范中,new表达式的形式如下:
::opt new new-placementopt new-type-id new-initializeropt ::opt new new-placementopt ( type-id ) new-initializeropt |
不要被上面的样子唬到,在实际使用当中,不会写的这么复杂。通常,你见到的是这样的:
// 单个对象 string *obj = new string; // 一组对象 string *array = new string[8]; |
或者是这样的(placement new):
// 自己分配内存 void *mem = malloc(sizeof(string) * 16); // 单个对象 string *obj = new(mem) string; // 一组对象 string *array = new(mem) string[8]; |
new表达式主要是做了两件事情:
1、动态分配内存;
2、对分配的内存做初始化。
这两件事情,我们可以交给语言缺省处理,当然也可以通过自定义的方式进行参与:
1、内存可以自行分配和管理,例如:为了提升性能,自行实现了内存池;
2、实现对象的构造函数,配合new的调用方式,控制内存的初始化行为。
关于对象
关于内存的分配和管理,不做展开。另外,还需把讨论的“对象”再细化,本文所关注的“对象”,是可以无参数构造的。例如:
struct A { int a_; }; struct B { int b_; B() = default; }; struct C { int c_; C() {} }; struct D { int d_; D(): d_(10) {} }; struct E { int e_; E(int e = 99): e_(e) {} }; |
之所以要限定这种“对象”,是因为这种类型的“对象”与new不同调用方式的结合后,会容易让人困扰,不清楚到底发生了什么,某些情况下的表现甚至会让人吃惊。
从现象开始
大家在写new的时候,很可能存在如下两种写法:
A *pa1 = new A; A *pa2 = new A(); |
不知道大家是否清楚这其中的差异?是知晓其差异,根据实际需要有选择的使用?或是认为反正都差不多,混着用?
我们从性能表现上入手,看一下这两者到底是否有差异。测试使用如下的数据结构,对于两种new方式分别运行32M次(1M=1024*1024)
struct A { int a_; }; // new方式1 A *pa1 = new A; // new方式2 A *pa2 = new A(); |
测试结果如下,单位为纳秒(因测试结果依赖于环境,因此请关注两者性能的相对差异,而非绝对数值)
未优化编译 |
|
new A |
263,894,340 |
new A() |
491,652,820 |
在未开优化编译的情况下,两者都有接近一倍的性能差异(更别提优化的情况了),可见两者的行为是不同的。
对比汇编代码(如下所示),可以看到,两种方式在调用完new函数(call _ZnwmPv)后,使用new A()方式的代码,多了一条关键性的指令:movl $0, (%rax)。这说明new A()这种方式,会对内存做清零的操作,而new A这种方式却不会。


由此,我们似乎可以得到一个结论:new对象时,加或者不加括号,其行为是不同的。加了括号会对内存“清零”。但是,我们不禁也会产生一个疑问,一个mov指令真的会这么耗时吗?
初始化
对于new A或者new A()这两种不同的方式,其实在C++语言中,是有规范可循的。语法规定如下:一个是缺省初始化,一个是值初始化。
new A |
Default initialization |
new A() |
Value initialization |
- 缺省初始化
1、对于非POD(Plain Old Data)类型,会使用该类型的无参数构造函数;
2、如果是内置类型或者POD类型,不做初始化。
- 值初始化
1、如果无参数构造函数是trivial范畴的,做“清零”初始化;
2、否则就使用无参数构造函数做初始化。
以上是笔者对于规范的解读,而非翻译。不过,可能还是不太容易理解,下面就以示例来说明。示例会对不同的类型,分别使用两种方式做初始化。为了演示效果,使用placement new的形式,预先把内存值置成0xee,然后在该内存上做初始化,再打印内存值以观察效果。
- 不写构造函数
struct A1 { int a11_; int a12_; }; // new A1: ee ee ee ee ee ee ee ee // new A1(): 00 00 00 00 00 00 00 00 |
2.缺省构造函数
struct A2 { int a21_; int a22_; A2() = default; }; // new A2: ee ee ee ee ee ee ee ee // new A2(): 00 00 00 00 00 00 00 00 |
3.空实现构造函数
struct A3 { int a31_; int a32_; A3() {} }; // new A3: ee ee ee ee ee ee ee ee // new A3(): ee ee ee ee ee ee ee ee |
4.普通构造函数
struct A4 { int a41_; int a42_; A4(int b = 0x66666666): a41_(b) {} }; // new A4: 66 66 66 66 ee ee ee ee // new A4(): 66 66 66 66 ee ee ee ee |
对于1和2,可以理解为是POD类型,或者是带有一个trivial构造的类型,因此new T不会有初始化动作,而new T()做了清零操作。对于3和4,则是一个带有非trivial(明确定义了初始化该怎么做)构造的类型,因此new T和new T()都使用了该构造做初始化。
那么,为什么需要“纠结”这些细节的差异呢?再次回到new表达式上来,之前提过,new表达式的作用是:
1、申请内存
2、做初始化
对于申请内存,可以由语言缺省处理,或者自行管理,所以内存是一定需要的。但是,“初始化”这一步,要与不要,是可以选择的。
从之前的性能对比中可以看到,“初始化”动作可以是相当耗时的,因此我们还是需要根据实际情况,主动的去选择正确的操作,而不会因为语法上细微的差异导致我们在不经意之间被“误伤”。
内存访问
前面还留下一个疑问需要解释,就是清零用的mov指令,真的有那么耗时吗?答案是:得看具体场景具体分析,没有一个统一的标准答案。
对象初始化时的清零操作,其实是一个写内
movl $0, (%rax) |
存的操作,这已不再是C++语言层面的事了,需要到系统层面来看一看。
这条指令是由CPU来执行的,所以从CPU为起点来讨论内存是如何访问的,CPU通常有多级缓存,所以CPU对内存的操作最终都化为了对缓存的操作,但是为了简单起见,不引入缓存,还是直接讨论内存。
CPU访问内存,分为快速通道和慢速通道,
- 快速通道
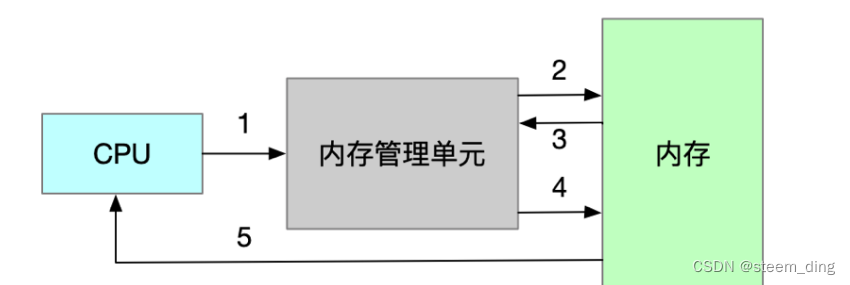
1、CPU把需要访问的内存地址告诉内存管理单元(此处的地址是虚拟地址,而非物理地址)
2、内存管理单元查询地址转换表(虚拟地址转换为物理地址,该表在内存中)
3、内存把物理地址返回给内存管理单元
4、内存管理单元告诉内存要访问的地址
5、内存把该地址上的数据返回给CPU
- 慢速通道
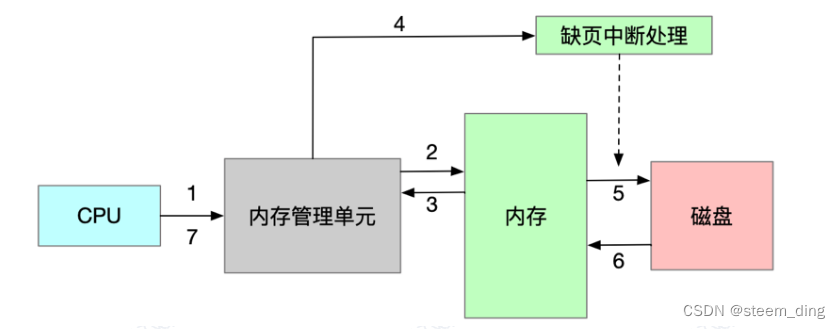
1、CPU把需要访问的内存地址告诉内存管理单元
2、内存管理单元查询地址转换表
3、内存把物理地址返回给内存管理单元
4、内存管理单元发现这是一个非法的物理地址(如:该地址非本进程使用,或未分配物理页),继而触发缺页中断异常,转交内核处理
5、内核会分配物理页,如果该页在被使用且写入了数据,还需要保存现场到磁盘
6、分配物理页完成,需要的话,还得从磁盘恢复此前的数据,更新地址转换表
7、缺页中断处理完毕,内存访问从失败的地方再次尝试,接下来就进入前述的快速通道进行访问。
由此可见,无论是快速通道还是慢速通道,CPU访问内存需要执行不少的操作,而慢速通道的处理则更加耗时(缺页中断的处理,如果不幸的,还需要处理与磁盘的交互),上述的描述还是忽略了缓存的简化版本,通常CPU有L1、L2、L3三级缓存,地址转换还有TLB缓存。
讲述了基本原理,再来看一下,前述的性能对比中,内存访问的情况。
缺页中断次数 |
|
new A |
327 page-faults |
new A() |
33,095 page-faults |
从表中可以看到,由于清零操作,带来了内存写入,进而引发了缺页中断,后者比前者多了32768次。这个数字是怎么来的呢?在前述测试中,A的大小是4字节,申请了32M次,申请总内存大小是128M。因为系统默认页面大小是4096字节,4096*32768=128M,两者正好匹配。
记录池性能优化
记录池插件(recordpool)的整体架构如下
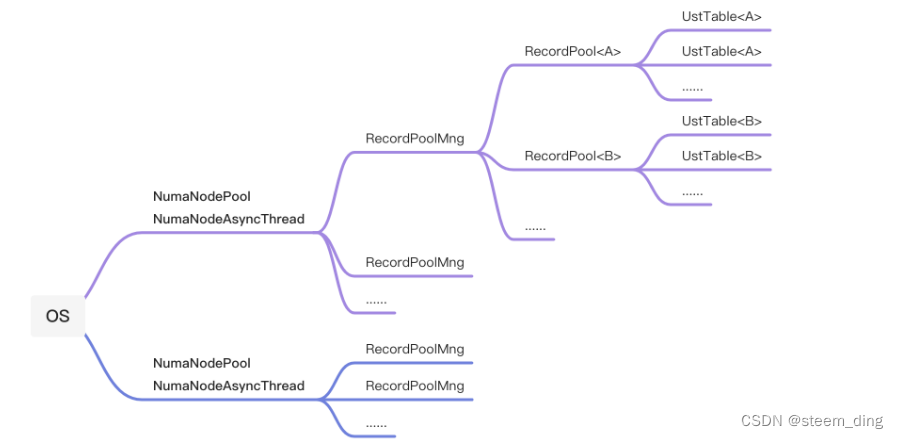
Table(内存表)的记录,是由其对应的RecordPool(记录池)提供的,记录池会有一个阈值,每当池中记录数不足时,会通过异步线程扩容一定数量的记录,以防止池中的记录消耗殆尽。
异步扩容线程使用的扩容方式,是采用placement new的方式
1、获取一定量的内存
2、在这片内存上做构造
其中,获取内存这部,通过向其上级,即RecordPoolMng申请即可,RecordPoolMng中有已经预热过(做过prefault)的内存,如果RecordPoolMng中内存不足,则继续向其上级申请,层层向上,直到向系统获取内存。此次测试发现的瓶颈不在此处,因为系统初始化时,会申请很大的一片内存,且在测试过程中,没有用尽。
此次的性能瓶颈在2,即在这片内存做构造上。
过程如下,Table会把自己的构造函数,通过接口的方式注册给RecordPool,RecordPool在拿完内存后,即以循环的方式调用虚函数,调用的次数取决去Table定义时的模板参数。
对于确实需要构造的数据结构,这样做确实没什么问题。
但是对于POD类型,或者内置类型,即指针,其实是没有必要的,白白浪费了多次虚函数调用,即内存清零的操作。因此关键点在于Table实现接口构造方法时,使用了 new T()这样的形式。把此处修改为 new T后,对于前述的POD类型,内置类型及指针类型,便无需进入内存清零操作。
此外,还有一层优化可做,即在循环调用接口函数做构造的外层,使用C++11的特性 std::is_trivially_default_constructible<T>来判断是否真有必要进入循环做构造的调用,但是由于目前基于g++ 4.8.5进行编译,还不支持此项功能,留待编译器版本升级后解决。