在PyTorch中,state_dict是一个非常重要的概念,它是一个包含模型参数的字典对象。每个模型的state_dict都包含了该模型的所有参数(权重和偏置等),用于在训练和推理过程中重现模型的内部状态.
pytorch 中的 state_dict 是一个简单的python的字典对象,将每一层与它的对应参数建立映射关系.(如 model的每一层的weights及偏置等等) (注意,只有那些参数可以训练的layer才会被保存到模型的state_dict中,如卷积层,线性层等等) 优化器对象Optimizer也有一个state_dict,它包含了优化器的状态以及被使用的超参数(如lr, momentum,weight_decay等)
1. 保存模型参数
使用torch.save(model.state_dict(), PATH)可以将state_dict保存到指定路径. 常用的保存 state_dict的格式是".pt"或’.pth’的文件,即下面命令的 PATH="./***.pt". 但是文件名字不影响,只是大家大家默认这个名字有辨识度,你取***.sp照样不影响.
torch.save(model.state_dicr(),PATH) # PATH为存储的位置例如: path/best.pth2.初始化模型
即初始化模型的参数, 使用model.load_state_dict(torch.load(PATH))可以重新加载模型。
modle = MyModel(*args, **kwargs)
model.load_state_dict(torch.load(PATH)3.取出或更新某一层参数
前面说了state_dict()中的参数是按字典存取,即每个层都有一个key值索引, 所以按照字典规则取出该值即可. 现在假设某层的名字为 conv1.weight.
weight_data = torch.load('./model_state_dict.pt')['conv1.weight']
修改某一层的值
# 假设 model 是一个已经初始化的模型
# 更改第一层的权重
model.state_dict()['layer1.weight'] = torch.randn(10, 10) 在训练过程中,state_dict还用于存储梯度信息。在反向传播过程中,PyTorch会通过state_dict来更新模型参数.
4.控制model的某层是否需要梯度求导
加载模型参数后,如何设置某层某参数的"是否需要训练"(param.requires_grad)
for param in list(mode.pretrained.parameters()):
param.requires_grad = True5.手写网络层及state_dict()使用例子
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import numpy as mp
import matplotlib.pyplot as plt
import torch.nn.functional as F
#define model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass,self).__init__()
self.conv1=nn.Conv2d(3,6,5)
self.pool=nn.MaxPool2d(2,2)
self.conv2=nn.Conv2d(6,16,5)
self.fc1=nn.Linear(16*5*5,120)
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10)
def forward(self,x):
x=self.pool(F.relu(self.conv1(x)))
x=self.pool(F.relu(self.conv2(x)))
x=x.view(-1,16*5*5)
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def main():
# Initialize model
model = TheModelClass()
#Initialize optimizer
optimizer=optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
#print model's state_dict
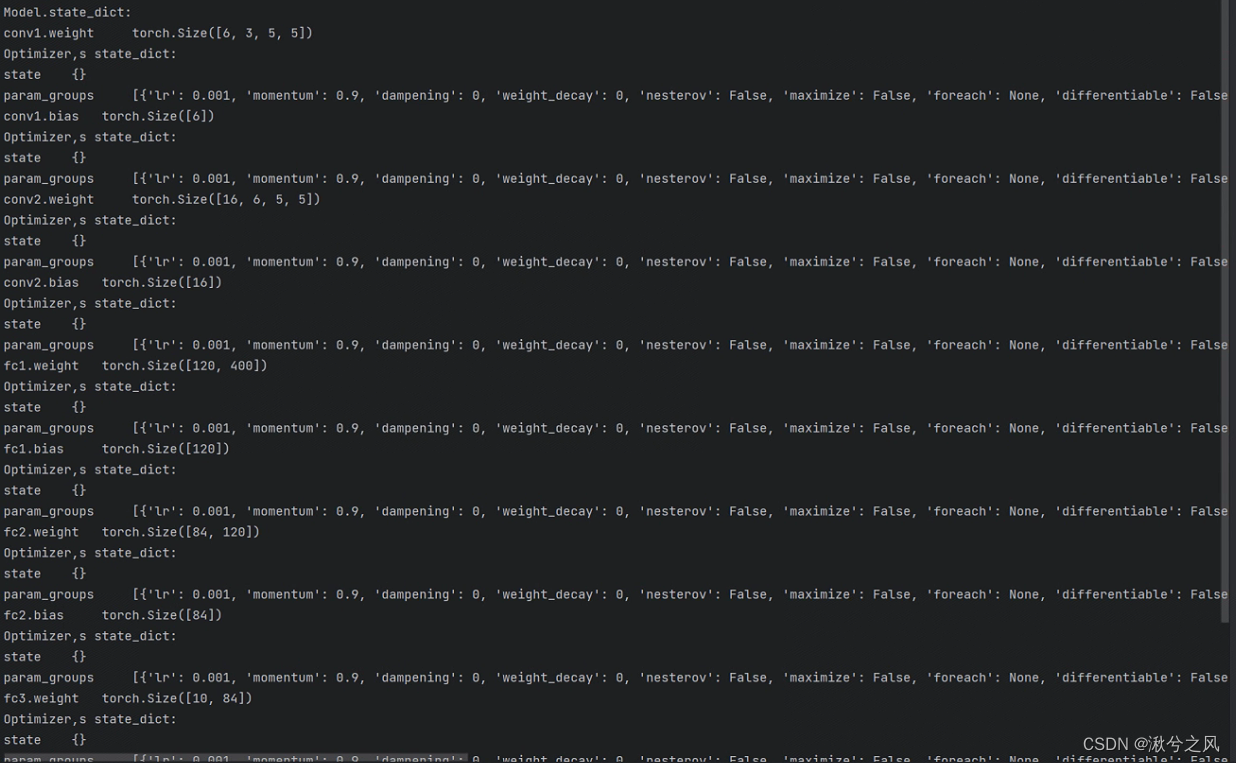
print('Model.state_dict:')
for param_tensor in model.state_dict():
#打印 key value字典
print(param_tensor,'\t',model.state_dict()[param_tensor].size())
#print optimizer's state_dict
print('Optimizer,s state_dict:')
for var_name in optimizer.state_dict():
print(var_name,'\t',optimizer.state_dict()[var_name])
if __name__=='__main__':
main()