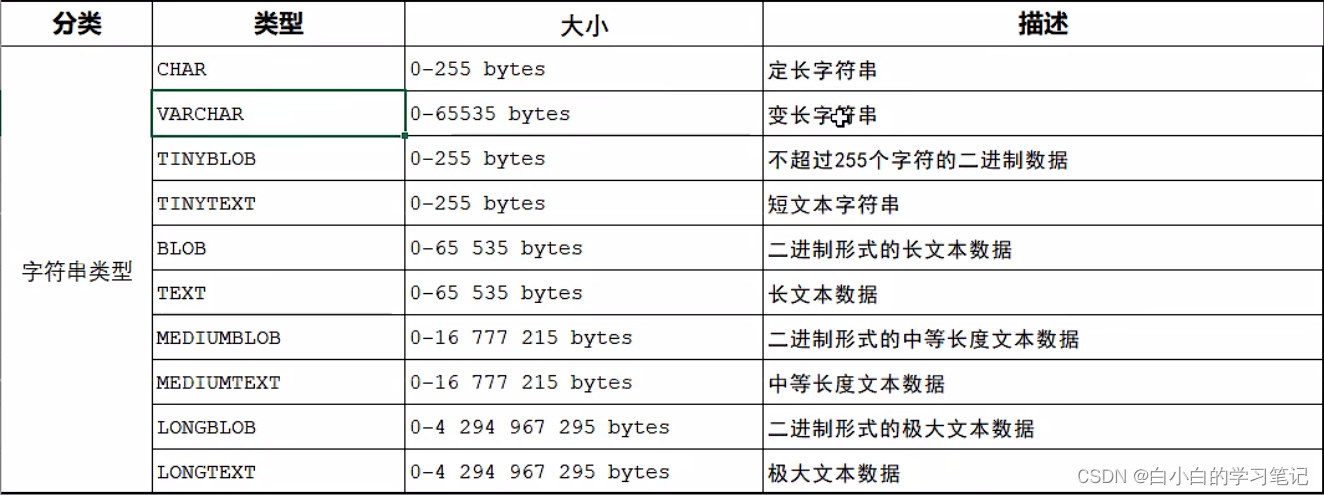
最近一直在做数据处理相关的工作,有几点经常遇到的情况总结如下:
- 数据中存在为空数据如何处理
处理方式1:丢弃数据行
# 实现方式1
data = data.dropna(subset=['id']) # 若id列中某行数值为空,丢弃整行数据
# 实现方式2
data = df[df['id'].notna()]
处理方式2:填充,定值填充或插值填充
data['value'] = data['value'].fillna(0.0) # 使用0.0对value列中空值进行填充
- 丢弃某行某列
# 如果rn列存在,丢弃该列
if 'rn' in df.columns:
df = df.drop('rn', axis=1) # axis控制行列
# 若直接在原数据做操作,需设置inplace参数
df.drop('rn', axis=1, inplace=True)
- 如何对某列中字符串数据进行批量操作
# 设time中数据为12:34这种类型
df['time'].str.split(':',expand=True).astype(int)
# expand参数用以将分割的字符串展开为单独的列,astype用于转换数据类型
- 数据中不存在某列,添加列
# 添加有值的列如何做
data = {
'A': ['item1', 'item2', 'item3', 'item4'],
'B': ['0.1', '0.2', '0.3', '0.4']
}
df = pd.DataFrame(data)
# 增加一列'id'字段, 并选择特定行赋值
df.loc[[True, False, True, True],'id'] = ['1', '2', '3']
# 不支持同时加两列,只能加单列
# 添加无值的列,再进行处理
df['add'] = np.nan
df['add'] = np.where(df['hour'] >= 1000, 1, 0)
df['hour'] = np.where(df['hour'] >= 1000, df['hour'] - 1000, df['hour'])
- 一些日期处理函数
# pd.to_datetime
# 将day转为datetime格式
tmp_day = pd.to_datetime(df['day'], format='%Y%m%d')
# pd.to_timedelta
timestamp = tmp_day + pd.to_timedelta(df['hour'], unit='h') + pd.to_timedelta(df['min'],
unit='m') + pd.to_timedelta(df['add'], unit='D')
- 一些处理函数
# id分组中,源数据只有一行batch字段有填充,函数实现将batch拓展填充到各数据行
df['batch'] = df.groupby('id')['batch'].transform(
lambda x: x.fillna(method='ffill').fillna(method='bfill'))
# 首先通过groupby函数根据id列对数据进行分组,然后对每个分组使用transform函数。
# transform函数中的lambda函数使用fillna方法先向前(ffill)填充分组中的np.nan值,
# 如果某一分组中的第一行为np.nan,则之后再向后(bfill)填充。
# 对每个id分组,执行apply操作,运行数据处理函数,实现功能
def trans(df):
df = df.groupby('id').apply(lambda group: group.apply(process_column))
return df
def process_column(col):
# 若数据列名中存在period或为a b c,将该组数据用;连接起来返回
if 'period' in col.name or col.name in ['a','b','c']:
return ';'.join(str(v) for v in col)
else:
# 其余数据直接做unique返回
return col.unique()