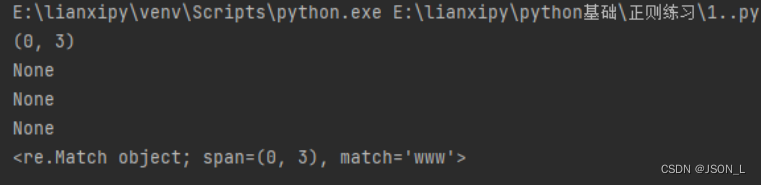
match()和search()方法是re模块中用于正则表达式匹配的两个函数,而不是research()。
match()方法从字符串开头开始匹配,只有当模式从字符串的起始位置开始匹配成功时才会返回匹配对象。如果模式无法从字符串起始位置匹配成功,则返回None。
search()方法在整个字符串中搜索匹配模式的第一个位置,并返回匹配对象。它不要求模式从字符串的起始位置匹配成功,只要字符串中存在匹配的内容即可。
下面是一个示例代码来说明两者之间的不同:
import re
pattern = r'abc'
string = 'xabcdefg'
# 使用 match() 方法进行匹配
match_result = re.match(pattern, string)
print(match_result) # None,因为模式无法从字符串起始位置匹配成功
# 使用 search() 方法进行匹配
search_result = re.search(pattern, string)
print(search_result) # <re.Match object; span=(1, 4), match='abc'>,匹配成功并返回匹配对象
总结:
match()方法从字符串起始位置开始匹配,如果匹配成功则返回匹配对象,否则返回None。search()方法在整个字符串中搜索匹配模式的第一个位置,如果匹配成功则返回匹配对象,否则返回None。
compile()匹配模式
在Python中,re.compile()函数用于将正则表达式模式编译为一个对象,以便可以重复使用该模式进行匹配。下面是一些常用的匹配模式及相应的示例:
re.IGNORECASE:不区分大小写匹配
import re
pattern = re.compile(r"hello", re.IGNORECASE)
result = pattern.search("Hello World")
print(result.group()) # 输出: Hello
re.MULTILINE:多行匹配,使^和$匹配每行的开始和结束
import re
pattern = re.compile(r"^hello", re.MULTILINE)
result = pattern.findall("hello world\nhello, python")
print(result) # 输出: ['hello', 'hello']
re.DOTALL:匹配任意字符的模式,包括换行符\n
import re
pattern = re.compile(r"hello.*world", re.DOTALL)
result = pattern.search("hello\nworld")
print(result.group()) # 输出: hello\nworld
re.ASCII:只匹配ASCII字符的模式
import re
pattern = re.compile(r"[a-z]", re.ASCII)
result = pattern.findall("Hello, Python")
print(result) # 输出: ['e', 'l', 'l', 'o', 'y', 't', 'h', 'o', 'n']
re.DEBUG:打印调试信息,方便调试正则表达式
import re
pattern = re.compile(r"\d{3}-\d{4}", re.DEBUG)
result = pattern.search("My phone number is 123-4567")
# 输出调试信息:
# MAX_REPEAT 3 4
# LITERAL 45
# IN
# RANGE (48, 57)
# MAX_REPEAT 0 4
# IN
# RANGE (48, 57)
# LITERAL 45
# IN
# RANGE (48, 57)
print(result.group()) # 输出: 123-4567
这些只是一些常用的匹配模式,re.compile()函数还支持其他更多的选项和模式。可以通过查阅Python官方文档来了解更多详细信息。



















![[node] Node.js的Web 模块](https://img-blog.csdnimg.cn/999f27a1616742569128568e8d1f3b4a.png)