参考:
李宏毅机器学习--self-supervised:BERT、GPT、Auto-encoder-CSDN博客
用无标注资料的任务训练完模型以后,它本身没有什么用,GPT 1只能够把一句话补完,可以把 Self-Supervised Learning 的 Model做微微的调整,把它用在其他下游的任务裡面,对于下游任务的训练,仍然需要少量的标记数据。
GPT1基本实现
例如有条训练语句是“台湾大学”,那么输入BOS后训练输出是台,再将BOS和"台"作为输入训练输出是湾,给它BOS "台"和"湾",然后它应该要预测"大",以此类推。模型输出embedding h,h再经过linear classification和softmax后,计算输出分布与正确答案之间的损失cross entropy,希望它越小越好。
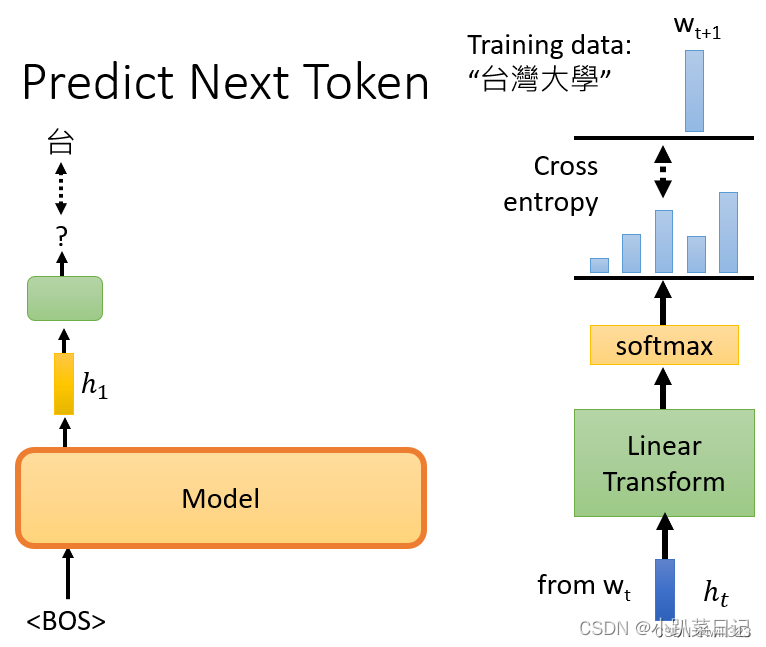
详细计算过程:

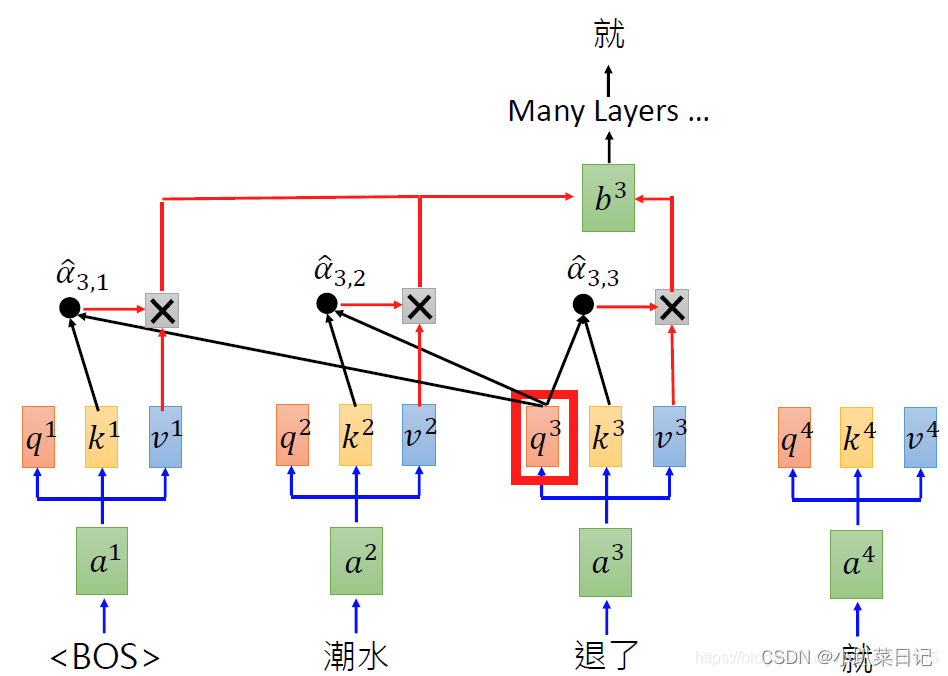
GPT1和GPT2
GPT1里主要用的是transformer中的decoder层。
GPT-2依然沿用GPT单向transformer的模式,只不过做了一些改进与改变:
- GPT-2去掉了fine-tuning层
- 增加数据集和参数
- 调整transformer
| 模型 | 参数量 |
| ELMO | 94M |
| BERT | 340M |
| GPT-2 | 1542M |