目录
链表是最基础的数据结构线性表的其中一种存储结构,它是以指针域来指向与其相连的元素来实现表中元素的线性连接。与线性表的另一种存储结构顺序表不同的是,链表不需要预先占用一整块连续的地址空间,链表中的元素的地址之间是没有关联的,链表中的元素的存储地址是分散的,每添加一个元素就对应申请一个元素的空间,而不需要像顺序表一样提前设定好整个表所占的空间,是一种动态的空间管理的存储结构。顺序表为保证存储空间足够,通常会申请比实际要大的存储空间,在实际使用中很多存储空间都是没有使用的,导致存储空间利用率下降,而链表的动态申请空间的方式相比顺序表能够显著提高存储空间的利用率。
一、链表的定义
链表是由多个地址不连续的存储结点连接而成的一种线性表,每个存储结构不仅包含元素本身的信息(数据域),而且包含表示元素之间的逻辑关系的信息,在c/c++中采样指针来实现,称为指针域,这个逻辑关系用指针来表示就是指向在线性表中与其相连的元素的地址。
在线性表中,每个元素最多只有一个前驱结点和后继结点,采样链式存储时,每个结点需要包含前驱结点或者后继结点的地址信息,其中最简单也是最常用的方法是只存储每个结点的后继结点的地址,以这种方式构成的链表称为单链表。每个结点同时包含前驱节点和后继结点的地址构成的链表称为双链表。
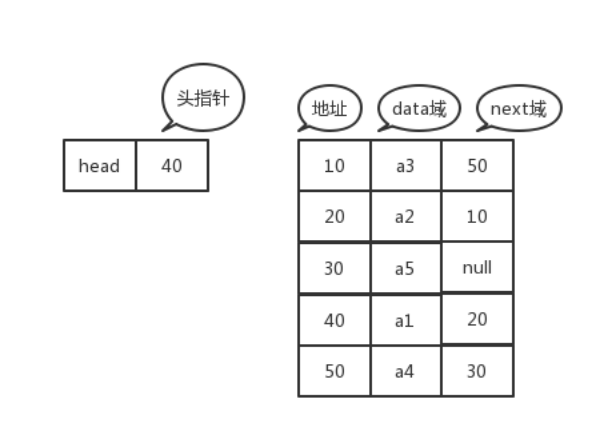
在链表中通常都会有一个头结点,头结点一般不包含信息,只用于存储顺序表中第一个元素的地址信息,头结点通常作为链表的起始地址,以头结点的地址作为链表的唯一标识,称为头指针。头结点指向的结点称为首结点,首结点是链表中第一个有元素信息的结点。链表中最后一个结点称为尾结点,尾结点之后没有结点了,因此指针域为空,指向尾结点的指针称为尾指针。如下图就是一个单链表的结构图,包含n个元素。

二、链表的基本操作
链表的基本操作与顺序表一样,包括创建、插入、查询、删除和遍历。
1. 单链表
1.1. 定义链表结点结构体
链表是由多个结点构造的,每个结点都包含元素的信息和下一个结点的地址,需要使用一个结构体来存储,链表结点定义如下:
template <typename T>
struct listNode
{
T data;
struct listNode<T>* next;
listNode(T val) {
data = val;
next = NULL;
}
};我使用的语言是c++,可以使用模板来定义结构体,结点的数据类型由创建结构体时给定,使其可以兼容各种类型的数据结点。 c语言则一般使用宏定义给出结点数据的类型。
此外,c++的结构体可以像类一样包含结构体的操作函数,与类不同的是结构体的成员都是公共访问权限的,在结构体中定义一个创建结点的构造函数,包含为数据成员data和next赋值的操作,next默认都初始化为NULL,这样就不用在结点都创建完之后再将尾结点的指针域设置为NULL了。
1.2. 定义链表类
使用c++实现链表可以使用类来包装链表,将链表的数据和函数包装在一起,以对象的方式来定义链表更加合适。
首先确定链表类的数据成员,链表使用头指针作为唯一标识,因此只需要定义一个头指针head就能完成对链表的所有操作,不过为了方便尾插法创建链表我也定义了一个尾指针tail。此外,线性表的一个重要属性线性表长度length也需要定义。因此链表类的数据成员就包括头指针head、尾指针tail、链表长度length。
链表类的定义如下:
template <typename T>
class LinkedList {
private:
// 头结点,唯一标识一个链表
listNode<T>* head;
// 尾结点,用于尾插法创建链表
listNode<T>* tail;
// 链表长度(线性表的长度,不包括头结点)
int length;
public:
// 无参构造,仅初始化头指针,不创建链表
LinkedList() {
head = new listNode<T>(T());
tail = head;
length = 0;
}
}上述代码只定义了一个简单的只包含数据成员以及一个无参构造函数的链表类,无参构造函数仅完成创建头结点和尾结点以及初始化length的操作,创建链表构造函数以及其他成员函数在下面再定义。
1.3. 创建链表
创建链表的方式有两种,一种是头插法,一种是尾插法。头插法是在头结点的后面插入结点,尾指针是在尾结点后插入结点。
1.3.1. 头插法创建链表
头插法创建链表时,每个新结点都是插入到头结点的后面。插入的操作只需要两步即可完成,第一步是获取头结点的指针域,使新结点的指针域指向头结点指针域所指的结点,第二步是将头结点的指针域指向新结点。简单点说就是先将新结点与头结点的下一个结点连接,再将头结点与新结点连接。注意连接的顺序不能反,如果反了就获取不到头结点原来的下一个结点的指针了。两步操作如下图。
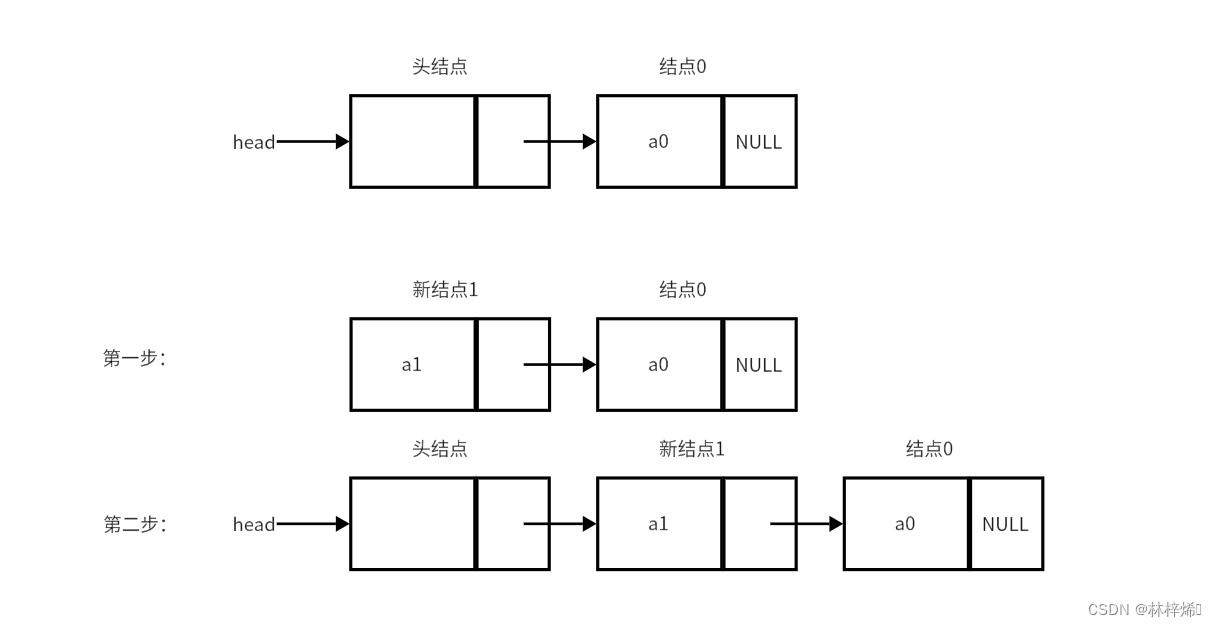
对应代码:
// 头插法
void headInsert(T data) {
listNode<T>* newNode = new listNode<T>(data);
newNode->next = head->next;
head->next = newNode;
length++;
}新结点的创建要调用listNode结构体的构造函数创建,传入data参数。
完整头插法创建链表操作如下图。
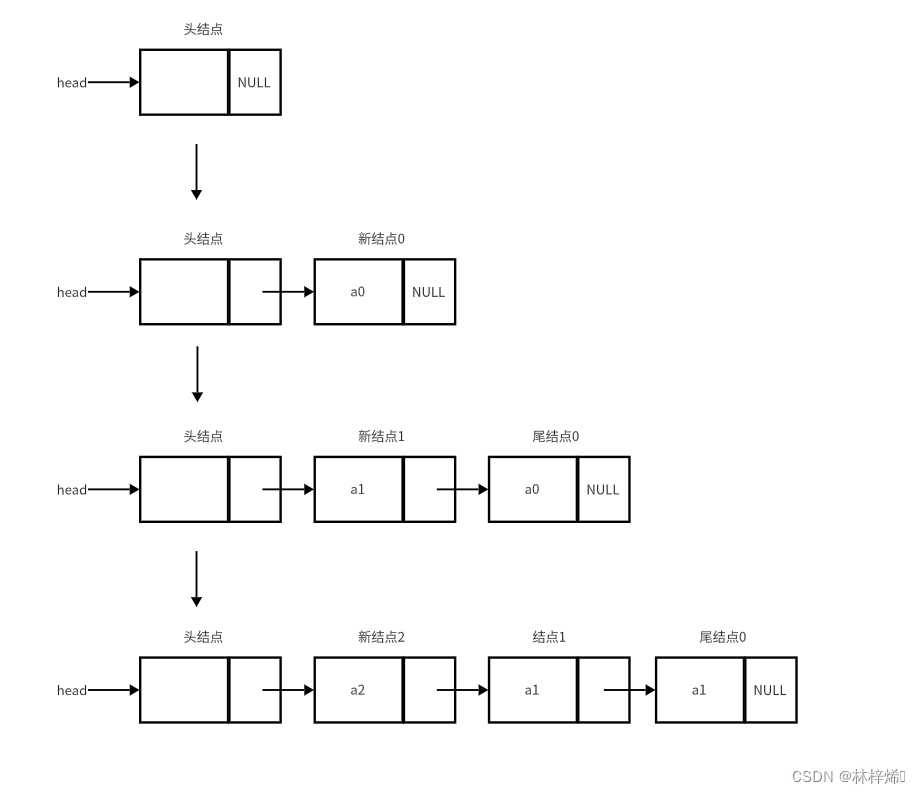
在上图中,一开始链表中只包含头结点,首先插入一个新的结点0,新结点0插入到头结点的后面,由于头结点没有下一个结点,因此将新结点0的指针域赋值为0;接着再插入一个新结点1,新结点1同样插入到头结点后,而头结点此前的下一个结点是结点0,新结点1先与结点0连接,再与头结点连接,完成插入;最后再插入一个新结点2,同样先和头结点的下一个结点连接,再与头结点连接。从上图中我们能观察到头插法创建的链表是逆序的,因为每个结点都是插入在原链表的首部。
完整的流程就是对于每个新结点都执行上述的两步操作。
对应代码:
// 头插法构造链表
void headCreateList(T data[], int n) {
for (int i = 0; i < n; i++) {
headInsert(data[i]);
// 头插法尾结点就是线性表中第一个结点
if (i == 0)
tail = head->next;
}
}1.3.2. 尾插法创建链表
尾插法与头插法类似,尾插法是将新结点插入到尾结点后,由于尾结点后没有结点了,新结点不用与尾结点后的结点连接,但是尾插法还是需要两步操作,第一步是将新结点插入到尾结点后,第一步是将尾指针指向新结点,即让新结点成为尾结点。如下图。
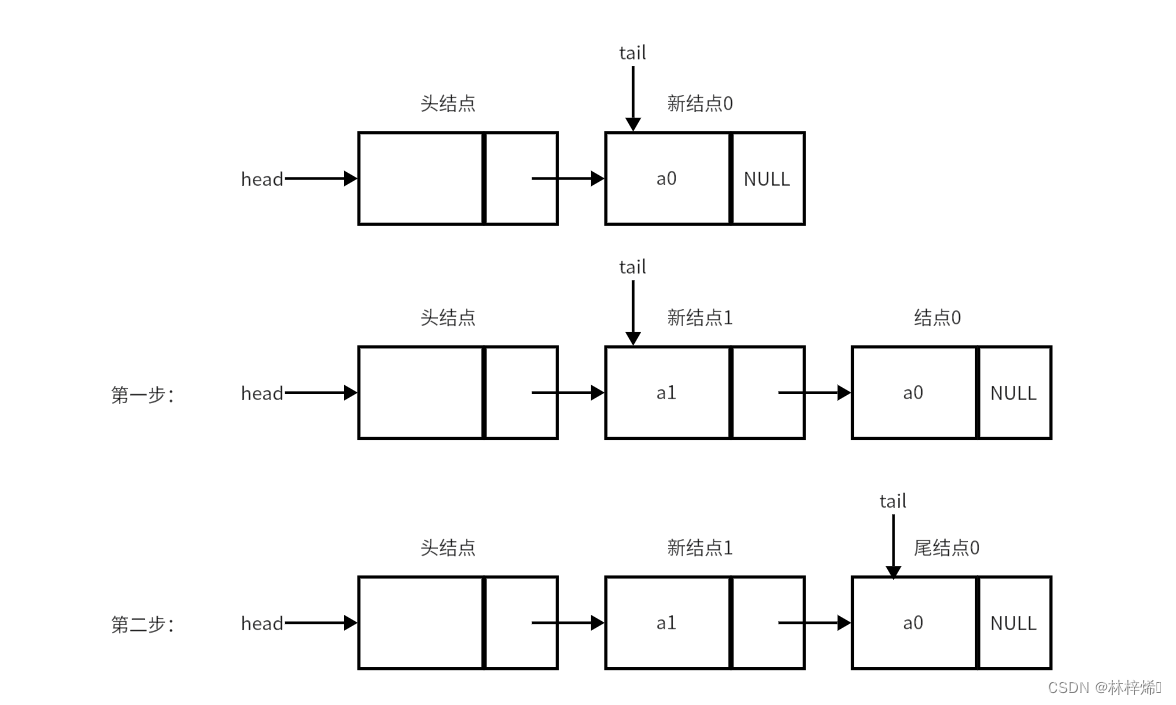
对应代码:
// 尾插法
void tailInsert(T data) {
listNode<T>* newNode = new listNode<T>(data);
tail->next = newNode;
tail = newNode;
length++;
}完整尾插法创建链表流程与头插法一样,对每个结点执行上述两步操作即可。
对应代码:
// 尾插法创建链表
void tailCreateList(T data[], int n) {
for (int i = 0; i < n; i++) {
tailInsert(data[i]);
}
}1.4. 遍历链表
遍历链表是链表的基础操作,步骤很简单,只需要使用指针不断往下一个结点移动,输出每个结点的数据,直到尾结点即可。
对应代码如下:
// 打印链表的所有元素
void dispList() {
listNode<T>* p = head->next;
while (p)
{
cout << p->data << " ";
p = p->next;
}
cout << endl;
}遍历到尾结点并输出后,指针指向尾结点的下一个结点,而尾结点的指针域是NULL,此时就不满足循环条件,退出循环,遍历结束。
接着使用dispList函数来打印头插法和尾插法创建的链表,查看两种方法创建的结果。
测试:
int a[] = { 1, 2, 3, 4 };
int n = 4;
LinkedList<int> lista = LinkedList<int>();
lista.headCreateList(a, n);
cout << "头插法创建结果:";
lista.dispList();
LinkedList<int> listb = LinkedList<int>();
listb.tailCreateList(a, n);
cout << "尾插法创建结果:";
listb.dispList();运行结果:

可以看到头插法是逆序创建的,尾插法是顺序创建的。
1.5. 查找结点
链表与顺序表不同,链表中的元素并不是按下标在地址空间中顺序存放的,要想查找链表指定下标的元素不能直接使用下标作为索引访问,而是需要遍历链表,直到遍历到对应下标的元素。
// 按元素下标查找元素,如果下标不合法返回NULL
listNode<T>* locatedElemByIndex(int index) {
listNode<T>* p = head->next;
// 下标不合法,返回空指针
if (index < 0 || index >= length)
return NULL;
for (int i = 0; i < index; i++) {
p = p->next;
}
return p;
}为了方便后续的插入和删除结点操作,我将返回值改为了结点的指针,而不是结点的数据。
测试:
int a[] = { 1, 2, 3, 4 };
int n = 4;
LinkedList<int> listb = LinkedList<int>();
listb.tailCreateList(a, n);
cout << "尾插法创建结果:";
listb.dispList();
cout << "查询结果:" << listb.locatedElemByIndex(2)->data << endl;运行结果:

查询第2个元素(从0开始) ,查询结果为3,结果正确!
1.6. 插入结点
插入结点操作是在指定的位置插入一个给定的结点。一般用线性表元素下标表示位置,插入位置是指定下标的元素的后面。
链表插入的操作与头插法是一样的操作,头插法就是插入位置在头结点后的插入结点操作。插入结点的两步操作如下。
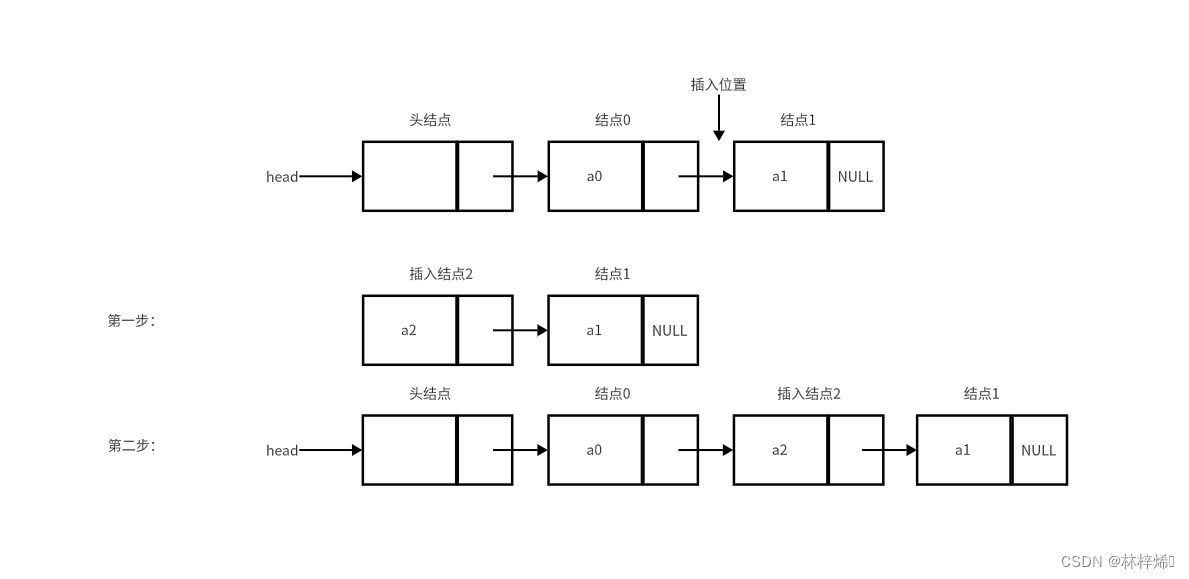
可以看出,插入结点的操作与头插法相比只是插入的位置变了而已。
对应代码:
// 插入结点(插入位置是该index下标对应结点的后面)
// index:插入位置前的结点的下标,data:插入结点数据
bool insertNode(int index, T data) {
listNode<T>* newNode = new listNode<T>(data);
listNode<T>* p = locatedElemByIndex(index);
// 没有index对应的结点,index可能不合法,返回失败
if (!p) {
return false;
}
newNode->next = p->next;
p->next = newNode;
length++;
return true;
}首先使用之前定义的查询函数locatedElemByIndex查找插入位置前的结点p,接着将新结点的指针域指向p的指针域所指向的结点,再将p的指针域指向新结点,最后增加链表的长度length。
测试:
int a[] = { 1, 2, 3, 4 };
int n = 4;
LinkedList<int> listb = LinkedList<int>();
listb.tailCreateList(a, n);
cout << "尾插法创建结果:";
listb.dispList();
listb.insertNode(2, 7);
cout << "插入后结果:";
listb.dispList();运行结果:

运行结果正确!
1.7. 删除结点
先找到要删除的结点的上一个结点(index-1),然后找到的结点的指针域赋值为要删除结点的下一个结点,接着释放要删除的结点占用的内存即可(c++中使用new创建的指针使用delete删除)。流程如下。

// 删除结点
bool deleteNode(int index) {
listNode<T>* p;
// index为0时,不能直接使用locateElemByIndex访问该结点的上一个结点
// 因为此时index-1为-1,index=0结点的上一个结点是head,直接将p赋值为head即可
if (index == 0) {
p = head;
}
else{
p = locateElemByIndex(index - 1);
}
if (!p) {
return false;
}
listNode<T>* curNode = p->next;
p->next = curNode->next;
delete curNode;
length--;
return true;
}删除前需要先使用一个指针保存要删除的结点的地址,接着先为要删除的结点的前驱结点的指针域赋值为要删除结点的下一个结点的地址,然后再删除结点,最后将length-1。
1.8. 删除链表
链表使用完后需要删除链表,释放链表结点所占用的内存。
操作步骤是遍历每一个结点,将每个结点删除。
将删除链表作为链表类的析构函数,在类对象不再使用后(生命周期结束),对象会自动销毁,销毁时会调用类的析构函数,如果没有自定义析构函数就会调用默认的析构函数,默认的析构函数只会释放类中定义的成员所占用的内存,类中只包含头指针和尾指针,不会释放整个链表所占用的空间。因此我们需要自己定义一个析构函数,完成删除链表的操作,除了释放链表占用内存外还要将tail赋值为NULL,将length赋值为0。
对应代码:
// 析构函数,释放链表所有结点占用的内存
~LinkedList() {
listNode<T>* p = head;
while (p)
{
head = head->next;
delete p;
p = head;
}
tail = NULL;
length = 0;
}至此,完整的单链表类的数据成员和成员函数全部定义完成。
1.9. 完整的单链表类
#pragma once
#include<iostream>
using namespace std;
template <typename T>
struct listNode
{
T data;
struct listNode<T>* next;
listNode(T val) {
data = val;
next = NULL;
}
};
template <typename T>
class LinkedList
{
private:
// 头结点,唯一标识一个链表
listNode<T>* head;
// 尾结点,用于尾插法创建链表
listNode<T>* tail;
// 链表长度(线性表的长度,不包括头结点)
int length;
public:
// 无参构造,仅初始化头指针,不创建链表
LinkedList() {
head = new listNode<T>(T());
tail = head;
length = 0;
}
// 有参构造函数默认使用尾插法构造链表,调用无参构造函数初始化头指针
LinkedList(T data[], int n) : LinkedList() {
// 调用tailCreateList函数创建链表
tailCreateList(data, n);
}
// 析构函数,释放链表所有结点占用的内存
~LinkedList() {
listNode<T>* p = head;
while (p)
{
head = head->next;
delete p;
p = head;
}
tail = NULL;
length = 0;
}
// 获取链表长度(不包括头结点)
int getLength() {
return length;
}
// 获取链表头指针
listNode<T>* getHead() {
return head;
}
// 获取链表尾指针
listNode<T>* getTail() {
return tail;
}
// 头插法构造链表
void headCreateList(T data[], int n) {
for (int i = 0; i < n; i++) {
headInsert(data[i]);
if (i == 0)
tail = head->next;
}
}
// 尾插法创建链表
void tailCreateList(T data[], int n) {
for (int i = 0; i < n; i++) {
tailInsert(data[i]);
}
}
// 尾插法
void tailInsert(T data) {
listNode<T>* newNode = new listNode<T>(data);
tail->next = newNode;
tail = newNode;
length++;
}
// 头插法
void headInsert(T data) {
listNode<T>* newNode = new listNode<T>(data);
newNode->next = head->next;
head->next = newNode;
length++;
}
// 按元素值查找元素,如果没找到就返回NULL
listNode<T>* locateElemByVal(T data) {
listNode<T>* p = head->next;
for (int i = 0; p; i++) {
if (p->data == data) {
break;
}
p = p->next;
}
return p;
}
// 按元素下标查找元素,如果下标不合法返回NULL
listNode<T>* locateElemByIndex(int index) {
listNode<T>* p = head->next;
// 下标不合法,返回空指针
if (index < 0 || index >= length)
return NULL;
for (int i = 0; i < index; i++) {
p = p->next;
}
return p;
}
// 插入结点(插入位置是该index下标对应结点的后面)
// index:插入位置前的结点的下标,data:插入结点数据
bool insertNode(int index, T data) {
listNode<T>* newNode = new listNode<T>(data);
listNode<T>* p = locateElemByIndex(index);
if (!p) {
return false;
}
newNode->next = p->next;
p->next = newNode;
length++;
return true;
}
// 删除结点
bool deleteNode(int index) {
listNode<T>* p;
// index为0时,不能直接使用locateElemByIndex访问该结点的上一个结点
// 因为此时index-1为-1,index=0结点的上一个结点是head,直接将p赋值为head即可
if (index == 0) {
p = head;
}
else{
p = locateElemByIndex(index - 1);
}
if (!p) {
return false;
}
listNode<T>* curNode = p->next;
p->next = curNode->next;
delete curNode;
length--;
return true;
}
bool deleteNodeByPreNode(listNode<T>* preNode) {
listNode<int>* q = preNode->next;
preNode->next = q->next;
delete q;
length--;
return true;
}
// 打印链表的所有元素
void dispList() {
listNode<T>* p = head->next;
while (p)
{
cout << p->data << " ";
p = p->next;
}
cout << endl;
}
// 判断链表是否为空(只需判断首指针是否为空即可)
bool isEmpty() {
return head->next == NULL;
}
};
除了上面定义的成员函数外,我还添加了判断链表是否为空以及数据成员head、tail、length的getter方法以及一个有参构造函数,该构造函数使用尾插法创建链表,由于头插法和尾插法的参数列表相同,无法为尾插法也重载一个构造函数,因此只添加了尾插法的构造函数。
2. 双链表
2.1. 定义双链表结点
双链表结点与单链表基本是一样的,只是多了一个pre指针用于指向该结点的上一个指针,构造函数也要同时添加pre指针的初始化。
定义如下:
template <typename T>
struct dListNode
{
T data;
struct dListNode<T>* pre;
struct dListNode<T>* next;
dListNode(T val) {
data = val;
pre = NULL;
next = NULL;
}
};双链表类的数据成员与单链表类似的,只是将listNode改为了双链表结点类型dListNode。
2.2. 创建双链表
2.2.1. 头插法
基本步骤与单链表是一样的,只是多了添加结点的前驱结点的步骤。在第一步将新结点的后继指针赋值为头结点的后继指针后,需要再加上为头结点后继指针指向的结点的前驱指针赋值为新结点的操作(如果头结点的后继指针不为空的话),在第二步头结点的后继指针赋值为新结点后,需要再加上将新结点的前驱指针赋值为头结点。听起来可能比较乱,其实只要记住新结点插入后头结点和头结点下一个结点哪个指针需要变动,改变为谁,新结点的前驱和后继指针分别赋值为谁,然后按照变量先取值再赋值的原则为上述的指针赋值即可。
// 头插法
void headInsert(T data) {
dListNode<T>* newNode = new dListNode<T>(data);
newNode->next = head->next;
if (head->next) {
head->next->pre = newNode;
}
head->next = newNode;
newNode->pre = head;
length++;
}2.2.2. 尾插法
尾插法就比较简单了,只需要在第一步将尾结点的后继指针赋值为新结点后,再加上将新结点的前驱指针赋值为尾结点即可,第二步不变。
// 尾插法
void tailInsert(T data) {
dListNode<T>* newNode = new dListNode<T>(data);
tail->next = newNode;
newNode->pre = tail;
tail = newNode;
length++;
}2.3. 遍历双链表
2.3.1. 顺序遍历
顺序遍历就是按照原顺序遍历,步骤与单链表完全相同。
void dispList() {
dListNode<T>* p = head->next;
while (p)
{
cout << p->data << " ";
p = p->next;
}
cout << endl;
}2.3.2. 逆序遍历
由于双链表有两个指针域,一个前驱指针一个后继指针,每个结点都能直接访问它的前驱和后继结点,因此双链表可以实现逆序遍历,即从尾结点开始,一个个往前遍历。步骤与顺序遍历是一样的,只需要将循环结束条件改为p!=head,将遍历语句p=p->next改为p=p->pre即可。
// 逆序输出
void ivsDispList() {
dListNode<T>* p = tail;
while (p != head)
{
cout << p->data << " ";
p = p->pre;
}
cout << endl;
}测试:
因为双链表有前驱和后继两个指针,两种创建方式都需要同时进行顺序和逆序的输出。
int a[] = { 1, 2, 3, 4 };
int n = 4;
DLinkedList<int> lista = DLinkedList<int>();
lista.headCreateList(a, n);
cout << "头插法创建结果:" << endl;
cout << "\t" << "顺序输出:";
lista.dispList();
cout << "\t" << "逆序输出:";
lista.ivsDispList();
DLinkedList<int> listb = DLinkedList<int>();
listb.tailCreateList(a, n);
cout << "尾插法创建结果:" << endl;
cout << "\t" << "顺序输出:";
listb.dispList();
cout << "\t" << "逆序输出:";
listb.ivsDispList(); 运行结果:
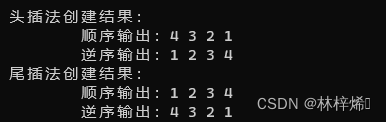
2.4. 查找结点
双链表查找结点的操作与单链表完全相同。
// 查找结点
dListNode<T>* locateElemByIndex(int index) {
dListNode<T>* p = head->next;
if (index < 0 || index >= length)
return NULL;
for (int i = 0; i < index; i++) {
p = p->next;
}
return p;
}2.5. 插入和删除结点
双链表的插入和删除结点和单链表是类似的,只是多了一个前驱指针,在赋值时考虑一下前驱指针就好了,按照先取值再赋值的原则来就不会错(不包括新结点,因为新结点原本的前驱指针和后继指针都为空),比如p->next需要先取出来赋值给newNode->next然后再为p->next赋值newNode,不过要注意p->next->pre=newNode是取p->next的值,因为它是要访问p的下一个结点,为p的下一个结点的前驱指针赋值。
// 插入结点
bool insertNode(int index, T data) {
dListNode<T>* newNode = new dListNode<T>(data);
dListNode<T>* p = locateElemByIndex(index);
if (!p) {
return false;
}
// 新结点的下一个结点是p原本的下一个结点
newNode->next = p->next;
// p原本的下一个结点的前驱结点修改为新结点
p->next->pre = newNode;
// p的下一个结点修改为新结点
p->next = newNode;
// 新结点的前驱指针指向p
newNode->pre = p;
length++;
return true;
}
// 删除结点
bool deleteNode(int index) {
dListNode<T>* p;
// index为0时,不能直接使用locateElemByIndex访问该结点的上一个结点
// 因为此时index-1为-1,index=0结点的上一个结点是head,直接将p赋值为head即可
if (index == 0) {
p = head;
}
else {
p = locateElemByIndex(index - 1);
}
if (!p) {
return false;
}
dListNode<T>* curNode = p->next;
p->next = curNode->next;
curNode->next->pre = p;
delete curNode;
length--;
return true;
}测试:
因为双链表结点同时拥有前驱和后继指针,因此需要顺序和逆序两种输出来分别检测后继和前驱指针是否都赋值正常。
DLinkedList<int> lista = DLinkedList<int>();
lista.headCreateList(a, n);
cout << "头插法创建结果:" << endl;
cout << "\t" << "顺序输出:";
lista.dispList();
cout << "\t" << "逆序输出:";
lista.ivsDispList();
lista.insertNode(1, 2002);
cout << "头插法插入后结果:" << endl;
cout << "\t" << "顺序输出:";
lista.dispList();
cout << "\t" << "逆序输出:";
lista.ivsDispList();
lista.deleteNode(3);
cout << "头插法删除后结果:" << endl;
cout << "\t" << "顺序输出:";
lista.dispList();
cout << "\t" << "逆序输出:";
lista.ivsDispList();
DLinkedList<int> listb = DLinkedList<int>();
listb.tailCreateList(a, n);
cout << "尾插法创建结果:" << endl;
cout << "\t" << "顺序输出:";
listb.dispList();
cout << "\t" << "逆序输出:";
listb.ivsDispList();
listb.insertNode(1, 2002);
cout << "尾插法插入后结果:" << endl;
cout << "\t" << "顺序输出:";
listb.dispList();
cout << "\t" << "逆序输出:";
listb.ivsDispList();
listb.deleteNode(3);
cout << "尾插法删除后结果:" << endl;
cout << "\t" << "顺序输出:";
listb.dispList();
cout << "\t" << "逆序输出:";
listb.ivsDispList();运行结果:
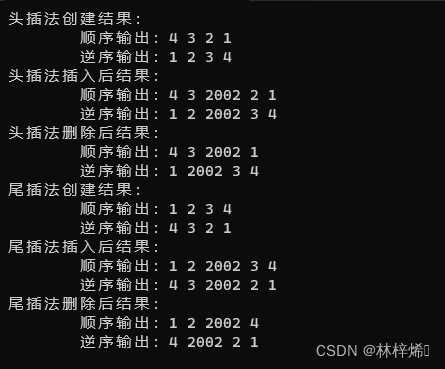
测试结果均正确。
2.6. 删除双链表
与单链表相同
// 析构函数,释放链表所有结点占用的内存
~DLinkedList() {
dListNode<T>* p = head;
while (p)
{
head = head->next;
delete p;
p = head;
}
tail = NULL;
length = 0;
}2.7. 完整双链表类:
#pragma once
#include<iostream>
using namespace std;
template <typename T>
struct dListNode
{
T data;
struct dListNode<T>* pre;
struct dListNode<T>* next;
dListNode(T val) {
data = val;
pre = NULL;
next = NULL;
}
};
template <typename T>
class DLinkedList {
private:
// 头结点,唯一标识一个链表
dListNode<T>* head;
// 尾结点,用于尾插法创建链表
dListNode<T>* tail;
// 链表长度(线性表的长度,不包括头结点)
int length;
public:
// 无参构造,仅初始化头指针,不创建链表
DLinkedList() {
head = new dListNode<T>(T());
tail = head;
length = 0;
}
// 有参构造函数默认使用尾插法构造链表,调用无参构造函数初始化头指针
DLinkedList(T data[], int n) : DLinkedList() {
// 调用tailCreateList函数创建链表
tailCreateList(data, n);
}
// 析构函数,释放链表所有结点占用的内存
~DLinkedList() {
dListNode<T>* p = head;
while (p)
{
head = head->next;
delete p;
p = head;
}
tail = NULL;
length = 0;
}
// 获取链表长度(不包括头结点)
int getLength() {
return length;
}
// 获取链表头指针
dListNode<T>* getHead() {
return head;
}
// 获取链表尾指针
dListNode<T>* getTail() {
return tail;
}
void headCreateList(T data[], int n) {
for (int i = 0; i < n; i++) {
headInsert(data[i]);
if (i == 0)
tail = head->next;
}
}
void tailCreateList(T data[], int n) {
for (int i = 0; i < n; i++)
tailInsert(data[i]);
}
// 尾插法
void tailInsert(T data) {
dListNode<T>* newNode = new dListNode<T>(data);
tail->next = newNode;
newNode->pre = tail;
tail = newNode;
length++;
}
// 头插法
void headInsert(T data) {
dListNode<T>* newNode = new dListNode<T>(data);
newNode->next = head->next;
if (head->next) {
head->next->pre = newNode;
}
head->next = newNode;
newNode->pre = head;
length++;
}
// 查找结点
dListNode<T>* locateElemByIndex(int index) {
dListNode<T>* p = head->next;
if (index < 0 || index >= length)
return NULL;
for (int i = 0; i < index; i++) {
p = p->next;
}
return p;
}
// 插入结点
bool insertNode(int index, T data) {
dListNode<T>* newNode = new dListNode<T>(data);
dListNode<T>* p = locateElemByIndex(index);
if (!p) {
return false;
}
newNode->next = p->next;
p->next->pre = newNode;
p->next = newNode;
newNode->pre = p;
length++;
return true;
}
// 删除结点
bool deleteNode(int index) {
dListNode<T>* p;
// index为0时,不能直接使用locateElemByIndex访问该结点的上一个结点
// 因为此时index-1为-1,index=0结点的上一个结点是head,直接将p赋值为head即可
if (index == 0) {
p = head;
}
else {
p = locateElemByIndex(index - 1);
}
if (!p) {
return false;
}
dListNode<T>* curNode = p->next;
p->next = curNode->next;
curNode->next->pre = p;
delete curNode;
length--;
return true;
}
// 逆序输出
void ivsDispList() {
dListNode<T>* p = tail;
while (p != head)
{
cout << p->data << " ";
p = p->pre;
}
cout << endl;
}
void dispList() {
dListNode<T>* p = head->next;
while (p)
{
cout << p->data << " ";
p = p->next;
}
cout << endl;
}
// 判断链表是否为空(只需判断首指针是否为空即可)
bool isEmpty() {
return head->next == NULL;
}
};
3. 循环链表
单链表将尾结点的指针域赋值为空,而循环单链表将尾结点的指针域赋值为head,也就是tail的下一个结点是头结点,以此达到循环的目的。循环链表就是将链表的尾结点的下一个结点修改为头结点,其他都和链表相同,注意一些以p!=NULL为终止条件的语句需要修改为p!=head,比如打印链表。
// 头插法构造链表
void headCreateList(T data[], int n) {
for (int i = 0; i < n; i++) {
headInsert(data[i]);
if (i == 0) {
tail = head->next;
}
}
tail->next = head;
}
// 尾插法创建链表
void tailCreateList(T data[], int n) {
for (int i = 0; i < n; i++) {
tailInsert(data[i]);
}
tail->next = head;
}
// 打印链表的所有元素
void dispList() {
listNode<T>* p = head->next;
while (p != head)
{
cout << p->data << " ";
p = p->next;
}
cout << endl;
}测试:
// 循环链表
CircleLinkedList<int> lista = CircleLinkedList<int>();
lista.headCreateList(a, n);
cout << "头插法创建结果:";
lista.dispList();
lista.deleteNode(1);
cout << "头插法删除后结果:";
lista.dispList();
lista.insertNode(2, 7);
cout << "头插法插入后结果:";
lista.dispList();
cout << "头插法查询结果:" << lista.locateElemByIndex(2)->data << endl;
LinkedList<int> listb = LinkedList<int>();
listb.tailCreateList(a, n);
cout << "尾插法创建结果:";
listb.dispList();
listb.deleteNode(1);
cout << "尾插法删除后结果:";
listb.dispList();
listb.insertNode(2, 7);
cout << "尾插法插入后结果:";
listb.dispList();
cout << "尾插法查询结果:" << listb.locateElemByIndex(2)->data << endl; 运行结果:

不知道为什么运行的时候会弹出一个debug assertion failed的框,可能是因为循环链表在访问时会有一些安全隐患,但是输出的都是正常的,我也不知道是哪一步操作出错了,索性先不管了。visual studio实在不会用,不知道为什么其他地方都正常,就是在类里面的代码都不检测语法错误,甚至编译的时候出错也只显示个内部错误,根本不说是哪里错的,搞得我很难受。
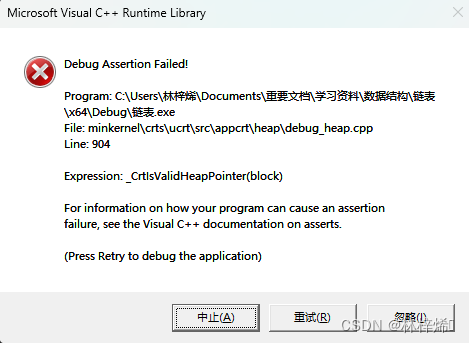
后面在写约瑟夫环的时候调试发现错在哪了,visual studio如果是非调试运行发生异常了也不会告诉你在哪发生异常中断。我错在析构函数的终止条件了,普通链表遍历到尾的条件是遍历指针为空,而循环链表是遍历指针为头指针,其他的函数都改了,唯独忘了析构函数,难怪其他函数运行都正常,在结尾的时候弹出个错误。
// 析构函数,释放链表所有结点占用的内存
~CircleLinkedList() {
listNode<T>* p = head->next;
while (p != head)
{
// 保存p指针,p指针需要先指向下一个结点再删除,因此需要一个指针指向原来的p
listNode<T>* temp = p;
p = p->next;
delete temp;
}
// 删除是从首结点开始的,头结点没有被删除,再最后需要删除头结点
delete head;
tail = NULL;
length = 0;
}三、约瑟夫环
问题描述:
有N个人围成一圈(编号为1~N),从第1号开始进行1、2、...、m报数,凡报m者就退出,下一个人又从1开始报数……直到最后只剩下一个人时为止。请问此人原来的编号是多少?
分别使用两种链表(单链表、循环链表)解决约瑟夫环问题。
1. 单链表
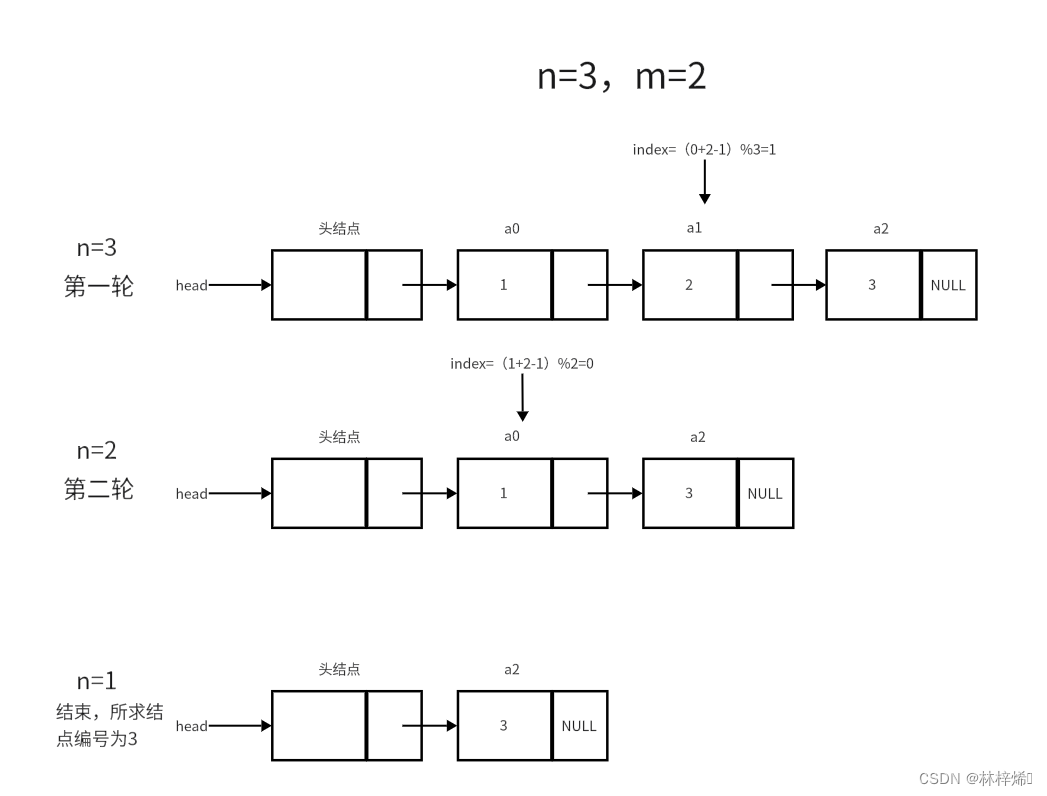
解题思路:约瑟夫环不一定要线性表是循环的,也可以使用下标来实现循环。创建一个单链表存储N个人的编号(1~N),N个人按顺序分别对应线性表的a0,a1,...,an-1。第一轮数到m的人在链表中对应am-1,删除am-1后,am-1原先的位置变为am,此时又重新开始报数,am报数1,则am+2报数m,删除am+2 。根据上面的规律每轮需要删除的结点的下标 index = index + m - 1,也就是每次删除的结点的下标是在上一个删除结点的下标的基础上再加m-1,而N个人是围成一圈的,an-1结点的下一个结点时a0,而单链表是无法实现这个要求的,但是可以先计算出当前要删除的结点下标,再将下标%n来实现虚拟的循环,然后再将该结点删除即可(注意这里的n是当前链表的长度,链表在不断删除结点的过程中n是会变的)。如下图是n=3,m=2的例子的解题步骤。
对应代码:
static int joeCircleUsLList(int n, int m) {
int a[101];
for (int i = 0; i < n; i++)
a[i] = i + 1;
// 默认尾插法创建
LinkedList<int> list = LinkedList<int>(a, n);
int index = 0;
// 循环删除第m个结点直到链表只剩一个结点
while (list.getLength() > 1) {
index = (index + m - 1) % list.getLength();
cout << index << endl;
list.deleteNode(index);
}
// 最后链表中只剩一个结点,即首结点,直接返回首结点的data
return list.getHead()->next->data;
}代码非常简单,只需要计算出每轮需要删除的结点的下标,然后调用deleteNode函数删除该结点即可。
测试:
// 单链表
int n = 3, m = 2;
int number = joeCircleUsLList(n, m);
cout << "n = 3, m = 2时,最后一个结点为:" << number << endl;
n = 5, m = 3;
number = joeCircleUsLList(n, m);
cout << "n = 5, m = 3时,最后一个结点为:" << number << endl;
n = 10, m = 4;
number = joeCircleUsLList(n, m);
cout << "n = 10, m = 4时,最后一个结点为:" << number << endl; 运行结果:

时间复杂度:每次while循环需要进行一次删除结点的操作,而删除结点的操作deleteNode的时间复杂度是O(n),一共n-1次循环,时间复杂度为O(n^2)。
其实根本不应该使用单链表来解决约瑟夫环问题的,因为这种方法根本没有体现链表的特性,随便使用一个线性表都能实现,比如使用数组实现的话更简单,还不需要创建链表这个繁琐的过程。使用单链表解决约瑟夫环只是为了实战一下单链表。
2. 循环链表
解题思路:使用一个循环链表来存储n个人的编号(从1开始),将循环链表中第m个结点删除,再从被删除的人的下一个结点开始,以该结点为第1个结点,顺序向下遍历,将第m个结点删除,重复执行直到链表中只剩一个结点为止,该结点的data即为该结点原来的编号。
对应代码:
// 循环链表解决约瑟夫问题
static int joeCircleUsCLList(int n, int m) {
int a[101];
for (int i = 0; i < n; i++)
a[i] = i + 1;
// 默认尾插法创建
CircleLinkedList<int> list = CircleLinkedList<int>(a, n);
listNode<int>* p = list.getHead()->next, *pre = list.getHead();
// 循环删除第m个结点直到链表只剩一个结点
while (list.getLength() > 1) {
for (int i = 0; i < m - 1; i++) {
pre = p;
p = p->next;
// 循环链表会遍历到头结点head,head不包含信息,不算一个结点,跳过
if (p == list.getHead()) {
pre = p;
p = p->next;
}
}
// p指向的结点删除前需要先将p指向下一个结点,否则结点删除后,
// p指向的结点已经不存在,p无法指向下一个结点
p = p->next;
// 同上
if (p == list.getHead()) {
p = p->next;
}
// 使用p结点前一个结点指针pre删除p指向的结点
list.deleteNodeByPreNode(pre);
}
// 最后链表中只剩一个结点,即首结点,直接返回首结点的data
return list.getHead()->next->data;
}循环链表会比单链表麻烦很多,因为单链表已经定义了按下标删除结点的函数,只要计算出index然后根据index删除结点即可。循环链表则需要循环遍历链表找到第m个结点,然后删除,循环链表才是真正的循环寻找第m个结点,是最适合解决约瑟夫环问题的。遍历时需要注意遍历到头结点需要再向后移一位,因为头结点不算一个结点(不包含信息)。
测试:
// 循环链表
int n = 3, m = 2;
int number = joeCircleUsCLList(n, m);
cout << "n = 3, m = 2时,最后一个结点为:" << number << endl;
n = 5, m = 3;
number = joeCircleUsCLList(n, m);
cout << "n = 5, m = 3时,最后一个结点为:" << number << endl;
n = 10, m = 4;
number = joeCircleUsCLList(n, m);
cout << "n = 10, m = 4时,最后一个结点为:" << number << endl;
n = 7, m = 2;
number = joeCircleUsCLList(n, m);
cout << "n = 7, m = 2时,最后一个结点为:" << number << endl;测试结果:

时间复杂度计算:一共n层while循环,每次while循环需要进行一次遍历找到第m个结点,遍历时执行语句p = p->next,该语句的时间复杂度为O(1),遍历后再继续删除结点,利用前驱结点删除结点的时间复杂度为O(1),则每层循环的时间复杂度为O(m)(m层循环),函数总时间复杂度为O(n*m)。当n和m差距很大时,循环链表解决约瑟夫环比单链表解决约瑟夫环更优。
四、总结
链表的删除和插入操作虽然比较简单,但是如果要根据元素下标来删除和插入操作的话其实跟顺序表也差不多了多少,只是少了一步将后序的元素全部前移的操作,它仍需要先遍历链表找到对应下标的结点,时间复杂度一样是O(n),并不比顺序表更好。只有在知道要删除结点的前一个结点的指针才能直接删除结点(如果是双链表的话只需要知道要删除结点的指针就可以了),这种情况下时间复杂度是O(1),才比顺序表更好。链表相较顺序表的最大优势并不在于插入和删除操作,而是在于链表可以动态的申请空间,而顺序表只能静态申请,一旦申请之后,在它整个生命周期中大小都固定了,因此通常需要申请更大的空间,实际使用时很多空间没有用到,空间利用率很低,而链表动态申请空间就可以根据后续的实际需要来申请对应大小的空间,不会有空间浪费。此外缓冲区中可申请的连续的地址空间其实是很小的,申请的大小过大的话就可能会超出可申请的范围。
链表相较于顺序表实现起来更加的麻烦,链表的创建和访问都比顺序表麻烦的多,而且需要频繁的使用指针,一不小心就容易出错,指针的使用对于初学者来说是很头疼的。在之前我就想过要使用c++写一个链表类封装链表的创建插入删除等基本操作,但因为初学的问题,对指针的了解不够,编写代码的时候频频出错,而且当时使用的是visual studio,不知道为什么visual studio在类中写的代码都不会检查语法错误,编译时出错了很多时候也只说内部错误,不说具体哪错了,于是没多久我就放弃了。这段时间比较闲,于是就想着写了几个基础的链表类,一开始以为会写的很快,结果还是一直出错,八成的时间都在改bug,而且经常在写另一个链表类时发现之前写的代码有问题,又回过头改来改去,最后花费了我一整天的时间才搞定,而且很多链表的实例问题我都没写,只写了一个约瑟夫环,不过能完成这样我感觉勉强算可以了。