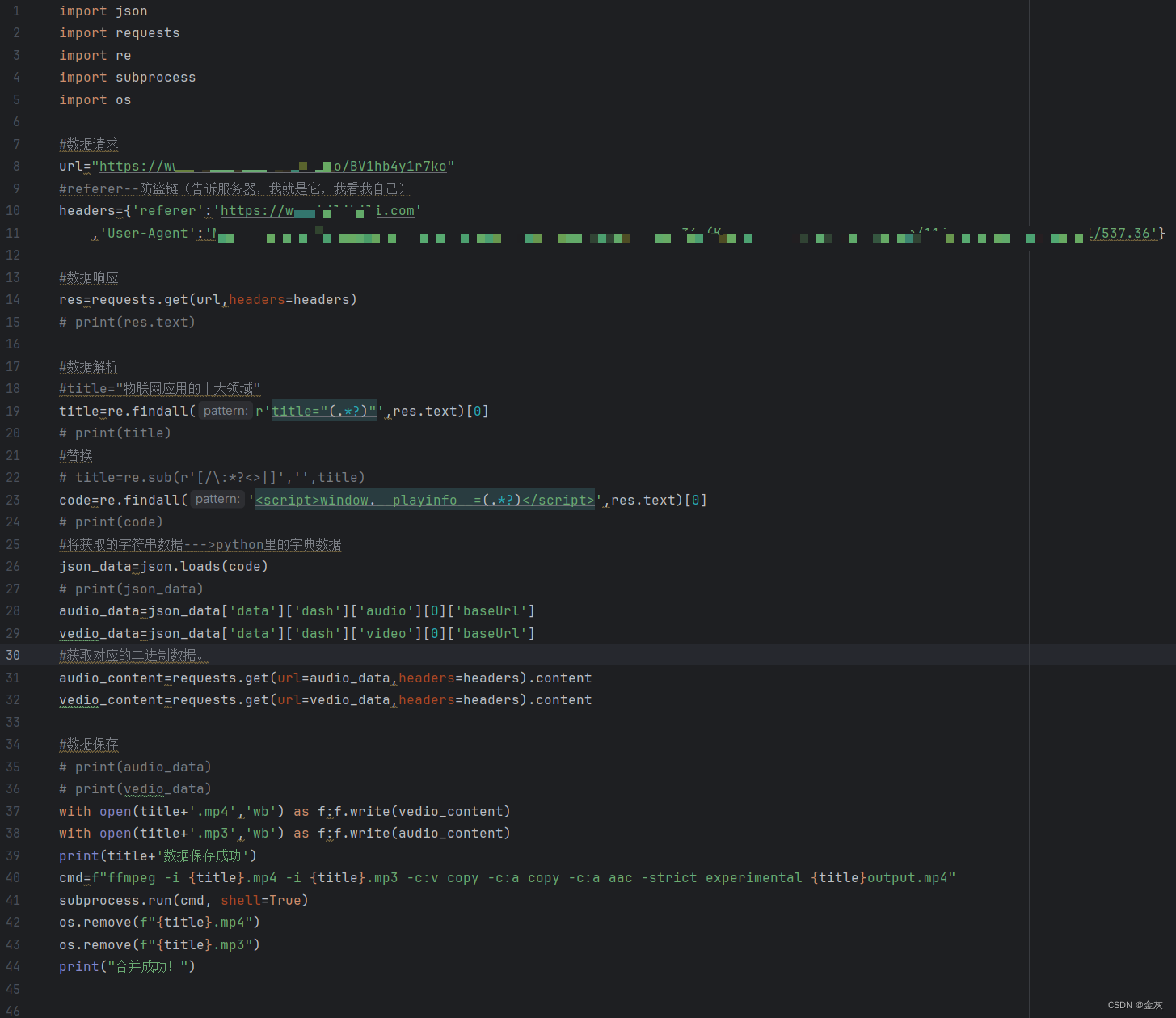
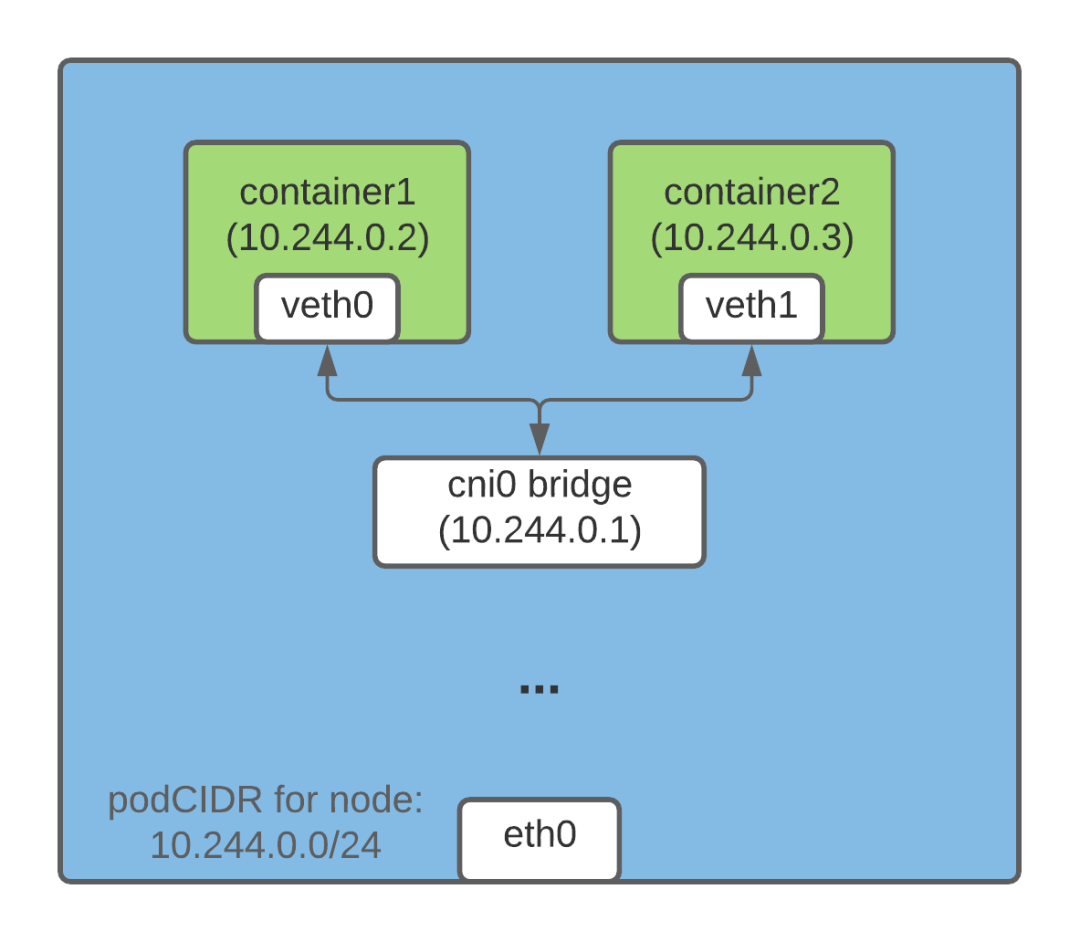
首先手工登录一次获取cookies,然后进行数据保存
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import json
# 创建Chrome浏览器对象
chrome_opt = webdriver.ChromeOptions()
# 开启无界面模式
#chrome_opt.add_argument('--headless')
# 禁用gpu
chrome_opt.add_argument('--disable-gpu')
service = Service('D:/网页数据爬取/selenium练习/chromedriver.exe')
# 创建Chrome浏览器实例
browser = webdriver.Chrome(service=service,options=chrome_opt)
#记得写完整的url 包括http和https
browser.get('https://space.bilibili.com/')
# 等待页面加载完成
browser.implicitly_wait(10)
#程序打开网页后20秒内手动登陆账户
time.sleep(10)
browser.find_element(By.CSS_SELECTOR,'input[type="text"]').send_keys('用户名')
browser.find_element(By.CSS_SELECTOR,'input[type="password"]').send_keys('密码')
#程序打开网页后30秒内手动登陆账户
time.sleep(30)
with open('cookies.txt','w') as cookief:
#将cookies保存为json格式
cookief.write(json.dumps(browser.get_cookies()))
browser.close()
然后使用现有cookies登录用户,进行网页访问,获取清晰视频
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from pprint import pprint
import time
import json
import re
import requests
from moviepy.editor import *
# 创建Chrome浏览器对象
chrome_opt = webdriver.ChromeOptions()
# 开启无界面模式
chrome_opt.add_argument('--headless')
# 禁用gpu
chrome_opt.add_argument('--disable-gpu')
service = Service('D:/网页数据爬取/selenium练习/chromedriver.exe')
# 创建Chrome浏览器实例
browser = webdriver.Chrome(service=service,options=chrome_opt)
#记得写完整的url 包括http和https
browser.get('https://space.bilibili.com/')
#首先清除由于浏览器打开已有的cookies
browser.delete_all_cookies()
with open('cookies.txt','r') as cookief:
#使用json读取cookies 注意读取的是文件 所以用load而不是loads
cookieslist = json.load(cookief)
# 方法1 将expiry类型变为int
for cookie in cookieslist:
#并不是所有cookie都含有expiry 所以要用dict的get方法来获取
if isinstance(cookie.get('expiry'), float):
cookie['expiry'] = int(cookie['expiry'])
browser.add_cookie(cookie)
#记得写完整的url 包括http和https
browser.get('https://space.bilibili.com/')
#程序打开网页后20秒内手动登陆账户
time.sleep(3)
for i in range(96):
num = i+1
url ='https://www.bilibili.com/video/BV1k94y1J7oJ?p=' + str(num)
browser.get(url)
# 等待页面加载完成
browser.implicitly_wait(10)
#网页内容
#print(browser.page_source)
html_text = browser.page_source
obj = re.compile(r'<title data-vue-meta="true">(.*?)</title>', re.S)
html_biaoti = obj.findall(html_text)[0] # 从列表转换为字符串
biaoti = str(html_biaoti).replace('、', '_').replace(',', '_').replace('/', '').replace(' ', '_').replace('|',
'').replace(
'_哔哩哔哩_bilibili', '')
# print('html_biaoti:',biaoti)
# baseUrl视频地址
obj = re.compile(r'window.__playinfo__=(.*?)</script>', re.S)
html_data = obj.findall(html_text)[0] # 从列表转换为字符串
# print(html_data)
json_data = json.loads(html_data)
# 格式化输出,JSON文件美观化
#pprint(json_data)
# video和audio分别时视频与音频
videos = json_data['data']['dash']['video']
video_url = videos[0]['baseUrl']
audios = json_data['data']['dash']['audio']
audio_url = audios[0]['baseUrl']
print('video_url', video_url)
print('audio_url', audio_url)
video_url_m4s = re.compile(r'-\d-\d(.*?).m4s', re.S)
video_url_m4s = video_url_m4s.findall(video_url)[0]
video_url_m4s = int(video_url_m4s)
print('video_url_m4s', video_url_m4s)
# cookies做拼接
cookies_list = [item["name"] + "=" + item["value"] for item in browser.get_cookies()]
cookies = ';'.join(it for it in cookies_list)
print(cookies)
# 得到cookies后,即可使用requests来做接口爬虫
headers = {
'Cookie': f'{cookies}',
"Referer": "https://space.bilibili.com/86219219/favlist?spm_id_from=333.788.0.0",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.51 Safari/537.36'
}
#判断视频清晰度
if video_url_m4s >= 64:
resp1 = requests.get(url=video_url, headers=headers)
with open(biaoti + '.mp4', mode='wb') as f:
f.write(resp1.content)
resp2 = requests.get(url=audio_url, headers=headers)
with open(biaoti + '.mp3', mode='wb') as f:
f.write(resp2.content)
# 视频音频文件组合
video_path = biaoti + '.mp4'
audio_path = biaoti + '.mp3'
# 提取音轨
audio = AudioFileClip(audio_path)
# 读入视频
video = VideoFileClip(video_path)
# 将音轨合并到视频中
video = video.set_audio(audio)
# 输出
video.write_videofile(f"{biaoti}(含音频).mp4")
time.sleep(1)
# 将涉及MP3MP4清除
try:
os.remove(video_path)
except:
pass
try:
os.remove(audio_path)
except:
pass
print(num, biaoti, '爬取完成')
#break
time.sleep(60)