一、类偏斜的误差度量
误差度量的关键性
之前的课程中已经提到了误差分析和设定误差度量值的重要性。评估学习算法并衡量其表现需要使用一个实数,这就是误差度量值。然而,在某些情况下,特别是当处理偏斜类时,选择正确的误差度量值可能会对算法的性能产生微妙但重要的影响。
偏斜类的问题
偏斜类的情况发生在训练集中某一类实例数量非常多,而其他类的实例数量很少或没有的情况下。举例来说,如果希望用算法来预测肿瘤是否是恶性的,而在训练集中只有0.5%的实例是恶性肿瘤,就会面临偏斜类的问题。

查准率和查全率
为了解决偏斜类问题,我们引入了两个重要的概念:查准率(Precision)和查全率(Recall)。
查准率:表示在所有预测为正例的样本中,实际为正例的比例。计算方式为查准率=TP/(TP+FP)。在肿瘤预测中,查准率高表示在我们预测为恶性的病人中,实际上有恶性肿瘤的比例高。
查全率:表示在所有实际为正例的样本中,成功预测为正例的比例。计算方式为查全率=TP/(TP+FN)。在肿瘤预测中,查全率高表示在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的比例高。

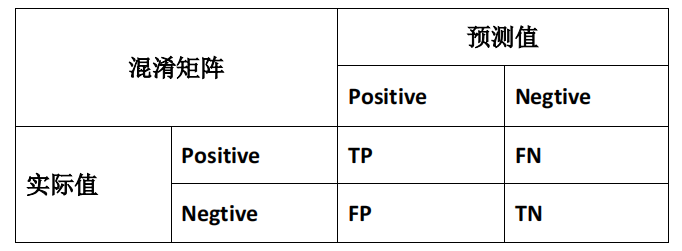
混淆矩阵
为了更清晰地理解查准率和查全率,引入了混淆矩阵。混淆矩阵以预测值和实际值的正负情况为基础,划分为True Positive(真正例)、True Negative(真负例)、False Positive(假正例)、False Negative(假负例)四个部分。

二、查准率和查全率之间的权衡
重温查准率和查全率
在之前的课程中,我们已经了解了查准率(Precision)和查全率(Recall)的概念。查准率表示在所有预测为正例的样本中,实际为正例的比例,而查全率表示在所有实际为正例的样本中,成功预测为正例的比例。
查准率(Precision):Precision = TP/(TP+FP),在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(Recall):Recall = TP/(TP+FN),在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。

权衡查准率和查全率
假设我们的算法输出的结果在 0-1 之间,使用阀值 0.5 来预测真和假。我们可以通过调整阀值来平衡查准率和查全率。如果我们希望提高查准率,可以使用比 0.5 更大的阀值,如 0.7 或 0.9。反之,如果希望提高查全率,可以使用比 0.5 更小的阀值,如 0.3。
F1 值的引入
为了更有效地权衡查准率和查全率,引入了 F1 值(F1 Score)。F1 值是查准率和查全率的调和平均数,计算公式为:
![]()
F1 值的范围在 0 到 1 之间,取得最高值的阀值即为我们选择的阀值。通过计算 F1 值,我们可以在查准率和查全率之间找到一个平衡,选择一个适当的阀值来优化算法性能。

三、机器学习的数据
在这段视频中,我们探讨了机器学习系统设计中一个重要的方面,即训练数据的数量对算法性能的影响。在研究中,研究人员Michele Banko和Eric Brill进行了一项实验,通过使用不同大小的训练数据集来比较不同学习算法的性能。
他们发现,随着训练数据集的增大,大多数算法表现出相似的性能提升趋势。即使是一些算法可能被认为是“劣等”的,但通过提供更多的训练数据,它们的性能可能超越一些被认为是“优等”的算法。这引发了一个普遍的共识:“在机器学习中取得成功的关键不在于拥有最好的算法,而在于拥有最多的数据。”

这个结论的前提条件是:首先,特征值𝑥包含足够的信息,使得人类专家能够准确预测𝑦值。其次,有大量的训练数据,且训练的学习算法具有足够多的参数,例如逻辑回归、线性回归或神经网络等。
这样的研究结果表明,大量的训练数据可以弥补算法的一些不足,甚至在某些情况下,数据的重要性可能超过选择算法的重要性。因此,在实践中,获取更多的训练数据可能是提高机器学习算法性能的有效途径。
请注意,这个结论并不适用于所有情况,而是在特定条件下成立。如果特定问题中特征包含足够信息,而且有足够的训练数据,那么增加数据量可能是改善算法性能的一种方法。
参考资料:























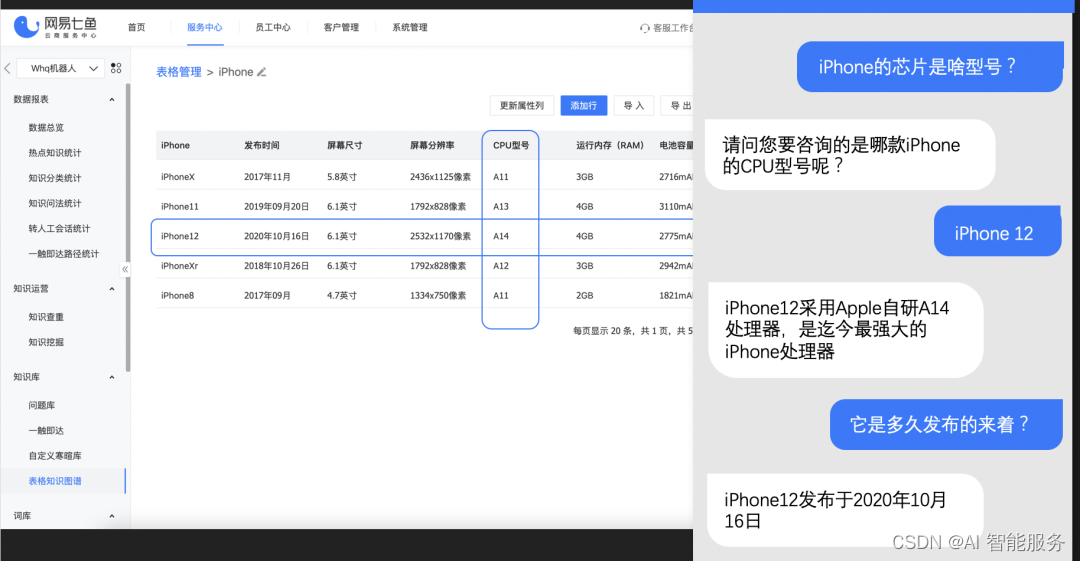


![[数据挖掘、数据分析] clickhouse在go语言里的实践](https://img-blog.csdnimg.cn/33371cb205b14839a4fd8f047f509b7f.png)