Transformer 是一种深度学习模型结构,最初由Vaswani等人于2017年提出,用于自然语言处理任务,尤其是机器翻译。Transformer 引入了自注意力机制(self-attention mechanism),这是其在处理序列数据时的关键创新。
以下是 Transformer 模型的主要组成部分和机制:
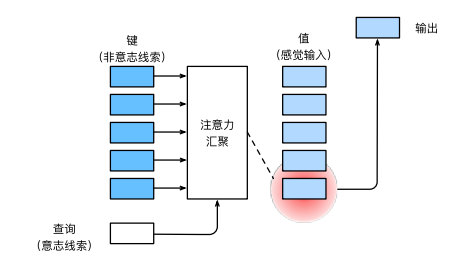
自注意力机制(Self-Attention):
- 自注意力机制允许模型在处理序列数据时为每个位置分配不同的注意力权重。给定一个输入序列,自注意力机制可以计算每个位置与其他所有位置之间的注意力权重。这使得模型能够更好地捕捉序列中不同位置之间的依赖关系。
多头注意力(Multi-Head Attention):
- 为了增强模型对不同信息尺度的表示能力,Transformer 引入了多头注意力机制。通过使用多个注意力头,模型可以学习多个不同的注意力权重,从而捕捉不同层次和方向的语义信息。
位置编码(Positional Encoding):
- 由于 Transformer 不包含序列顺序信息,为了将位置信息引入模型,位置编码被加到输入嵌入中。这允许模型区分序列中不同位置的单词。
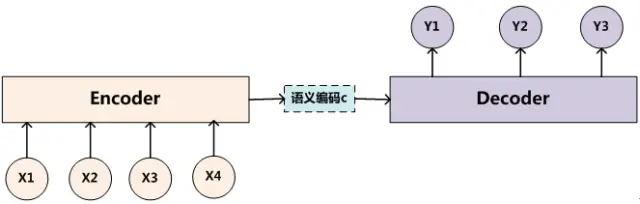
编码器-解码器结构:
- Transformer 通常由编码器和解码器组成,用于处理不同任务,例如机器翻译。编码器用于处理输入序列,解码器用于生成输出序列。它们都包含多个层,每个层都包含自注意力机制和前馈神经网络。
残差连接和层归一化:
- 在每个子层(如自注意力和前馈神经网络)的输入和输出之间都存在残差连接,有助于防止梯度消失问题。此外,层归一化用于规范每个子层的输出。
Transformer 的创新极大地改变了自然语言处理领域,使得模型在处理长序列和捕捉全局依赖关系方面更为有效。此外,由于其通用性,Transformer 的思想也被应用于其他领域,例如计算机视觉和强化学习。
























![[数据挖掘、数据分析] clickhouse在go语言里的实践](https://img-blog.csdnimg.cn/33371cb205b14839a4fd8f047f509b7f.png)