MVC与MTV模型
MVC
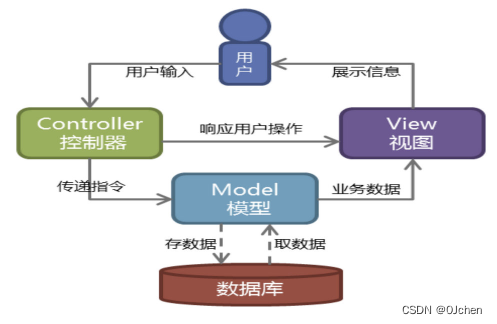
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为
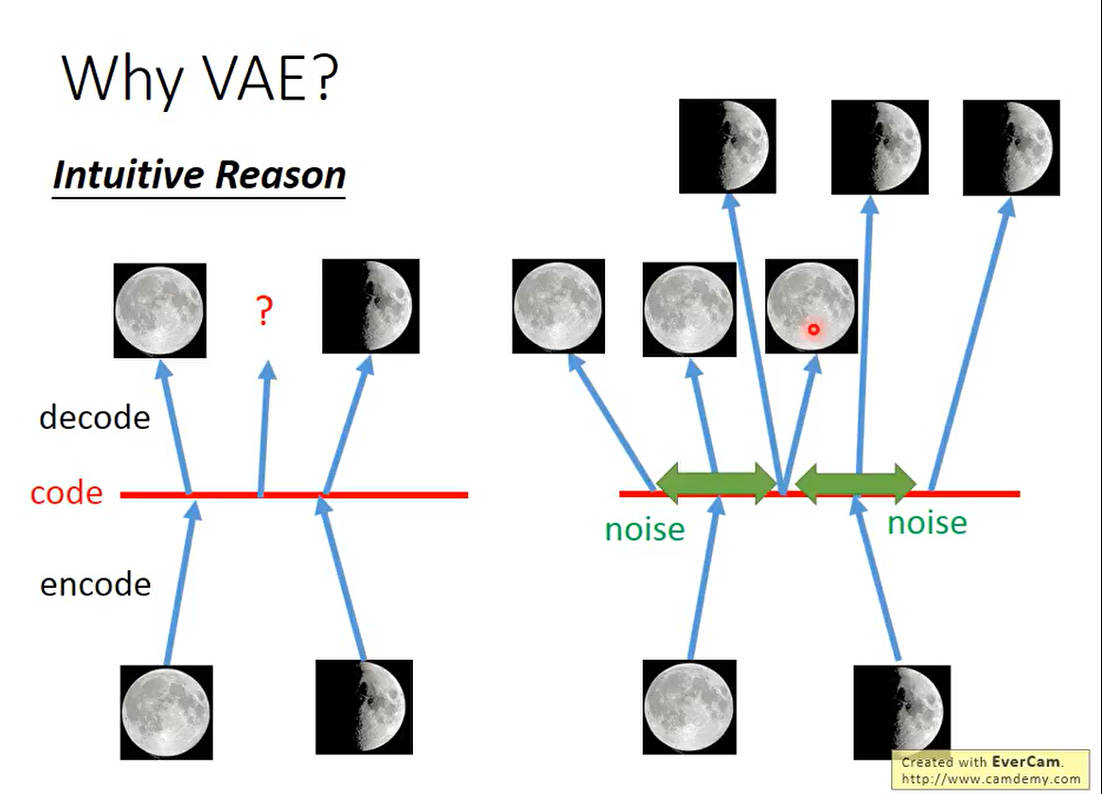
模型(M:数据层),控制器(C:逻辑判断)和视图(V:用户所看的)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示:
MTV
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
- M 代表模型(Model):负责业务对象和数据库的关系映射(ORM)。
(M 就是 MVC 的 M) - T 代表模版(Template):负责如果把页面展示给用户(HTML)。
(T 就是 MVC 的 V) - V 代表视图(View):负责业务逻辑,并在适当时候调用Model和Template
(V+路由 就是 MVC 的 C)
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示:
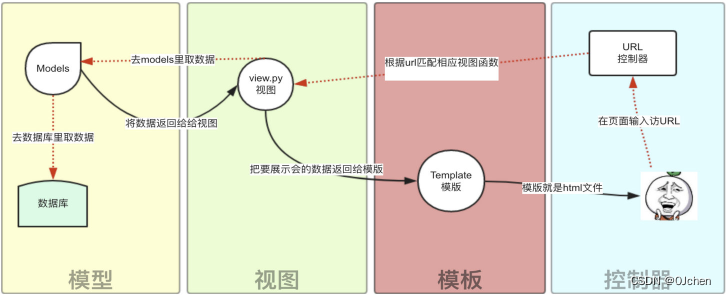
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模版也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模版中的空格中,最后返回页面给用户
Django目录结构
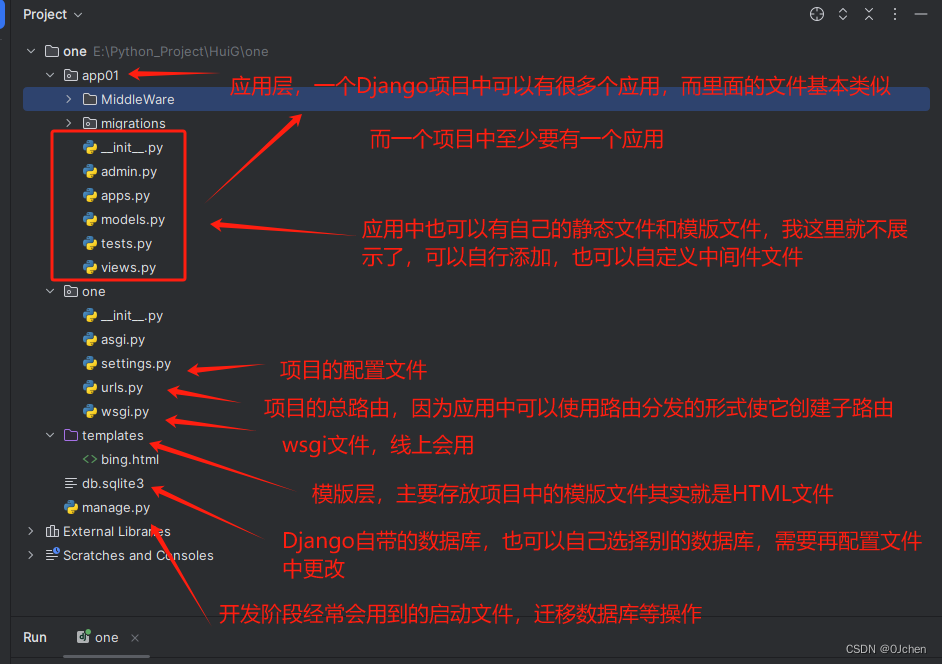
django项目目录
项目同名文件夹
__init__.py 很少用 主要做一些冷门配置
settings.py 项目的全局配置文件
urls.py 路由文件,写地址的后缀和视图函数的对应关系
wsgi.py django服务 基本不用
manage.py django的启动文件、入口文件
templates文件夹 模版文件,存储项目所需的html文件
应用名文件夹(可以有多个)
migrations文件夹 orm相关(数据库打交道的记录)
__init__.py 很少用 主要做一些冷门配置
admin.py django自带的后台管理系统
apps.py 创建应用之后用于应用的注册
models.py 模型层,存储与数据库表相关的类
tests.py 自带的测试文件
views.py 视图文件。存储业务相关的逻辑代码(函数、类)
db.sqlite3 自带的小型数据库
urls.py 路由层
views.py 视图层
templates 模板层
models.py 模型层
更多Django基本操作可以去看我的这篇博客https://blog.csdn.net/achen_m/article/details/134296792?spm=1001.2014.3001.5501
Django请求生命周期流程图

django的生命周期是从用户发送HTTP请求数据到网站响应的过程。
整个过程的流程:
1.首先,用户在浏览器输入一个URL,发送一个请求
2.在django中有一个封装的socket的方法模块wsgiref,监听端口接收request请求,并且封装传送到中间件中。
3.在由中间件传输到路由系统中进行路由分发,匹配相对应的视图函数
4.将reqeust请求传输到视图函数中进行逻辑处理。
5.调用models中表对象,然后通过ORM操作数据库拿到数据,同时去templates中去相应的模版文件中进行渲染
6.然后返回到中间件中,进行response响应返回数据到wsgiref中进行封装后再返回给浏览器展示给用户
路由控制
此处只做补充知识,想看更多可查看我的这篇博客了解https://blog.csdn.net/achen_m/article/details/134377889?spm=1001.2014.3001.5501
路由是什么
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于客户端发来的某个URL调用哪一段逻辑代码对应执行
(请求路径和要执行的视图函数的关系)
路由匹配
此处只说2.X版本以上使用的关键字path,想看1.X的可以前去上面标题处的连接
在django2.x及以上版本:path第一个参数写什么就匹配什么(精准匹配),匹配到直接执行对应的视图函数
path('admin/',函数名), '这种写法不支持正则表达式'
当然2.x版本也有可以使用正则匹配的方式:
re_path(正则表达式,函数名) '其作用和django1.x的url使用效果一模一样'
'但是因为有转换器,基本就用不上re_path这个关键字,而且正则匹配本就不是那么的安全'
path的详细使用
urlpatterns = [
path('admin/', views.admin),
]
等价于:_path(route, view, kwargs=None, name=None)
第一个参数:
精准路径,字符串
可以使用转换器:'<int:pk>' '<str:name>'
例子:
path('index/<int:year>/<str:info>/',views.index)
转换器有几个名字,那么视图函数的形参就必须对应
视图层:
def index(request,year,info):
print(year,info)
return HttpResponse('from index')
第二个参数:视图函数的内存地址,不要加括号
1.路由一旦匹配成功,就会执行,你写的这个视图函数(request),并且会把request对象传入
2.如果有分组的参数[有名分组、无名分组],或者转换器的参数,都会被传递到视图函数中作为参数
'''
总结:需要放视图函数内存地址------》视图函数的第一个参数是固定的,必须是reqeust,后续的参数取决于
写没写转换器或者写没写有名分组、无名分组
'''
第三个参数:kwargs 是给视图函数传递默认参数
第四个参数:是路径的别名---》主要用于反向解析得到该路径
而
re_path除了第一个参数不一样以外,其他完全和path是一样的。re_path第一个参数是正则表达式
现在基本很少使用
re_path,因为危险性比较大,原来之所以使用就是为了使用正则匹配分组出参数,现在path可以通过转换器就能完成这个操作,所以基本不使用re_path
反向解析
在使用Django 项目时,一个常见的需求是获得URL 的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
反向解析为的就是防止路由经常变动,这样我们页面的链接、或者函数的重定向就能动态获取到路由可接收的URL。
此处也仅用path来讲述
'反向解析,用于视图函数中、用于模版中'
1.没有转换器的情况:
path('index/', views.index,name='index'),
'视图函数'
from django.shortcuts import HttpResponse,reverse
def index(request):
reverse('index') # 定义路径传入的name参数对应的字符串
2.有转化器的情况:
path('index/<str:name>', views.index,name='index'),
'视图函数'
from django.shortcuts import HttpResponse,reverse
def index(request):
reverse('index',kwargs={
'name':'jack'})
'最后生成的路径:URL/index/jack'
路由分发
django是专注于开发应用的,当一个django项目特别庞大的时候所有的路由与视图函数映射关系全部写在总的urls.py很明显太冗余不便于管理,其实django中的每一个app应用都可以有自己的urls.py、static文件夹、templates文件夹,基于上述特点,使用django做分组开发非常的简便。
可以分开写多个app应用,最后再汇总到一个空的Django项目然后使用路由分发将多个app应用关联起来。
未使用路由分发前:所有请求都由主路由转发到对应视图函数,全部都在一个urls.py文件内。
为什么默认路由匹配能匹配到urls.py文件呢?是因为在settings配置文件中配置了ROOT_URLCONF = 'django_项目名.urls'
路由分发需要使用到关键字include
from django.urls. import path,include
主路由:
urlpatterns = [
path('admin/', admin.site.urls),
path('app01/', include('app01.urls')),
]
然后需要再应用里面建立一个urls.py文件
充当子路由
from django.urls import path
from app01 import views
urlpatterns = [
path('index/',views.index),
]
视图层
django视图层:Django项目下的views.py文件,它的内部是一系列的函数或者是类,用来处理客户端的请求后处理并返回相应的数据
视图层,熟练掌握两个对象即可:请求对象(request)和响应对象(HttpResponse)
视图函数语法
'视图函数必须要有一个reqeust参数,并且必须要返回一个HttpResponse对象'
def index(reqeust):
return HttpResponse('hello,world')
reqeust对象属性
django将请求报文中的请求行、首部信息、内容主体封装成 HttpRequest 类中的属性。 除了特殊说明的之外,其他均为只读的
'它是http请求(数据包----》字符串形式)-----》拆分成了django中的reqeust对象'
request对象常用的属性:
request.GET 一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。
reqeust.POST 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。
reqeust.body
一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,例如:二进制图片、XML,Json等。
但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。
request.path 一个字符串,表示请求的路径组件(不含域名)。例如:"/music/bands/the_beatles/"
request.method 一个字符串,表示请求使用的HTTP 方法。必须使用大写。例如:"GET"、"POST"
reqeust.FILES 一个类似于字典的对象,包含所有的上传文件信息。
request对象不常用的属性:
request.cookie
reqeust.session
reqeust.content_type:提交的编码格式:'urlencoded(form表单),json,form-data,text/plain(一般不用,浏览器默认格式)'
reqeust.META:请求头中的数据
一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端和服务器,下面是一些示例:
取值:
CONTENT_LENGTH —— 请求的正文的长度(是一个字符串)。
CONTENT_TYPE —— 请求的正文的MIME 类型。
HTTP_ACCEPT —— 响应可接收的Content-Type。
HTTP_ACCEPT_ENCODING —— 响应可接收的编码。
HTTP_ACCEPT_LANGUAGE —— 响应可接收的语言。
HTTP_HOST —— 客服端发送的HTTP Host 头部。
HTTP_REFERER —— Referring 页面。
HTTP_USER_AGENT —— 客户端的user-agent 字符串。
QUERY_STRING —— 单个字符串形式的查询字符串(未解析过的形式)。
REMOTE_ADDR —— 客户端的IP 地址。
REMOTE_HOST —— 客户端的主机名。
REMOTE_USER —— 服务器认证后的用户。
REQUEST_METHOD —— 一个字符串,例如"GET" 或"POST"。
SERVER_NAME —— 服务器的主机名。
SERVER_PORT —— 服务器的端口(是一个字符串)。
从上面可以看到,除 CONTENT_LENGTH 和 CONTENT_TYPE 之外,请求中的任何 HTTP 首部转换为 META 的键时,
都会将所有字母大写并将连接符替换为下划线最后加上 HTTP_ 前缀。
所以,一个叫做 X-Bender 的头部将转换成 META 中的 HTTP_X_BENDER 键。
'''
用户自定义写的例如:name=jack
取:request.META.get('HTTP_NAME') # 前面加上HTTP_把自定义的转成大写
'''
reqeust对象方法
1.HttpRequest.get_full_path()
返回 path,如果可以将加上查询字符串。
例如:"/music/bands/the_beatles/?print=true"
注意和path的区别:http://127.0.0.1:8001/order/?name=lqz&age=10
2.HttpRequest.is_ajax()
如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH
相应的首部是否是字符串'XMLHttpRequest'。
大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),
你必须手工设置这个值来让 is_ajax() 可以工作。
如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware,
你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。
HttpResponse对象(响应)
当浏览器向服务器发起数据请求的时候,那么服务器用来响应的视图函数的返回值的种类有两种,分别是
HTML响应(HttpResponse、render、redirect)和JsonResponse(前后端分离)
而其中HTML的三种响应方式返回的都是一个HttpResponse对象(可以查看源码)
'''源码大概注解展示'''
1.HttpResponse()
HttpResponse()括号内直接跟一个具体的字符串作为响应体,比较直接很简单,所以这里主要介绍后面两种形式。
class HttpResponse(HttpResponseBase):
'''括号内直接跟一个具体的字符串作为响应体'''
streaming = False # 表示是否支持流式传输
# 初始化HttpResponse实例,设置响应的内容
def __init__(self, content=b'', *args, **kwargs):
super(HttpResponse, self).__init__(*args, **kwargs)
# Content is a bytestring. See the `content` property methods.
self.content = content
......
2.render()
render方法就是将一个模版页面中的模版语法进行渲染,最终渲染成一个html页面作为响应体
'结合一个给定的模版和一个给定的上下文字典,并返回一个渲染后的HttpResponse对象。'
def render(request, template_name, context=None, content_type=None, status=None, using=None):
'''
参数:
request:用于生成响应的请求对象
template_name:要使用的模版的完整名称,可选的参数
context:添加到模版上下文的一个字典。默认是空字典。如果字典中的某一个值是可调用的,视图将在渲染模版之前调用它。
status:响应的HTTP状态码,默认Django状态码为200
content_type:响应的内容类型如:text/html、application/json等
'''
# 使用Django的模版引擎加载和渲染模版
content = loader.render_to_string(template_name, context, request, using=using)
# 返回一个HttpResponse对象加括号调用HttpResponse的类
return HttpResponse(content, content_type, status)
注意:渲染模版是在后端完成的,是从模版层渲染模版,把相应的模版语法写入到模版中,然后返回到后端视图层,经过响应对象处理成字符串形式。而js代码是在客户端浏览器里执行的
3.redirect()
传递要重定向的一个硬编码的URL,当然也可以是一个完整的URL
def my_view(request):return redirect(‘/some/url/’) |||| def my_view(request):return redirect(‘https://www.baidu.com/’)
def redirect(to, *args, **kwargs):
'传递要重定向的一个硬编码的URL或者路由'
if kwargs.pop('permanent', False):
'如果参数中包含 'permanent',并且其值为 True,则使用 HttpResponsePermanentRedirect 类'
redirect_class = HttpResponsePermanentRedirect
else:
'否则使用默认的 HttpResponseRedirect 类,而这个类中就规定了响应状态码为3开头的重定向'
redirect_class = HttpResponseRedirect
'''
这里返回一个HttpResponse对象加括号调用HttpResponse的类
创建相应的重定向对象,将重定向目标设置为 to
'''
return redirect_class(resolve_url(to, *args, **kwargs))
'''
这样的设计使得 redirect 函数能够支持两种类型的重定向:
临时重定向(HttpResponseRedirect)和永久重定向(HttpResponsePermanentRedirect),
具体取决于 'permanent' 参数的值。
'''
301和302的区别:
301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从
响应的Localtion首部中获取(用户看到的效果就是他输入的地址A瞬间便槽了另一个地址B)-----这是它们的共同点。
它们的不同在于:
301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的地址;
302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地2从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存就得网址。
'''
重定向的原因:
1.网站调整(如改变网页目录结构);
2.网页被移到一个新地址;
3.网页拓展名改变(如应用需要把,.php改成.html或者.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个404页面错误
访问流量白白丧失;在这某些注册了多个域名的网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点
'''
注意:redirect重定向,字符串参数不能是空的,它的响应状态码是3开头(可以从源码中的看到最后类加括号实例化对象,并且给参数都传入到其中了,而这两个类中就是有规定响应状态码为301或者302),
JsonResponse
JsonResponse源码分析
return JsonResponse({
'name': 'jack', 'age': 19})
'首先类名加括号实例化对象,触发 JsonResponse的__init__方法把字典给到了data参数'
class JsonResponse(HttpResponse): # 这里可以看到JsonResponse也是继承了HttpResponse类
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
'''
参数解读:
data:需要序列化为JSON并包含响应中的数据
encoder:要使用的JSON编码器类
safe:一个布尔参数,为True时要求data参数是一个字典,False时则允许序列化非字典类型对象
json_dumps_params:传递给'json.dumps'函数的额外参数。
**kwargs:用于配置HTTP响应的其他关键字参数
'''
if safe and not isinstance(data, dict):
'''
此处的判断为safe默认为True,而当data数据传入进来不是字典格式就为True然后取反为False,然后判断True and False
当后面取反后还为True则执行此语句,否则直接往下执行
所以这里的safe也是可以在返回的时候更改成False,使其别的类型都可以序列化
isinstance(对象, 类) 判断这个对象,是不是这个类的对象
'''
raise TypeError( # 断言报错
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
'''
json_dumps_params从最上面__init__那里参数可以看到默认为空,所以会执行里面的语句
'''
if json_dumps_params is None:
json_dumps_params = {
} # 设置为空字典
'kwargs配置关键字参数,所以格式是字典类型,而setdefault则是字典的方法设置默认关键字,有则修改无则增加'
'这里面的就是{content_type:application/json}'
kwargs.setdefault('content_type', 'application/json')
'''
最后把data参数序列化,也就是把字典转换成json格式的字符串,然后在赋值给data
而这里面的**json_dumps_params是传递给json.dumps的额外参数,例如默认状态下Django使用中文会默认转码,
而序列化模块json是有着去掉转码中文的属性的,但是Django中不能直接使用,所以需要传递到这个里面使其不自动转码
json_dumps_params={'ensure_ascii':False},因为是两个星星所有会是把传入的参数打散成K:V键值,所以是字典的形式
'''
data = json.dumps(data, cls=encoder, **json_dumps_params)
'super().__init__调用父类(HttpResponse)的__init__,完成实例化,然后传递序列化后的JSON数据及其他参数'
'以序列化的数据作为响应的内容,并传递任何其他关键字参数,这初始化了HTTP响应对象'
super().__init__(content=data, **kwargs)
本质是把传入的字典或者列表(如果是其他类型需要指定safe=False),使用json序列化得到json格式字符串,最终做成HttpResponse对象返回给前端,如果想给json序列化的时候传参数,必须使用json_dumps_params字典传入
补充:如果想往响应头中写数据,需要传入headers={'xxx':'xxx'}
所以说响应对象本质上都是HttpResponse
CBV和FBV
FBV
(Function Base Views)基于函数的视图;在视图里面通过函数来处理请求、响应请求。在之前Django学习中我们一直使用的都是这种方式。这里就不过多介绍了
Python是一个面向对象的编程语言,如果只用函数来开发,很多面向对象的优点就错失了(继承、封装、多态)。所以Django在后来加入了Class-Based-View。可以让我们用类写View。这样做的优点主要下面两种:
- 提高代码的复用性,可以使用面向对象的技术。
- 根据不同的类方法处理不同的HTTP请求,而不是通过很多if判断,提高代码可读性。
CBV
(Class Base Views)基于类的视图;在视图里通过面向对象的方式来处理、响应请求
CBV的写法,典型
路由配置:
urlpatterns = [
path('index/',views.视图类名.as_view()), # as_view是类的绑定方法
]
视图层:
from django.views import View
class UserView(View):
# 写方法----》与请求同名的方法
def get(self,request):
return 必须返回四件套(render/HttpRespone/redirect/JsonResponse)
CBV部分源码解读
我们目前只需要看这一些就行了
path('index/', index),--->请求来了,路由匹配成功会执行 index(request,)
path('index/', views.视图类名.as_view()), 执行绑定类的方法,然后把request传入进去
'入口:路由----从as_view来开始'
class View:
'这是一个类级别的属性,包含了视图类允许处理的HTTP方法列表,默认包含了常见的HTTP方法'
http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
@classonlymethod
def as_view(cls, **initkwargs):
#这是一个类方法,用于返回一个可调用对象(通常是函数),该对象实际会处理视图的逻辑,在这个方法内部创建了一个嵌套函数
'''
-请求来了,路由匹配成功后,执行视图类.as_view()(request)
-
'''
def view(request, *args, **kwargs): # view函数会创建视图类的实例化self。方法可以加括号调用
self = cls(**initkwargs)
'''
setup括号内会将reqeust请求给这个对象作为属性
而args、kwargs则是防止有名、无名分组,用于接收分组产生的值,也一同赋给此对象
'''
self.setup(request, *args, **kwargs) #用于初始化视图实例,会将reqeust对象等参数传递到这里
if not hasattr(self, 'request'): # 判断类是否有这个属性,没有则执行断言语句
raise AttributeError(
"%s instance has no 'request' attribute. Did you override "
"setup() and forget to call super()?" % cls.__name__
)
'调用这个对象下面的dispatch方法,并将Django传递的参数一并带过去了'
return self.dispatch(request, *args, **kwargs)
'''
小结:
def view(request,*args,**kwargs)
-本质上就是在执行 view(request)
-本质上也是执行完毕上面的参数后再执行dispatch
首先会去视图类中找,如果找不到就会去父类view中找。
'''
def dispatch(self, request, *args, **kwargs):
'''
request当次请求的请求对象,取出请求方式,假设是get请求,就会转换成小写的get
self.http_method_names是用于存放允许处理的请求方式列表,当get请求在这个列表中
就直接返回get(reqeust,*args,**kwargs) 真正执行原来视图函数的内容
'''
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
'对象的反射方法,通过字符串去对象中取出属性或方法'
'而这个self是谁调用的就是谁,我们是通过视图类调用的所以是视图类'
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
'''
小结:
dispatch方法是一个实例方法,用于根据请求的方法分派到相应的处理方法。
它检查请求的方法是否在允许的方法列表中,如果是则调用对应的处理方法,否则调用self.http_method_not_allowed方法
如果请求的方法在这个请求列表中,它会使用getattr获取相应的处理方法
最后提哦啊用得到的处理方法,并传递请求和其他参数
'''
总结:写cbv,只需要在视图类中写跟请求方式同名的方法即可。而不同请求方式,就会执行不同的方法
上传图片
使用CBV方式上传图片到Django项目中
路由配置:
urlpatterns = [
path('myfiles/',views.MyView.as_view()),
]
视图配置:
from django.views import View
class MyFile(View):
def get(self,request):
return render(request,'mj.html')
def post(self,request):
myfile = request.FILES.get('myfile')
print(myfile.name)
with open(myfile.name,'wb')as f:
for line in myfile:
f.write(line)
return HttpResponse('上传成功')
模版层:
<form action="" method="post" enctype="multipart/form-data">
{
% csrf_token %}
<input type="file" name="myfile">
<br>
<input type="submit" value="提交">
</form>
模版层
简介
模版层文件在浏览器中是运行不了的,因为它有模版语法,浏览器解析不了模版语法,必须在后端渲染完成(替换完成),变成纯粹的html,css,js
而这种在后端会被渲染的,类python语法,他叫模版语法,在Django中它又叫
dtl(django template language)
你可能已经注意到我们在例子视图中返回文本的方式有点特别。 也就是说,HTML被直接硬编码在 Python代码之中。
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
尽管这种技术便于解释视图是如何工作的,但直接将HTML硬编码到你的视图里却并不是一个好主意。 让我们来看一下为什么:
- 对页面设计进行的任何改变都必须对 Python 代码进行相应的修改。 站点设计的修改往往比底层 Python 代码的修改要频繁得多,因此如果可以在不进行 Python 代码修改的情况下变更设计,那将会方便得多。
- Python 代码编写和 HTML 设计是两项不同的工作,大多数专业的网站开发环境都将他们分配给不同的人员(甚至不同部门)来完成。 设计者和HTML/CSS的编码人员不应该被要求去编辑Python的代码来完成他们的工作。
- 程序员编写 Python代码和设计人员制作模板两项工作同时进行的效率是最高的,远胜于让一个人等待另一个人完成对某个既包含 Python又包含 HTML 的文件的编辑工作。
基于这些原因,将页面的设计和Python的代码分离开会更干净简洁更容易维护。 我们可以使用 Django的 模板系统 (Template System)来实现这种模式,这就是本章要具体讨论的问题
自定义过滤器和标签
定义自定义过滤器和标签步骤:
1.首先在settings配置文件中的NSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag
2.在配置好的app中创建一个templatetags模块(模块名只能是templatetags)'注意:模块是建一个包'
3.然后在包下创建一个任意的py文件,例如my_tags.py
4.在py文件中写入:
register = template.Library() 'register的名字是固定的,不能更改'
'自定义过滤器'
from django import template
@register.filter
def filter_words(content: str) -> str:
'''
此处的content:str的写法是当pycharm不知道是否是什么的时候,你自己知道会传入的是什么类型的参数就可以强行指定一个
这样当你使用这个参数点的时候就会提示相应类型的属性提示,它们都不会影响程序的操作,仅仅作为给自己的提示
'''
l = ['妈的','傻逼','退游']
'这里你也可以导入数据库中的数据,我这里就不做多演示,就直接写死'
for item in l:
'把content中所有对应上面列表中的关键字替换成**'
content = content.replace(item,'**')
return content
视图层:
def wan(request):
content = '今天天气真他妈的好,但是碰见一个傻逼了,想退游了'
return render(request,'test.html',{
'content':content})
'随意定义一个'
模版层:
<h1>过滤</h1>
'''需要先导入'''
{
% load my_filter %}
<p>{
{
content|filter_words }}</p> # 过滤器模版语法
'自定义标签'
from django.utils.safestring import mark_safe
# 自定义标签
@register.simple_tag
def my_input(id,arg):
res = "<input type='text' id='%s' class='%s'></input>"%(id,arg)
return mark_safe(res) # 必须返回这个mark_safe因为django中不指定safe参数渲染到前端是字符串
模版层:
<h1>标签替换</h1>
{
% my_input 7 'red' %}
注意:自定义的过滤器可以在if等语句中使用,但是自定义的标签不可以
其他模版层的知识可以去看我这篇博客[https://blog.csdn.net/achen_m/article/details/134423737]
(https://blog.csdn.net/achen_m/article/details/134423737),我这里就不重新写了。
模型层
简介
- MVC或者MTV框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以请求更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- 而ORM就是"对象—关系—映射"的简称。
ORM框架----->>对象关系映射
数据库中的一个个表:如:user表、book表,一条条记录
对应程序中的一个个类,一个个对象
'''此处程序指的是django模型层中的所建立的关系'''
以后数据库中一张表----》》》对应程序中的一个类
以后数据库中的一条记录---》》》对应程序中的一个对象
此处模型层知识只做补充知识,详细知识可以去我的这篇博客查看https://blog.csdn.net/achen_m/article/details/134428964?spm=1001.2014.3001.5501
补充表查询:
当查询是一对多或者多对多时,反向查询是按照表名小写并且因为反向查多的数据,则需要_set.all()
补充第三方日志模块loguru的使用
对于 logging 模块,即便是简单的使用,也需要自己定义格式,这里介绍一个更加优雅、高效、简洁的第三方模块:loguru,官方的介绍是:Loguru is a library which aims to bring enjoyable logging in Python. Loguru 旨在为 Python 带来愉快的日志记录。这里引用官方的一个 GIF 来快速演示其功能:

安装:
pip install loguru
Loguru 的主要概念是只有一个:logger
from loguru import logger # 导入模块
'添加配置日志输出到文件'
log_file = logger.add('test.log',rotation='500 MB',level='INFO') # 添加
'''添加到test.log文件中,第二个参数是设置每个文件最大存储500MB后就会新建文件继续存储,并且设置的记录级别为INFO级别'''
# 记录日志
logger.
logger.info('this is log info') # 信息
logger.debug('this is log debug') # 调试
logger.warning('this is log warning') # 警告
logger.error('this is log error') # 错误
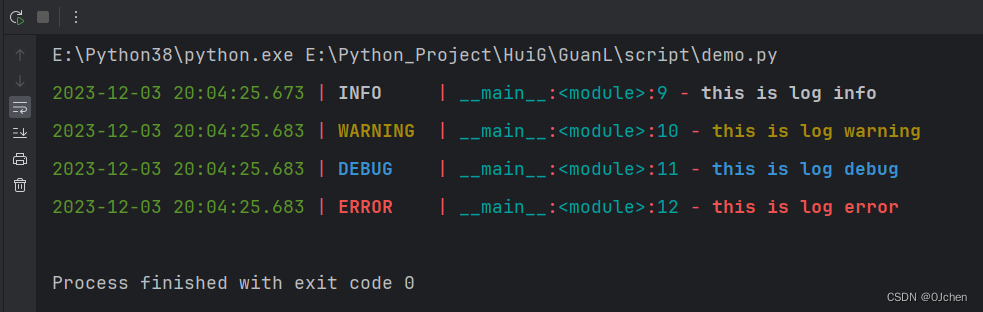
可以看到不需要手动设置,
Loguru 会提前配置一些基础信息,自动输出时间、日志级别、模块名、行号等信息,而且根据等级的不同,还自动设置了不同的颜色,方便观察,真正做到了开箱即用!
常用方法:
add()/remove()
如果想自定义日志级别,自定义日志格式,保存日志到文件该怎么办?与 logging 模块不同,不需要 Handler,
不需要 Formatter,只需要一个 add() 函数就可以了,例如我们想把日志储存到文件:
from loguru import logger
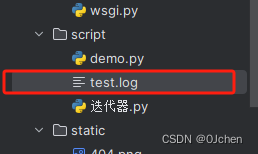
logger.add('test.log')
logger.debug('this is a debug')
我们不需要像 logging 模块一样再声明一个 FileHandler 了,就一行 add() 语句搞定,运行之后会发现目录下 test.log 里面同样出现了刚刚控制台输出的 debug 信息。
与 add() 语句相反,remove() 语句可以删除我们添加的配置:
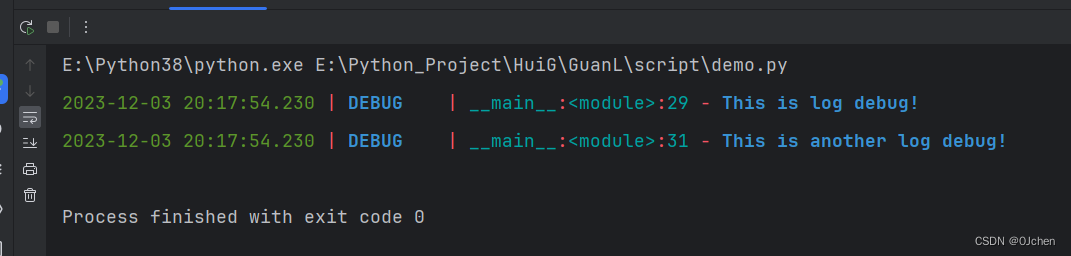
from loguru import logger
log_file = logger.add('test.log')
logger.debug('This is log debug!')
logger.remove(log_file)
logger.debug('This is another log debug!')
此时控制台会输出两条Debug信息,
并且在test.log日志文件里面只会有一条debug信息,原因就是在于我们在第二条debug语句之前使用了remove()语句

add语句的详细参数
Loguru 对输出到文件的配置有非常强大的支持,比如
支持输出到多个文件,分级别分别输出,过大创建新文件,过久自动删除等等。
'基本语法'
add(sink, *, level='DEBUG',
format='<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | <level>{level: <8}</level> | <cyan>{name}</cyan>:<cyan>{function}</cyan>:<cyan>{line}</cyan> - <level>{message}</level>',
filter=None, colorize=None, serialize=False, backtrace=True,
diagnose=True, enqueue=False, catch=True, **kwargs)
基本参数释义:
sink:可以是一个 file 对象,例如 sys.stderr 或 open('file.log', 'w'),也可以是 str 字符串或者 pathlib.Path 对象,即文件路径,也可以是一个方法,可以自行定义输出实现,也可以是一个 logging 模块的 Handler,比如 FileHandler、StreamHandler 等,还可以是 coroutine function,即一个返回协程对象的函数等。
level:日志输出和保存级别。
format:日志格式模板。
filter:一个可选的指令,用于决定每个记录的消息是否应该发送到 sink。
colorize:格式化消息中包含的颜色标记是否应转换为用于终端着色的 ansi 代码,或以其他方式剥离。 如果没有,则根据 sink 是否为 tty(电传打字机缩写) 自动做出选择。
serialize:在发送到 sink 之前,是否应首先将记录的消息转换为 JSON 字符串。
backtrace:格式化的异常跟踪是否应该向上扩展,超出捕获点,以显示生成错误的完整堆栈跟踪。
diagnose:异常跟踪是否应显示变量值以简化调试。建议在生产环境中设置 False,避免泄露敏感数据。
enqueue:要记录的消息是否应在到达 sink 之前首先通过多进程安全队列,这在通过多个进程记录到文件时很有用,这样做的好处还在于使日志记录调用是非阻塞的。
catch:是否应自动捕获 sink 处理日志消息时发生的错误,如果为 True,则会在 sys.stderr 上显示异常消息,但该异常不会传播到 sink,从而防止应用程序崩溃。
\kwargs:仅对配置协程或文件接收器有效的附加参数(见下文)。
当且仅当 sink 是协程函数时,以下参数适用:
loop:将在其中调度和执行异步日志记录任务的事件循环。如果为 None,将使用 asyncio.get_event_loop() 返回的循环。
当且仅当 sink 是文件路径时,以下参数适用:
rotation:一种条件,指示何时应关闭当前记录的文件并开始新的文件。
*retention *:过滤旧文件的指令,在循环或程序结束期间会删除旧文件。
compression:日志文件在关闭时应转换为的压缩或存档格式。
delay:是在配置 sink 后立即创建文件,还是延迟到第一条记录的消息时再创建。默认为 False。
mode:内置 open() 函数的打开模式,默认为 a(以追加模式打开文件)。
buffering:内置 open() 函数的缓冲策略,默认为1(行缓冲文件)。
encoding:内置 open() 函数的文件编码,如果 None,则默认为 locale.getpreferredencoding()。
\kwargs:其他传递给内置 open() 函数的参数。
这么多参数可以见识到 add() 函数的强大之处,仅仅一个函数就能实现 logging 模块的诸多功能,接下来介绍几个比较常用的方法。
常用参数
rotation 日志文件分隔
add()函数的 rotation 参数,可以实现按照固定时间创建新的日志文件,比如设置每天 0 点新创建一个 log 文件:
logger.add('runtime_{time}.log', rotation='00:00')
设置超过 500 MB 新创建一个 log 文件:
logger.add('runtime_{time}.log', rotation='00:00')
设置每隔一个周新创建一个 log 文件:
logger.add('runtime_{time}.log', rotation='1 week')
retention 日志保留时间
add()函数的 retention 参数,可以设置日志的最长保留时间,比如设置日志文件最长保留 15 天:
logger.add('runtime_{time}.log', retention='15 days')
设置日志文件最多保留 10 个:
logger.add('runtime_{time}.log', retention=10)
也可以是一个
datetime.timedelta 对象,比如设置日志文件最多保留 5 个小时:
import datetime
from loguru import logger
logger.add('runtime_{time}.log', retention=datetime.timedelta(hours=5))
compression 日志压缩格式
add()函数的 compression 参数,可以配置日志文件的压缩格式,这样可以更加节省存储空间,比如设置使用 zip 文件格式保存:
logger.add('runtime_{time}.log', compression='zip')
'其支持的格式:gz、bz2、xz、lzma、tar、tar.gz、tar.bz2、tar.xz'
字符串格式化
Loguru 在输出 log 的时候还提供了非常友好的字符串格式化功能,相当于
str.format():
logger.info('If you are using Python {}, prefer {feature} of course!', 3.6, feature='f-strings')
输出为》》》》》:
2023-12-03 20:33:33.305 | INFO | __main__:<module>:35 - If you are using Python 3.6, prefer f-strings of course!
异常追溯
在 Loguru 里可以直接使用它提供的装饰器就可以直接进行异常捕获,而且得到的日志是无比详细的:
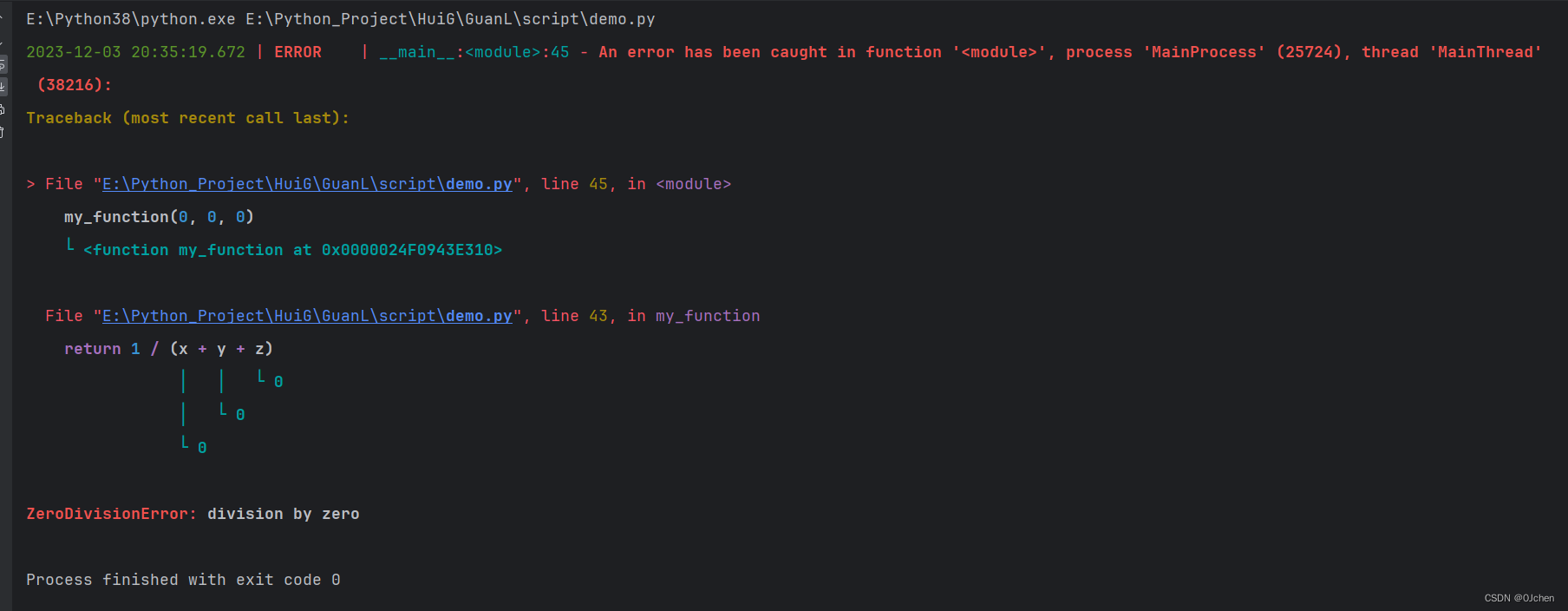
from loguru import logger
@logger.catch
def my_function(x, y, z):
# An error? It's caught anyway!
return 1 / (x + y + z)
my_function(0, 0, 0)
日志输出
相比 Logging,Loguru 无论是在配置方面、日志输出样式还是异常追踪,都远优于 Logging,使用 Loguru 无疑能提升开发人员效率。本文仅介绍了一些常用的方法,想要详细了解可参考 Loguru 官方文档https://loguru.readthedocs.io/en/stable/
补充聚合查询
聚合查询是指对一个数据表中的一个字段的数据进行部分或者全部进行统计查询,例如计算平均值、总和、最大值、最小值、个数等。
聚合查询又分为整表聚合和分组聚合
整表聚合查询(aggregate)
整表聚合就是不带分组的聚合查询,即将全部数据进行集中统计查询
五种聚合函数
- Avg(Average):平均值
- Max(Maximum):最大值
- Min(Minimum):最小值
- Sum(Summary):求和
- Count:个数
当然还有更多的聚合函数可去查看官方文档查看https://docs.djangoproject.com/en/3.2/topics/db/aggregation/
聚合查询需要先导入聚合函数
from django.db.models.import *
'常见的聚合函数有Sum、Avg、Count、Max、Min'
语法:
res = models.Book.objects.all().aggregate(结果变量名=聚合函数(‘列’))
返回结果:结果变量名和值组成的字典,即('结果变量名':值)
示例
from django.db.models import Avg,Max,Min,Sum,Count # 导入聚合函数
# 计算所有图书的平均值
res = models.Book.objects.all().aggregate(Avg('price'))
print(res)
结果为》》》:{
'price__avg': 777.0}
aggregate(*args,**kwargs)
aggregate()是QuerySet对象的一个终止子句,意思是说,它返回一个包含一些键值对的字典- 键的名称是聚合值的标识符,值是计算出来的聚合值
- 键的名称是按照字段和聚合函数的名称自动生成出来的
- 如果你想要为聚合值指定一个名称,可以向聚合子句提供它
res = models.Book.objects.all().aggregate(Avg_price=Avg('price')) # 指定名称
print(res)
结果为》》》:{
'Avg_price': 777.0}
如果你希望生成的不止一个聚合,你可与向aggregate()子句中添加别的参数。
# 计算所有图书的总和、最大值、最小值、个数
res = models.Book.objects.all().aggregate(Min('price'),Count('price'),Sum_price=Sum('price'),Max_price=Max('price'))
print(res)
'''
和正常传参一样,有位置参数和关键字参数,要使用位置参数(不指定名称)必须放在关键字参数(指定名称)前面,
'''
结果为》》》:{
'Sum_price': 3885, 'Max_price': 999, 'price__min': 555, 'price__count': 5}
分组聚合查询(annotate)
分组聚合就是指通过计算查询结果中的每一个对象所关联的对象集合,从而得出总计值(也可以平均值、总和等),即为查询集的每一项生成聚合
annotate()为调用的QuerySet每一个对象都生成一个独立的统计值(统计方法用聚合函数)
以字段为依据将相同的分为一类,annotate()分组关键字内写聚合函数
语法:
QuerySet.annotate(结果变量名=聚合函数('列'))
返回值为QuerySet
分组依据
- values() 在 annotate() 之前则表示group by字段(分组),如果不写表示按整个表分组
'默认分组依据'
如果 annotate()直接跟在object后面,则表示直接以当前的基表为分组依据
例如:按书来分组 models.Book.objects.all().annotate()
'指定分组依据'
如果 annotate()跟在values()后面,则表示按照values中指定的字段来进行分组
例如:按照书的价格进行分组 models.Book.objects.values('price').annotate()
- values() 在 annotate() 之后则表示取字段(只能取分组字段和聚合函数字段)
- filter() 在 annotate() 之前则表示where条件 (过滤)
- filter() 在 annotate() 之后则表示having条件
分组的目的:把有相同特征的分成一组,分成一组后一般用来,统计总条数、统计平均值、求最大值等。
示例
# 按书的价格进行分组
res = models.Book.objects.values('price').annotate()
# print(res)
# 查询出版社id大于1的出版社的id,以及书的平均价格
res = models.Publish.objects.values('id').filter(pk__gt=1).annotate(avg_price=Avg('book__price')).values('pk','avg_price')
# print(res)
# 查询出版社id大于1的出版社id,已经出书的平均价格大于666
res = models.Publish.objects.values('id').filter(pk__gt=1).annotate(avg_price=Avg('book__price')).filter(avg_price__gt=666).values('pk','avg_price')
print(res)
# 统计每一本书作者个数
res = models.Book.objects.all().annotate(count_authors=Count('authors__pk')).values('title','count_authors')
# print(res)
# 统计每一个出版社的最便宜的书
res = models.Publish.objects.all().annotate(min_book=Min('book__price')).values('name','min_book')
# # print(res)
# 统计不止一个作者的图书 (作者数量大于一)
res = models.Book.objects.annotate(count_authors=Count('authors')).filter(count_authors__gt=0).values('title','count_authors')
# print(res)
# 查询各个作者出的书的总价格
res = models.Author.objects.all().annotate(sum_price=Sum('book__price')).values('name','sum_price')
# print(res)
# 查询每个出版社的名称和书籍个数
res = models.Publish.objects.annotate(count_book=Count('book__id')).values('name','count_book')
# print(res)
# 查询每一个书籍的名称,以及对应的作者个数-->按书分
res = models.Book.objects.all().annotate(count_authors=Count('authors__pk')).values('title','count_authors')
# print(res)
# 查询每一个以 Python开头 书籍的名称,以及对应的作者个数-->按书分
res = models.Book.objects.all().filter(title__startswith='Python').annotate(count_authors=Count('authors__pk')).values('title','count_authors')
print(res)
补充F查询和Q查询
F查询
F查询:拿到某个字段在表中具体的值
从上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量作比较,如果我们要对两个字段的值作比较,那该如何做呢?
Django提供了F()来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个model实例中两个不同字段的值。
# 查询评论数大于收藏数的书籍
from django.db.models import F
Book.objects.filter(评论数__gt=F('收藏数'))
# 让所有图书价格+1
Book.objects.update(price=F("price")+1)
Q查询
Q查询:为了组装成 与 或 非 条件
与条件:and条件,在filter中直接写就是暗调条件
res = models.Book.objects.filter(title='MySQL从入门到删库跑路',price__gt=666)
print(res)
结果为》》》》:<QuerySet [<Book: MySQL从入门到删库跑路>]>
或条件:or条件
res = models.Book.objects.filter(Q(title='Python从入门到放弃')|Q(title='MySQL从入门到删库跑路'))
print(res)
结果为》》》》:<QuerySet [<Book: Python从入门到放弃>, <Book: MySQL从入门到删库跑路>]>
非条件:not条件
res = models.Book.objects.filter(~Q(title='论重启人生'))
print(res)
复杂逻辑:
res = models.Book.objects.filter((Q(title="论重启人生")& Q(price__gt=666))| Q (id__gt=2))
补充字段参数
ForeignKey属性
- related_name 反向操作时,使用的字段名,用于代替原反向查询时的’表名小写_set’
- related_query_name 反向查询操作时,使用的连接前缀,用于替代表名
ManyToManyField 用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系
to 设置要关联的表,中间是有个中间表的,区别于一对多
related_name 同ForeignKey字段。
related_query_name 同ForeignKey字段。
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。through_fields设置关联的字段。
db_table 默认创建第三张表时,数据库中表的名称。
补充SQL连表有哪几种链接方式
数据通常不在同一张表中,这就涉及到连表操作,而表之间连接方式有很多,
能够联表的大前提就是多表之间有关联关系[外键关系],呈现出三种关系:一对一,一对多,多对多
前置工作
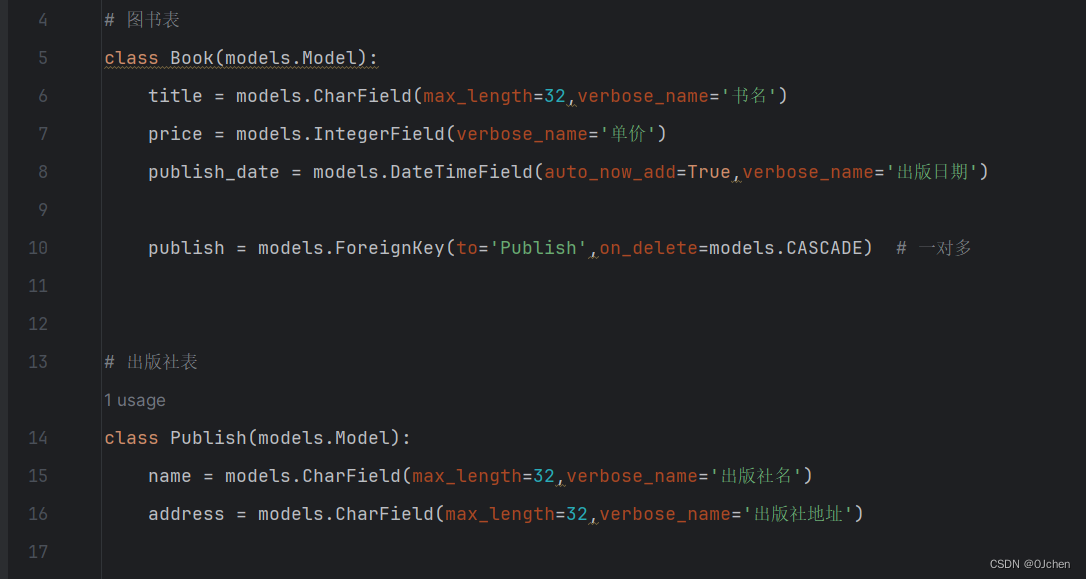
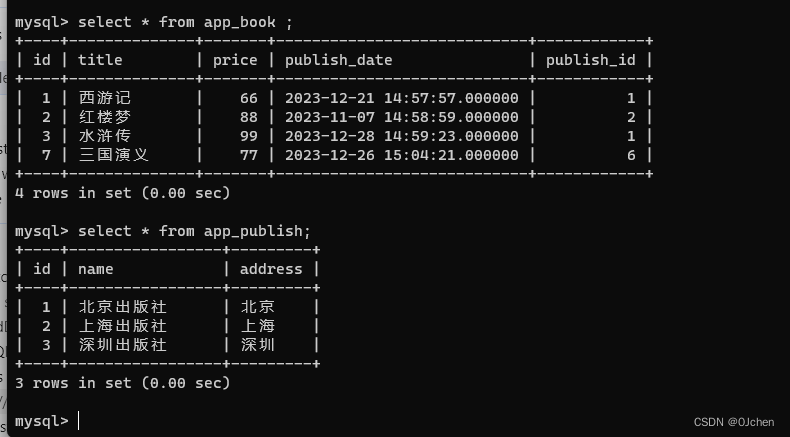
这里我就直接使用图书表以及出版社表来进行讲解了
然后插入一些数据,这里我会做一条脏数据来实验(创建了外键关系才可用使用这些连接方式,脏数据就是没有外键关系才能插入),所以我这里会先断开一下外键关系。
然后在恢复回来,这样准备工作就好了
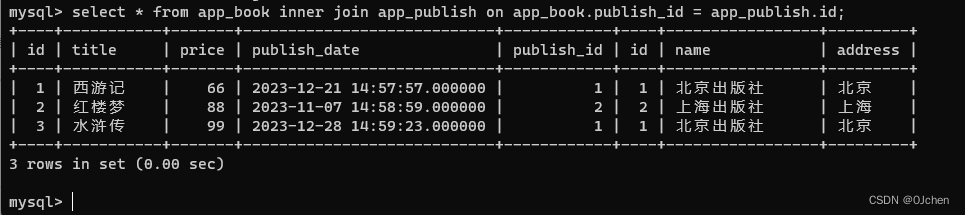
内连接(inner join)
把两张表中共有的数据,连接到一起
SQL语句:
select * from app_book inner join app_publish on app_book.publish_id = app_publish.id;
左连接(left join)
以左表为基准,把左表所有数据都展示出来,如右表没有对应的数据则使用null补齐

SQL语句:
select * from app_book left join app_publish on app_book.publish_id = app_publish.id;

右连接(right join)
以右表为基准,把右表所有数据都展示出来,如左表没有对应的数据则使用null补齐
SQL语句:
select * from app_book right join app_publish on app_book.publish_id = app_publish.id;
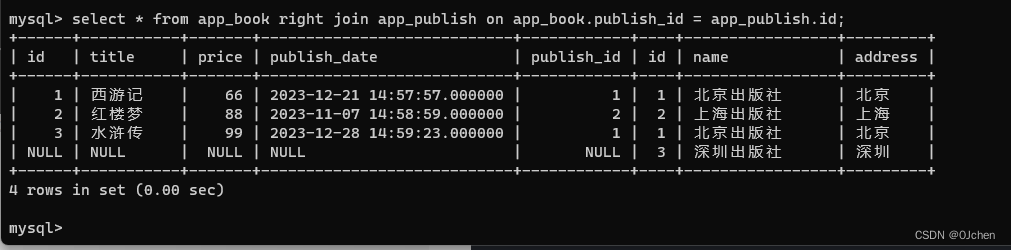
全连接(union)
全连接以左右两张表数据作为基准,左右两张表数据都展示,如左右表都有没有对应的数据则使用null补齐
mysql并不支持全连接,所谓的全连接其实本质是左连接的结果 union 右连接的结果

SQL语句:
select * from app_book left join app_publish on app_book.publish_id = app_publish.id
union
select * from app_book right join app_publish on app_book.publish_id = app_publish.id;
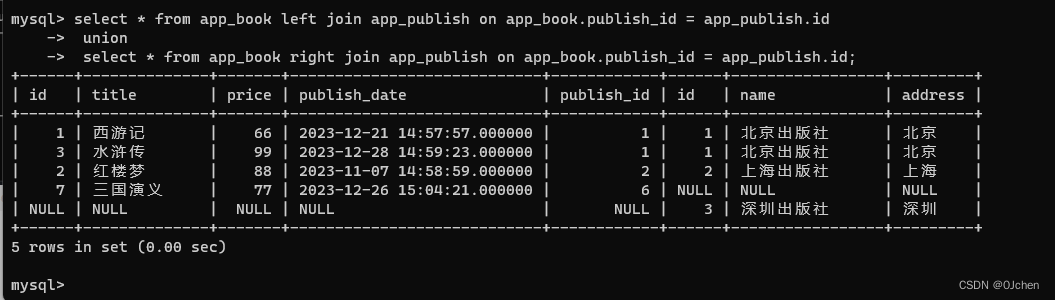
笛卡尔积(cross join)
还需要注册的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个N*M的组合,即笛卡尔积。表达式如下:
SELECT * FROM TableA CROSS JOIN TableB
这个笛卡尔乘积会产生 4 x 4 = 16 条记录,一般来说,我们很少用到这个语法。但是我们得小心,如果不是使用嵌套的select语句,一般系统都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。
SQL语句:
select * from app_book cross join app_publish;
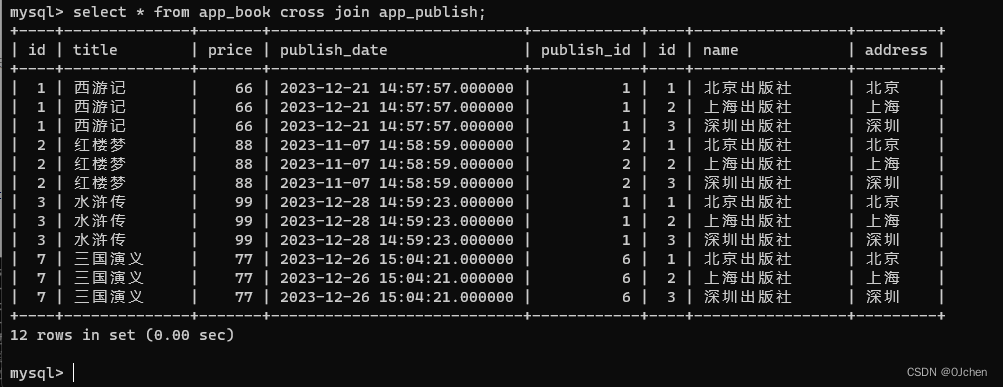
使用笛卡尔积这种方法会是左右两表,每个都与其中一张表循环匹配一遍,这样就太多余了,所以我们可以使用笛卡尔积后来使用过滤一下
SQL语句:
select * from app_book,app_publish where app_book.publish.id = app_publish.id;
SQL查询的基本原理
单表查询:根据WHERE条件过滤表中的记录,形成中间表(这个中间表对用户是不可见的);然后根据SELECT的选择列选择相应的列进行返回最终结果。
两表连接查询:对两表求积(笛卡尔积)并用ON条件和连接连接类型进行过滤形成中间表;然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。
多表连接查询:先对第一个和第二个表按照两表连接做查询,然后用查询结果和第三个表做连接查询,以此类推,直到所有的表都连接上为止,最终形成一个中间的结果表,然后根据WHERE条件过滤中间表的记录,并根据SELECT指定的列返回查询结果。
理解SQL查询的过程是进行SQL优化的理论依据。
cookie与session(补充)
大体的内容可以去查看我这篇博客进行了解Cookie与Sessioin
Cookie(是在客户端上的键值对)------主要为了做会话保持的
怎么来的?
首先从服务端写入到一个
HttpResponse对象.set_cookie(key,value),然后服务端再返回到响应头中写入,这样客户端访问后就会自动取出来放到cookie中进行保存
set_cookie中可以操作的参数具体看上面我说的那篇博客

只要浏览器中有cookie,再次朝着当前域发送请求,都会自动把cookie携带着。
- 携带在请求头中得cookie字段中。如
(name=jack;age=18)这种格式
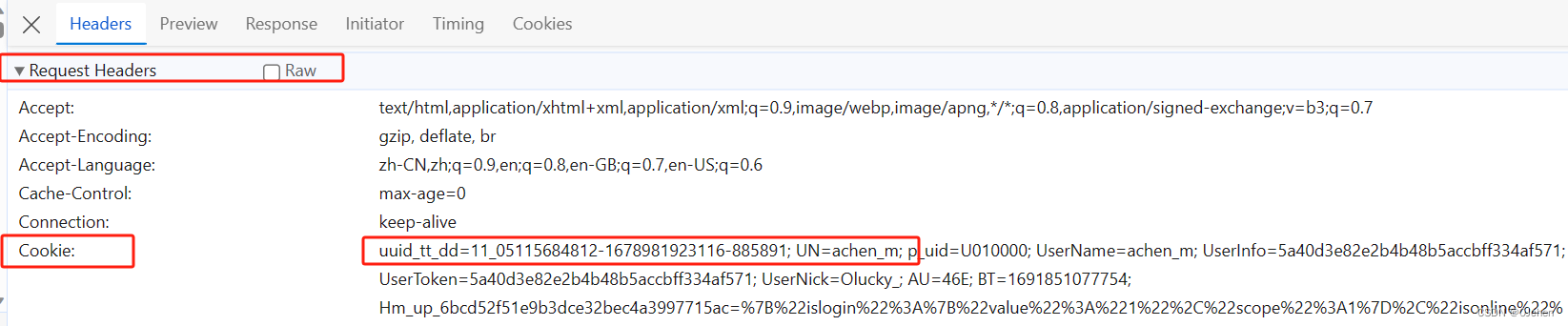
服务端进行cookie的操作
'设置cookie首先需要生成一个HttpResponse对象'
obj = HttpResponse('xxx')
设置cookie:obj.set_cookie('name','jack')
取值cookie:request.COOKIES.get('name')
清空cookie:reqeust.COOKIES.clear()
但是使用cookie有个很不安全的问题,
就是如果在cookie中发了像用户和密码等敏感数据,它只会用明文展示,并且客户就能看到。所以我们需要让cookie变的安全,那么我们就可以把敏感数据放在session中。
Session(是在服务端上的键值对)
Session与cookie有什么关系呢?
Session就是为了解决cookie上面一系列不安全问题,可以把敏感数据使用密文保存在服务端指定的文件、数据库、缓存等当中。而只会把key存放到浏览器cookie中,这样以后浏览器发送请求过来就会携带这个session的key,然后服务端在根据这个可以去指定存放的文件或者数据库等中进行匹对,当匹对成功后则放到reqeust.session当中,当我们需要取的时候就可以从session当中取出数据。
session的存放配置
在django中默认是配置了session是在django_session表中存放的的,当然自己也可以去设置存放在哪里。更多的设置都可以去追源码查看,当然更改默认配置都需要放在settings配置文件中。
因为默认是存放在django_session表中的,所以我们需要第一次的时候就得执行数据库迁移,否则无法使用
django_session字段

- session_key:存放在浏览器cookie中的sessioinid(这个sessionid也是可以修改默认命名的,但是没必要),随机字符串
- session_data:真正存放的数据,并且加密了
- expire_date:过期时间(默认设置为两周,也是可以自行修改的)
session的使用
取值:request.session.get()
赋值:request.session['xxx'] = 'xxx'
session的本质执行原理
如我们在视图函数中设置了session:
request.session['xxx'] = 'xxx'
本质上就是向session对象中放入了xxx=xxx
2.当视图函数执行结束后,会经过中间件,然后在返回给前端
- 而django中内置了一个session中间件
其主要用途就是判断request.session是否有没有变化,如果有变化
'情况一:django_session表中没有数据时'
会在django_session表中创建出一条数据,并且随机生成一个字符串[session_key],
然后把数据存入到django_session表中的[session_data]字段当中,并且以加密的形式存放。
然后会把随机生成的字符串在写入到浏览器的cookie中
'情况二:django_session表中有数据时'
会把session中的写入的值,进行加密处理后更新到原来的django_session表的session_data字段当中,其他字段值不变
3.当下次再发送请求进入任意视图函数之前,又会经过中间件中匹对完毕后,在进入到视图函数
-然后就可以在视图函数中取出session:reqeust.session.get('xxx')
-而浏览器发送请求后,会携带cookie过来,然后会进入到中间件中,进入到中间件中的sessionMiddleWare中间件会根据携带过来的sessionid取出随机字符串
-然后会拿着随机字符串进入到django_session表去查是否有相对应的[session_key],如果能查到就会把session_data里面的数据解密后,放到request.session中
-后续再视图函数中,才能通过request.session取出值。
中间件补充
大致完整的知识内容可以查看我的这篇博客进行学习中间件与CSRF_TOKEN。此处我仅仅做补充