文章目录
使后感
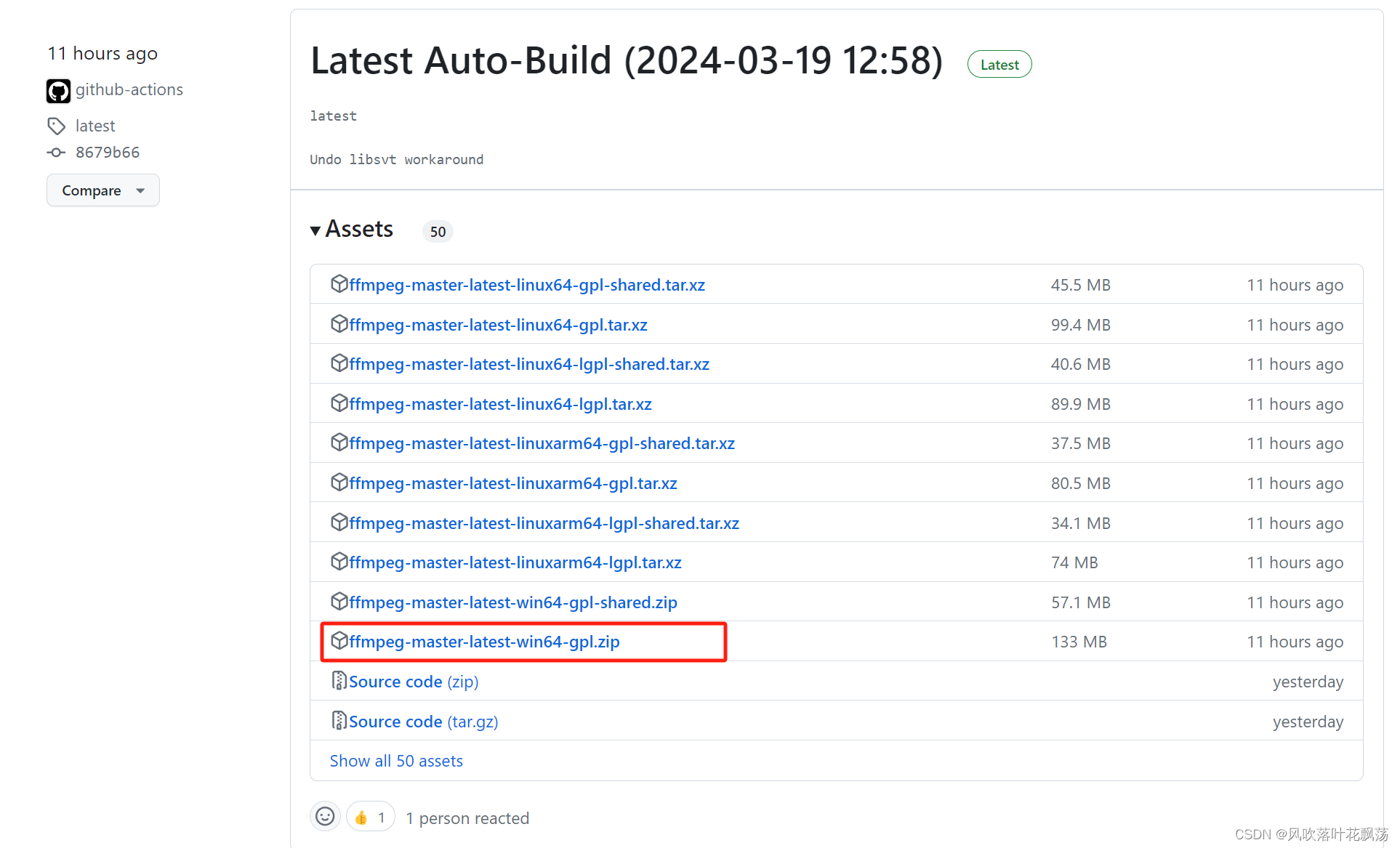
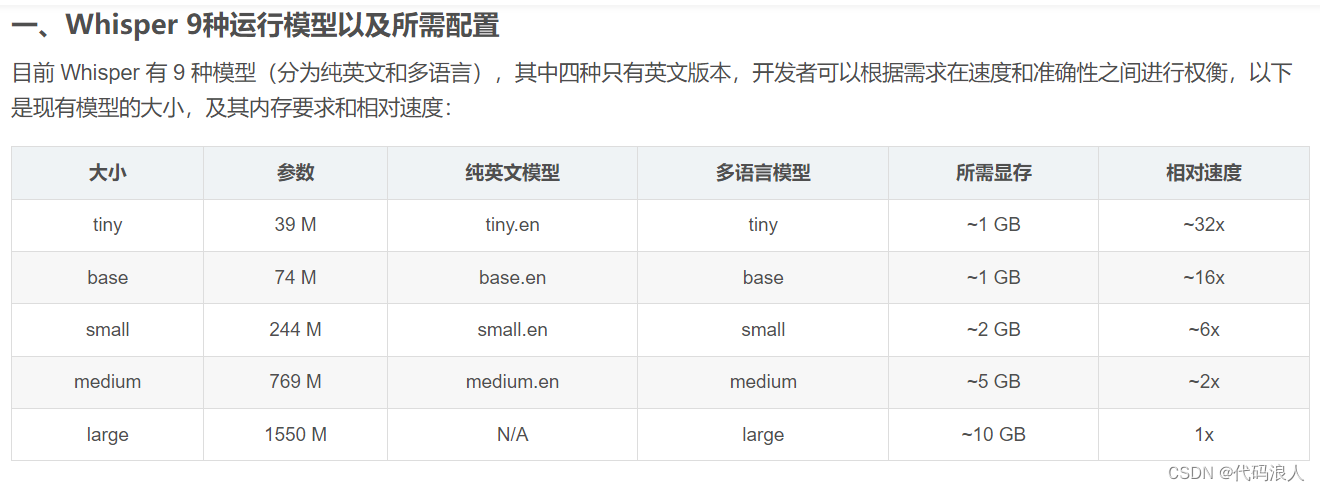
因为运用里需要考虑到时效和准确性,类似于YOLO,只考虑 tiny, base,和small 的模型。准确率基本反应了模型的大小,即越大的模型有越高的准确率
Paper Review
个人觉得有趣的
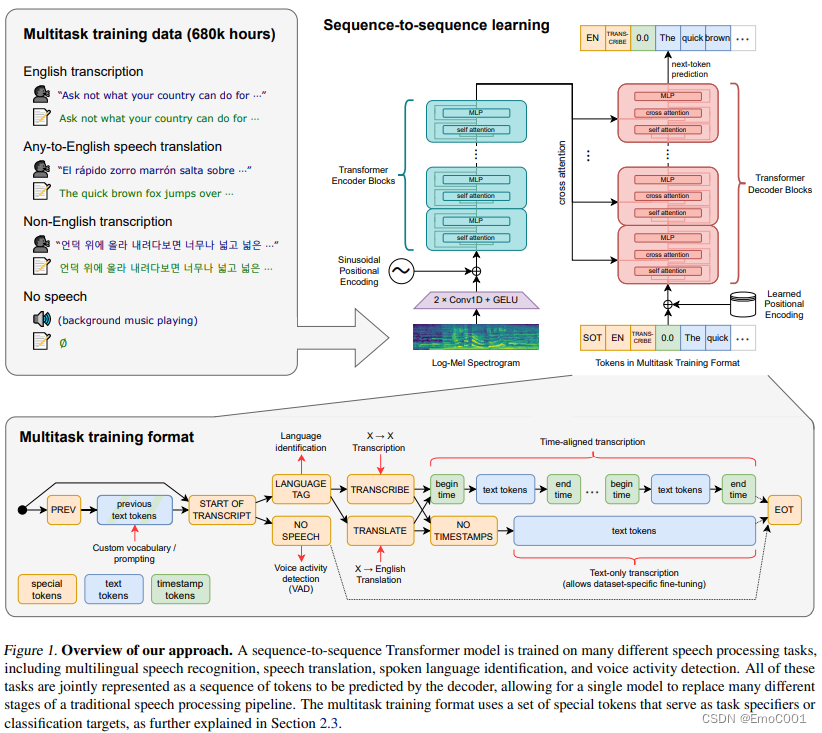
这里的feature不是直接的声音array,但log-mel spectrogram 也不是陌生的。mel 比 STFT更少的特征数量,也更接近人类感知,Mel 频谱通过在较低频率提供更多的分辨率,有助于减少背景噪音的影响。
整个结构也是很一目了然,喜闻乐见的transformer。 但是有限制: 16,000Hz的audio sample, 80 channels,25 millisseconds的窗口,移动距离为 10 milliseconds
为啥可以得到 时间轴对应的Txt, 这个得感谢decoding.py 里 “begin time” 和 “end time”
Log Mel spectrogram & STFT
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
# 加载音频文件
audio_path = 'your_audio_file.wav'
y, sr = librosa.load(audio_path)
# 计算 STFT
D = librosa.stft(y)
# 将功率谱转换为dB
D_dB = librosa.amplitude_to_db(np.abs(D), ref=np.max)
# 创建 Mel 滤波器组
n_mels = 128
mel_filter = librosa.filters.mel(sr, n_fft=D.shape[0], n_mels=n_mels)
# 应用 Mel 滤波器组
mel_S = np.dot(mel_filter, np.abs(D))
# 对 Mel 频谱取对数
log_mel_S = librosa.power_to_db(mel_S, ref=np.max)
# 绘图
plt.figure(figsize=(12, 8))
plt.subplot(2, 1, 1)
librosa.display.specshow(D_dB, sr=sr, x_axis='time', y_axis='log')
plt.title('STFT Power Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.subplot(2, 1, 2)
librosa.display.specshow(log_mel_S, sr=sr, x_axis='time', y_axis='mel')
plt.title('Log-Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.tight_layout()
plt.show()
Training
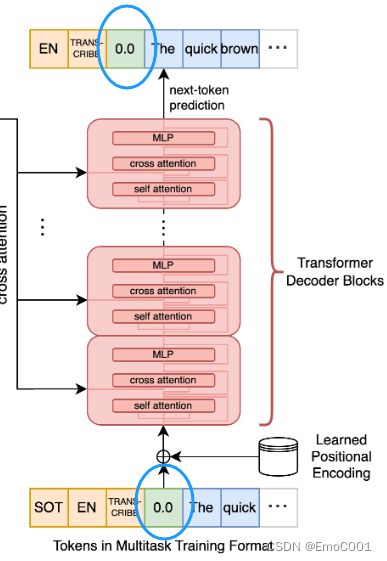
cross-attention输入
SOT: start of trascription token
EN: English token
TRANS-CRIBE: token
timestamp
balabalabala(真的语音转成的文字)
cross-attention输出
EN: English token
TRANS-CRIBE: token
timestamp
balabalabala(真的语音转成的文字)
positional encoding
在这里面用到了不同的positional encoding,只是不确定如果不一样会不会有什么影响。挖个坑先(后面把这里填了)
输入用的是Sinusoidal Positional Encoding
输出用的是 Learned Positional Encoding
数据
- 基本是需要人工参与去检查大数据里的数据质量的(后期有通过使用初训的Whisper过筛数据后加人工检查的操作)
- Whisper还有减翅膀的悲剧(哭哭),本来有显示出可以“猜”说话的人,但是这个应该和NLP大模型里面的“想象力”一样,都是瞎猜,为了减少其影响,后来在fine-tune 时把这个信息从训练里删除了
- 也有比较有趣的是,Speech reg 是依靠WER(word error rate)来的,也就是非常粗暴的word edit distance. 那每个人讲话啊风格不一样,就算是同一个意思的数据也会因为WER过高,导致训练了个寂寞。
- hmmmmm…这个数据处理相当heavily depends on manually inspection. 如果资金不够。。。真的很尴尬
- 在normalise.py 和 paper最后,给了一堆normalization的tricks
Decoding
和NLP的东西环环相扣,基本greedy search都会有那种说车轱辘话的bug, 作者的解决方法是将beam-search size = 5
看完论文后,个人推荐使用 temperature <0.5 (中庸设置)
相比于上个世纪的依靠频谱判断有没有人讲话,Whisper是模型控制和判断。比如作者会将不说话<|nospeech|>的机率调到0.6。
这个训练模式是causal 来的,也就是通过一个upper 三角设置为 -inf 未来的说话是会被忽视的,用前面的内容往后推理
为什么可以有时间戳的信息
它在decoding(decoding.py)阶段,只需要依靠 self.tokenizer.timestamp 里的数据来,只要知道一段语音的开始,就能反推结束,因为一段语音的分割结尾即是另一个语音的开始
# if sum of probability over timestamps is above any other token, sample timestamp
logprobs = F.log_softmax(logits.float(), dim=-1)
for k in range(tokens.shape[0]):
timestamp_logprob = logprobs[k, self.tokenizer.timestamp_begin :].logsumexp(
dim=-1
)
max_text_token_logprob = logprobs[k, : self.tokenizer.timestamp_begin].max()
if timestamp_logprob > max_text_token_logprob:
logits[k, : self.tokenizer.timestamp_begin] = -np.inf
Test code
import whisper
import speech_recognition as sr
recognizer = sr.Recognizer()
import os
from moviepy.editor import *
import time
start_time = time.time()
modeltype = "small"
model = whisper.load_model(modeltype)
input_folder = r"D:\xxxxxxx"
output_folder = r"out_"+modeltype+"model_whisper"
format = 'mp4'
without_timestamps = False
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for root, dirs, files in os.walk(input_folder):
for file in files:
if file.endswith(("."+format,)):
video_path = os.path.join(root, file)
basename = os.path.splitext(file)[0]
audio_path = os.path.join(input_folder, f"{basename}.{format}")
start_time = time.time()
result = model.transcribe(audio_path, language="zh",without_timestamps=without_timestamps)
print(basename,time.time()-start_time)
with open(output_folder+'/'+basename+'_all.txt', 'w') as res_file:
res_file.write(str(time.time()-start_time)+'\n')
for seg in result["segments"]:
if without_timestamps:
line = f"{seg['text']}'\n'"
else:
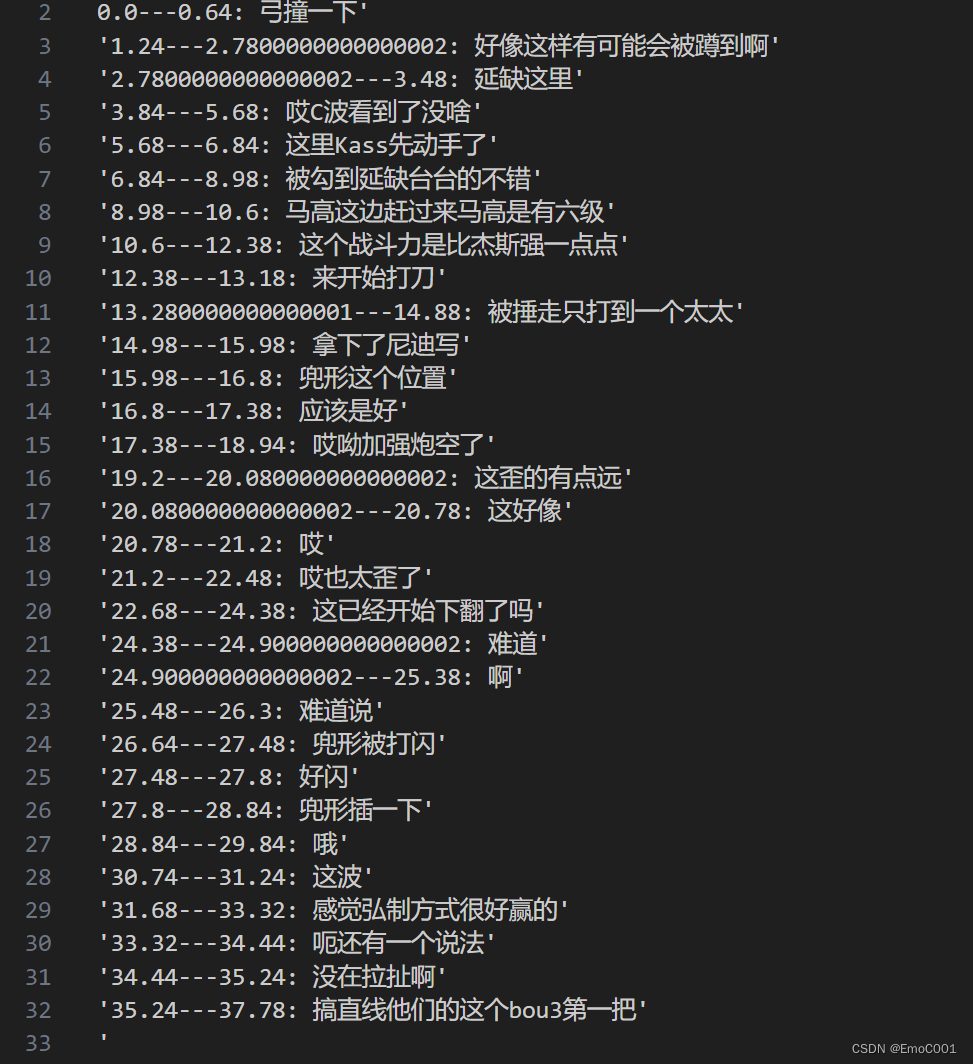
line = f"{seg['start']}---{seg['end']}: {seg['text']}'\n'"
res_file.write(line)
print("Done")