1. 请简要介绍一下Hadoop的基本架构和组件。
Hadoop是一个由Apache基金会开发的分布式系统基础架构,它可以充分利用集群的威力进行高速运算和存储。用户无需了解分布式底层细节,就可以开发分布式程序。
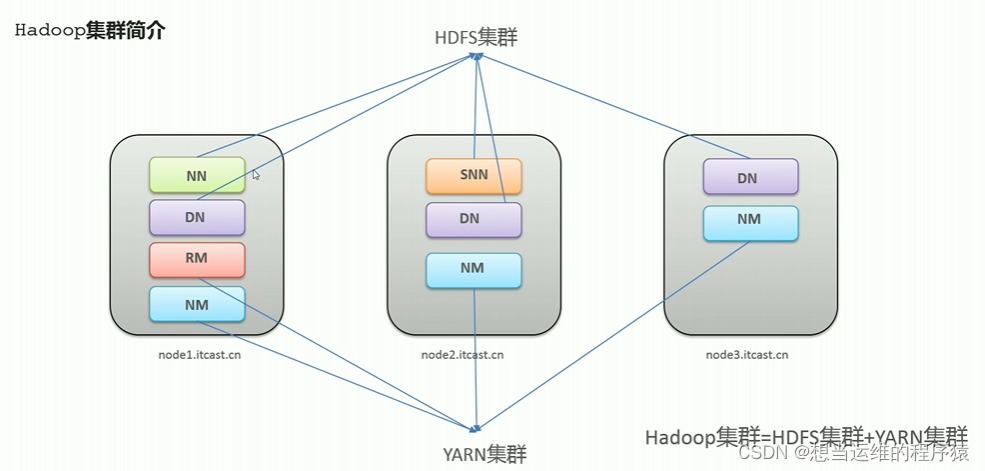
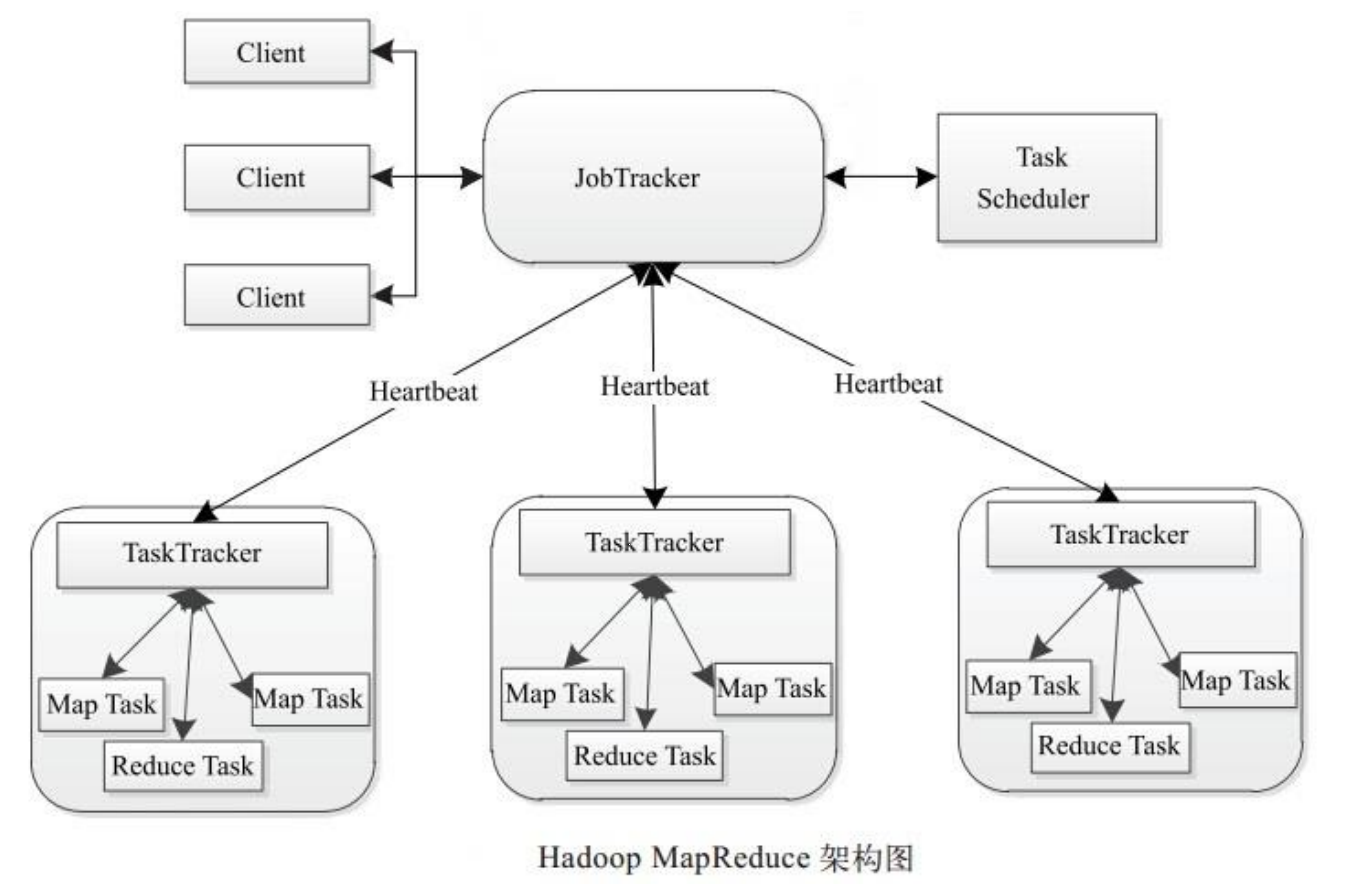
Hadoop的基本架构包括以下几个核心组件:
- HDFS(Hadoop Distributed File System):它是一个高度容错性的分布式文件系统,能提供高吞吐量的数据访问,非常适合大规模数据集的应用。
- MapReduce:这是一种编程模型和处理引擎,用于大规模数据集的并行运算和处理。
- HBase:这是一个分布式列存数据库,支持大型表格的随机读/写操作。
- ZooKeeper:它是一个为分布式应用提供一致性服务的开源框架。
- Hive:这是一个基于Hadoop的数据仓库工具,可以通过类似SQL的查询语言HiveQL来查询和分析存储在Hadoop中的数据。
2. Hadoop中的HDFS是什么?它的主要特点和优势是什么?
HDFS(Hadoop Distributed File System)是Hadoop的核心组件之一,它是一个HDFS(Hadoop Distributed File System)是Hadoop的核心组件之一,它是一个分布式文件系统,用于存储和管理大数据。HDFS的主要特点包括:
- 适用于在分布式存储和处理。
- Hadoop提供了一个与HDFS交互的命令接口。
- NameNode和DataNode的内置服务器帮助用户轻松检查集群的状态。
- 流式访问文件系统数据。
- HDFS提供文件权限和身份验证。
同时,HDFS也有许多显著的优点:
- 高容错性:HDFS通过保存数据的多个副本来提高容错性,某个副本丢失以后,它可以自动恢复。
- 适合批处理:HDFS是通过移动计算而不是移动数据来进行处理,这大大减少了数据传输的时间。
- 扩展性强:HDFS支持线性扩展,可以轻松地向集群中添加更多的节点,以适应不断增长的数据需求。
- 数据量大:HDFS可以存储非常大的数据量,适合处理大规模的数据集。
然而,HDFS也有一些缺点,如不适合低延时的IO操作频繁的场景,不可以并发没有事务,没有锁机制,以及不实用数据量小的文件等。
3. Hadoop中的MapReduce是什么?请简要描述其工作原理。
MapReduce是Hadoop的一个核心组件,它是一个开源的计算框架,通过分布式计算处理海量数据,具有高可靠性、高扩展性和高效性等特点。MapReduce的工作流程主要包括Map阶段和Reduce阶段。
在Map阶段,输入的数据会被切分为多个小块,然后在集群中的多个计算节点上并行处理这些小块。每个计算节点都会执行Map函数,将输入数据转换成键值对。这个阶段的主要任务是对数据进行预处理,将数据分解成多个独立的部分,以便于后续的并行处理。
接下来是Reduce阶段,在此阶段中,Map阶段生成的键值对会被按照键进行分组,然后每个组内的所有键值对都会被传递给同一个Reducer进行处理。Reducer的主要任务是将每个组内的键值对按照某种规则进行整合,生成一组新的键值对。这个过程通常是对数据进行汇总或者统计,以得出最终的结果。
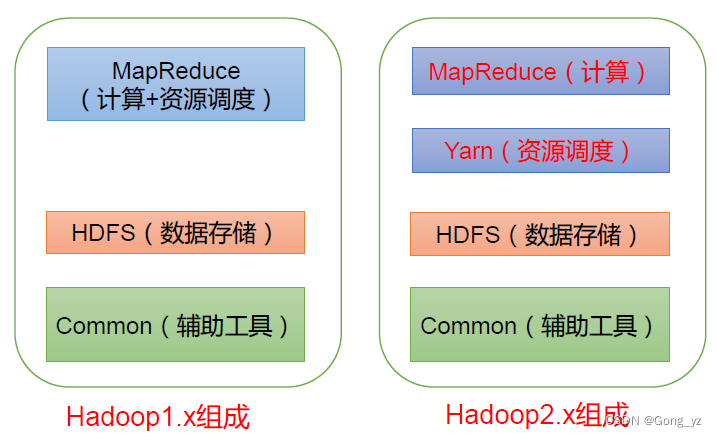
值得注意的是,从Hadoop 2.0开始,引入了资源管理框架YARN,使用ResourceManager来负责容器的调度以及作业的管理,使用NodeManager来向ResourceManager汇报节点资源以及容器运行状态。这种新的架构使得Hadoop MapReduce能够更好地适应复杂的数据处理需求。
4. 请解释一下Hadoop的YARN(Yet Another Resource Negotiator)框架,它的主要作用是什么?
YARN,全称Yet Another Resource Negotiator,是Hadoop的资源管理系统和任务调度平台。这个框架在Hadoop 2.0中引入,目的是改善MapReduce的实现并提升其扩展性。
YARN主要由ResourceManager、NodeManager和ApplicationMaster等组件构成。ResourceManager负责整个集群的资源管理和调度;而每个计算节点上的NodeManager则负责单个节点上的所有容器的生命周期管理;同时,每个应用程序都有一个ApplicationMaster,它负责协调应用程序内各个任务的执行。
其主要工作流程分为两个阶段:资源管理和任务调度。在资源管理阶段,ResourceManager负责整个集群的资源管理和调度,接收用户提交的任务请求,并为任务分配资源;而在任务调度阶段,ResourceManager将分配给任务的资源信息通知给ApplicationMaster,由ApplicationMaster根据这些资源信息启动并监控任务的运行。
值得注意的是,自Hadoop 2.0开始,YARN不仅仅支持MapReduce计算模型,还支持其他多种计算框架,如Tez、Spark等。只要这些计算框架实现了YARN所定义的接口,都可以运行在YARN上,这使得YARN具备了很好的通用性和扩展性。
5. Hadoop中的数据块大小是如何定义的?为什么选择这个数据块大小?
在Hadoop中,数据块的大小是通过设置dfs.blocksize参数来定义的。默认情况下,Hadoop 2.x及以后的版本,文件块的大小为128M,之前的版本默认为64M。当用户上传文件至HDFS时,如果文件的大小超过设定的块大小,该文件会被分割成多个块进行存储,这些块可以存放于不同的DataNode上。
这种设定的初衷主要是为了处理和管理大数据。通过将大文件切割成一个一个的数据块,再将这些数据块分发到集群上进行处理,可以极大地提高数据处理的效率。例如,如果集群的块大小设置为64MB,那么一个128MB的文件将会被切割成两个数据块。这样,即使某个数据块发生故障,也不会影响整个文件的读取和处理。同时,每个数据块都可以并行处理,进一步增加了处理速度。
需要注意的是,如果某文件大小没有到达64MB(或128MB),该文件并不会占据整个块空间。此外,HDFS中的NameNode会记录文件的各个块都存放在哪个dataNode上,这些信息一般被称为元信息(MetaInfo)。
6. 请简要介绍一下Hadoop的高可用性(HA)配置,如何实现NameNode和DataNode的故障切换?
Hadoop的高可用性(HA)是一种设计架构,旨在保证业务的连续性。在HA配置中,通常有两个或两个以上的节点,包括一个活动节点(Active)和若干备用节点(Standby)。活动节点是正在执行业务的节点,而备用节点则是活动节点的备份。
实现NameNode和DataNode的故障切换主要包括以下步骤:首先,配置Hadoop集群的基础环境,包括安装JDK、SSH、NTP等必要的软件和服务。然后,配置Hadoop集群的主节点和从节点,在主节点上配置ZooKeeper集群,从节点上安装HDFS和YARN组件。在这个过程中,通过编辑hdfs-site.xml文件来指定Hadoop的数据存储目录,例如<hdfs://mycluster/user/hadoop/data。
当NameNode出现故障时,可以通过ZooKeeper自动进行故障切换,新的NameNode将被选举出来以继续提供服务。同样,当DataNode出现故障时,也可以通过HDFS的自我修复机制进行故障切换,新的DataNode将被添加到HDFS中以保持数据的完整性和可用性。
7. Hadoop中的HBase是什么?它与HDFS有什么区别?
HBase,正式称为Hadoop Database,是Hadoop生态系统的一部分,本质上为Hadoop框架中的结构化数据提供存储服务。它是一个基于列的分布式数据库,同时也是一个NoSQL数据库。HBase的主要特点是适用于随机读写和实时查询的数据访问模式,常见的应用场景包括Web应用程序和实时分析等。
而HDFS(Hadoop Distributed File System),则是Hadoop的核心组件之一,它是一个分布式文件系统,用于存储大量的数据。HDFS提供了高吞吐量的数据访问,并且可以在通用硬件上运行。其典型的应用包括一次写入,多次读取的数据访问模式,例如批处理和数据挖掘等。
因此,HDFS和HBase的主要区别在于它们的数据存储和访问模式。HDFS更适用于大量数据的批处理和数据挖掘等访问模式,它通过将大数据切割成多个数据块进行存储,以实现对大规模数据的高效处理;而HBase则更侧重于随机读写和实时查询,它支持实时数据查询和高速读/写操作,适用于需要快速获取和修改数据的应用场景。
8. 请简要介绍一下Hadoop的数据压缩机制,它对性能有什么影响?
Hadoop使用了一种高效的数据压缩机制,旨在减小计算机文件大小,以提高存储和传输效率。这种压缩机制通过特定的算法进行,能够有效地减少底层存储系统(HDFS)读写字节数,进而提高网络带宽和磁盘空间的利用率。
在Hadoop环境中,尤其是在处理大数据规模的任务时,数据压缩显得尤为重要。因为在这种情况下,数据压缩可以有效地节省资源,并成为MapReduce程序的一种优化策略。具体来说,数据压缩可以帮助减少网络传输的数据量,使文件能够通过较慢的网络连接实现更快的传输速度;同时,它也可以减少文件在磁盘上的占用空间,从而提高存储效率。
然而,值得注意的是,虽然数据压缩具有许多优点,但它也可能对性能产生一定影响。因为压缩和解压缩数据需要消耗一定的CPU资源,如果CPU资源不足,可能会反而降低系统的性能。因此,在选择是否进行数据压缩时,需要综合考虑系统的实际需求和资源情况。
9. Hadoop中的Impala是什么?它与传统的MapReduce相比有哪些优势?
Impala是Apache开源的大规模并行处理(MPP)SQL查询引擎,专为查询存储在Hadoop集群中的数据而设计。它为用户提供了高性能、低延迟的大数据分析体验,且能与Hive使用相同的元数据、SQL定义、ODBC驱动和用户接口。
与传统的MapReduce相比,Impala有以下优势:
- 基于内存进行计算,能够对PB级数据进行交互式实时查询和分析。
- 直接读取HDFS数据,无需转换为MR。
- Impala由C++编写,使用LLVM统一编译运行,优化了运行效率。
- 兼容HiveSQL,可以使用Hive的元数据、SQL定义等。
- 省去了MapReduce作业启动的开销,避免了不必要的shuffle、sort等操作。
- 通过使用LLVM来统一编译运行时代码,提高了运行效率。
- 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
- 完全抛弃了不太适合做SQL查询的MapReduce范式,借鉴了MPP并行数据库的思想,可做更多的查询优化。
10. 请简要介绍一下Hadoop的安全机制,如何实现用户权限管理和数据加密?
Hadoop的安全机制主要包括用户权限管理和数据加密。用户权限管理主要通过Kerberos认证来实现,这是一种安全机制,用于确保Hadoop集群中的数据和应用程序不会被未经授权的访问。在Hadoop集群中启用Kerberos认证后,客户端需要使用Kerberos票证来验证其身份。此外,Hadoop还支持基于角色的访问控制(RBAC),可以为不同的用户或用户组分配不同的角色,从而实现对不同数据和资源的访问控制。
对于数据加密,Hadoop提供了两种加密机制:HDFS加密和RPC加密。HDFS加密可以通过配置来实现,从而保护存储在HDFS上的数据的安全性。而RPC加密则可以保护Hadoop内部通信过程中的数据安全。这些安全机制不仅遵循了不能损害集群功能、架构一致以及能够解决安全威胁的原则,而且能够有效地防止未经授权的访问和数据泄露,保障了Hadoop集群的数据安全。
11. Hadoop中的Oozie是什么?它的主要作用是什么?
Oozie是一个基于工作流引擎的开源框架,由Cloudera公司贡献给Apache,主要用于管理和协调Hadoop作业,特别是对Hadoop MapReduce和Pig Jobs的任务调度与协调。它的主要功能包括:
- 统一调度Hadoop系统中的各种任务,如常见的MR任务启动、HDFS操作、Shell调度、Hive操作等;
- 提供XML语言来表达复杂的依赖关系、时间触发和事件触发,从而提升开发效率;
- 通过图形方式表示工作流中的任务流程逻辑,使得流程更加直观;
- 支持按照执行的逻辑顺序进行定时调度任务。
Oozie需要部署到Java Servlet容器中运行,并且其工作流由HPDL(Honeybee Process Definition Language)描述。总的来说,Oozie作为一个工作流调度系统,极大地提高了Hadoop作业的灵活性和自动化程度。
12. 请简要介绍一下Hadoop的资源管理,如何为应用程序分配资源?
Hadoop的资源管理是由YARN(Yet Another Resource Negotiator)负责的,这是一个Hadoop的资源管理是由YARN(Yet Another Resource Negotiator)负责的,这是一个分布式资源管理系统,旨在解决Hadoop 1.x架构中集群资源管理和数据计算耦合在一起,导致维护成本越来越高的问题。YARN的出现使得各种服务框架可以部署在YARN上,由YARN进行统一地管理和资源分配。
具体来说,YARN主要负责管理集群中的CPU和内存资源。它采用的主要组件是ResourceManager和NodeManager。其中,ResourceManager负责整个集群的资源管理和调度;而NodeManager则在每台机器上运行,负责单个节点上的资源管理和任务监控。当MapReduce任务在运行时,会生成具体子任务,这些子任务将在NodeManager上产生的Container容器中运行。
总的来说,YARN为应用程序提供了高效、动态的集群资源管理和调度服务,使得多个应用程序能够同时在同一Hadoop集群上运行,有效地共享集群资源。
13. Hadoop中的Spark是什么?它与MapReduce相比有哪些优势?
Spark是一个开源的大数据处理框架,它在Hadoop生态系统中以其优越的性能和易用性脱颖而出。与MapReduce相比,Spark有以下主要优势:
- 速度快:Spark使用内存计算技术,能够将数据存储在内存中进行处理,从而实现更快的数据处理速度。同时,Spark还支持并行计算,可以在多台机器上同时执行任务,进一步提高了处理速度。
- 易用性:Spark提供了丰富的API和库,支持多种编程语言(如Java、Scala、Python等),使得开发人员可以更方便地使用Spark进行数据处理和分析。此外,Spark还提供了交互式Shell、Web UI等多种工具,方便用户进行程序开发和调试。
- 灵活性:Spark不仅支持批处理模式,还支持流处理模式(即Spark Streaming),可以实现实时数据的处理和分析。此外,Spark还支持机器学习、图计算等多种应用场景,具有很高的灵活性。
- 高容错性:Spark采用弹性分布式数据集(RDD)作为基本数据结构,每个RDD都可以被切分为多个分区进行处理。当某个分区出现故障时,Spark可以自动重新计算该分区的数据,从而提高了系统的容错性。
14. 请简要介绍一下Hadoop的数据迁移工具,如Ambari、Cloudera Manager等。
Ambari和Cloudera Manager都是用于管理Hadoop集群的工具。其中,Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控,它已经支持了大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、Hbase、Zookeper、Sqoop和Hcatalog等。而Cloudera Manager则主要用于管理Cloudera发行版(Cloudera Distribution including Apache Hadoop,CDH)。
在实际应用中,两者也常常用于Hadoop集群的数据迁移任务。例如,可以先采用Ansible进行过渡,然后采用Cloudera Manager托管现有的Apache集群,这样就可以方便地进行数据迁移。不过,需要注意的是,不同的工具可能支持的Hadoop发行版不同,例如Ambari可以与各种Hadoop发行版集成,包括Apache Hadoop、Hortonworks Data Platform(HDP)和IBM Spectrum Scale,而Cloudera Manager则主要用于管理Cloudera发行版。因此,在实际使用中,需要根据具体的环境和需求来选择适合的工具。
15. Hadoop中的Flume是什么?它的主要作用是什么?
Flume是Apache下的一个开源大数据日志采集、聚合和传输系统。它主要的作用是实时的读取服务器本地磁盘的数据,并将数据写到HDFS里面。同时,Flume也能提供从固定目录下采集日志信息到目的地(HDFS,HBase,Kafka)的能力。
Flume的核心架构由Source、Channel和Sink三个组件构成。Source是数据流中接受Event(事件)的组件,通常从客户端程序或上一个Agent接收数据,并写入一个或多个Channel。Channel是位于Source和Sink之间的缓冲区,Flume自带两种Channel:Memory Channel和File Channel。Memory Channel是基于内存缓存,适用于不需要关心数据丢失的情景;而File Channel则是Flume的持久化Channel,即使系统宕机也不会丢失数据。最后,Sink负责将数据输出到各种目的地,常见的包括HDFS、Kafka、logger、File等。
16. 请简要介绍一下Hadoop的数据仓库解决方案,如Hive、Pig等。
Hadoop中的数据仓库解决方案主要包括Hive和Pig。
Hive是一款基于Hadoop的数据仓库系统,它可以将结构化数据存储在Hadoop的HDFS中,并使用SQL语言进行查询和分析。Hive的主要目标是让用户可以使用熟悉的SQL语言来处理大规模的结构化数据,而无需熟悉MapReduce编程。
Pig则是一种基于Hadoop的大数据分析平台,它提供了一种高级语言PL/SQL,可以简化数据处理流程。与Hive不同,Pig的执行流程是声明性的,因此更适合供数据科学家用于实现数据分析。
总的来说,Hive和Pig都是在Hadoop环境中对大数据进行处理和分析的重要工具,它们各自具有独特的优势和适用场景。
17. Hadoop中的Zookeeper是什么?它的主要作用是什么?
ZooKeeper是Apache Hadoop的一个子项目,它是一个开放源码的,分布式的协调服务。在Hadoop生态系统中,ZooKeeper的主要作用是管理和协调分布式应用程序的配置信息、命名服务、分布式锁和分布式协调等任务。
为了进一步明确其功能,可以将其具体作用归纳为以下几个方面:首先,ZooKeeper提供统一命名服务,为分布式系统中的每个节点提供一个唯一的标识符,以便于对各个节点进行管理和调度;其次,ZooKeeper可以实现状态同步服务,通过监控和管理各个节点的状态变化,确保整个系统的正常运行;再次,ZooKeeper可用于集群管理,如实时监控集群中各个节点的工作状态,以及进行节点的添加、删除和替换等操作;最后,ZooKeeper还可以实现分布式应用配置项的管理,帮助开发人员对应用的配置信息进行统一的管理和调整。
此外,ZooKeeper也在诸如Apache Hbase和Apache Solr等项目中发挥着重要的作用。例如,在搭建高可用的Hadoop集群(High Availability, 简称HA)时,ZooKeeper可以用于实现namenode的备份,以提高集群的可靠性。
18. 请简要介绍一下Hadoop的性能调优方法,如何提高数据处理速度?
Hadoop的性能优化主要有以下几个方面:
合理分配CPU核数:数据节点建议预留24个核给操作系统和其他进程(如数据库,HBase等),其他的核分配给YARN。控制节点由于运行的进程较多,建议预留68个核。
JVM重用:N个Task按顺序在同一个Jvm上运行,省去了Jvm关闭和再重启的时间。
调整MapReduce参数:可以调整Java虚拟机堆大小、Map和Reduce任务数等参数来提高MapReduce性能。
优化HDFS配置:例如调整Hadoop的副本数,增加数据块大小等。
优化网络配置:例如增加带宽、减少网络延迟等。
通过这些方法,可以有效地提高Hadoop的数据处理速度。
19. Hadoop中的Capacity Scheduler是什么?它的主要作用是什么?
Hadoop中的Capacity Scheduler是一个可插拔的资源调度器,它的主要作用是允许多租户安全的共享集群资源。在保证每个队列的应用程序在容量限制之下,可以及时的分配资源,以运行hadoop应用。
具体来说,它是YARN中默认的资源调度器,负责对各种用户提交的任务进行调度和资源分配。例如,对于每天晚上进行的日常任务dailyTask,这些任务需要在尽可能短的时间内完成,因此会分配较多的资源;而对于白天通过Hive来获取一些数据信息的任务,由于对查询速度要求并不是很高,且断断续续的,所以分配的资源较少。
同时,Capacity Scheduler也支持多队列结构,包括预定义队列和用户自定义队列。其核心就是队列的分配和使用了,可以通过修改配置文件来配置队列。例如,可以调整队列的最大资源使用率、总资源容量等参数。
总的来说,Capacity Scheduler的设计目标是以操作员友好的方式运行Hadoop应用程序,同时最大限度地提高集群的吞吐量和利用率,实现资源的高效共享和管理。
20. 请简要介绍一下Hadoop的扩展性和可伸缩性,如何应对不断增长的数据量和处理需求?
Hadoop的设计原则之一就是高度的可扩展性和伸缩性,它允许用户处理从单个服务器到成千上万台计算机集群的计算需求。这种设计使得Hadoop能有效地应对不断增长的数据量和处理需求。
当数据量不断增长时,Hadoop可以通过增加节点的方式扩大集群的规模,以提高数据处理能力。同时,Hadoop可以在成百上千的机器间分配和处理数据,这也是其可伸缩性的一种体现。此外,Hadoop能够在节点之间动态地移动数据,以保持各个节点的动态平衡,从而提高整个集群的处理效率。
除了硬件层面的扩展外,Hadoop也支持软件层面的扩展性。例如,用户可以使用多种编程语言(如Python、C++、Perl、Ruby等)在Hadoop中进行编程,以满足不同的处理需求。同时,Hadoop的MapReduce编程模型和HDFS分布式文件系统等核心组件也提供了丰富的API,使用户可以灵活地进行定制和优化。
总的来说,Hadoop通过硬件和软件的双重扩展能力,以及其内部机制的优化,有效地应对了不断增长的数据量和处理需求。
(Hadoop的可扩展性和伸缩性是其核心优势之一,它能够适应不断增长的数据量和处理需求。具体来说,Hadoop的设计使得它不会用单个企业服务器的容量来限制数据吞吐量,而是允许跨计算机集群对大型数据集进行分布式处理。
在实现大数据扩展性与可伸缩性方面,Hadoop主要采取以下策略:
分布式存储与计算:Hadoop采用分布式存储系统(如HDFS),将数据分散存储在多个节点上,从而提高存储能力。同时,通过MapReduce编程模型,实现数据的并行处理,进而提高数据处理效率。
垂直扩展:在垂直扩展中,我们向单个节点添加了更多资源(如CPU)。通过这种方式,我们增加了Hadoop系统的硬件容量。
水平扩展:除了垂直扩展外,Hadoop还可以通过增加更多的机器来扩大整个集群的规模,进而提高整体的处理能力。)