爬虫的深度爬取和爬取视频的方式
深度爬取豆瓣读书
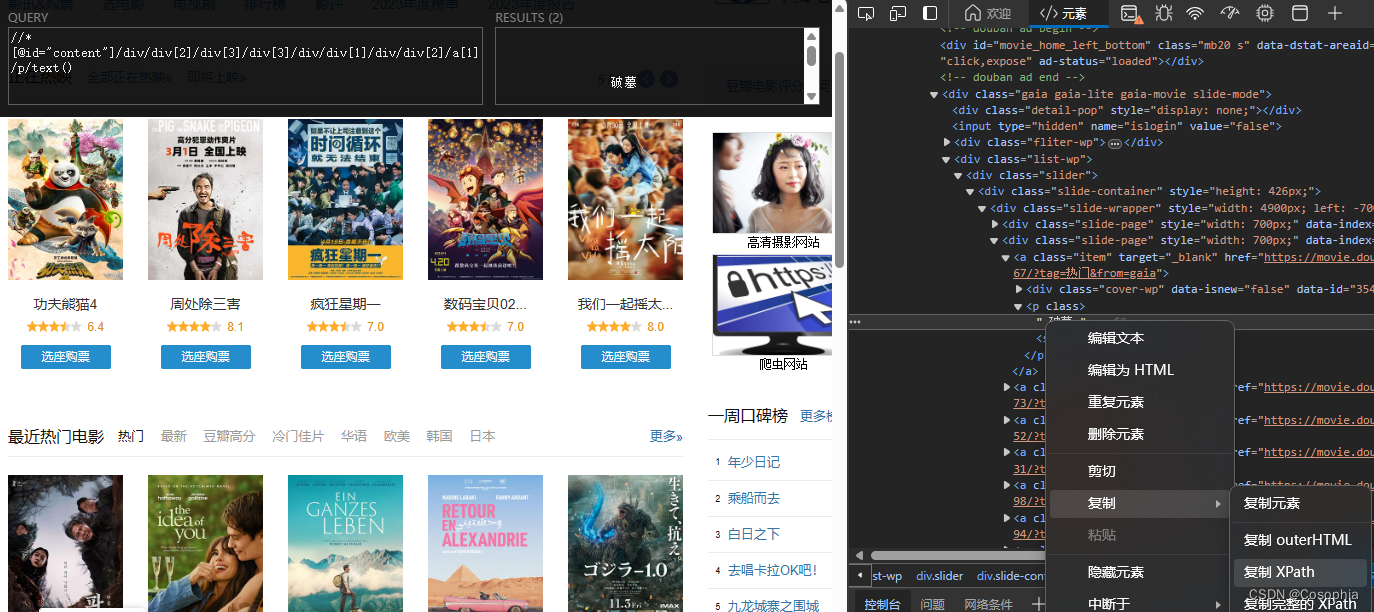
import time import fake_useragent import requests from lxml import etree head = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0" } if __name__ == '__main__': # 1、url url = "https://book.douban.com/tag/%E4%BA%92%E8%81%94%E7%BD%91"#url地址 # 2、发送请求 resp = requests.get(url, headers=head) time.sleep(5) # 3、获取想要的数据 res_text = resp.text#获得html形式的数据 # 4、数据解析 tree = etree.HTML(res_text)#将html转化为元素形式 a_list = tree.xpath("//ul[@class='subject-list']/li/div[2]/h2/a") for a in a_list: time.sleep(3) # 1、url book_url = "".join(a.xpath("./@href"))#里面的网页的url # 2、发送请求 book_res = requests.get(book_url, headers=head) # 3、获取想要的信息 book_text = book_res.text # 4、数据解析 book_tree = etree.HTML(book_text) book_name = "".join(book_tree.xpath("//span[@property='v:itemreviewed']/text()")) author = "".join(book_tree.xpath("//div[@class='subject clearfix']/div[2]/span[1]/a/text()")) publish = "".join(book_tree.xpath("//div[@class='subject clearfix']/div[2]/a[1]/text()")) y = "".join(book_tree.xpath("//span[@class='pl' and text()='出版年:']/following-sibling::text()[1]")) page = "".join(book_tree.xpath("//span[@class='pl' and text()='页数:']/following-sibling::text()[1]")) price = "".join(book_tree.xpath("//span[@class='pl' and text()='定价:']/following-sibling::text()[1]")) bind = "".join(book_tree.xpath("//span[@class='pl' and text()='装帧:']/following-sibling::text()[1]")) isbn = "".join(book_tree.xpath("//span[@class='pl' and text()='ISBN:']/following-sibling::text()[1]")) print(book_name, author, publish, y, page, price, bind, isbn) pass代码思路






B站爬取视频
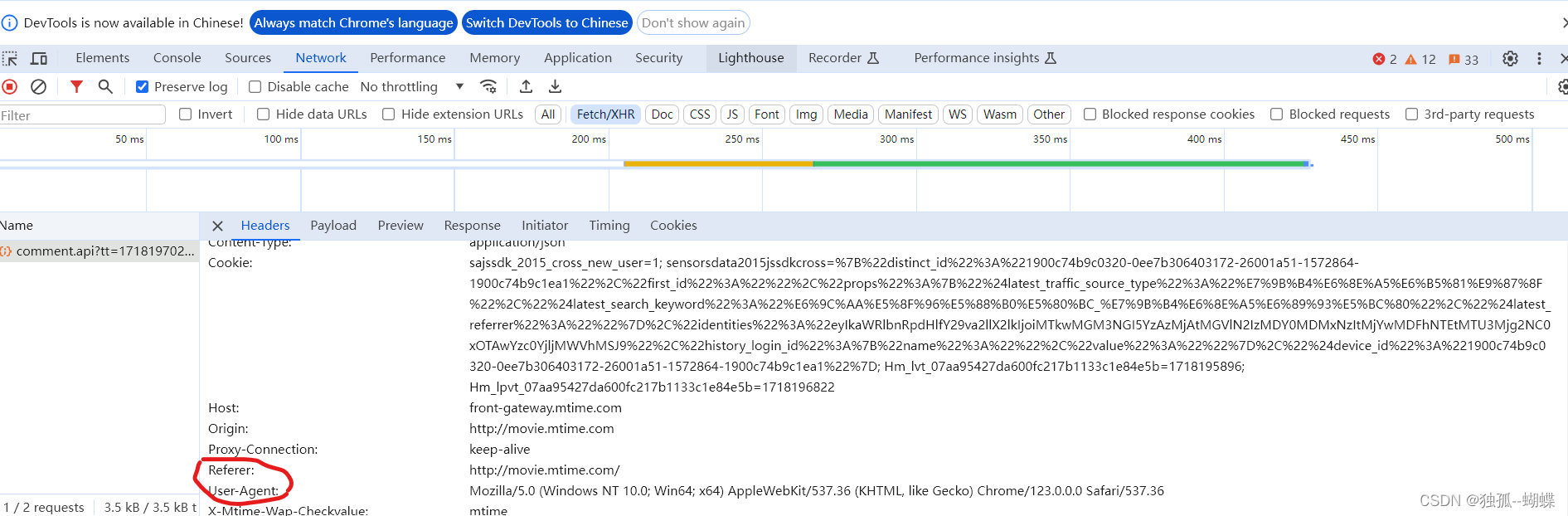
# requests 请求b站视频 import json import fake_useragent import requests from lxml import etree if __name__ == '__main__': # UA伪装 head = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0" # 防盗链 , "Referer": "https://www.bilibili.com/"#必须有 , "Cookie": "这里是登录要求,输入个人的登录信息" } # 1、指定url url = "https://www.bilibili.com/video/BV12z421z75d/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=4b1ef23e5d47e143cfb702705740719d" # 2、发送请求 response = requests.get(url, headers=head) # 3、获取响应的数据 res_text = response.text # 4、数据解析 tree = etree.HTML(res_text) with open("b.html", "w", encoding="utf8") as f: f.write(res_text) base_info = "".join(tree.xpath("/html/head/script[4]/text()"))[20:]#b站固定的位置html/head/script[4],前面的不需要,只有括号里的字符串有用所有取20以后的 info_dict = json.loads(base_info) video_url = info_dict["data"]["dash"]['video'][0]["baseUrl"]#视频 audio_url = info_dict["data"]["dash"]['audio'][0]["baseUrl"]#音频 video_content = requests.get(video_url, head).content#和图片一样采用content audio_content = requests.get(audio_url, head).content with open("video.wmv", "wb") as f:#以二进制的形式 f.write(video_content) with open("audio.mp4", "wb") as fp: fp.write(audio_content) pass代码思路