概要
之前的文章已经介绍了如何在本地使用源码的yolo-world进行本地化训练模型,具体请参考:Yolo-World在自定义数据集上进行闭集词汇训练过程
下边介绍一下基于ultralytics库训练yolo-world的方法,非常简单!
训练整体流程
(1)首先可以编辑一个py文件写上以下几行代码,在官网有详细的代码解释,大家可以去官网详细阅读其他基于命令行CLI的训练方式等。
官网链接在这
from ultralytics import YOLOWorld
if __name__ == '__main__':
# Load a pretrained YOLOv8s-worldv2 model
model = YOLOWorld("yolov8s-worldv2.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="data.yaml", epochs=80, imgsz=640)
(2)代码中可以看到我们需要两个文件,一个是yolov8s-worldv2.pt文件,一个是data.yaml文件(这个是根据自己的数据集做的自定义文件),接下来准备这两个文件即可。
(3)准备权重文件:
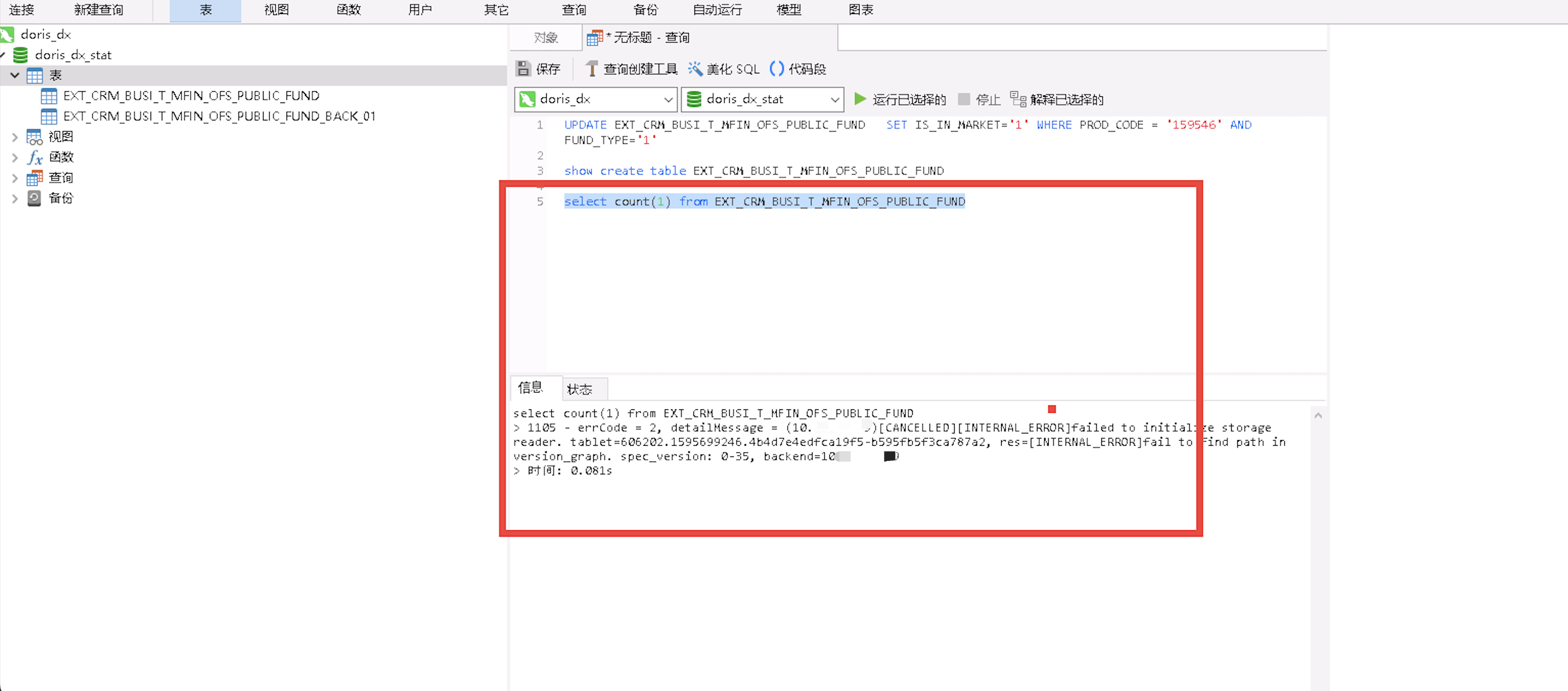
yolov8s-worldv2.pt文件可以直接在github上下载:github链接
注意下载权重文件的时候找到Zero-shot Inference on LVIS dataset部分,然后最下边的的框框往又拉,找到链接进入Hugging Face下载,具体可以看下图,下载后放到指定位置,修改代码中的文件路径,这样就准备好了权重文件。

(3)准备yaml文件:
yaml文件的格式如果大家之前跑过yolo项目的话应该都知道是什么样的,不了解的话可以去官网看一下coco.yaml,我这里自定义的yaml文件主要有这几部分:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/software/code/yolo/yoloWorld-demo/data2019 # dataset root dir
train: data2019_train/images # train images (relative to 'path') 118287 images
val: data_val/images # val images (relative to 'path') 5000 images
test: data_test/images # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
names:
0: person
1: bicycle
2: car
解释一下:
path:: 这个参数指定了数据集的根目录。这个目录应该包含训练、验证和测试数据集的图像文件以及标签文件。train: 这个参数指定了训练图像和标签的目录。data_train/images表示训练图像存储在path目录下的data_train文件夹中的images子文件夹。这个目录包含用于训练的图像。val这个参数指定了验证图像和标签的目录。data_val/images表示验证图像存储在path目录下的data_val文件夹中的images子文件夹。test: 这个参数指定了测试图像的目录。data_test/images表示测试图像存储在path目录下的data_test文件夹中的images子文件夹。names: 这个参数指定了图像中检测目标的类别,以及类别对应的id。
当然在官网上的yaml文件中的train和val后边放的都是txt文件,txt中包含的是每一张图片的存放路径,那种写法也是可以的,大家可以自行尝试,这里不再过多解释。
下图是yaml文件与上边的代码一一对应的写法,大家可以参考。
注意:train和val文件夹下边都有images和labels,这样可以在训练的时候直接加载进去。(labels中的yolo格式的txt标注文件)

(4)这时候直接运行就可以进行训练了。其他遇到的问题可能就是处理标签的问题了,问题各异,大家可以通过ChatGPT解决,很方便。

推理整体流程
跑完你设定的epoch之后会得到runs\detect\train\weights文件夹这里边会保存训练过程中的模型文件,以及训练过程中的数据。拿到训练好的权重文件之后就可以进行推理了。
from ultralytics import YOLOWorld
if __name__ == '__main__':
# Initialize a YOLO-World model
model = YOLOWorld("runs/detect/train/weights/best.pt") # or select yolov8m/l-world.pt for different sizes
# Execute inference with the YOLOv8s-world model on the specified image
model.set_classes(["truck"])
results = model.predict("car.jpg")
# Show results
results[0].show()
在推理过程中可以设定检测类别set_classes这样只会检测你设定的类别,也可以选择不设定,就会检测所有的类别,最后进行结果展示。
其他的操作和玩法请参考官网