目录
2.2 backend/scraper/rss_scraper.py
2.3 backend/data_processing/cleaner.py
3.1 frontend/src/services/api.js
3.2 frontend/src/components/NewsList.js
七、考虑错误处理、日志记录、性能优化、安全措施(如CORS、CSRF防护)和多线程/异步处理
2.修改frontend/src/components/NewsList.js:
十、处理WebSocket断线重连、优化UI布局和样式、以及处理大量新闻数据时的性能优化
2.修改frontend/src/components/NewsList.js
十一、处理网络延迟、服务器性能、数据库优化等,以确保整个系统的稳定性和响应速度
十二、实现监控和分析系统性能瓶颈,调整硬件资源配置,以及优化代码逻辑
十三、使用生产级的Web服务器(如Nginx)和负载均衡器,并考虑容器化部署和持续集成/持续部署(CI/CD)
要实现一个7x24小时新闻资讯同步系统,涉及多个技术层面和架构设计考虑。以下是一个基于这些需求的分析、架构设计建议、以及技术实现概述。
一、需求分析
- 数据抓取:从多个新闻源(如RSS、API、网站等)抓取新闻资讯。
- 实时同步:确保新闻资讯能够实时或接近实时地同步到你的平台上。
- 7x24小时更新:系统需具备高可用性和稳定性,确保全天候不间断运行。
- 数据存储:高效存储抓取的数据,便于后续处理和展示。
- 数据处理:对抓取的数据进行清洗、去重、分类等处理。
- 前端展示:提供一个用户友好的界面来展示新闻资讯。
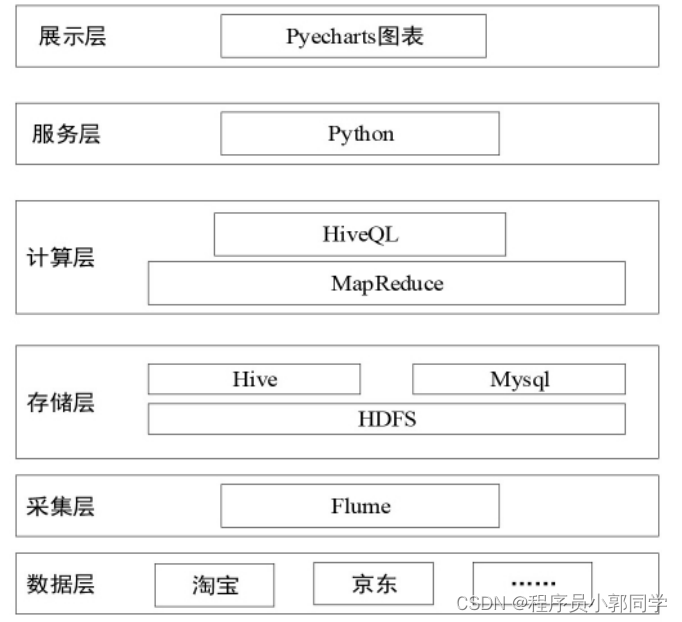
二、架构设计
1.系统架构
- 数据源层:包括多个新闻源(RSS、APIs、网页爬虫)。
- 数据抓取层:使用爬虫或API调用技术从数据源层抓取数据。
- 数据处理层:对抓取的数据进行清洗、去重、分类等处理。
- 数据存储层:使用数据库或NoSQL存储系统(如MongoDB)来存储处理后的数据。
- 消息队列:可选,用于解耦数据抓取和数据处理,确保系统的可扩展性和稳定性。
- 应用服务层:提供API接口供前端调用,获取新闻数据。
- 前端展示层:通过Web或移动应用展示新闻资讯。
2 .关键技术选型
- 爬虫技术:Python的Scrapy、等库,或使用Node.js的Puppeteer进行网页渲染抓取。
- API调用:使用HTTP客户端库(如Python的requests或Node.js的axios)调用新闻源的API。
- 数据存储:MongoDB(适用于非结构化数据)、MySQL(如果需要结构化查询)或Redis(缓存热门新闻)。
- 消息队列:RabbitMQ、Kafka等,用于异步处理和数据缓冲。
- 后端服务:Node.js、Django/Flask(Python)等,提供RESTful API。
- 前端技术:React、Vue.js或Angular等现代JavaScript框架,结合Redux/Vuex/NgRx等状态管理库。
- 部署与运维:Docker容器化部署,Kubernetes进行集群管理,Prometheus和Grafana进行监控。
三、代码实现概述
1.数据抓取
- 编写爬虫:根据新闻源的类型(RSS、HTML、API),编写相应的爬虫脚本。
- API调用:编写函数调用新闻源的API,获取新闻数据。
- 异常处理:处理网络请求异常、数据格式错误等。
2. 数据处理
- 数据清洗:去除HTML标签、转义特殊字符等。
- 去重:根据新闻标题、URL或内容摘要等信息进行去重。
- 分类:根据新闻内容或标签进行分类。
3.数据存储
- 数据库设计:设计合理的数据库模型,存储新闻数据。
- 数据入库:将处理后的数据存储到数据库中。
4.应用服务
- API开发:开发RESTful API,供前端调用获取新闻数据。
- 认证与授权:实现API的访问控制。
5. 前端展示
- 界面设计:设计用户友好的新闻展示界面。
- 数据交互:通过AJAX或Fetch API与后端服务进行数据交互。
- 实时更新:使用WebSocket或轮询技术实现新闻资讯的实时更新。
四、项目实践及代码实现
创建一个完整的新闻资讯同步系统涉及多个技术栈和组件,这里我将提供一个简化版的示例代码结构和关键部分的代码片段,用于说明如何开始构建这个系统。
1. 项目结构
NewsSyncSystem/
│
├── backend/
│ ├── api/
│ │ └── news.py
│ ├── scraper/
│ │ ├── rss_scraper.py
│ │ └── api_scraper.py
│ ├── data_processing/
│ │ ├── cleaner.py
│ │ └── categorizer.py
│ ├── database/
│ │ └── db_manager.py
│ └── main.py
│
└── frontend/
├── public/
│ └── index.html
├── src/
│ ├── components/
│ │ └── NewsList.js
│ ├── services/
│ │ └── api.js
│ └── App.js
└── package.json2. 后端代码片段
2.1 backend/main.py
from flask import Flask, jsonify
from scraper import scrape_news
from data_processing import clean_and_categorize
from database.db_manager import save_news
app = Flask(__name__)
@app.route('/news')
def get_news():
news = scrape_news()
cleaned_news = clean_and_categorize(news)
save_news(cleaned_news)
return jsonify(cleaned_news)
if __name__ == '__main__':
app.run(debug=True) 2.2 backend/scraper/rss_scraper.py
import feedparser
def scrape_rss_feed(url):
feed = feedparser.parse(url)
news = [{'title': entry.title, 'link': entry.link} for entry in feed.entries]
return news 2.3 backend/data_processing/cleaner.py
import re
def clean_news(news_list):
cleaned_news = []
for news in news_list:
title = re.sub('<[^<]+?>', '', news['title'])
link = news['link']
cleaned_news.append({'title': title, 'link': link})
return cleaned_news3. 前端代码片段
3.1 frontend/src/services/api.js
const fetchNews = async () => {
const response = await fetch('/news');
const news = await response.json();
return news;
}; 3.2 frontend/src/components/NewsList.js
import React, { useEffect, useState } from 'react';
import { fetchNews } from '../services/api';
function NewsList() {
const [news, setNews] = useState([]);
useEffect(() => {
fetchNews().then(setNews);
}, []);
return (
<div>
<h1>Latest News</h1>
<ul>
{news.map(item => (
<li key={item.link}>
<a href={item.link}>{item.title}</a>
</li>
))}
</ul>
</div>
);
}
export default NewsList;4. 注意事项
- 这个示例非常简化,实际应用中你可能需要考虑错误处理、日志记录、性能优化、安全措施(如CORS、CSRF防护)和多线程/异步处理。
- 数据库操作、API调用、数据去重和分类在示例中未完整体现,需要根据具体需求和技术栈选择合适的方法实现。
- 前端部分仅展示了基本的新闻列表展示,实时更新和更复杂的UI设计需要额外实现。
- 生产环境中应使用生产级的Web服务器(如Nginx)和负载均衡器,并考虑容器化部署和持续集成/持续部署(CI/CD)。
七、考虑错误处理、日志记录、性能优化、安全措施(如CORS、CSRF防护)和多线程/异步处理
在上一次的代码基础上,我们将添加错误处理、日志记录、性能优化、安全措施(如CORS、CSRF防护)和多线程/异步处理。这些增强功能将使我们的新闻资讯同步系统更加健壮和专业。
1. 错误处理和日志记录
在后端,我们将使用logging模块记录错误和关键事件,使用try...except语句处理异常。
1.1 修改backend/main.py
import logging
from flask import Flask, jsonify, make_response
from flask_cors import CORS
from scraper import scrape_news
from data_processing import clean_and_categorize
from database.db_manager import save_news
app = Flask(__name__)
CORS(app)
logging.basicConfig(level=logging.INFO)
@app.errorhandler(Exception)
def handle_exception(e):
logging.error(f"An error occurred: {e}")
return make_response(jsonify({"error": "Internal server error"}), 500)
@app.route('/news')
def get_news():
try:
news = scrape_news()
cleaned_news = clean_and_categorize(news)
save_news(cleaned_news)
return jsonify(cleaned_news)
except Exception as e:
logging.error(f"Error fetching news: {e}")
return make_response(jsonify({"error": "Failed to fetch news"}), 500)
if __name__ == '__main__':
app.run(debug=True)2. 性能优化
使用缓存可以显著提高性能,尤其是在频繁访问相同资源的情况下。在后端,可以使用flask-caching扩展。
2.1 安装Flask-Caching
pip install Flask-Caching 2.2 修改backend/main.py
from flask_caching import Cache
cache = Cache(config={'CACHE_TYPE': 'simple'})
app = Flask(__name__)
cache.init_app(app)
CORS(app)
@app.route('/news')
@cache.cached(timeout=60) # 缓存1分钟
def get_news():
# ...3. 安全措施
3.1 CORS
已在上面的代码中启用。
3.2 CSRF防护
使用flask-wtf和flask-csrf扩展。
pip install Flask-WTF Flask-CSRF3.3 修改backend/main.py
from flask_wtf.csrf import CSRFProtect
csrf = CSRFProtect(app)
@app.route('/news', methods=['GET'])
def get_news():
# ...4. 多线程/异步处理
使用threading模块或asyncio进行异步处理。
4.1 使用多线程
import threading
def scrape_news_threaded():
news = scrape_news()
cleaned_news = clean_and_categorize(news)
save_news(cleaned_news)
thread = threading.Thread(target=scrape_news_threaded)
thread.start()
@app.route('/news')
def get_news():
if not thread.is_alive():
thread.start()
# 返回缓存或最新新闻4.2 使用异步IO (asyncio)
import asyncio
from scraper import scrape_news_async
async def get_news_async():
news = await scrape_news_async()
cleaned_news = await clean_and_categorize_async(news)
await save_news_async(cleaned_news)
return cleaned_news
@app.route('/news')
async def get_news():
return jsonify(await get_news_async())注意:在Flask中直接使用asyncio可能需要一些额外的配置,或使用如quart这样的异步框架。
以上示例提供了错误处理、日志记录、性能优化、安全措施和多线程/异步处理的基本框架。在实际应用中,你可能需要根据具体的业务需求和系统架构进一步定制和优化。
八、实现数据库操作、API调用、数据去重和分类
在新闻资讯同步系统中,实现数据库操作、API调用、数据去重和分类是关键步骤。以下是如何在后端实现这些功能的代码示例。
1. 数据库操作
我们将使用sqlite3作为简单的示例数据库。在生产环境中,你可能需要使用更强大的数据库系统如PostgreSQL或MongoDB。
1.1 创建数据库连接
在database/db_manager.py中:
import sqlite3
from contextlib import closing
DATABASE = 'news.db'
def init_db():
with closing(sqlite3.connect(DATABASE)) as conn:
with open('schema.sql') as f:
conn.executescript(f.read())
conn.commit()
def get_db():
db = sqlite3.connect(DATABASE)
db.row_factory = sqlite3.Row
return db
def close_db(error):
if hasattr(g, 'sqlite_db'):
g.sqlite_db.close()1.2 创建表结构
在项目根目录下创建schema.sql文件:
CREATE TABLE IF NOT EXISTS news (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
url TEXT NOT NULL UNIQUE,
category TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);2. API调用
我们假设有一个API提供新闻数据,使用requests库进行调用。
2.1 API调用
在scraper/api_scraper.py中:
import requests
NEWS_API_URL = "https://api.example.com/news"
HEADERS = {'User-Agent': 'NewsSyncSystem'}
def fetch_news_from_api():
response = requests.get(NEWS_API_URL, headers=HEADERS)
if response.status_code == 200:
return response.json()
else:
raise Exception("Failed to fetch news from API")3. 数据去重和分类
3.1 数据去重
在data_processing/cleaner.py中:
def deduplicate_news(news_list):
seen_urls = set()
unique_news = []
for news in news_list:
if news['url'] not in seen_urls:
seen_urls.add(news['url'])
unique_news.append(news)
return unique_news3.2 数据分类
在data_processing/categorizer.py中:
def categorize_news(news_list):
categorized_news = {}
for news in news_list:
category = news.get('category', 'Uncategorized')
if category not in categorized_news:
categorized_news[category] = []
categorized_news[category].append(news)
return categorized_news4. 整合以上功能
在backend/main.py中:
from scraper.api_scraper import fetch_news_from_api
from data_processing.cleaner import deduplicate_news
from data_processing.categorizer import categorize_news
from database.db_manager import get_db, init_db
# 初始化数据库
init_db()
@app.route('/news')
def get_news():
try:
news_data = fetch_news_from_api()
unique_news = deduplicate_news(news_data)
categorized_news = categorize_news(unique_news)
# 插入到数据库
db = get_db()
for news in unique_news:
db.execute(
"INSERT INTO news (title, url, category) VALUES (?, ?, ?)",
(news['title'], news['url'], news.get('category'))
)
db.commit()
return jsonify(categorized_news)
except Exception as e:
logging.error(f"Error fetching and processing news: {e}")
return make_response(jsonify({"error": "Failed to fetch and process news"}), 500)请确保在实际部署前,你已对数据库操作进行了充分的测试和安全性检查,防止SQL注入和其他数据库相关的安全问题。此外,根据API的响应格式和数据的具体情况,你可能需要对数据解析和处理逻辑进行适当的调整。
九、实时更新和更复杂的UI设计
1.实时更新
要实现实时更新新闻资讯,可以使用WebSocket技术或者轮询策略。这里我们将使用WebSocket,因为它提供了低延迟的双向通信,非常适合实时更新场景。
2.后端WebSocket支持
使用flask-socketio扩展来添加WebSocket支持。
1.安装flask-socketio:
pip install flask-socketio 2.修改backend/main.py:
注意:由于flask-socketio使用eventlet作为异步服务器,所以启动方式有所不同。
3.前端WebSocket客户端
在前端,我们将使用Socket.IO的JavaScript客户端库。
1.在frontend/public/index.html中引入Socket.IO库:
<script src="https://cdn.socket.io/socket.io-1.4.5.js"></script>2.修改frontend/src/App.js:
import React, { useEffect, useState } from 'react';
import NewsList from './components/NewsList';
import io from 'socket.io-client';
const socket = io('http://localhost:5000');
function App() {
const [news, setNews] = useState([]);
useEffect(() => {
socket.on('news_update', (data) => {
setNews(data);
});
}, []);
return (
<div className="App">
<h1>Latest News</h1>
<NewsList news={news} />
</div>
);
}
export default App;3.更复杂的UI设计
对于更复杂的UI设计,你可以使用React的Material-UI、Ant Design或其他流行的UI库。这里使用Material-UI作为示例。
1.安装Material-UI:
npm install @material-ui/core @material-ui/icons2.修改frontend/src/components/NewsList.js:
import React from 'react';
import { List, ListItem, ListItemText, ListItemAvatar, Avatar } from '@material-ui/core';
import AccountCircleIcon from '@material-ui/icons/AccountCircle';
function NewsList({ news }) {
return (
<List>
{news.map((item) => (
<ListItem key={item.url}>
<ListItemAvatar>
<Avatar>
<AccountCircleIcon />
</Avatar>
</ListItemAvatar>
<ListItemText primary={item.title} secondary={item.category} />
</ListItem>
))}
</List>
);
}
export default NewsList;以上代码提供了实时更新功能和更复杂的UI设计。但请注意,实际项目中可能需要根据具体需求进行更多定制和优化,例如处理WebSocket断线重连、优化UI布局和样式、以及处理大量新闻数据时的性能优化等。
十、处理WebSocket断线重连、优化UI布局和样式、以及处理大量新闻数据时的性能优化
1.处理WebSocket断线重连
在WebSocket的前端实现中,我们可以监听disconnect事件,并在断开连接后自动尝试重新连接。下面是在前端React应用中如何实现这一功能的示例:
1.修改frontend/src/App.js
import React, { useEffect, useState } from 'react';
import NewsList from './components/NewsList';
import io from 'socket.io-client';
const socket = io('http://localhost:5000', { reconnect: true, autoConnect: true });
function App() {
const [news, setNews] = useState([]);
useEffect(() => {
socket.on('connect', () => {
console.log('Connected to the server');
});
socket.on('disconnect', () => {
console.log('Disconnected from the server');
});
socket.on('reconnect', () => {
console.log('Reconnected to the server');
});
socket.on('news_update', (data) => {
setNews(data);
});
return () => {
socket.off('news_update');
socket.disconnect();
};
}, []);
return (
<div className="App">
<h1>Latest News</h1>
<NewsList news={news} />
</div>
);
}
export default App;2.优化UI布局和样式
为了优化UI布局和样式,我们可以使用CSS框架或CSS-in-JS库,如styled-components,来创建更美观且响应式的布局。这里我们将使用styled-components来修改NewsList组件。
1.安装styled-components
npm install styled-components2.修改frontend/src/components/NewsList.js
import React from 'react';
import { List, ListItem, ListItemText, ListItemAvatar, Avatar } from '@material-ui/core';
import AccountCircleIcon from '@material-ui/icons/AccountCircle';
import styled from 'styled-components';
const StyledList = styled(List)`
margin-top: 16px;
& .MuiListItem-root {
border-bottom: 1px solid rgba(0, 0, 0, 0.12);
&:last-child {
border-bottom: none;
}
}
`;
function NewsList({ news }) {
return (
<StyledList>
{news.map((item) => (
<ListItem key={item.url}>
<ListItemAvatar>
<Avatar>
<AccountCircleIcon />
</Avatar>
</ListItemAvatar>
<ListItemText primary={item.title} secondary={item.category} />
</ListItem>
))}
</StyledList>
);
}
export default NewsList;3.处理大量新闻数据时的性能优化
当处理大量新闻数据时,前端需要考虑性能优化,以避免页面加载缓慢或卡顿。一种常见的方法是分页显示数据,或者使用虚拟滚动技术。
1.分页显示
在NewsList组件中,你可以添加分页功能,只显示一部分新闻,当用户滚动到页面底部时再加载更多。
2.虚拟滚动
另一种方法是使用虚拟滚动,它只渲染视口内的项,大大减少了DOM元素的数量,从而提高了性能。你可以使用如react-virtualized或react-window等库来实现虚拟滚动。
4.总结
以上代码示例展示了如何在新闻资讯同步系统中实现WebSocket的断线重连、优化UI布局和样式,以及在处理大量数据时的性能优化。在实际应用中,你可能还需要考虑其他因素,如网络延迟、服务器性能、数据库优化等,以确保整个系统的稳定性和响应速度。
十一、处理网络延迟、服务器性能、数据库优化等,以确保整个系统的稳定性和响应速度
1.网络延迟和服务器性能优化
为了减少网络延迟并提高服务器性能,你可以采取以下几种策略:
使用CDN(内容分发网络): CDN可以缓存静态资源(如CSS、JS文件和图片)并就近提供给用户,减少网络延迟。
负载均衡: 使用负载均衡器(如Nginx或HAProxy)可以在多台服务器间分发请求,减轻单台服务器的压力。
缓存: 实现缓存策略,如使用Redis或Memcached,可以存储常用数据和计算结果,减少数据库查询次数。
异步处理和队列: 使用消息队列(如RabbitMQ或Kafka)处理耗时任务,如新闻抓取和数据处理,可以避免阻塞主线程,提高服务器响应速度。
优化API响应时间: 使用压缩(gzip)减少传输数据量,限制API请求的并发数,以及优化数据库查询。
2.数据库优化
数据库优化是提高系统响应速度的关键。以下是一些数据库优化的策略:
索引: 对于经常用于查询的字段,如新闻的
url和category,应该创建索引。批量插入: 在插入大量新闻数据时,使用批量插入而不是逐条插入,可以显著提高效率。
定期维护: 定期执行数据库的VACUUM或ANALYZE操作,以保持数据库的最佳性能。
读写分离: 如果可能,设置主从数据库,将读取操作分散到多个从数据库,减轻主数据库的负担。
3.编写代码示例
1.优化API响应时间
在backend/main.py中,我们可以使用flask-compress来启用gzip压缩。
1.安装flask-compress:
pip install flask-compress2.在main.py中添加压缩中间件:
from flask_compress import Compress
app.config['COMPRESS_MIMETYPES'] = ['text/html', 'text/css', 'application/json']
app.config['COMPRESS_LEVEL'] = 6
app.config['COMPRESS_MIN_SIZE'] = 500
compress = Compress(app)2.批量插入数据库
在database/db_manager.py中,修改插入新闻数据的函数:
def insert_news(news_list):
db = get_db()
db.executemany(
"INSERT INTO news (title, url, category) VALUES (?, ?, ?)",
[(news['title'], news['url'], news.get('category')) for news in news_list]
)
db.commit()3.数据库索引
在schema.sql中,为url和category字段创建索引:
CREATE INDEX idx_news_url ON news(url);
CREATE INDEX idx_news_category ON news(category);以上代码示例展示了如何在网络延迟、服务器性能和数据库优化方面进行改进,以确保新闻资讯同步系统的稳定性和响应速度。在实际部署中,你可能需要根据具体情况进行更深入的性能调优,包括但不限于监控和分析系统性能瓶颈,调整硬件资源配置,以及优化代码逻辑。
十二、实现监控和分析系统性能瓶颈,调整硬件资源配置,以及优化代码逻辑
1.实现监控和分析系统性能瓶颈
为了监控和分析系统性能,可以采用以下策略:
使用Prometheus和Grafana: Prometheus是一个开源的监控系统和时间序列数据库,Grafana是一个开源的可视化平台,可以用来展示Prometheus收集的数据。
日志分析: 使用ELK Stack(Elasticsearch, Logstash, Kibana)或类似工具来收集和分析日志,帮助识别性能瓶颈和异常行为。
性能剖析: 使用Python的
cProfile或JavaScript的console.time等工具进行代码级别的性能剖析。
2.调整硬件资源配置
根据监控结果,你可能需要调整服务器的硬件配置,如增加CPU核心数量、内存大小或磁盘空间。在云环境中,可以使用如AWS EC2、Google Cloud Compute Engine或Azure Virtual Machines等服务,根据需求动态调整资源。
3.优化代码逻辑
代码优化可以从多个角度入手,包括但不限于:
算法优化: 确保使用最有效的数据结构和算法,减少不必要的计算。
减少数据库交互: 尽量减少数据库的查询和写入操作,利用缓存来存储频繁访问的数据。
异步编程: 使用异步I/O和多线程/多进程来提高程序的并发能力。
代码重构: 重构冗长或复杂的代码段,提高代码的可读性和可维护性。
4.编写代码示例
1.实现监控
安装Prometheus和Grafana: 根据官方文档安装并配置Prometheus和Grafana。
在Flask应用中加入Prometheus监控: 使用
flask-prometheus-metrics库来收集应用的指标。pip install flask-prometheus-metrics在
backend/main.py中:from flask_prometheus_metrics import register_metrics # ... register_metrics(app, app_version="1.0.0", app_config="production") if __name__ == '__main__': app.run(debug=False)2.异步编程
在
scraper/api_scraper.py中,我们可以使用asyncio来异步调用API,以提高效率。import aiohttp import asyncio NEWS_API_URL = "https://api.example.com/news" async def fetch(session, url): async with session.get(url) as response: return await response.json() async def fetch_news_from_api(): async with aiohttp.ClientSession() as session: tasks = [fetch(session, NEWS_API_URL)] return await asyncio.gather(*tasks) # 在调用的地方使用 asyncio.run(fetch_news_from_api())3.代码重构
在
data_processing/cleaner.py中,重构去重逻辑,使用集合来提高查找效率:
def deduplicate_news(news_list):
url_set = set()
unique_news = []
for news in news_list:
if news['url'] not in url_set:
url_set.add(news['url'])
unique_news.append(news)
return unique_news以上代码示例展示了如何在新闻资讯同步系统中实现监控和分析性能瓶颈,调整硬件资源配置,以及优化代码逻辑。在实际应用中,持续的监控和优化是必要的,以确保系统长期稳定运行并能应对不断增长的负载。
十三、使用生产级的Web服务器(如Nginx)和负载均衡器,并考虑容器化部署和持续集成/持续部署(CI/CD)
1.生产环境部署与CI/CD
在生产环境中,使用生产级的Web服务器和负载均衡器,以及容器化部署和持续集成/持续部署(CI/CD)流程,可以提高系统的可靠性、可伸缩性和自动化程度。
1. 使用Nginx作为Web服务器和负载均衡器
Nginx是一个高性能的HTTP和反向代理服务器,可以用于负载均衡和缓存,提升应用的稳定性和性能。
Nginx配置示例
创建一个Nginx配置文件,例如/etc/nginx/sites-available/news-sync.conf:
server {
listen 80;
server_name news.example.com;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_read_timeout 90;
}
location /metrics {
proxy_pass http://backend:5000/metrics;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_read_timeout 90;
}
}然后,创建符号链接以启用配置:
sudo ln -s /etc/nginx/sites-available/news-sync.conf /etc/nginx/sites-enabled/重启Nginx以应用更改:
sudo service nginx restart2. 容器化部署
使用Docker和Docker Compose或Kubernetes进行容器化部署,可以方便地管理和扩展应用。
Dockerfile示例
在项目根目录下创建Dockerfile:
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "main.py"]docker-compose.yml示例
在项目根目录下创建docker-compose.yml:
version: '3'
services:
backend:
build: .
ports:
- "5000:5000"
environment:
- FLASK_ENV=production构建和运行Docker容器:
docker-compose up -d3. CI/CD
使用Jenkins、GitLab CI/CD或GitHub Actions等工具实现自动化构建和部署。
GitHub Actions示例
在项目根目录下创建.github/workflows/ci-cd.yml:
name: CI/CD Pipeline
on:
push:
branches:
- master
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.10
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Build Docker image
run: |
docker build -t news-sync-backend .
- name: Push Docker image
run: |
docker login -u ${{ secrets.DOCKER_USERNAME }} -p ${{ secrets.DOCKER_PASSWORD }}
docker tag news-sync-backend ${{ secrets.DOCKER_REGISTRY }}/news-sync-backend:latest
docker push ${{ secrets.DOCKER_REGISTRY }}/news-sync-backend:latest
- name: Deploy to production
uses: appleboy/ssh-action@master
with:
host: ${{ secrets.PRODUCTION_SERVER_HOST }}
username: ${{ secrets.PRODUCTION_SERVER_USERNAME }}
password: ${{ secrets.PRODUCTION_SERVER_PASSWORD }}
port: 22
script: |
docker stop news-sync-backend
docker rm news-sync-backend
docker rmi ${{ secrets.DOCKER_REGISTRY }}/news-sync-backend:latest
docker pull ${{ secrets.DOCKER_REGISTRY }}/news-sync-backend:latest
docker run -d --name news-sync-backend -p 5000:5000 ${{ secrets.DOCKER_REGISTRY }}/news-sync-backend:latest以上步骤描述了如何在生产环境中使用Nginx作为Web服务器和负载均衡器,使用Docker和Docker Compose进行容器化部署,以及使用GitHub Actions实现CI/CD自动化流程。在实际部署中,你可能需要根据具体环境和需求调整配置和脚本。
十四、案例分析
可以参考类似的新闻聚合网站或应用(如Flipboard、今日头条等),分析它们的架构设计、技术选型、数据处理流程等,以获取更多的实践经验和灵感。
十五、总结
实现一个7x24小时新闻资讯同步系统需要综合考虑数据源、数据抓取、数据处理、数据存储、应用服务、前端展示等多个方面。通过合理的架构设计和技术选型,可以构建一个高效、稳定、可扩展的新闻资讯同步系统。

![[<span style='color:red;'>架构</span>之路-<span style='color:red;'>254</span>]:目标<span style='color:red;'>系统</span> - <span style='color:red;'>设计</span>方法 - 软件工程 - 软件<span style='color:red;'>设计</span> - <span style='color:red;'>架构</span><span style='color:red;'>设计</span> - 全程<span style='color:red;'>概述</span>](https://img-blog.csdnimg.cn/direct/03b31a234d9747889425d2ad2899d09a.png)


























![[算法题]组队竞赛](https://i-blog.csdnimg.cn/direct/933b5db42d204e6b85487c4a77024687.png)



![[HTML]一文掌握](https://img-blog.csdnimg.cn/img_convert/ed5a84e10a127c45489ce18c57dc7da0.png)