在实际使用过程中,使用python速度不够快,并且不太好嵌入到c++程序中,因此可以把pytorch训练的模型转成onnx模型,然后使用opencv进行调用。
所需要用到的库有:
opencv
1.完整的程序如下
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import numpy as np
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import LambdaLR
import os
import re
from PIL import Image
cur_pwd_path = os.getcwd()
def getBestModuleFilename(browser):
file_name = browser #"tf_logs/save_module"
filenames = os.listdir(file_name)
pattern = r"d+"
result = []
for i in range(len(filenames)):
rst = int(filenames[i][10:-4])
result.append(rst)
val = max(result)
index = result.index(val)
file_best = filenames[index]
print(file_best)
return file_best
tensor = torch.randn(3,3)
bTensor = type(tensor) == torch.Tensor
print(bTensor)
print("tensor is on ", tensor.device)
#数据转到GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
if torch.cuda.is_available():
tensor = tensor.to(device)
print("tensor is on ",tensor.device)
#数据转到CPU
if tensor.device == 'cuda:0':
tensor = tensor.to(torch.device("cpu"))
print("tensor is on", tensor.device)
if tensor.device == "cpu":
tensor = tensor.to(torch.device("cuda:0"))
print("tensor is on", tensor.device)
trainning_data = datasets.MNIST(root="data",train=True,transform=ToTensor(),download=True)
print(len(trainning_data))
test_data = datasets.MNIST(root="data",train=True,transform=ToTensor(),download=False)
train_loader = DataLoader(trainning_data, batch_size=64,shuffle=True)
test_loader = DataLoader(test_data, batch_size=64,shuffle=True)
print(len(train_loader)) #分成了多少个batch
print(len(trainning_data)) #总共多少个图像
# for x, y in train_loader:
# print(x.shape)
# print(y.shape)
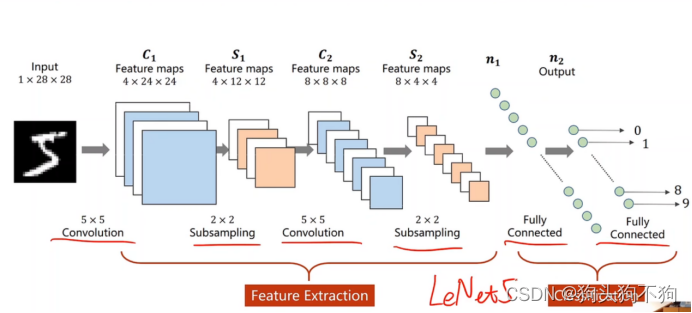
class MinistNet(nn.Module):
def __init__(self):
super().__init__()
# self.flat = nn.Flatten()
self.conv1 = nn.Conv2d(1,1,3,1,1)
self.hideLayer1 = nn.Linear(28*28,256)
self.hideLayer2 = nn.Linear(256,10)
def forward(self,x):
x= self.conv1(x)
x = x.view(-1,28*28)
x = self.hideLayer1(x)
x = torch.sigmoid(x)
x = self.hideLayer2(x)
# x = nn.Sigmoid(x)
return x
model_path = "E:\\TOOLE\\slam_evo\\pythonProject\\tf_logs\\save_module\\ckpt_best_10.pth"
img_path = "E:\\TOOLE\\slam_evo\\pythonProject\\2.jpg"
img = Image.open(img_path)
test_model = MinistNet()
test_model1 = torch.load(model_path)
test_model.load_state_dict(test_model1["net"])
test_model.eval()
test_model.to("cuda")
transform =torchvision.transforms.Compose([
torchvision.transforms.Grayscale(),
torchvision.transforms.ToTensor()
])
img = transform(img)
img = torch.unsqueeze(img, 0)
img = img.to("cuda")
result = test_model(img)
result = result.to("cpu")
val,index = torch.max(result,dim=1)
print(index)
model = MinistNet()
model = model.to(device)
cuda = next(model.parameters()).device
print(model)
criterion = nn.CrossEntropyLoss()
optimer = torch.optim.RMSprop(model.parameters(),lr= 0.001)
scheduler_1 = LambdaLR(optimer, lr_lambda=lambda epoch: 1/(epoch+1))
num_epoches =10
min_loss_val = 100000
Resume = False
def train():
global min_loss_val
start_epoch = -1
if Resume == False:
start_epoch = 0
else:
#找到数字最大的pth文件
path_checkpoint = r'tf_logs/'+"save_module"
best_path_checkpoint = getBestModuleFilename(path_checkpoint)
if(best_path_checkpoint == ""):
return
else:
checkpointResume = torch.load(path_checkpoint)
start_epoch = checkpointResume["epoch"]
model.load_state_dict(checkpointResume["net"])
optimer.load_state_dict(checkpointResume["optimizer"])
scheduler_1.load_state_dict(checkpointResume["lr_schedule"])
train_losses = []
train_acces = []
eval_losses = []
eval_acces = []
#训练
model.train()
tensorboard_ind =0;
for epoch in range(num_epoches):
batchsizeNum = 0
train_loss = 0
train_acc = 0
train_correct = 0
for x,y in train_loader:
# print(epoch)
# print(x.shape)
# print(y.shape)
x = x.to('cuda')
y = y.to('cuda')
bte = type(x)==torch.Tensor
bte1 = type(y)==torch.Tensor
A = x.device
B = y.device
pred_y = model(x)
loss = criterion(pred_y,y)
optimer.zero_grad()
loss.backward()
optimer.step()
loss_val = loss.item()
batchsizeNum = batchsizeNum +1
train_acc += (pred_y.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
tensorboard_ind += 1
train_losses.append(train_loss / len(trainning_data))
train_acces.append(train_acc / len(trainning_data))
#测试
test_loss_value = 0
model.eval()
with torch.no_grad():
num_batch = len(test_data)
numSize = len(test_data)
test_loss, test_correct = 0,0
for x,y in test_loader:
x = x.to(device)
y = y.to(device)
pred_y = model(x)
test_loss += criterion(pred_y, y).item()
test_correct += (pred_y.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batch
test_correct /= numSize
eval_losses.append(test_loss)
eval_acces.append(test_correct)
test_loss_value = test_loss
print("test result:",100 * test_correct,"% avg loss:",test_loss)
scheduler_1.step()
#设置checkpoint
if epoch > int(num_epoches/3) and test_loss_value < min_loss_val:
min_loss_val = test_loss_value
checkpoint = {"epoch": epoch,
"net": model.state_dict(),
"optimizer":optimer.state_dict(),
"lr_schedule":scheduler_1.state_dict()}
if not os.path.isdir(r'tf_logs/' + "save_module"):
os.makedirs("tf_logs/" + "save_module")
PATH = r'tf_logs/'+"save_module" + "/ckpt_best_%s.pth"%(str(epoch+1))
torch.save(checkpoint, PATH)
def test_singleFrame():
model_path = "E:\\TOOLE\\slam_evo\\pythonProject\\tf_logs\\save_module\\ckpt_best_10.pth"
img_path = "E:\\TOOLE\\slam_evo\\pythonProject\\1.jpg"
img =Image.open(img_path)
test_model = MinistNet()
test_model = torch.load(model_path)
test_model.to("cuda")
transform=ToTensor()
img = transform(img)
img.to("cuda")
result = test_model(img)
val, index = torch.max(result)
print(index)
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
train()
#保存onnx
model.cpu()
model.eval()
x= torch.randn(1,1,28,28)
torch.onnx.export(model,x,"model.onnx")
2.训练并保存模型
if epoch > int(num_epoches/3) and test_loss_value < min_loss_val:
min_loss_val = test_loss_value
checkpoint = {"epoch": epoch,
"net": model.state_dict(),
"optimizer":optimer.state_dict(),
"lr_schedule":scheduler_1.state_dict()}
if not os.path.isdir(r'tf_logs/' + "save_module"):
os.makedirs("tf_logs/" + "save_module")
PATH = r'tf_logs/'+"save_module" + "/ckpt_best_%s.pth"%(str(epoch+1))
torch.save(checkpoint, PATH)3.加载并测试模型
model_path = "E:\\TOOLE\\slam_evo\\pythonProject\\tf_logs\\save_module\\ckpt_best_10.pth"
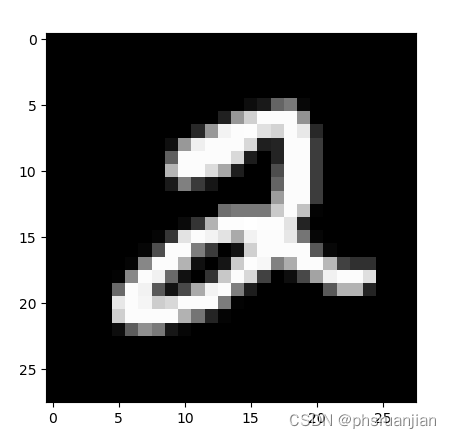
img_path = "E:\\TOOLE\\slam_evo\\pythonProject\\2.jpg"
img = Image.open(img_path)
test_model = MinistNet()
test_model1 = torch.load(model_path)
test_model.load_state_dict(test_model1["net"])
test_model.eval()
test_model.to("cuda")
transform =torchvision.transforms.Compose([
torchvision.transforms.Grayscale(),
torchvision.transforms.ToTensor()
])
img = transform(img)
img = torch.unsqueeze(img, 0)
img = img.to("cuda")
result = test_model(img)
result = result.to("cpu")
val,index = torch.max(result,dim=1)
print(index)结果如下:


按照第0,1来数数,tensor([1])刚好就是2.
4.保存onnx模型
if __name__ == '__main__':
train()
#保存onnx
model.cpu()
model.eval()
x= torch.randn(1,1,28,28)
torch.onnx.export(model,x,"model.onnx")5.使用C++加opencv实现minist手写数字的识别
// test_onnm.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include<ostream>
#include<opencv2/opencv.hpp>
#include<opencv2/dnn.hpp>
#include <iostream>
using namespace std;
using namespace cv;
using namespace dnn;
int main()
{
std::cout << "Hello World!\n";
//cv::dnn::Net net = cv::dnn::readTensorFromONNX();
cv::dnn::Net net = cv::dnn::readNetFromONNX("E:\\TOOLE\\slam_evo\\pythonProject\\model.onnx");
if (net.empty())
{
std::cout << "加载onnx模型失败" << std::endl;
return -1;
}
net.setPreferableBackend(DNN_BACKEND_OPENCV);
net.setPreferableTarget(DNN_TARGET_CPU);
cv::Mat img = cv::imread("E:\\TOOLE\\slam_evo\\pythonProject\\1.jpg",cv::IMREAD_GRAYSCALE);
if(img.cols != 28 || img.rows != 28)
{
return -1;
}
cv::Mat blob;
float scaleFactor = 1 / 255.0;
blobFromImage(img, blob, scaleFactor, Size(), Scalar(), true, false, CV_32F);
net.setInput(blob);
cv::Mat predict = net.forward();
for (int i = 0; i < predict.total(); i++)
{
std::cout << predict.at<float>(i) << " ";
}
std::cout << std::endl;
double minVal, maxVal;
Point minLoc, maxLoc;
// 查找最大值和最小值及其位置
minMaxLoc(predict, &minVal, &maxVal, &minLoc, &maxLoc);
cout << maxVal << " " << maxLoc.x<<" "<< maxLoc.y << "\n";
return 0;
}
结果展示: