Sampling for stable diffusion
笔记来源:
1.pytorch-stable-diffusion
2.Denoising Diffusion Probabilistic Models | DDPM Explained
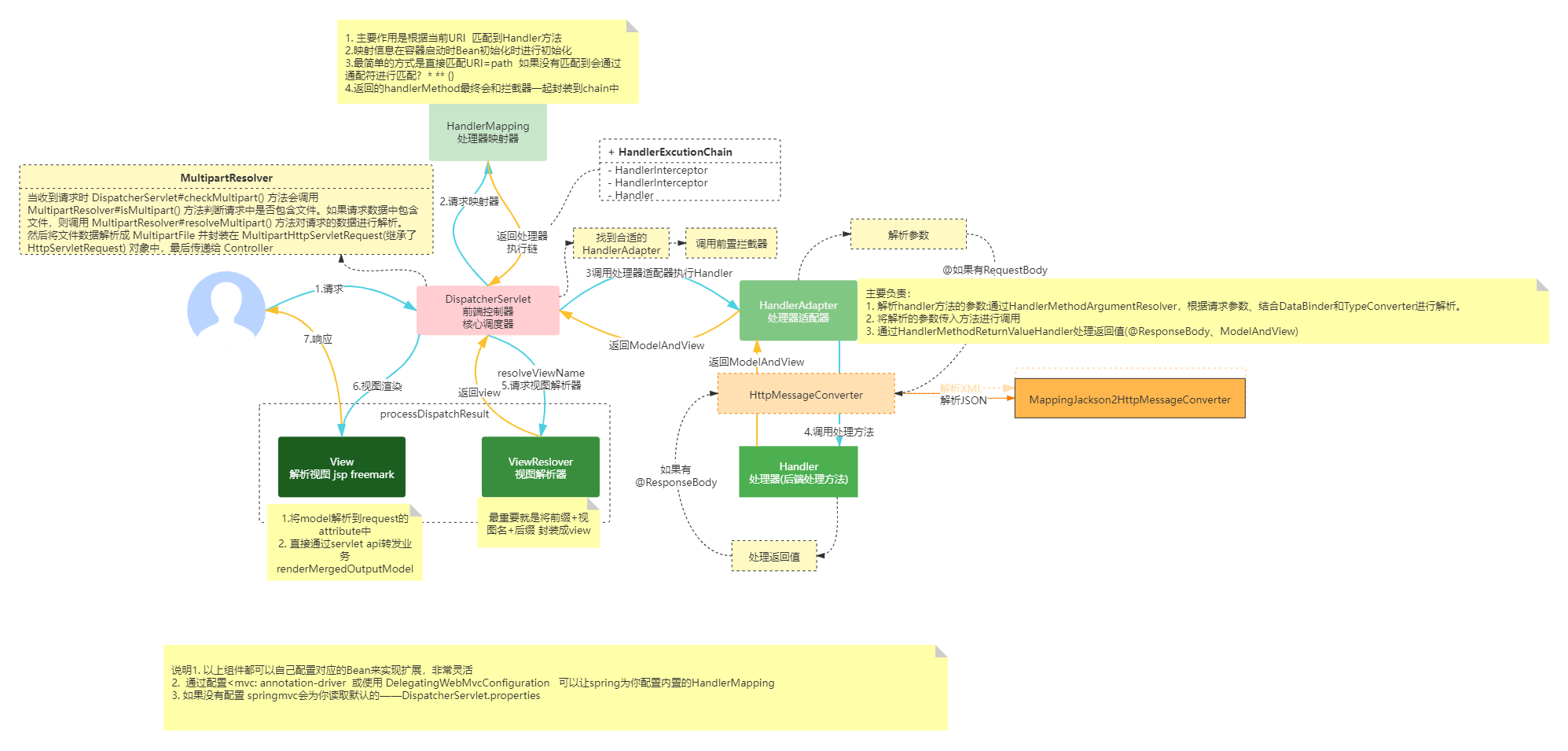
stable diffusion 训练过程(上半部分)和采样过程(下半部分)

Sampling(Reverse)过程



上述第四行公式,其实笔者在DDPM(Denoising Diffusion Probabilistic Models)和 Training for Stable Diffusion 博客中已有涉及,我们这里不再推导

为什么我们无法直接计算 transition probability q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt) 得到前一张图像 x t − 1 x_{t-1} xt−1,而是需要用Unet网络 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) pθ(xt−1∣xt) 去估计 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt)?
我们不能计算它是因为那需要计算涉及到整个数据的分布,但是我们可以用一个分布 p θ p_{\theta} pθ 来近似它,它被表述为高斯分布它的均值和方差

(1) Iterative Denoising Process
Forward Diffusion: In the forward process of a diffusion model, noise is gradually added to an image over multiple steps until it becomes almost pure noise. Each step introduces a small amount of noise, which is a straightforward application of a Markov process since the next state depends only on the current state.
Reverse Diffusion: The reverse process aims to gradually remove noise from the noisy image, transforming it back into a clean image. This reverse process requires knowledge of the entire noise addition process, not just the current noisy state.
(2) Complex Dependencies
The reverse diffusion process must account for the cumulative noise addition across all steps in the forward process. This introduces dependencies on previous states that a forward Markov process cannot capture because it only considers the present state.
(3) Non-Markovian Nature of Reverse Process
While the forward diffusion process can be described as a Markov process (since each state depends only on the previous state), the reverse diffusion process is inherently non-Markovian. The reverse process must infer and correct the noise introduced at each step, requiring information from multiple past states to accurately denoise the image.
(4) Learned Denoising Distribution
Stable diffusion models use a neural network to learn the denoising distribution, i.e., how to reverse the noise addition. This neural network is trained to predict and remove noise iteratively, taking into account the cumulative effect of all previous denoising steps. A simple forward Markov process does not have the capability to model such complex, learned transformations.
(5) Non-Linear Transformations
The process of denoising involves non-linear transformations that are highly complex and dependent on the input data. Forward Markov processes typically assume linear or simple transitions, which are insufficient for capturing the intricate non-linearities involved in image denoising.
上述内容由gpt生成,其实在看完上述内容后笔者仍然没怎么理解,但经过询问师兄,笔者得到了一些理解,以此写下这个通俗理解:Forward Markov 由 x 0 x_0 x0 到 x t x_{t} xt 的过程,其实 x t x_t xt 的状态是依赖前面 t − 1 t-1 t−1 个 x x x 的状态(或者通俗理解为融合了前面 t − 1 t-1 t−1 个 x x x 的状态),如果你现在做 Reverse Markov 由 x t x_t xt 到 x t − 1 x_{t-1} xt−1 (融合了前面 t − 1 t-1 t−1 个 x x x 的状态)你必须要知道前面 t − 1 t-1 t−1 个 x x x 的情况,才能推导出 x t − 1 x_{t-1} xt−1 也就是说 Reverse Markov 不能够一步一步向前推导


鉴于笔者写此博客时,自己训练的SD模型还未训练完成,故这里使用预训练模型v1-5-pruned-emaonly.ckpt
pipeline.py
import torch
import numpy as np
from tqdm import tqdm
from ddpm import DDPMSampler
WIDTH = 512
HEIGHT = 512
LATENTS_WIDTH = WIDTH // 8
LATENTS_HEIGHT = HEIGHT // 8
def generate(
prompt,
uncond_prompt=None,
input_image=None,
strength=0.8,
do_cfg=True,
cfg_scale=7.5,
sampler_name="ddpm",
n_inference_steps=50,
models={},
seed=None,
device=None,
idle_device=None,
tokenizer=None,
):
with torch.no_grad():
if not 0 < strength <= 1:
raise ValueError("strength must be between 0 and 1")
if idle_device:
to_idle = lambda x: x.to(idle_device)
else:
to_idle = lambda x: x
# Initialize random number generator according to the seed specified
generator = torch.Generator(device=device)
if seed is None:
generator.seed()
else:
generator.manual_seed(seed)
clip = models["clip"]
clip.to(device)
if do_cfg:
# Convert into a list of length Seq_Len=77
cond_tokens = tokenizer.batch_encode_plus(
[prompt], padding="max_length", max_length=77
).input_ids
# (Batch_Size, Seq_Len)
cond_tokens = torch.tensor(cond_tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
cond_context = clip(cond_tokens)
# Convert into a list of length Seq_Len=77
uncond_tokens = tokenizer.batch_encode_plus(
[uncond_prompt], padding="max_length", max_length=77
).input_ids
# (Batch_Size, Seq_Len)
uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
uncond_context = clip(uncond_tokens)
# (Batch_Size, Seq_Len, Dim) + (Batch_Size, Seq_Len, Dim) -> (2 * Batch_Size, Seq_Len, Dim)
context = torch.cat([cond_context, uncond_context])
else:
# Convert into a list of length Seq_Len=77
tokens = tokenizer.batch_encode_plus(
[prompt], padding="max_length", max_length=77
).input_ids
# (Batch_Size, Seq_Len)
tokens = torch.tensor(tokens, dtype=torch.long, device=device)
# (Batch_Size, Seq_Len) -> (Batch_Size, Seq_Len, Dim)
context = clip(tokens)
to_idle(clip)
if sampler_name == "ddpm":
sampler = DDPMSampler(generator)
sampler.set_inference_timesteps(n_inference_steps)
else:
raise ValueError("Unknown sampler value %s. ")
latents_shape = (1, 4, LATENTS_HEIGHT, LATENTS_WIDTH)
if input_image:
encoder = models["encoder"]
encoder.to(device)
input_image_tensor = input_image.resize((WIDTH, HEIGHT))
# (Height, Width, Channel)
input_image_tensor = np.array(input_image_tensor)
# (Height, Width, Channel) -> (Height, Width, Channel)
input_image_tensor = torch.tensor(input_image_tensor, dtype=torch.float32, device=device)
# (Height, Width, Channel) -> (Height, Width, Channel)
input_image_tensor = rescale(input_image_tensor, (0, 255), (-1, 1))
# (Height, Width, Channel) -> (Batch_Size, Height, Width, Channel)
input_image_tensor = input_image_tensor.unsqueeze(0)
# (Batch_Size, Height, Width, Channel) -> (Batch_Size, Channel, Height, Width)
input_image_tensor = input_image_tensor.permute(0, 3, 1, 2)
# (Batch_Size, 4, Latents_Height, Latents_Width)
encoder_noise = torch.randn(latents_shape, generator=generator, device=device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = encoder(input_image_tensor, encoder_noise)
# Add noise to the latents (the encoded input image)
# (Batch_Size, 4, Latents_Height, Latents_Width)
sampler.set_strength(strength=strength)
latents = sampler.add_noise(latents, sampler.timesteps[0])
to_idle(encoder)
else:
# (Batch_Size, 4, Latents_Height, Latents_Width)
latents = torch.randn(latents_shape, generator=generator, device=device)
diffusion = models["diffusion"]
diffusion.to(device)
# tqdm is used to provide a progress bar for visual feedback during the iteration over timesteps.
# This is helpful for monitoring the progress of long-running loops.
timesteps = tqdm(sampler.timesteps)
for i, timestep in enumerate(timesteps):
# (1, 320)
time_embedding = get_time_embedding(timestep).to(device)
# (Batch_Size, 4, Latents_Height, Latents_Width)
model_input = latents
if do_cfg:
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (2 * Batch_Size, 4, Latents_Height, Latents_Width)
model_input = model_input.repeat(2, 1, 1, 1)
# model_output is the predicted noise
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width)
model_output = diffusion(model_input, context, time_embedding)
if do_cfg:
output_cond, output_uncond = model_output.chunk(2)
model_output = cfg_scale * (output_cond - output_uncond) + output_uncond
# (Batch_Size, 4, Latents_Height, Latents_Width) -> (Batch_Size, 4, Latents_Height, Latents_Width)
latents = sampler.step(timestep, latents, model_output)
to_idle(diffusion)
decoder = models["decoder"]
decoder.to(device)
# (Batch_Size, 4, Latents_Height, Latent_Width) -> (Batch_Size, 3, Height, Width)
images = decoder(latents)
to_idle(decoder)
images = rescale(images, (-1, 1), (0, 255), clamp=True)
# (Batch_Size, Channel, Height, Width) -> (Batch_Size, Height, Width, Channel)
images = images.permute(0, 2, 3, 1)
images = images.to("cpu", torch.uint8).numpy()
return images[0]
def rescale(x, old_range, new_range, clamp=False):
old_min, old_max = old_range
new_min, new_max = new_range
x = x.clone()
x -= old_min
x *= (new_max - new_min) / (old_max - old_min)
x += new_min
if clamp:
x = x.clamp(new_min, new_max)
return x
# time -> time_embedding
def get_time_embedding(timestep):
# Shape: (160,)
freqs = torch.pow(10000, -torch.arange(start=0, end=160, dtype=torch.float32) / 160)
# Shape: (1, 160)
x = torch.tensor([timestep], dtype=torch.float32)[:, None] * freqs[None]
# Shape: (1, 160 * 2)
return torch.cat([torch.cos(x), torch.sin(x)], dim=-1)
generate.py
import model_loader
import pipeline
from PIL import Image
from transformers import CLIPTokenizer
import torch
import matplotlib.pyplot as plt
DEVICE = "cpu"
ALLOW_CUDA = False
ALLOW_MPS = False
if torch.cuda.is_available() and ALLOW_CUDA:
DEVICE = "cuda"
elif (torch.has_mps or torch.backends.mps.is_available()) and ALLOW_MPS:
DEVICE = "mps"
print(f"Using device: {DEVICE}")
vocab_path = "~/Documents/PycharmProjects/pytorch-stable-diffusion/sd/data/tokenizer_vocab.json"
merges_path = "~/Documents/PycharmProjects/pytorch-stable-diffusion/sd/data/tokenizer_merges.txt"
model_path = "~/Documents/PycharmProjects/pytorch-stable-diffusion/sd/data/v1-5-pruned-emaonly.ckpt"
tokenizer = CLIPTokenizer(vocab_path, merges_file=merges_path)
model_file = model_path
models = model_loader.preload_models_from_standard_weights(model_file, DEVICE)
## TEXT TO IMAGE
# prompt = "A dog with sunglasses, wearing comfy hat, looking at camera, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution."
prompt = "A cat stretching on the floor, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution."
uncond_prompt = "" # Also known as negative prompt
do_cfg = True
cfg_scale = 8 # min: 1, max: 14
## IMAGE TO IMAGE
input_image = None
# Comment to disable image to image
# image_path = "../images/dog.jpg"
# input_image = Image.open(image_path)
# Higher values means more noise will be added to the input image, so the result will further from the input image.
# Lower values means less noise is added to the input image, so output will be closer to the input image.
strength = 0.9
## SAMPLER
sampler = "ddpm"
num_inference_steps = 50
seed = 42
output_image = pipeline.generate(
prompt=prompt,
uncond_prompt=uncond_prompt,
input_image=input_image,
strength=strength,
do_cfg=do_cfg,
cfg_scale=cfg_scale,
sampler_name=sampler,
n_inference_steps=num_inference_steps,
seed=seed,
models=models,
device=DEVICE,
idle_device="cpu",
tokenizer=tokenizer,
)
# Combine the input image and the output image into a single image.
img = Image.fromarray(output_image)
plt.imshow(img)
plt.axis('off')
plt.title(prompt, fontdict=None, loc="center",fontsize=12)
plt.show()
prompt 为 “A cat stretching on the floor, highly detailed, ultra sharp, cinematic, 100mm lens, 8k resolution.”
输出的结果为: