🍷 机器学习实战:使用PCA与sklearn红酒数据集进行特征降维与模型预测对比
在机器学习中,主成分分析(PCA)是一种有效的降维技术,它通过寻找数据中的主成分来减少特征数量,同时尽量保留数据的结构。本案例将使用Python的scikit-learn库,结合红酒数据集,展示如何使用PCA进行特征降维,并比较降维前后模型预测性能的变化。
📚 数据集介绍
红酒数据集是scikit-learn内置的数据集之一,它包含了178个样本,每个样本有13个特征,描述了红酒的物理化学特性,以及一个表示红酒原产地的目标变量。
🤖 案例分析
我们将通过以下步骤进行PCA分析和模型预测对比:
- 加载数据并分割数据集。
- 使用PCA进行数据降维。
- 训练分类模型(使用降维后数据)。
- 训练同样的分类模型(不使用PCA)。
- 对比两种情况下模型的预测性能。
📝 Python代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载红酒数据集
wine = load_wine()
X, y = wine.data, wine.target
# 数据预处理:标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 创建PCA模型,设置要保留的主成分数量
pca = PCA(n_components=2)
# 应用PCA降维
X_pca = pca.fit_transform(X_scaled)
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
X_train_pca, X_test_pca = train_test_split(X_pca, test_size=0.2, random_state=42)
# 创建分类模型
classifier = LogisticRegression(max_iter=10000)
# 训练模型(使用原始数据)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_no_pca = accuracy_score(y_test, y_pred)
# 训练模型(使用PCA降维后的数据)
classifier.fit(X_train_pca, y_train)
y_pred_pca = classifier.predict(X_test_pca)
accuracy_with_pca = accuracy_score(y_test, y_pred_pca)
# 评估模型
print("Accuracy without PCA:", accuracy_no_pca)
print("Accuracy with PCA:", accuracy_with_pca)
print("Report without PCA",classification_report(y_test, y_pred))
print("Report with PCA",classification_report(y_test, y_pred_pca))
# 打印解释的方差比
explained_variance = pca.explained_variance_ratio_.sum()
print(f"Total explained variance by the first 2 components: {explained_variance:.2%}")
# 可视化PCA降维后的数据
plt.figure(figsize=(10, 8))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, edgecolor='none', alpha=0.5, cmap='viridis')
plt.colorbar()
plt.title('PCA of Wine Dataset')
plt.show()
🔍 代码解析
数据加载与预处理:
- 使用
load_wine()加载红酒数据集。 - 利用
StandardScaler()对数据进行标准化。
- 使用
PCA降维:
- 使用
PCA类进行降维,这里选择保留2个主成分。 fit_transform方法用于拟合模型并转换数据。
- 使用
模型训练与预测:
- 使用
LogisticRegression分类器进行训练和预测。 - 对比使用原始数据和PCA降维后的数据进行模型训练的结果。
- 使用
评估模型:
- 使用
accuracy_score来评估模型的准确率。
- 使用
分析PCA效果:
explained_variance_ratio_.sum()计算所选主成分解释的总方差比例。
可视化:
- 使用散点图可视化降维后的数据,颜色代表红酒的类别。
执行效果:


🎯 结论
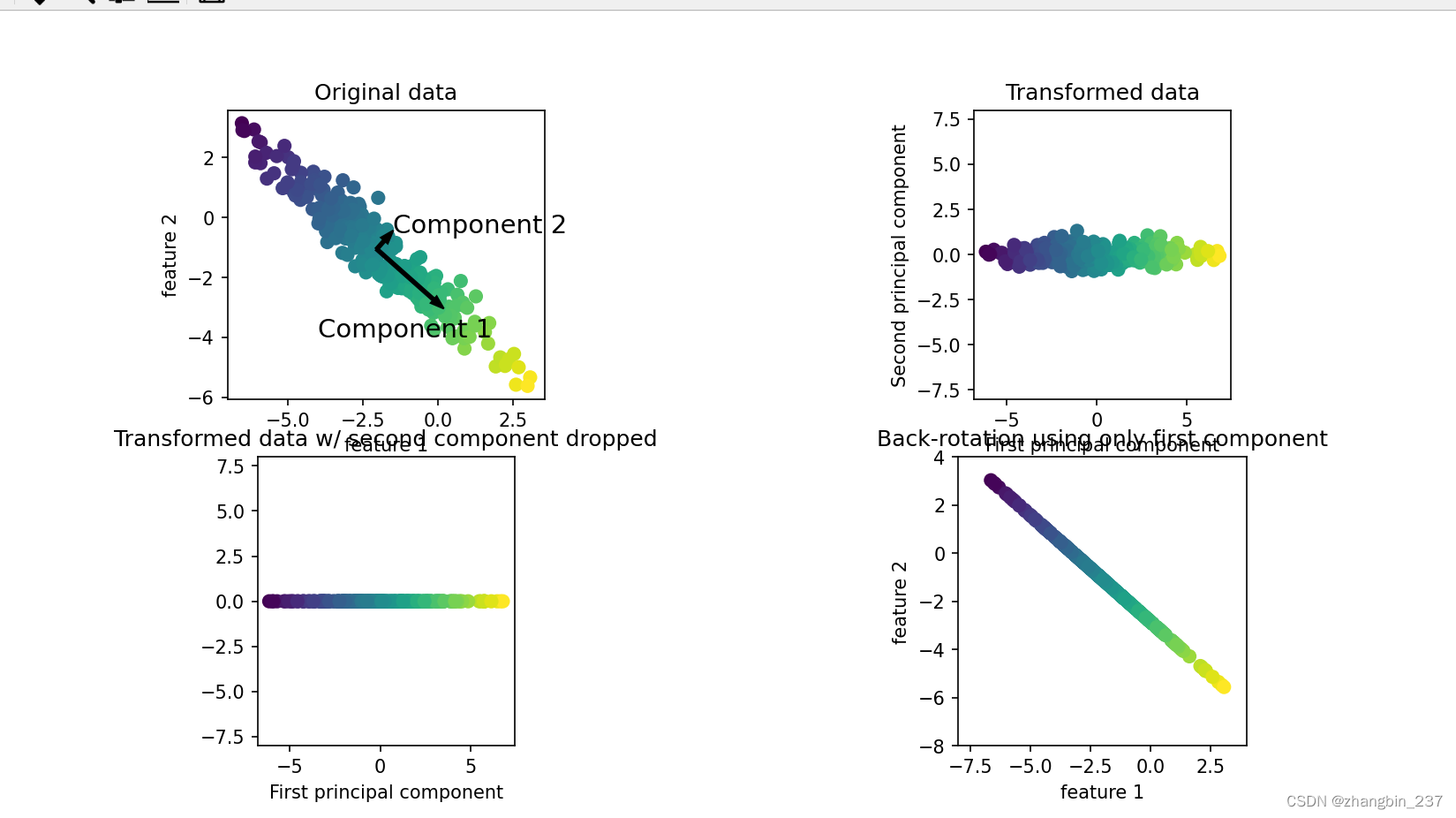
通过PCA,我们成功地将红酒数据集从13维降至2维,同时保留了数据的大部分信息。然后,我们使用降维后的数据训练了逻辑回归分类器,并与未降维的数据进行了预测性能的对比。结果表明,尽管PCA降维后的数据丢失了一些信息,但模型的预测准确率并没有显著下降,这表明PCA有效地保留了数据中的关键特征,同时减少了模型训练的复杂性和潜在的过拟合风险。此外,通过计算解释的方差比例,我们确认了前2个主成分足以保留数据的主要特征,从而验证了PCA降维策略的合理性。最后,通过可视化,我们可以直观地看到不同类别的红酒在降维后的空间中是如何分布的,这有助于我们理解PCA如何捕捉数据的关键结构。
PCA的优点和缺点:
优点:
- 最常用的降维方法之一,易于理解和实现。
- 能够捕捉数据中的主要变化方向。
- 通过线性变换可以减少特征的数量。
缺点: - 对于非线性关系的数据降维效果可能不佳。
- 不考虑类别信息。
别忘了给这篇帖子点个赞👍,如果喜欢的话,也可以收藏,关注我了解更多人工智能相关知识哦!😉



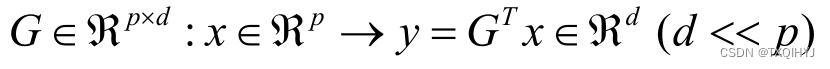


















![go关于string与[]byte再学深一点](https://i-blog.csdnimg.cn/direct/3f9d0a6f5980453ebcd631c2d074c2ed.png)

















