三、Spark 和 Kafka 整合
Spark天然支持集成Kafka, 基于Spark读取Kafka中的数据, 同时可以实施精准一次(仅且只会处理一次)的语义, 作为程序员, 仅需要关心如何处理消息数据即可, 结构化流会将数据读取过来, 转换为一个DataFrame的对象, DataFrame就是一个无界的DataFrame, 是一个无限增大的表
1、整合Kafka准备工作
说明: Jar包上传的位置说明
如何放置相关的Jar包? 1- 放置位置一: 当spark-submit提交的运行环境为Spark集群环境的时候,以及运行模式为local, 默认从 spark的jars目录下加载相关的jar包, 目录位置: /export/server/spark/jars 2- 放置位置二: 当我们使用pycharm运行代码的时候, 基于python的环境来运行的, 需要在python的环境中可以加载到此jar包 目录位置: /root/anaconda3/lib/python3.8/site-packages/pyspark/jars/ 3- 放置位置三: 当我们提交选择的on yarn模式 需要保证此jar包在HDFS上对应目录下 hdfs的spark的jars目录下: hdfs://node1:8020/spark/jars 请注意: 以上三个位置, 主要是用于放置一些 spark可能会经常使用的jar包, 对于一些不经常使用的jar包, 在后续spark-submit 提交运行的时候, 会有专门的处理方案: spark-submit --jars jar包路径 jar包下载地址: https://mvnrepository.com/
2、从kafka中读取数据
spark和kafka集成官网文档:
2.1 流式处理
官方示例:
# 订阅Kafka的一个Topic,从最新的消息数据开始消费
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 订阅Kafka的多个Topic,多个Topic间使用英文逗号进行分隔。从最新的消息数据开始消费
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1,topic2") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 订阅一个Topic,并且指定header信息
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.option("includeHeaders", "true") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "headers")
# 订阅符合规则的Topic,从最新的数据开始消费
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribePattern", "topic.*") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
练习示例
对接kafka后,返回的结果数据内容:
key: 发送数据的key值。如果没有,就为null value: 最重要的字段。发送数据的value值,也就是消息内容。如果没有,就为null topic: 表示消息是从哪个Topic中消费出来 partition: 分区编号。表示消费到的该条数据来源于Topic的哪个分区 offset: 表示消息偏移量 timestamp: 接收的时间戳 timestampType: 时间戳类型(无意义)类型的说明:
列名 类型 key binary value binary topic string partition int offset long timestamp timestamp timestampType int headers (optional) array
从某一个Topic中读取消息数据
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.config("spark.sql.shuffle.partitions",1)\
.appName('ss_read_kafka_1_topic')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
# 默认从最新的地方开始消费
df = spark.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers","node1:9092")\
.option("subscribe","itheima")\
.load()
# 查看类型
print(type(df))
# 注意: 字符串需要解码!!!
etl_df = df.select(
F.expr("cast(key as string) as key"),
F.decode(df.key,'utf8'),
F.expr("cast(value as string) as value"),
F.decode(df.value, 'utf8'),
df.topic,
df.partition,
df.offset
)
# 获取数据
etl_df.writeStream.format("console").outputMode("append").start().awaitTermination()
# 3- 数据处理
# result_df1 = init_df.select(F.expr("cast(value as string) as value"))
# # selectExpr = select + F.expr
# result_df2 = init_df.selectExpr("cast(value as string) as value")
# result_df3 = init_df.withColumn("value",F.expr("cast(value as string)"))
# 4- 数据输出
# 5- 启动流式任务
"""
如果有多个输出,那么只能在最后一个start的后面写awaitTermination()
"""
# result_df1.writeStream.queryName("result_df1").format("console").outputMode("append").start()
# result_df2.writeStream.queryName("result_df2").format("console").outputMode("append").start()
# result_df3.writeStream.queryName("result_df3").format("console").outputMode("append").start().awaitTermination()
2.2 批处理
官方示例:
# 订阅一个Topic主题, 默认从最早到最晚的偏移量范围
df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 批处理订阅Kafka的多个Topic数据。并且可以通过startingOffsets和endingOffsets指定要消费的消息偏移
# 量(offset)范围。"topic1":{"0":23,"1":-2} 含义是:topic1,"0":23从分区编号为0的分区的
# offset=23地方开始消费,"1":-2 从分区编号为1的分区的最开始的地方开始消费
df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1,topic2") \
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""") \
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 通过正则匹配多个Topic, 默认从最早到最晚的偏移量范围
df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribePattern", "topic.*") \
.option("startingOffsets", "earliest") \
.option("endingOffsets", "latest") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
演示示例
参数说明:
选项 值 说明 assign 通过一个Json 字符串的方式来表示: {"topicA":[0,1],"topicB":[2,4]} 设置使用特定的TopicPartitions subscribe 以逗号分隔的Topic主题列表 要订阅的主题列表 subscribePattern 正则表达式字符串 订阅匹配符合条件的Topic。assign、subscribe、subscribePattern任意指定一个。 kafka.bootstrap.servers 以英文逗号分隔的host:port列表 指定kafka服务的地址
订阅一个Topic
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.config("spark.sql.shuffle.partitions",1)\
.appName('sparksql_read_kafka_1_topic')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
# 默认从Topic开头一直消费到结尾
df = spark.read\
.format("kafka")\
.option("kafka.bootstrap.servers","node1.itcast.cn:9092,node2.itcast.cn:9092")\
.option("subscribe","itheima")\
.load()
# 查看类型
print(type(df))
# 注意: 字符串需要解码!!!
etl_df = df.select(
F.expr("cast(key as string) as key"),
F.decode(df.key,'utf8'),
F.expr("cast(value as string) as value"),
F.decode(df.value, 'utf8'),
df.topic,
df.partition,
df.offset
)
# 获取数据
etl_df.show()
# # 3- 数据处理
# result_df1 = init_df.select(F.expr("cast(value as string) as value"))
# # selectExpr = select + F.expr
# result_df2 = init_df.selectExpr("cast(value as string) as value")
# result_df3 = init_df.withColumn("value",F.expr("cast(value as string)"))
# # 4- 数据输出
# print("result_df1")
# result_df1.show()
# print("result_df2")
# result_df2.show()
# print("result_df3")
# result_df3.show()
# # 5- 释放资源
# spark.stop()
3、数据写入Kafka中
3.1 流式处理
官方示例:
# 将Key和Value的数据都写入到Kafka当中
ds = df \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.start()
# 将Key和Value的数据都写入到Kafka当中。使用DataFrame数据中的Topic字段来指定要将数据写入到Kafka集群
# 的哪个Topic中。这种方式适用于消费多个Topic的情况
ds = df \
.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.start()
练习示例
备注 Column 数据类型 可选字段 key string or binary 必填字段 value string or binary 可选字段 headers array 必填字段 topic string 可选字段 partition int
写出到指定Topic
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.config("spark.sql.shuffle.partitions",1)\
.appName('ss_read_kafka_1_topic')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
# 默认从最新的地方开始消费
init_df = spark.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers","node1:9092,node2:9092")\
.option("subscribe","itheima")\
.load()
# 3- 数据处理
result_df = init_df.select(
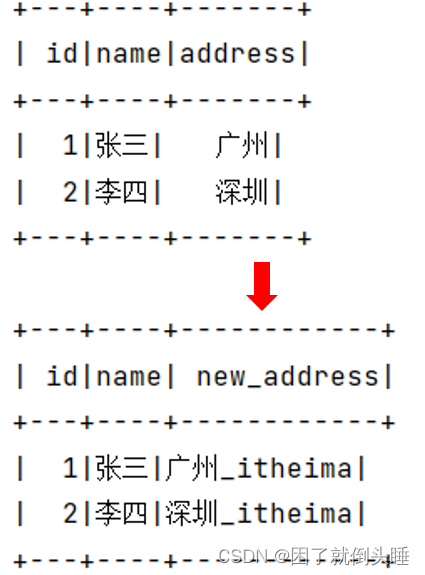
F.expr("concat(cast(value as string),'_itheima') as value")
)
# 4- 数据输出
# 注意: 咱们修改完直接保存到kafka的itcast主题中,所以控制台没有数据,这是正常的哦!!!
# 5- 启动流式任务
result_df.writeStream\
.format("kafka")\
.option("kafka.bootstrap.servers","node1:9092,node2:9092")\
.option("topic","itcast")\
.option("checkpointLocation", "hdfs://node1:8020/ck")\
.start()\
.awaitTermination()
3.2 批处理
官方示例:
# 从DataFrame中写入key-value数据到一个选项中指定的特定Kafka topic中
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.write \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.save()
# 使用数据中指定的主题将key-value数据从DataFrame写入Kafka
df.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") \
.write \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.save()
演示示例
备注 Column 数据类型 可选字段 key string or binary 必填字段 value string or binary 可选字段 headers array 必填字段 topic string 可选字段 partition int
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.config("spark.sql.shuffle.partitions",1)\
.appName('ss_read_kafka_1_topic')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
# 默认从最新的地方开始消费
init_df = spark.read\
.format("kafka")\
.option("kafka.bootstrap.servers","node1:9092,node2:9092")\
.option("subscribe","itheima")\
.load()
# 3- 数据处理
result_df = init_df.select(F.expr("concat(cast(value as string),'_666') as value"))
# 4- 数据输出
# 5- 启动流式任务
result_df.write.format("kafka")\
.option("kafka.bootstrap.servers","node1:9092,node2:9092")\
.option("topic","itcast")\
.option("checkpointLocation", "hdfs://node1:8020/ck")\
.save()