1、软件安装
搭建Kafka集群
1、下载安装
安装包下载地址:https://kafka.apache.org/download
2、将Kafka的安装包上传到虚拟机,并解压
cd /export/software/ tar -xzvf kafka_2.12-2.4.1.tgz -C ../server/ 配置软连接: cd /export/server ln -s kafka_2.12-2.4.1 kafka |
3、创建data目录
在kafka目录中创建data目录,用来存放数据 cd /export/server/kafka mkdir data |
4、修改 server.properties
cd /export/server/kafka/config vim server.properties # 指定broker的id broker.id=0 # 指定 kafka的绑定监听的地址 listeners=PLAINTEXT://node1.itcast.cn:9092 # 指定Kafka数据的位置 log.dirs=/export/server/kafka/data # 配置zk的三个节点 zookeeper.connect=node1.itcast.cn:2181,node2.itcast.cn:2181,node3.itcast.cn:2181 |
5、将安装好的kafka复制到另外两台服务器
cd /export/server scp -r kafka_2.12-2.4.1/ node2:$PWD scp -r kafka_2.12-2.4.1/ node3:$PWD 注意:要拷贝源文件夹,不要拷贝软连接 在 node2 和 node3 分别配置 软连接 cd /export/server ln -s kafka_2.12-2.4.1 kafka 修改另外两个节点的broker.id分别为1和2 cd /export/server/kafka/config vim server.properties ---------node2.itcast.cn-------------- cd /export/server/kafka/config vim server.properties broker.id=1 listeners=PLAINTEXT://node2.itcast.cn:9092 --------node3.itcast.cn-------------- cd /export/server/kafka/config vim server.properties broker.id=2 listeners=PLAINTEXT://node3.itcast.cn:9092 |
6、配置KAFKA_HOME环境变量
vim /etc/profile 内容如下: #KAFKA_HOME export KAFKA_HOME=/export/server/kafka export PATH=:$PATH:$KAFKA_HOME 加载环境变量 source /etc/profile 其他的两个节点也是一样的处理 |
7、启动服务
# 先启动ZooKeeper 在每个节点上执行如下命令: cd /export/server/zookeeper/bin ./zkServer.sh start # 再启动Kafka。要在每个节点上都执行如下命令: cd /export/server/kafka nohup bin/kafka-server-start.sh config/server.properties 2>&1 & |
8、测试Kafka集群是否启动成功
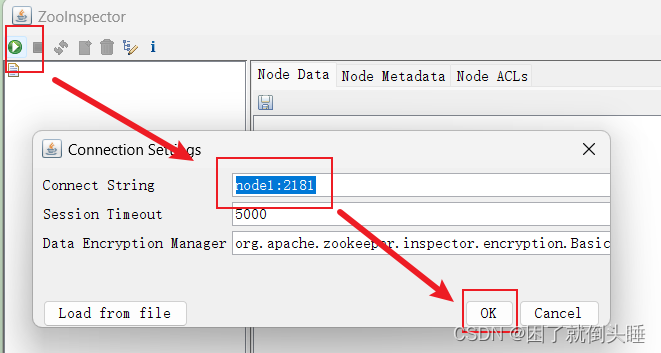
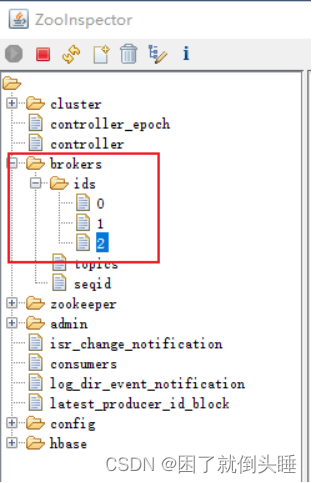
使用 jps 查看各个节点 是否出现有kafka 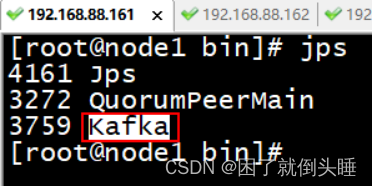 或者通过 zookeeper查看 brokers节点目录下, 是否有三个ids
|
2、安装易错点
1- 配置文件中监听地址前面的注释,记得打开。也就是删除最前面的#
2- 分发之后,记得要修改每个server.properties的 id 和 监听地址
3- 分发之后,记得source /etc/profile让环境变量生效
4- 没有启动zookeeper,或者仅仅启动了其中一台
5- 启动的时候server.properties中路径,不要写错了
3、配置Kafka的一键化启动
注意:使用一键化脚本,也得需要先启动zookeeper
(1)在 节点1 中创建 /export/onekey 目录
mkdir /export/onekey
(2)准备slave配置文件,用于保存要启动哪几个节点上的kafka
node1.itcast.cn node2.itcast.cn node3.itcast.cn |
(3) start-kafka.sh脚本内容
vim start-kafka.sh cat /export/onekey/slave | while read line do { echo $line ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & " }& wait done |
(4) stop-kafka.sh脚本内容
vim stop-kafka.sh cat /export/onekey/slave | while read line do { echo $line ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9" }& wait done |
(5) 给start-kafka.sh、stop-kafka.sh配置执行权限
chmod u+x start-kafka.sh chmod u+x stop-kafka.sh |
(6) 执行一键启动、一键关闭
./start-kafka.sh ./stop-kafka.sh |
4、启动服务
方式1: 正常启动
# 1.先在三台机器都输入以下命令,启动ZooKeeper /export/server/zookeeper/bin/zkServer.sh start # 2.再在三台集群上都输入以下命令,启动Kafka # 注意:下面是一条命令!!! nohup /export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties 2>&1 &
方式2: 使用kafka的onekey脚本
# 1.先在三台机器都输入以下命令,启动ZooKeeper /export/server/zookeeper/bin/zkServer.sh start # 2.只在node1上一键启动所有kafka服务 /export/onekey/start-kafka.sh