标题:“Python爬虫实战:地震数据的自动化抓取与分析”

摘要
在本文中,我们将深入探讨如何使用Python编写爬虫程序来自动化抓取地震数据,并进行简单的数据分析。通过实际案例,我们将学习爬虫的工作原理、常用库的使用,以及如何处理动态网页内容和反爬虫机制。
1. 爬虫简介与工作原理
爬虫,又称为网络爬虫或网页蜘蛛,是一种自动获取网页内容的程序。它按照一定的规则,自动访问互联网上的网页,获取所需信息。
工作原理简述:
- 发送请求:爬虫向目标网站发送HTTP请求。
- 解析响应:服务器响应后,爬虫解析HTML或JSON内容。
- 提取数据:根据需求提取结构化数据。
- 存储数据:将数据保存到文件或数据库中。
2. 常用Python爬虫库
- Requests:发送HTTP请求。
- BeautifulSoup:解析HTML,提取数据。
- Scrapy:强大的爬虫框架。
- Selenium:处理JavaScript渲染的动态网页。
3. 实战案例:地震数据爬虫
本文以爬取地震数据为例,演示爬虫的编写和使用。
3.1 环境准备
安装必要的Python库:
pip install requests BeautifulSoup4 selenium
3.2 爬虫代码编写
以下是一个简单的爬虫示例,用于抓取地震数据:
import requests
from bs4 import BeautifulSoup
def fetch_earthquake_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
earthquakes = []
for item in soup.find_all('div', class_='earthquake'):
eq_data = {
'time': item.find('span', class_='time').text,
'location': item.find('span', class_='location').text,
'magnitude': item.find('span', class_='magnitude').text
}
earthquakes.append(eq_data)
return earthquakes
# 示例URL
url = 'http://earthquake.example.com/data'
data = fetch_earthquake_data(url)
print(data)
3.3 动态内容处理
如果地震数据是动态加载的,可以使用Selenium库:
from selenium import webdriver
def fetch_dynamic_earthquake_data(url):
driver = webdriver.Chrome()
driver.get(url)
# 等待页面加载完成
driver.implicitly_wait(10)
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 提取数据...
driver.quit()
return data
data = fetch_dynamic_earthquake_data(url)
print(data)
4. 反爬虫机制应对策略
- 设置请求头:模拟浏览器行为。
- 使用代理:避免IP被封。
- 控制请求频率:避免过于频繁的请求。
5. 数据分析
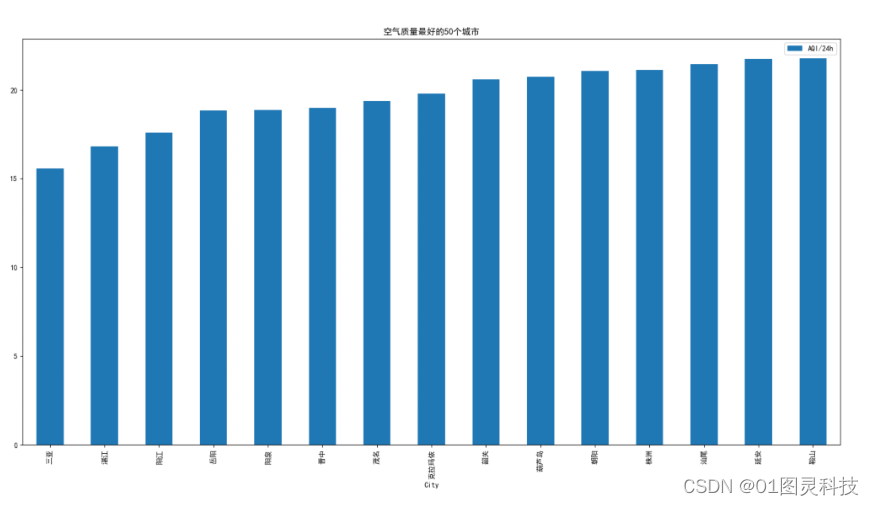
对抓取的地震数据进行简单分析,如统计一定时间内的地震次数、最大震级等。
6. 结论
通过本文的学习,读者应能够理解爬虫的工作原理,掌握Python爬虫库的使用,以及如何编写能够处理动态内容和反爬虫机制的爬虫程序。爬虫技术在数据抓取领域具有重要应用,但同时也要遵守法律法规,合理使用爬虫技术。
7. 参考文献与资源
- Python官方文档
- Requests库文档
- BeautifulSoup库文档
- Scrapy框架官方文档
- Selenium自动化测试框架文档