X光肺部感染识别项目背景
世界卫生组织的报告显示,全球每年因肺炎致死的儿童多达200万,超过HIV/AIDS、疟疾和麻疹致死人数的总和,成为儿童夭折的首要原因。95%的新发儿童临床性肺炎病例发生在发展中国家,包括东南亚、非洲、拉丁美洲地区。
肺炎会造成呼吸困难、高烧、持续咳嗽、神经系统紊乱、胃肠道功能紊乱。根据X射线胸片影像及病理状态,肺炎分为大叶性肺炎、支气管肺炎(小叶性肺炎)和间质性肺炎。
目前肺炎的诊断主要依赖血检、胸片、痰菌培养,血检需要穿刺抽血,胸片分析则需有经验的医生,菌痰培养需要较长时间。落后地区医疗资源紧缺,过度依赖人工判断,不仅使医生筋疲力尽,也会带来漏检。患者排队三小时,看病五分钟,专家号千金难求,精准医疗却遥不可及。本项目希望借助前沿的人工智能图像识别算法,从肺炎医疗大数据影像中进行细粒度数据挖掘。
有一个数据较多的胸部X光的数据库,是用来诊断是否患有肺部感染的。正常肺部如图17-1所示,胸部X线检查描绘了清晰的肺部,图像中没有任何异常混浊的区域。

图17-1
而肺部感染的X光胸片影像特征如图17-2所示,肺部炎症呈斑点状、片状或均匀的阴影,有病变的肺叶或肺段出现有斑片样的表现,肺炎后期可能出现肺部影像大片发白。
 图17-2
图17-2
项目所用到的图像分类模型
本项目使用ResNet50深度学习图像分类模型。ResNet50是一种基于深度卷积神经网络(Convolutional Neural Network,CNN)的图像分类算法。它是由微软研究院的Kaiming He等人于2015年提出的,是ResNet系列中的一个重要成员。ResNet50相比于传统的卷积神经网络模型具有更深的网络结构,通过引入残差连接(Residual Connection)解决了深层网络训练过程中的梯度消失问题,有效提升了模型的性能。
实战项目代码分析
本项目借鉴了迁移学习(Transfer Learning)的思想,使用了在 ImageNet 上训练的 ResNet50网络模型。迁移学习,简单说就是把已经训练好的模型参数迁移到新的模型来帮助新模型训练。
###############lung_demo2.py#######
#案例:肺部检测
# 加入必要的库
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, transforms, utils, models
import time
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torch.utils.tensorboard.writer import SummaryWriter
import os
import torchvision
import copy
# 加载数据集
# 图像变化设置
data_transforms = {
"train":
transforms.Compose([
transforms.RandomResizedCrop(300),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
"val":
transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test':
transforms.Compose([
transforms.Resize(size=300),
transforms.CenterCrop(size=256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224,
0.225])
]),
}
# 可视化图片
def imshow(inp, title=None):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# 可视化模型预测
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (datas, targets) in enumerate(dataloaders['val']):
datas, targets = datas.to(device), targets.to(device)
outputs = model(datas) # 预测数据
_, preds = torch.max(outputs, 1) # 获取每行数据的最大值
for j in range(datas.size()[0]):
images_so_far += 1 # 累计图片数量
ax = plt.subplot(num_images // 2, 2, images_so_far) # 显示图片
ax.axis('off') # 关闭坐标轴
ax.set_title('predicted:{}'.format(class_names[preds[j]]))
imshow(datas.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
# 定义训练函数
def train(model, device, train_loader, criterion, optimizer, epoch, writer):
# 作用:声明在模型训练时,采用Batch Normalization 和 Dropout
# Batch Normalization : 对网络中间的每层进行归一化处理
# Dropout : 减少过拟合
model.train()
total_loss = 0.0 # 总损失初始化为0.0
# 循环读取训练数据,更新模型参数
for batch_id, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 梯度初始化为零
output = model(data) # 训练后的输出
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 参数更新
total_loss += loss.item() # 累计损失
# 写入日志
writer.add_scalar('Train Loss', total_loss / len(train_loader), epoch)
writer.flush() # 刷新
return total_loss / len(train_loader) # 返回平均损失值
# 定义测试函数
def test(model, device, test_loader, criterion, epoch, writer):
# 作用:声明在模型训练时,不采用Batch Normalization 和 Dropout
model.eval()
# 损失和正确
total_loss = 0.0
correct = 0.0
# 循环读取数据
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 预测输出
output = model(data)
# 计算损失
total_loss += criterion(output, target).item()
# 获取预测结果中每行数据概率最大的下标
_, preds = torch.max(output, dim=1)
# pred = output.data.max(1)[1]
# 累计预测正确的个数
correct += torch.sum(preds == target.data)
# correct += pred.eq(target.data).cpu().sum()
######## 增加 #######
misclassified_images(preds, writer, target, data, output, epoch)
# 记录错误分类的图片
# 总损失
total_loss /= len(test_loader)
# 正确率
accuracy = correct / len(test_loader)
# 写入日志
writer.add_scalar('Test Loss', total_loss, epoch)
writer.add_scalar('Accuracy', accuracy, epoch)
writer.flush()
# 输出信息
print("Test Loss : {:.4f}, Accuracy : {:.4f}".format(total_loss, accuracy))
return total_loss, accuracy
# 定义一个获取Tensorboard的writer的函数
def tb_writer():
timestr = time.strftime("%Y%m%d_%H%M%S")
writer = SummaryWriter('logdir/' + timestr)
return writer
# 定义一个池化层处理函数
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super().__init__()
size = size or (1, 1) # 池化层的卷积核大小,默认值为(1,1)
self.pool_one = nn.AdaptiveAvgPool2d(size) # 池化层1
self.pool_two = nn.AdaptiveMaxPool2d(size) # 池化层2
def forward(self, x):
return torch.cat([self.pool_one(x), self.pool_two(x)], 1) # 连接两个池化层
def get_model():
model_pre = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
# 获取预训练模型
# 冻结预训练模型中所有参数
for param in model_pre.parameters():
param.requires_grad = False
# 替换ResNet最后的两层网络,返回一个新的模型(迁移学习)
model_pre.avgpool = AdaptiveConcatPool2d() # 池化层替换
model_pre.fc = nn.Sequential(
nn.Flatten(), # 所有维度拉平
nn.BatchNorm1d(4096), # 正则化处理
nn.Dropout(0.5), # 丢掉神经元
nn.Linear(4096, 512), # 线性层处理
nn.ReLU(), # 激活函数
nn.BatchNorm1d(512), # 正则化处理
nn.Dropout(p=0.5), # 丢掉神经元
nn.Linear(512, 2), # 线性层
nn.LogSoftmax(dim=1) # 损失函数
)
return model_pre
def train_epochs(model, device, dataloaders, criterion, optimizer, num_epochs, writer):
print("{0:>20} | {1:>20} | {2:>20} | {3:>20} |".format('Epoch',
'Training Loss',
'Test Loss',
'Accuracy'))
best_score = np.inf # 假设最好的预测值
start = time.time() # 开始时间
# 开始循环读取数据进行训练和验证
for epoch in num_epochs:
train_loss = train(model, device, dataloaders['train'], criterion, optimizer, epoch, writer)
test_loss, accuracy = test(model, device, dataloaders['val'], criterion, epoch, writer)
if test_loss < best_score:
best_score = test_loss
torch.save(model.state_dict(), model_path)
# 保存模型
# state_dict变量存放训练过程中需要学习的权重和偏置系数
print("{0:>20} | {1:>20} | {2:>20} | {3:>20.2f} |".format(epoch,
train_loss,
test_loss,
accuracy))
writer.flush()
# 训练完所耗费的总时间
time_all = time.time() - start
# 输出时间信息
print("Training complete in {:.2f}m {:.2f}s".format(time_all // 60, time_all % 60))
def misclassified_images(pred, writer, target, data, output, epoch, count=10):
misclassified = (pred != target.data) # 记录预测值与真实值不同的True和False
for index, image_tensor in enumerate(data[misclassified][:count]):
# 显示预测不同的前10幅图片
img_name = '{}->Predict-{}x{}-Actual'.format(
epoch,
LABEL[pred[misclassified].tolist()[index]],
LABEL[target.data[misclassified].tolist()[index]],
)
writer.add_image(img_name, inv_normalize(image_tensor), epoch)
# 训练和验证
# 定义超参数
model_path = './chk/chest_model.pth'
batch_size = 16
device = torch.device('gpu' if torch.cuda.is_available() else 'cpu') # gpu和cpu选择
# 加载数据
data_path = "./chest_xray/" # 数据集所在的文件夹路径
# 加载数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_path, x),
data_transforms[x]) for x in
['train', 'val', 'test']}
# 为数据集创建iterator
dataloaders = {x: DataLoader(image_datasets[x], batch_size=batch_size,
shuffle=True) for x in ['train', 'val', 'test']}
# 训练集和验证集的大小
data_sizes = {x: len(image_datasets[x]) for x in ['train', 'val', 'test']}
# 训练集所对应的标签
class_names = image_datasets['train'].classes
# 一共有两个:NORMAL正常 vs PNEUMONIA肺炎
LABEL = dict((v, k) for k, v in image_datasets['train'].class_to_idx.items())
print("-" * 50)
# 获取trian中的一批数据
datas, targets = next(iter(dataloaders['train']))
# 显示这批数据
out = torchvision.utils.make_grid(datas)
imshow(out, title=[class_names[x] for x in targets])
# 将tensor转换为image
inv_normalize = transforms.Normalize(
mean=[-0.485 / 0.229, -0.456 / 0.224, -0.406 / 0.225],
std=[1 / 0.229, 1 / 0.224, 1 / 0.255]
)
writer = tb_writer()
images, labels = next(iter(dataloaders['train'])) # 获取一批数据
grid = torchvision.utils.make_grid([inv_normalize(image) for image in images[:32]])
writer.add_image('X-Ray grid', grid, 0) # 添加到TensorBoard
writer.flush() # 将数据读取到存储器中
model = get_model().to(device) # 获取模型
criterion = nn.NLLLoss() # 损失函数
optimizer = optim.Adam(model.parameters())
train_epochs(model, device, dataloaders, criterion, optimizer, range(0, 10), writer)
writer.close()
运行结果如图17-5所示:
 图17-5
图17-5
这个项目使用了ResNet50网络并使用该网络预训练权重进行迁移学习,在肺部感染X射线数据集上进行了网络训练,可以增加训练轮次,最终达到了比较高的识别准确率。
《PyTorch深度学习与企业级项目实战(人工智能技术丛书)》(宋立桓,宋立林)【摘要 书评 试读】- 京东图书 (jd.com)




















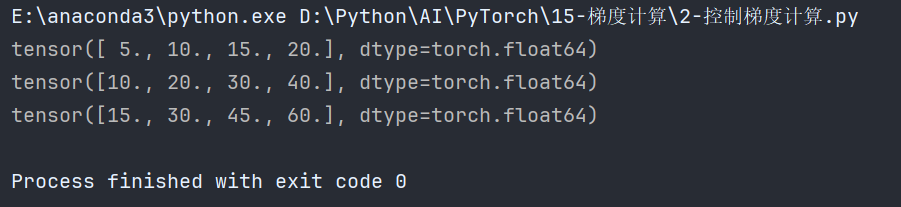









![[MySQL][事务管理][上][事务是什么?]详细讲解](https://i-blog.csdnimg.cn/direct/b1c1d3243ad44860aef29a9ed18e7e9c.png)