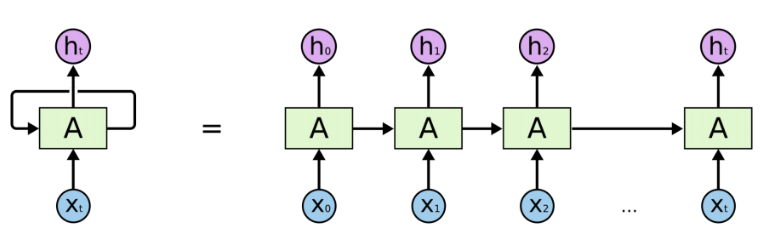
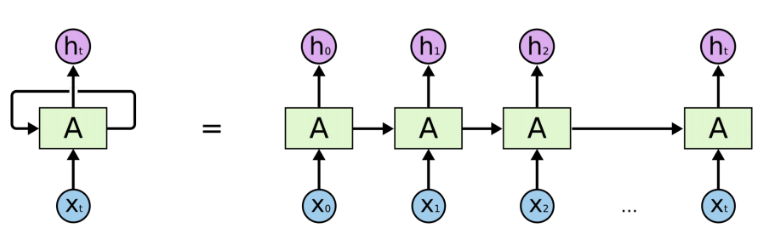
相关知识
情感分类
指输入一段话或句子,返回该段话的正向或复兴的情感分类。
text embedding
指将文本转化成向量的方法。这里的文本指词、句子、文档等文本序列。
词向量化后会将词转为二进制(独热编码)或高维实数向量,句子和文档向量化则将句子或文档转为数值向量。具体方法包括,平均每个词的词向量(Word2Vec、Doc2Vec),或使用Bert或GPT来捕捉句子的语义和上下文信息。
IMDB数据集
数据集链接:Sentiment Analysis (stanford.edu)
该数据集包含了50000条偏向明显的电影评论,其中25000条是训练集,另外为测试集。label为postive和negative。
数据集中给出了大小89527的字典文件“imdb.vocab”方便做embedding。在词典中的单词embedding时则为单词的序列号,不在词典中的设为0.
GloVe
GloVe是获取单词向量表示的无监督学习算法。它可以把单词表达成一个实数组成的向量,这些向量捕捉到了单词之间的语义特性,如相似性,类比性等。它的训练使用语料库中汇总的全球词-词共同出现的统计数据,展现了词向量空间的线性子结构。
要点1:共现词频矩阵
x_i定义为任意词出现在x附近的次数
P_ij得到的是给定词x_i的环境中出现x_j的频率,也称共先概率。词与词之间的共现概率比值可以直接或间接的表示出两个词对给定词的相关性。
glove期望能通过三个词的词向量表达共现关系比。
LSTM
循环神经网络 recurrent neural network,以序列数据为输入,在序列的演进方向上进行递归,且所有的循环单元都按照链式连接的神经网络。RNN在不断循环计算中更新。而在序列较长时,尾部就会丢失序列首部的信息,造成了梯度消失的问题。LSTM通过门控系统来控制信息的保存和丢弃,从而能更好的捕获长距离的关系。
实验
数据加载
class IMDBData():
# 两个极性标签
label_map = {
"pos": 1,
"neg": 0
}
def __init__(self, path, mode="train"):
self.mode = mode
self.path = path
self.docs, self.labels = [], []
self._load("pos")
self._load("neg")
# 加载为可迭代对象
def _load(self, label):
pattern = re.compile(r"aclImdb/{}/{}/.*\.txt$".format(self.mode, label))
# 将数据加载至内存
with tarfile.open(self.path) as tarf:
tf = tarf.next()
while tf is not None:
if bool(pattern.match(tf.name)):
# 对文本进行分词、去除标点和特殊字符、小写处理
self.docs.append(str(tarf.extractfile(tf).read().rstrip(six.b("\n\r"))
.translate(None, six.b(string.punctuation)).lower()).split())
self.labels.append([self.label_map[label]])
tf = tarf.next()
def __getitem__(self, idx):
return self.docs[idx], self.labels[idx]
def __len__(self):
return len(self.docs)
# 使用Generatordataset加载数据集
def load_imdb(imdb_path):
imdb_train = ds.GeneratorDataset(IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True, num_samples=10000)
imdb_test = ds.GeneratorDataset(IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False)
return imdb_train, imdb_test
加载词向量
# 加载glove
def load_glove(glove_path):
glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')
if not os.path.exists(glove_100d_path):
glove_zip = zipfile.ZipFile(glove_path)
glove_zip.extractall(cache_dir)
embeddings = []
tokens = []
with open(glove_100d_path, encoding='utf-8') as gf:
for glove in gf:
word, embedding = glove.split(maxsplit=1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=' '))
# 增加两个embedding
# 分别针对词表中没有对应单词
# 及输入长度不一致打包成batch时填充的短文本
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,), np.float32))
vocab = ds.text.Vocab.from_list(tokens, special_tokens=["<unk>", "<pad>"], special_first=False)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings
数据集预处理
这里将所有的token都处理成indexid,并让文本序列统一长度,不足的补齐,超出的截断。
# 查询
lookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
# 补齐
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transforms.TypeCast(ms.float32)
# 对训练集和测试集进行处理
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=['label'])
imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=['label'])
# 手动分割训练验证
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])
# 指定batch大小,并丢弃剩余的
imdb_train = imdb_train.batch(64, drop_remainder=True)
imdb_valid = imdb_valid.batch(64, drop_remainder=True)
模型构建
整体结构为 nn.Embedding -> nn.RNN(特征提取) -> nn.Dense(全连接层)
class RNN(nn.Cell):
def __init__(self, embeddings, hidden_dim, output_dim, n_layers,
bidirectional, pad_idx):
super().__init__()
vocab_size, embedding_dim = embeddings.shape
# 将之前的词表设为embedding层
self.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table=ms.Tensor(embeddings), padding_idx=pad_idx)
# 设定LSTM层
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
batch_first=True)
weight_init = HeUniform(math.sqrt(5))
bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))
# 设定全连接层
self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init=weight_init, bias_init=bias_init)
def construct(self, inputs):
embedded = self.embedding(inputs)
_, (hidden, _) = self.rnn(embedded)
hidden = ops.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)
output = self.fc(hidden)
return output
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)
def train_step(data, label):
loss, grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_one_epoch(model, train_dataset, epoch=0):
model.set_train()
total = train_dataset.get_dataset_size()
loss_total = 0
step_total = 0
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in train_dataset.create_tuple_iterator():
loss = train_step(*i)
loss_total += loss.asnumpy()
step_total += 1
t.set_postfix(loss=loss_total/step_total)
t.update(1)
hidden_size = 256
output_size = 1
num_layers = 2
bidirectional = True
lr = 0.001
pad_idx = vocab.tokens_to_ids('<pad>')
model = RNN(embeddings, hidden_size, output_size, num_layers, bidirectional, pad_idx)
# 使用二分类交叉熵损失函数
loss_fn = nn.BCEWithLogitsLoss(reduction='mean')
optimizer = nn.Adam(model.trainable_params(), learning_rate=lr)
模型训练
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)
def train_step(data, label):
loss, grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_one_epoch(model, train_dataset, epoch=0):
model.set_train()
total = train_dataset.get_dataset_size()
loss_total = 0
step_total = 0
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in train_dataset.create_tuple_iterator():
loss = train_step(*i)
loss_total += loss.asnumpy()
step_total += 1
t.set_postfix(loss=loss_total/step_total)
t.update(1)
效果评估
def binary_accuracy(preds, y):
"""
计算每个batch的准确率
"""
# 对预测值进行四舍五入
rounded_preds = np.around(ops.sigmoid(preds).asnumpy())
correct = (rounded_preds == y).astype(np.float32)
acc = correct.sum() / len(correct)
return acc
def evaluate(model, test_dataset, criterion, epoch=0):
total = test_dataset.get_dataset_size()
epoch_loss = 0
epoch_acc = 0
step_total = 0
model.set_train(False)
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in test_dataset.create_tuple_iterator():
predictions = model(i[0])
loss = criterion(predictions, i[1])
epoch_loss += loss.asnumpy()
acc = binary_accuracy(predictions, i[1])
epoch_acc += acc
step_total += 1
t.set_postfix(loss=epoch_loss/step_total, acc=epoch_acc/step_total)
t.update(1)
return epoch_loss / total
num_epochs = 2
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'sentiment-analysis.ckpt')
for epoch in range(num_epochs):
train_one_epoch(model, imdb_train, epoch)
valid_loss = evaluate(model, imdb_valid, loss_fn, epoch)
# 将loss最小的结果保存
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
ms.save_checkpoint(model, ckpt_file_name)
模型加载与测试
param_dict = ms.load_checkpoint(ckpt_file_name)
ms.load_param_into_net(model, param_dict)
imdb_test = imdb_test.batch(64)
evaluate(model, imdb_test, loss_fn)
模型预测
score_map = {
1: "Positive",
0: "Negative"
}
def predict_sentiment(model, vocab, sentence):
model.set_train(False)
tokenized = sentence.lower().split()
indexed = vocab.tokens_to_ids(tokenized)
tensor = ms.Tensor(indexed, ms.int32)
tensor = tensor.expand_dims(0)
prediction = model(tensor)
return score_map[int(np.round(ops.sigmoid(prediction).asnumpy()))]
总结
本章基于glove,使用LSTM完成情感分类任务。
打卡凭证