将机器学习模型部署到生产环境是一个复杂的过程,涉及多个步骤和考虑因素。以下是从模型训练到生产环境部署的一般流程和最佳实践:
### 1. 模型开发与训练
- **数据准备**:收集、清洗和预处理数据。确保数据质量和代表性。
- **特征工程**:选择和构建有助于模型性能的特征。
- **模型选择与训练**:选择适合问题的算法,进行模型训练。使用交叉验证等技术来避免过拟合。
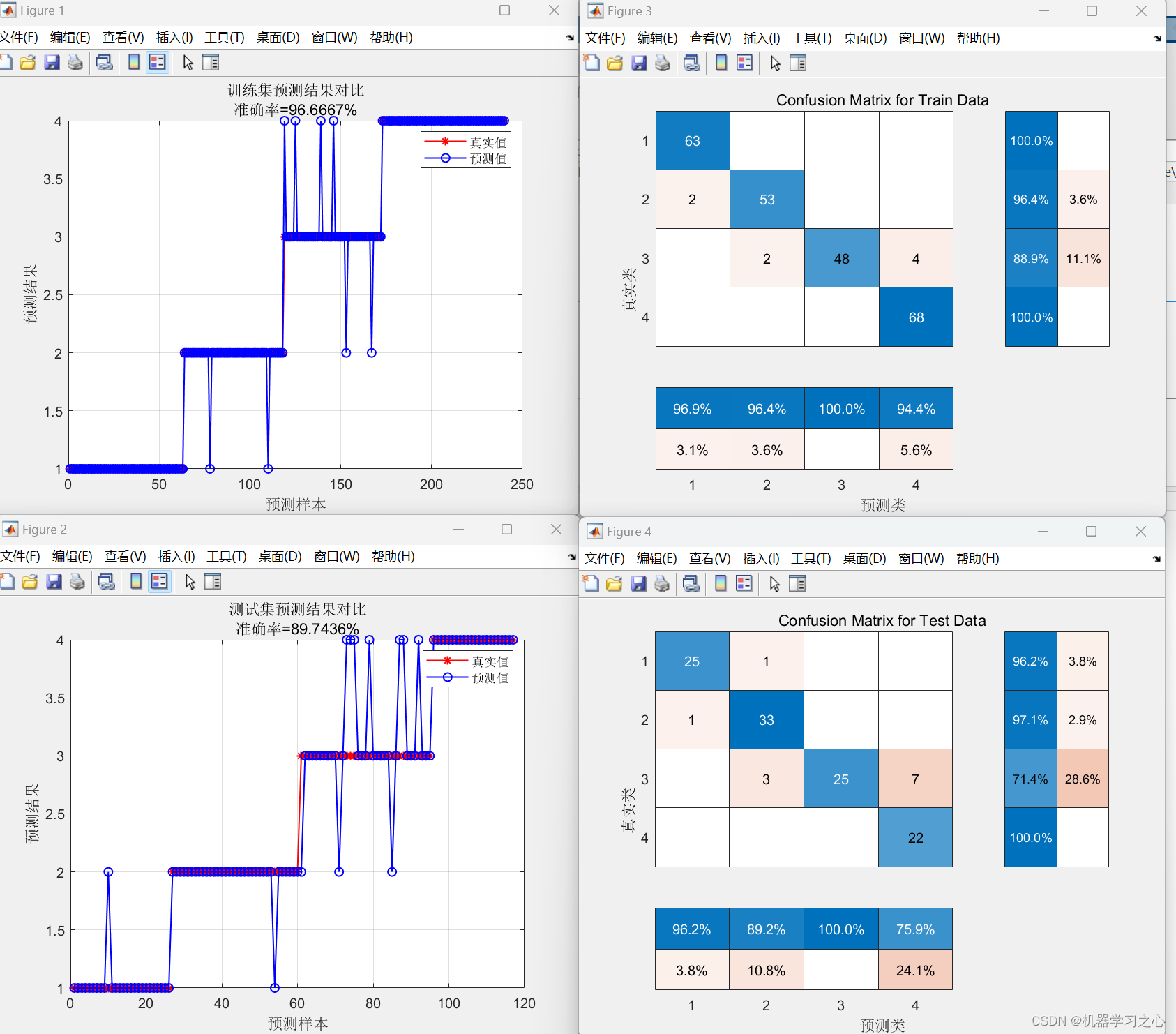
- **模型评估**:使用适当的评估指标(如准确率、召回率、F1 分数等)来评估模型性能。
### 2. 模型优化与验证
- **超参数调优**:使用网格搜索、随机搜索或贝叶斯优化等方法优化模型的超参数。
- **模型验证**:在独立的验证集上测试模型性能,确保模型的泛化能力。
### 3. 模型持久化
- **保存模型**:使用合适的格式(如 pickle、HDF5、ONNX)保存训练好的模型,以便加载和部署。
### 4. 部署准备
- **选择部署方式**:根据需求选择合适的部署方式,如 REST API、批处理或实时处理。
- **环境和依赖管理**:确保生产环境与训练环境尽可能一致,管理好所有依赖项。
### 5. 模型部署
- **构建 API**:使用 Flask、FastAPI、Django 等框架构建 API,以便应用程序可以与模型交互。
- **容器化**:使用 Docker 等工具将模型和其依赖环境打包,以便在不同环境中一致地部署。
- **部署到服务器或云**:将容器部署到本地服务器、云服务器或使用云服务如 AWS SageMaker、Google AI Platform、Azure ML 等。
### 6. 监控与维护
- **性能监控**:监控模型的性能和资源使用情况,确保系统稳定运行。
- **日志记录**:记录关键数据和系统错误,以便问题追踪和分析。
- **模型更新和迭代**:根据业务需求和模型性能反馈定期更新模型。
### 7. 安全与合规
- **数据安全**:确保符合 GDPR、HIPAA 等数据保护法规。
- **访问控制**:实施适当的访问控制和认证机制,保护模型和数据不被未授权访问。
### 8. 用户反馈与优化
- **收集用户反馈**:定期收集用户反馈,了解模型在实际环境中的表现。
- **持续优化**:根据用户反馈和业务变化调整和优化模型。
部署机器学习模型到生产环境是一个持续的过程,需要跨部门合作和不断的技术支持。确保模型的稳定性、可扩展性和安全性是成功部署的关键。



![[<span style='color:red;'>机器</span><span style='color:red;'>学习</span>系列]深入探索回归决策树:<span style='color:red;'>从</span>参数选择<span style='color:red;'>到</span><span style='color:red;'>模型</span>可视化](https://img-blog.csdnimg.cn/direct/5081b8dfc34a48fcb7eb15d764bbeb11.png)