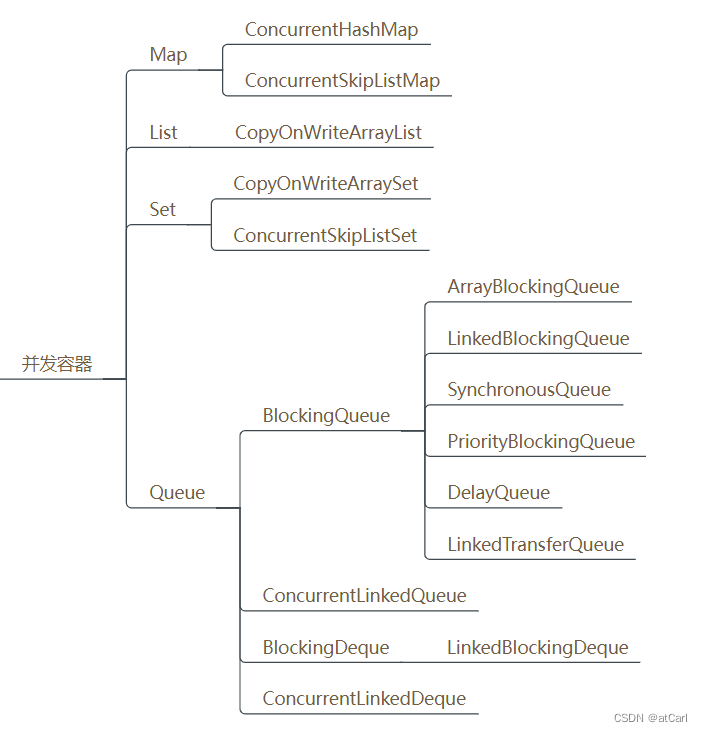
在Java中,并发容器是专门设计用于多线程环境的数据结构,能够提供线程安全的操作。以下是7大并发容器的种类及其简要介绍:
- ConcurrentHashMap:这是一个线程安全的哈希表实现,支持高效的并发读写操作。它使用分段锁技术来提高并发性能。
- ConcurrentSkipListMap:基于跳表(Skip List)实现的线程安全Map接口,支持高效的有序访问。它适用于读多写少的场景。
- ConcurrentLinkedQueue:基于链表实现的线程安全队列,支持高效的并发插入和移除操作。它适用于高吞吐量的场景。
- ConcurrentLinkedDeque:基于链表实现的线程安全双端队列,支持高效的并发插入和移除操作。它适用于需要频繁进行入队和出队操作的场景。
- ArrayBlockingQueue:基于数组实现的线程安全阻塞队列,支持有界队列和定长队列两种类型。它适用于生产者-消费者模型。
- LinkedBlockingQueue:基于链表实现的线程安全阻塞队列,支持有界队列和定长队列两种类型。它也适用于生产者-消费者模型。
- PriorityBlockingQueue:基于优先级队列实现的线程安全阻塞队列,支持按照元素的优先级进行出队操作。它适用于需要处理高优先级任务的场景。
这些容器通过不同的锁机制和算法来实现线程安全,从而在多线程环境中提供高效的数据访问和操作。
下面来V哥挨个分析一下源码实现原理和应用场景。
1. ConcurrentHashMap
ConcurrentHashMap 是 Java 中用于处理并发数据的哈希表,其设计目标是提供高性能的并发访问。以下是其主要实现原理:
JDK 1.7 版本
- 分段锁(Segment):
- ConcurrentHashMap 被划分为多个段(Segment),每个段是一个小型的 HashMap。
- 每个段独立进行加锁,从而减少锁竞争,提高并发性能。
- 数据结构:
- 每个段包含一个 HashEntry 数组,存储实际的键值对。
- 扩容机制:
- 当一个段的元素数量超过阈值时,会触发扩容操作。
- 扩容时,每个段的容量翻倍,并将原段的元素重新散列到新的段中。
JDK 1.8 版本之后
- 无锁设计:
- JDK 1.8 版本放弃了分段锁,采用 CAS(Compare-And-Swap)算法实现无锁设计。
- 数据结构:
- 内部使用 Node 数组存储键值对,Node 类继承自 AtomicReference,使得节点的引用可以原子性地更新。
- 链表和红黑树:
- 当一个桶(bucket)的元素数量超过阈值时,链表会转换成红黑树,以提高查找效率。
- 默认情况下,链表长度达到 8 时转换为红黑树,红黑树节点数量小于 6 时转换回链表。
- 扩容机制:
- 当总元素数量超过容量与加载因子的乘积时,触发扩容操作。
- 扩容时,容量翻倍,并将原数组中的元素重新散列到新数组中。
- 查找和插入:
- 通过计算键的哈希值,确定元素在数组中的位置。
- 如果当前位置的节点为空,直接插入新节点。
- 如果当前位置的节点不为空,通过 CAS 操作进行无锁插入。
- 删除操作:
- 删除操作同样使用 CAS 算法,确保在删除过程中不会影响其他线程的访问。
业务应用场景与代码案例
场景:缓存系统
在高并发系统中,缓存是常见的需求。使用 ConcurrentHashMap 可以实现高效的缓存存储和访问。
import java.util.concurrent.ConcurrentHashMap;
public class CacheSystem {
private ConcurrentHashMap<String, String> cacheMap;
public CacheSystem() {
cacheMap = new ConcurrentHashMap<>();
}
public void putToCache(String key, String value) {
cacheMap.put(key, value);
}
public String getFromCache(String key) {
return cacheMap.get(key);
}
public void removeFromCache(String key) {
cacheMap.remove(key);
}
public static void main(String[] args) {
CacheSystem cacheSystem = new CacheSystem();
// 模拟并发写入缓存
for (int i = 0; i < 1000; i++) {
final int index = i;
new Thread(() -> cacheSystem.putToCache("key" + index, "value" + index)).start();
}
// 模拟并发读取缓存
for (int i = 0; i < 1000; i++) {
final int index = i;
new Thread(() -> {
String value = cacheSystem.getFromCache("key" + index);
System.out.println("Key: key" + index + ", Value: " + value);
}).start();
}
}
}
在这个示例中,CacheSystem 类使用 ConcurrentHashMap 来存储缓存数据。通过多线程模拟并发写入和读取缓存的操作,展示了 ConcurrentHashMap 在高并发环境下的性能优势。
场景:分布式锁
在分布式系统中,有时需要实现分布式锁来控制对共享资源的访问。可以使用 ConcurrentHashMap 来实现一个简单的分布式锁。
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.TimeUnit;
public class DistributedLock {
private ConcurrentHashMap<String, Boolean> lockMap;
public DistributedLock() {
lockMap = new ConcurrentHashMap<>();
}
public boolean tryLock(String key) {
return lockMap.putIfAbsent(key, true) == null;
}
public void unlock(String key) {
lockMap.remove(key);
}
public static void main(String[] args) throws InterruptedException {
DistributedLock distributedLock = new DistributedLock();
// 模拟并发访问资源
for (int i = 0; i < 10; i++) {
final int index = i;
new Thread(() -> {
if (distributedLock.tryLock("resource")) {
try {
System.out.println("Thread " + index + " acquired the lock.");
TimeUnit.SECONDS.sleep(1); // 模拟资源访问
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
distributedLock.unlock("resource");
System.out.println("Thread " + index + " released the lock.");
}
} else {
System.out.println("Thread " + index + " failed to acquire the lock.");
}
}).start();
}
}
}
在这个示例中,DistributedLock 类使用 ConcurrentHashMap 来实现分布式锁。通过 putIfAbsent 方法尝试获取锁,如果成功则执行资源访问操作,访问完成后释放锁。
2. ConcurrentSkipListMap
ConcurrentSkipListMap 是 Java java.util.concurrent 包中提供的一个并发集合类,它实现了 SortedMap 接口。它是基于跳表(Skip List)的数据结构实现的,跳表是一种可以替代平衡树的数据结构,通过多层链表实现快速的查找、插入和删除操作。
跳表原理
- 多层索引:跳表由多层链表组成,每一层都是有序的。最底层是完整的数据链表,每一层的索引节点是下一层的子集。
- 随机化:在插入新节点时,会随机决定该节点所在的层数,从而减少查找时的比较次数。
- 查找效率:查找操作可以通过逐层跳转,每次跳过多个节点,实现近似 O(log n) 的查找效率。
ConcurrentSkipListMap 的实现细节的关键点
- Node 结构:内部使用 Node 类来存储键值对,每个 Node 包含一个 key、value 以及多个 forward 指针(指向下一层的相同节点)。
- 头节点:跳表有一个头节点,它不存储数据,仅作为链表的起点。
- 索引维护:在插入和删除操作中,跳表会维护索引节点,确保索引的准确性。
- 并发控制:通过细粒度的锁机制(如 ReadWriteLock)来控制并发访问,提高性能。
业务应用场景
ConcurrentSkipListMap 适用于需要有序访问的数据集合,以下是一些典型的应用场景:
- 实时监控系统:存储和更新监控数据,按时间戳排序。
- 日志系统:按时间戳排序的日志记录。
- 任务调度:按优先级或时间排序的任务队列。
- 数据聚合:按时间范围聚合数据。
应用代码案例
以下是一个使用 ConcurrentSkipListMap 的示例,展示如何在高并发环境下存储和访问有序数据。
import java.util.concurrent.ConcurrentSkipListMap;
import java.util.concurrent.atomic.AtomicInteger;
public class ConcurrentSkipListMapExample {
private static final ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();
public static void main(String[] args) {
// 模拟并发写入
for (int i = 0; i < 10000; i++) {
final int index = i;
new Thread(() -> {
map.put(index, "Value" + index);
System.out.println("Inserted: Key=" + index + ", Value=" + map.get(index));
}).start();
}
// 模拟并发读取
for (int i = 0; i < 10000; i++) {
final int index = i;
new Thread(() -> {
String value = map.get(index);
if (value != null) {
System.out.println("Retrieved: Key=" + index + ", Value=" + value);
}
}).start();
}
}
}
在这个示例中:
- 使用 ConcurrentSkipListMap 存储键值对,键为整数,值为字符串。
- 模拟并发写入操作,每个线程向映射表中插入一个键值对。
- 模拟并发读取操作,每个线程从映射表中检索一个键的值。
由于 ConcurrentSkipListMap 是线程安全的,因此在多线程环境下可以安全地进行读写操作,而不需要额外的同步控制。
ConcurrentSkipListMap 通过跳表和细粒度的锁机制实现了高效的并发访问和有序性,适用于需要高并发读写和有序数据存储的业务场景。
3. ConcurrentLinkedQueue
ConcurrentLinkedQueue 是 Java 并发包 java.util.concurrent 中提供的一个无界线程安全队列,它基于链表实现。以下是其主要实现原理是这样的:
- 基于链表:
- ConcurrentLinkedQueue 使用链表来存储元素,每个节点包含一个 item(存储数据)和一个 next 指针(指向下一个节点)。
- 无锁设计:
- 通过使用 CAS(Compare-And-Swap)操作来实现无锁的并发控制,确保在多线程环境下的数据一致性。
- 头尾指针:
- 队列有两个指针:head 和 tail。head 指向队列的第一个元素,tail 指向最后一个元素的下一个位置(即新元素插入的位置)。
- 入队操作:
- 当新元素入队时,通过 CAS 操作将新节点的 next 指针指向当前的 head 节点,然后将 head 指针更新为新节点。
- 出队操作:
- 当元素出队时,通过 CAS 操作将 head 指针更新为当前 head 节点的下一个节点。
- 迭代器:
- ConcurrentLinkedQueue 提供了弱一致性迭代器,即迭代器在迭代过程中可能会看到部分修改,但不会影响迭代器的一致性。
业务应用场景
ConcurrentLinkedQueue 适用于以下业务场景:
- 生产者-消费者队列:在生产者-消费者模型中,ConcurrentLinkedQueue 可以作为消息队列,处理并发消息的传递。
- 任务调度:在任务调度系统中,ConcurrentLinkedQueue 可以用于存储待执行的任务。
- 日志收集:在日志系统中,ConcurrentLinkedQueue 可以用于收集日志消息,进行异步处理。
- 数据缓冲:在数据流处理中,ConcurrentLinkedQueue 可以作为缓冲区,存储中间数据。
应用代码案例
以下是一个使用 ConcurrentLinkedQueue 的示例,展示如何在生产者-消费者模型中使用它。
import java.util.concurrent.ConcurrentLinkedQueue;
public class ConcurrentLinkedQueueExample {
private static final ConcurrentLinkedQueue<Integer> queue = new ConcurrentLinkedQueue<>();
public static void main(String[] args) {
// 生产者线程
for (int i = 0; i < 10; i++) {
new Thread(() -> {
queue.offer(i); // 入队
System.out.println("Produced: " + i);
}).start();
}
// 消费者线程
for (int i = 0; i < 5; i++) {
new Thread(() -> {
while (true) {
Integer item = queue.poll(); // 出队
if (item == null) {
break;
}
System.out.println("Consumed: " + item);
}
}).start();
}
}
}
在这个示例中:
- 使用 ConcurrentLinkedQueue 作为消息队列,存储整数。
- 生产者线程向队列中添加整数,模拟生产消息。
- 消费者线程从队列中取出整数,模拟消费消息。
由于 ConcurrentLinkedQueue 是线程安全的,因此生产者和消费者线程可以并发地访问队列,而不需要额外的同步控制。
ConcurrentLinkedQueue 通过链表和 CAS 操作实现了高效的并发访问,适用于需要高并发读写的队列操作。它在生产者-消费者模型、任务调度、日志收集等场景中具有广泛的应用。
4. ConcurrentLinkedDeque
ConcurrentLinkedDeque 是 Java java.util.concurrent 包中的一个并发双端队列实现。它是一个无界队列,支持从队列的头部或尾部进行高效的并发插入、删除和访问操作。以下是其主要实现原理:
- 基于链表:
- ConcurrentLinkedDeque 内部使用双向链表来存储元素。每个节点包含一个 item(存储数据)和两个指针 prev(指向前一个节点)与 next(指向后一个节点)。
- 无锁设计:
- 通过使用 CAS(Compare-And-Swap)操作来实现无锁的并发控制,确保在多线程环境下的数据一致性。
- 头尾指针:
- 队列有两个指针:head 和 tail。head 指向队列的第一个元素,tail 指向最后一个元素。
- 入队操作:
- 当元素从头部入队时,通过 CAS 操作将新节点的 prev 指针指向当前的 head 节点,然后将 head 指针更新为新节点。
- 当元素从尾部入队时,通过 CAS 操作将新节点的 next 指针指向当前的 tail 节点,然后将 tail 指针更新为新节点。
- 出队操作:
- 当元素从头部出队时,通过 CAS 操作将 head 指针更新为当前 head 节点的下一个节点。
- 当元素从尾部出队时,通过 CAS 操作将 tail 指针更新为当前 tail 节点的前一个节点。
- 迭代器:
- ConcurrentLinkedDeque 提供了弱一致性迭代器,即迭代器在迭代过程中可能会看到部分修改,但不会影响迭代器的一致性。
业务应用场景
ConcurrentLinkedDeque 适用于以下业务场景:
- 生产者-消费者队列:在生产者-消费者模型中,ConcurrentLinkedDeque 可以作为消息队列,处理并发消息的传递。
- 任务调度:在任务调度系统中,ConcurrentLinkedDeque 可以用于存储待执行的任务,支持从队列的两端进行任务的添加和移除。
- 日志收集:在日志系统中,ConcurrentLinkedDeque 可以用于收集日志消息,进行异步处理。
- 数据缓冲:在数据流处理中,ConcurrentLinkedDeque 可以作为缓冲区,存储中间数据。
应用代码案例
以下是一个使用 ConcurrentLinkedDeque 的示例,展示如何在生产者-消费者模型中使用它。
import java.util.concurrent.ConcurrentLinkedDeque;
public class ConcurrentLinkedDequeExample {
private static final ConcurrentLinkedDeque<Integer> deque = new ConcurrentLinkedDeque<>();
public static void main(String[] args) {
// 生产者线程
for (int i = 0; i < 10; i++) {
new Thread(() -> {
deque.offer(i); // 入队
System.out.println("Produced: " + i);
}).start();
}
// 消费者线程
for (int i = 0; i < 5; i++) {
new Thread(() -> {
while (true) {
Integer item = deque.poll(); // 从头部出队
if (item == null) {
break;
}
System.out.println("Consumed from head: " + item);
item = deque.pollLast(); // 从尾部出队
if (item == null) {
break;
}
System.out.println("Consumed from tail: " + item);
}
}).start();
}
}
}
在这个示例中:
- 使用 ConcurrentLinkedDeque 作为消息队列,存储整数。
- 生产者线程向队列中添加整数,模拟生产消息。
- 消费者线程从队列的两端取出整数,模拟消费消息。
由于 ConcurrentLinkedDeque 是线程安全的,因此生产者和消费者线程可以并发地访问队列,而不需要额外的同步控制。
ConcurrentLinkedDeque 通过双向链表和 CAS 操作实现了高效的并发访问,支持从队列的两端进行插入和删除操作。它在生产者-消费者模型、任务调度、日志收集等场景中具有广泛的应用。
5. ArrayBlockingQueue
ArrayBlockingQueue 是 Java java.util.concurrent 包中的一个有界阻塞队列实现。它基于数组实现,可以指定队列的容量。以下是其主要实现原理是这样的:
- 基于数组:
- ArrayBlockingQueue 内部使用一个数组来存储队列的元素。
- 锁机制:
- 使用一个 ReentrantLock 来控制对队列的访问,确保线程安全。
- 条件变量:
- 使用两个条件变量 notEmpty 和 notFull:
- notEmpty 用于等待队列非空的线程。
- notFull 用于等待队列非满的线程。
- 入队操作:
- 当元素入队时,首先检查队列是否已满。如果未满,则将元素添加到数组中,并更新相关索引。
- 如果队列已满,则调用 notFull 条件变量的 await() 方法,使当前线程等待。
- 出队操作:
- 当元素出队时,首先检查队列是否为空。如果不为空,则从数组中移除元素,并更新相关索引。
- 如果队列为空,则调用 notEmpty 条件变量的 await() 方法,使当前线程等待。
- 公平性:
- ArrayBlockingQueue 提供了两种构造方法,可以选择是否公平(fairness)。公平性高的队列会按照线程等待的顺序来分配资源,而非公平的队列则可能使先到达的线程等待更长时间。
业务应用场景
ArrayBlockingQueue 适用于以下业务场景:
- 生产者-消费者队列:在生产者-消费者模型中,ArrayBlockingQueue 可以作为消息队列,处理并发消息的传递。
- 任务调度:在任务调度系统中,ArrayBlockingQueue 可以用于存储待执行的任务。
- 数据缓冲:在数据流处理中,ArrayBlockingQueue 可以作为缓冲区,存储中间数据。
应用代码案例
以下是一个使用 ArrayBlockingQueue 的示例,展示如何在生产者-消费者模型中使用它。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class ArrayBlockingQueueExample {
private static final BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10); // 队列容量为10
public static void main(String[] args) {
// 生产者线程
for (int i = 0; i < 15; i++) {
new Thread(() -> {
try {
queue.put(i); // 入队
System.out.println("Produced: " + i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
// 消费者线程
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
while (true) {
Integer item = queue.take(); // 从队列中取出元素
System.out.println("Consumed: " + item);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}
在这个示例中:
- 使用 ArrayBlockingQueue 作为消息队列,存储整数,队列容量为10。
- 生产者线程向队列中添加整数,模拟生产消息。当队列满时,生产者线程会阻塞。
- 消费者线程从队列中取出整数,模拟消费消息。当队列为空时,消费者线程会阻塞。
由于 ArrayBlockingQueue 是线程安全的,因此生产者和消费者线程可以并发地访问队列,而不需要额外的同步控制。
ArrayBlockingQueue 通过数组和锁机制实现了有界阻塞队列,支持从队列的两端进行插入和删除操作。它在生产者-消费者模型、任务调度、数据缓冲等场景中具有广泛的应用。
6. LinkedBlockingQueue
LinkedBlockingQueue 是 Java java.util.concurrent 包中的一个阻塞队列实现。与 ArrayBlockingQueue 不同的是,LinkedBlockingQueue 使用链表而非数组来存储元素,因此它可以是一个有界队列也可以是一个无界队列。以下是其主要实现原理关键点:
- 基于链表:
- LinkedBlockingQueue 内部使用双向链表来存储队列的元素。每个节点包含一个 item(存储数据)和两个指针 prev(指向前一个节点)与 next(指向后一个节点)。
- 锁机制:
- 使用一个 ReentrantLock 来控制对队列的访问,确保线程安全。
- 条件变量:
- 使用两个条件变量 notEmpty 和 notFull:
- notEmpty 用于等待队列非空的线程。
- notFull 用于等待队列非满的线程(对于无界队列,此条件变量通常不会使用)。
- 入队操作:
- 当元素入队时,首先检查队列是否已满(仅对有界队列)。如果未满,则将元素添加到链表末尾,并更新相关指针。
- 如果队列已满,则调用 notFull 条件变量的 await() 方法,使当前线程等待。
- 出队操作:
- 当元素出队时,首先检查队列是否为空。如果不为空,则从链表中移除元素,并更新相关指针。
- 如果队列为空,则调用 notEmpty 条件变量的 await() 方法,使当前线程等待。
- 公平性:
- LinkedBlockingQueue 提供了两种构造方法,可以选择是否公平(fairness)。公平性高的队列会按照线程等待的顺序来分配资源,而非公平的队列则可能使先到达的线程等待更长时间。
业务应用场景
LinkedBlockingQueue 适用于以下业务场景:
- 生产者-消费者队列:在生产者-消费者模型中,LinkedBlockingQueue 可以作为消息队列,处理并发消息的传递。
- 任务调度:在任务调度系统中,LinkedBlockingQueue 可以用于存储待执行的任务。
- 数据缓冲:在数据流处理中,LinkedBlockingQueue 可以作为缓冲区,存储中间数据。
应用代码案例
以下是一个使用 LinkedBlockingQueue 的示例,展示如何在生产者-消费者模型中使用它。
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class LinkedBlockingQueueExample {
private static final BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(); // 无界队列
public static void main(String[] args) {
// 生产者线程
for (int i = 0; i < 15; i++) {
new Thread(() -> {
try {
queue.put(i); // 入队
System.out.println("Produced: " + i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
// 消费者线程
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
while (true) {
Integer item = queue.take(); // 从队列中取出元素
System.out.println("Consumed: " + item);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}
在这个示例中:
- 使用 LinkedBlockingQueue 作为消息队列,存储整数。这里创建的是一个无界队列。
- 生产者线程向队列中添加整数,模拟生产消息。即使队列无界,生产者线程也会在中断时停止。
- 消费者线程从队列中取出整数,模拟消费消息。消费者线程使用 take() 方法,会阻塞直到队列中有元素可取。
由于 LinkedBlockingQueue 是线程安全的,因此生产者和消费者线程可以并发地访问队列,而不需要额外的同步控制。
LinkedBlockingQueue 提供了一个灵活的阻塞队列实现,既可以配置为有界队列也可以是无界队列,适用于需要高并发处理的生产者-消费者场景、任务调度和数据缓冲等应用。
7. PriorityBlockingQueue
PriorityBlockingQueue 是 Java java.util.concurrent 包中的一个优先级阻塞队列实现。它基于优先队列(Priority Queue)的数据结构,确保队列中元素的顺序按照自然顺序或者根据提供的 Comparator 来排序。以下是其主要实现原理:
- 基于堆:
- PriorityBlockingQueue 内部使用一个二叉堆(通常是二叉最小堆)来存储队列的元素。二叉堆是一种完全二叉树,可以高效地维护元素的顺序。
- 锁机制:
- 使用一个 ReentrantLock 来控制对队列的访问,确保线程安全。
- 条件变量:
- 使用一个条件变量 notEmpty 来管理等待队列非空的线程。
- 入队操作:
- 当元素入队时,首先将元素添加到堆中,然后通过堆调整(heapify)操作确保堆的性质。
- 如果队列未满,则直接添加元素;如果队列已满(对于有界队列),则根据优先级决定是否替换队列中的最低优先级元素。
- 出队操作:
- 当元素出队时,移除堆顶元素(即优先级最高的元素),然后将堆的最后一个元素移至堆顶,并重新调整堆以维持堆的性质。
- 公平性:
- PriorityBlockingQueue 构造时可以选择是否公平(fairness)。公平性高的队列会按照线程等待的顺序来分配资源,而非公平的队列则可能使先到达的线程等待更长时间。
- 容量限制:
- 可以选择是否设置队列的容量限制。如果设置了容量限制,队列在满时会阻塞入队操作,直到有空间可用。
业务应用场景
PriorityBlockingQueue 适用于以下业务场景:
- 任务调度:在任务调度系统中,可以根据任务的优先级来安排任务的执行顺序。
- 资源分配:在资源有限的情况下,可以根据优先级来分配资源。
- 紧急任务处理:在需要处理紧急任务的场景中,可以使用优先级队列来确保高优先级任务优先执行。
应用代码案例
以下是一个使用 PriorityBlockingQueue 的示例,展示如何在任务调度系统中使用它。
import java.util.concurrent.PriorityBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class PriorityBlockingQueueExample {
private static final BlockingQueue<Task> queue = new PriorityBlockingQueue<>(10, (t1, t2) -> {
// 优先级比较,优先级高的先执行
return t1.getPriority() - t2.getPriority();
});
static class Task implements Comparable<Task> {
private final int priority;
private final String name;
public Task(int priority, String name) {
this.priority = priority;
this.name = name;
}
public int getPriority() {
return priority;
}
@Override
public int compareTo(Task other) {
return other.priority - this.priority; // 优先级高的先执行
}
@Override
public String toString() {
return name;
}
}
public static void main(String[] args) {
// 添加任务
for (int i = 0; i < 15; i++) {
int priority = (int) (Math.random() * 10);
new Thread(() -> {
try {
queue.put(new Task(priority, "Task " + i));
System.out.println("Added: " + new Task(priority, "Task " + i));
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
// 执行任务
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
while (true) {
Task task = queue.take();
System.out.println("Executing: " + task);
Thread.sleep(1000); // 模拟任务执行时间
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}
在这个示例中:
- 使用 PriorityBlockingQueue 作为任务队列,存储 Task 对象。
- Task 对象实现了 Comparable 接口,定义了任务的优先级比较逻辑。
- 生产者线程向队列中添加任务,模拟任务生成。
- 消费者线程从队列中取出任务并执行,模拟任务处理。任务按照优先级顺序执行。
由于 PriorityBlockingQueue 是线程安全的,因此生产者和消费者线程可以并发地访问队列,而不需要额外的同步控制。
PriorityBlockingQueue 提供了一个高效的优先级阻塞队列实现,适用于需要按优先级顺序处理任务的业务场景。通过使用二叉堆来维护元素的顺序,它能够确保高优先级任务的优先执行。
最后
除了以上7种并发容器,还有CopyOnWriteArrayList,来代替Vector、synchronizedList,CopyOnWriteArraySet来代替synchronizedSet,基于CopyOnWriteArrayList实现,ConcurrentSkipListSet可以代替synchronizedSortedSet,内部基于ConcurrentSkipListMap实现。兄弟们还有哪些应用场景和见解,欢迎评论留言,如果内容对你有些许帮助,V哥真诚向你求个赞,关注【威哥爱编程】一起成长。