通过简单的工作流程变更,实现了1000倍的加速——连我都对此感到惊讶!

我从Pandas切换到Polars,并将数据集从CSV格式转换为IPC格式。但是,我们需要深入了解这在实践中意味着什么。
什么是IPC文件?
首先,IPC格式是什么?它是一种磁盘格式,反映了Apache Arrow在内存中存储数据的方式。它也被称为Arrow格式或Feather格式。
IPC读取速度非常快,因为它只需要极少的序列化操作。但IPC不止于此,因为Polars中的IPC支持内存映射。
通过内存映射,Polars不会将整个文件读入内存——它知道数据在磁盘上的位置。
这使得Polars中的pl.read_ipc操作非常快,因为它不需要将数据读入内存。但与read_csv相比,不在内存中的数据可能会对性能造成一定的拖累。
(说明:IPC文件通常指的是用于进程间通信的文件格式,特别是Apache Arrow的IPC格式。Apache Arrow是一种跨平台的开发平台,用于在内存中高效表示平面列式数据。Polars是一个Python数据分析库,其底层数据结构与Apache Arrow紧密集成,因此Polars能够利用Arrow的IPC格式来存储和交换数据。使用IPC文件,Polars可以在多个进程之间快速、高效地传输和共享数据,而无需将数据转换为其他格式或进行昂贵的序列化和反序列化操作。这可以显著提高数据处理的性能和效率。)
测试完整查询
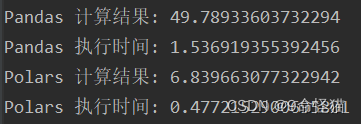
我们可以通过执行完整查询来测试实际性能——在这种情况下,是在纽约出租车数据上。我们按乘客数量获取平均距离。
So in practice: Polars with IPC is 100x faster than Pandas with CSV. Not bad.
所以在实践中:使用IPC格式的Polars比使用CSV格式的Pandas快100倍。这很不错。

Pandas 当然也支持 IPC,通过 pd.read_feather。在这种比较中,Polars 大约比 Pandas 快 5 倍。
IPC 的主要缺点是文件大小可能比 CSV 大。然而,在许多情况下,为了更快的查询而增加存储空间是一个很好的权衡。
无论如何,使用 IPC 的 Polars 都可以通过流式计算处理大于内存的文件。
我认为 IPC 格式的使用并不普遍,尤其是当你需要从本地文件系统或快速云连接中读取大文件时——想象一下,你可以在具有 10ms 延迟的 Streamlit 应用程序中做什么!

![[DS]<span style='color:red;'>Polar</span>靶场web(<span style='color:red;'>二</span>)](https://img-blog.csdnimg.cn/direct/32846b2739924b6182f8fc43f356e388.png)